 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoSplatt3R: Leveraging Perspective Pretraining for Generalized Unposed Wide-Baseline Panorama Reconstruction
Jul 29, 2025Wide-baseline panorama reconstruction has emerged as a highly effective and pivotal approach for not only achieving geometric reconstruction of the surrounding 3D environment, but also generating highly realistic and immersive novel views. Although existing methods have shown remarkable performance across various benchmarks, they are predominantly reliant on accurate pose information. In real-world scenarios, the acquisition of precise pose often requires additional computational resources and is highly susceptible to noise. These limitations hinder the broad applicability and practicality of such methods. In this paper, we present PanoSplatt3R, an unposed wide-baseline panorama reconstruction method. We extend and adapt the foundational reconstruction pretrainings from the perspective domain to the panoramic domain, thus enabling powerful generalization capabilities. To ensure a seamless and efficient domain-transfer process, we introduce RoPE rolling that spans rolled coordinates in rotary positional embeddings across different attention heads, maintaining a minimal modification to RoPE's mechanism, while modeling the horizontal periodicity of panorama images. Comprehensive experiments demonstrate that PanoSplatt3R, even in the absence of pose information, significantly outperforms current state-of-the-art methods. This superiority is evident in both the generation of high-quality novel views and the accuracy of depth estimation, thereby showcasing its great potential for practical applications. Project page: https://npucvr.github.io/PanoSplatt3R
The Meeseeks Mesh: Spatially Consistent 3D Adversarial Objects for BEV Detector
May 29, 20253D object detection is a critical component in autonomous driving systems. It allows real-time recognition and detection of vehicles, pedestrians and obstacles under varying environmental conditions. Among existing methods, 3D object detection in the Bird's Eye View (BEV) has emerged as the mainstream framework. To guarantee a safe, robust and trustworthy 3D object detection, 3D adversarial attacks are investigated, where attacks are placed in 3D environments to evaluate the model performance, e.g. putting a film on a car, clothing a pedestrian. The vulnerability of 3D object detection models to 3D adversarial attacks serves as an important indicator to evaluate the robustness of the model against perturbations. To investigate this vulnerability, we generate non-invasive 3D adversarial objects tailored for real-world attack scenarios. Our method verifies the existence of universal adversarial objects that are spatially consistent across time and camera views. Specifically, we employ differentiable rendering techniques to accurately model the spatial relationship between adversarial objects and the target vehicle. Furthermore, we introduce an occlusion-aware module to enhance visual consistency and realism under different viewpoints. To maintain attack effectiveness across multiple frames, we design a BEV spatial feature-guided optimization strategy. Experimental results demonstrate that our approach can reliably suppress vehicle predictions from state-of-the-art 3D object detectors, serving as an important tool to test robustness of 3D object detection models before deployment. Moreover, the generated adversarial objects exhibit strong generalization capabilities, retaining its effectiveness at various positions and distances in the scene.
Generative Edge Detection with Stable Diffusion
Oct 04, 2024



Edge detection is typically viewed as a pixel-level classification problem mainly addressed by discriminative methods. Recently, generative edge detection methods, especially diffusion model based solutions, are initialized in the edge detection task. Despite great potential, the retraining of task-specific designed modules and multi-step denoising inference limits their broader applications. Upon closer investigation, we speculate that part of the reason is the under-exploration of the rich discriminative information encoded in extensively pre-trained large models (\eg, stable diffusion models). Thus motivated, we propose a novel approach, named Generative Edge Detector (GED), by fully utilizing the potential of the pre-trained stable diffusion model. Our model can be trained and inferred efficiently without specific network design due to the rich high-level and low-level prior knowledge empowered by the pre-trained stable diffusion. Specifically, we propose to finetune the denoising U-Net and predict latent edge maps directly, by taking the latent image feature maps as input. Additionally, due to the subjectivity and ambiguity of the edges, we also incorporate the granularity of the edges into the denoising U-Net model as one of the conditions to achieve controllable and diverse predictions. Furthermore, we devise a granularity regularization to ensure the relative granularity relationship of the multiple predictions. We conduct extensive experiments on multiple datasets and achieve competitive performance (\eg, 0.870 and 0.880 in terms of ODS and OIS on the BSDS test dataset).
TAVGBench: Benchmarking Text to Audible-Video Generation
Apr 22, 2024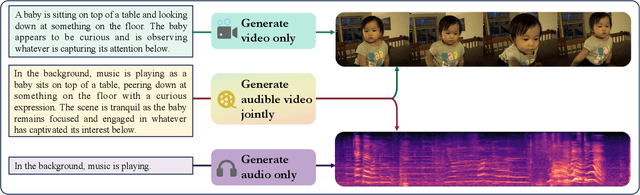

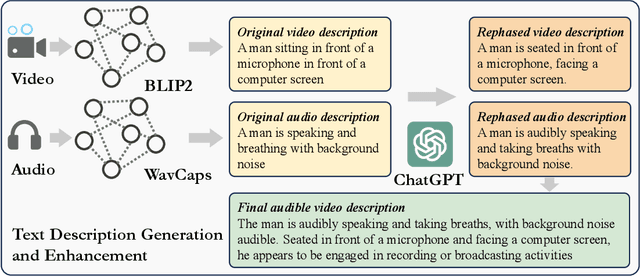

The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.
Multimodal Variational Auto-encoder based Audio-Visual Segmentation
Oct 12, 2023



We propose an Explicit Conditional Multimodal Variational Auto-Encoder (ECMVAE) for audio-visual segmentation (AVS), aiming to segment sound sources in the video sequence. Existing AVS methods focus on implicit feature fusion strategies, where models are trained to fit the discrete samples in the dataset. With a limited and less diverse dataset, the resulting performance is usually unsatisfactory. In contrast, we address this problem from an effective representation learning perspective, aiming to model the contribution of each modality explicitly. Specifically, we find that audio contains critical category information of the sound producers, and visual data provides candidate sound producer(s). Their shared information corresponds to the target sound producer(s) shown in the visual data. In this case, cross-modal shared representation learning is especially important for AVS. To achieve this, our ECMVAE factorizes the representations of each modality with a modality-shared representation and a modality-specific representation. An orthogonality constraint is applied between the shared and specific representations to maintain the exclusive attribute of the factorized latent code. Further, a mutual information maximization regularizer is introduced to achieve extensive exploration of each modality. Quantitative and qualitative evaluations on the AVSBench demonstrate the effectiveness of our approach, leading to a new state-of-the-art for AVS, with a 3.84 mIOU performance leap on the challenging MS3 subset for multiple sound source segmentation.
Contrastive Conditional Latent Diffusion for Audio-visual Segmentation
Jul 31, 2023



We propose a latent diffusion model with contrastive learning for audio-visual segmentation (AVS) to extensively explore the contribution of audio. We interpret AVS as a conditional generation task, where audio is defined as the conditional variable for sound producer(s) segmentation. With our new interpretation, it is especially necessary to model the correlation between audio and the final segmentation map to ensure its contribution. We introduce a latent diffusion model to our framework to achieve semantic-correlated representation learning. Specifically, our diffusion model learns the conditional generation process of the ground-truth segmentation map, leading to ground-truth aware inference when we perform the denoising process at the test stage. As a conditional diffusion model, we argue it is essential to ensure that the conditional variable contributes to model output. We then introduce contrastive learning to our framework to learn audio-visual correspondence, which is proven consistent with maximizing the mutual information between model prediction and the audio data. In this way, our latent diffusion model via contrastive learning explicitly maximizes the contribution of audio for AVS. Experimental results on the benchmark dataset verify the effectiveness of our solution. Code and results are online via our project page: https://github.com/OpenNLPLab/DiffusionAVS.
Measuring and Modeling Uncertainty Degree for Monocular Depth Estimation
Jul 19, 2023Effectively measuring and modeling the reliability of a trained model is essential to the real-world deployment of monocular depth estimation (MDE) models. However, the intrinsic ill-posedness and ordinal-sensitive nature of MDE pose major challenges to the estimation of uncertainty degree of the trained models. On the one hand, utilizing current uncertainty modeling methods may increase memory consumption and are usually time-consuming. On the other hand, measuring the uncertainty based on model accuracy can also be problematic, where uncertainty reliability and prediction accuracy are not well decoupled. In this paper, we propose to model the uncertainty of MDE models from the perspective of the inherent probability distributions originating from the depth probability volume and its extensions, and to assess it more fairly with more comprehensive metrics. By simply introducing additional training regularization terms, our model, with surprisingly simple formations and without requiring extra modules or multiple inferences, can provide uncertainty estimations with state-of-the-art reliability, and can be further improved when combined with ensemble or sampling methods. A series of experiments demonstrate the effectiveness of our methods.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023



This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
Dense Uncertainty Estimation
Oct 13, 2021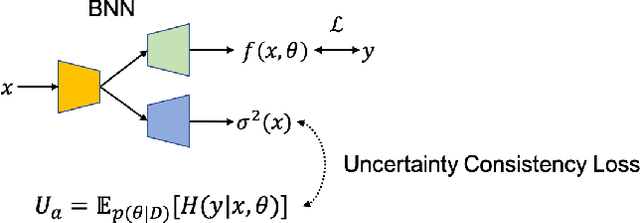
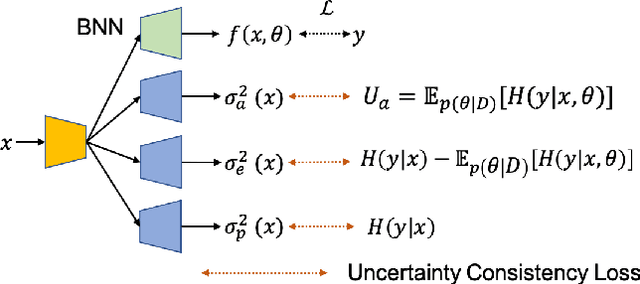
Deep neural networks can be roughly divided into deterministic neural networks and stochastic neural networks.The former is usually trained to achieve a mapping from input space to output space via maximum likelihood estimation for the weights, which leads to deterministic predictions during testing. In this way, a specific weights set is estimated while ignoring any uncertainty that may occur in the proper weight space. The latter introduces randomness into the framework, either by assuming a prior distribution over model parameters (i.e. Bayesian Neural Networks) or including latent variables (i.e. generative models) to explore the contribution of latent variables for model predictions, leading to stochastic predictions during testing. Different from the former that achieves point estimation, the latter aims to estimate the prediction distribution, making it possible to estimate uncertainty, representing model ignorance about its predictions. We claim that conventional deterministic neural network based dense prediction tasks are prone to overfitting, leading to over-confident predictions, which is undesirable for decision making. In this paper, we investigate stochastic neural networks and uncertainty estimation techniques to achieve both accurate deterministic prediction and reliable uncertainty estimation. Specifically, we work on two types of uncertainty estimations solutions, namely ensemble based methods and generative model based methods, and explain their pros and cons while using them in fully/semi/weakly-supervised framework. Due to the close connection between uncertainty estimation and model calibration, we also introduce how uncertainty estimation can be used for deep model calibration to achieve well-calibrated models, namely dense model calibration. Code and data are available at https://github.com/JingZhang617/UncertaintyEstimation.
Depth-Guided Camouflaged Object Detection
Jun 26, 2021
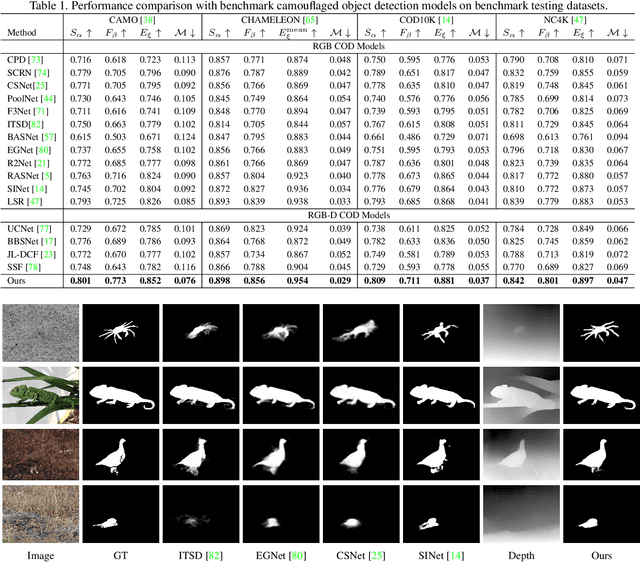
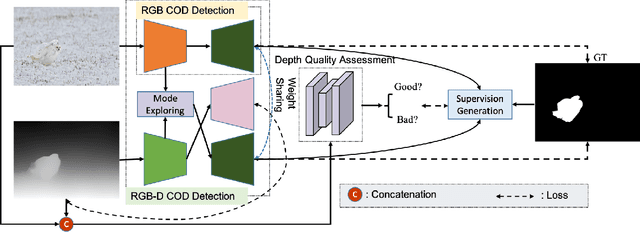

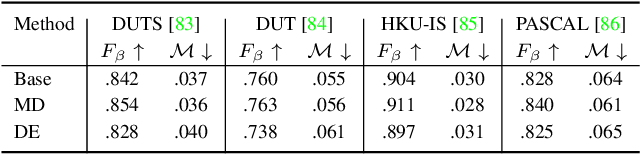
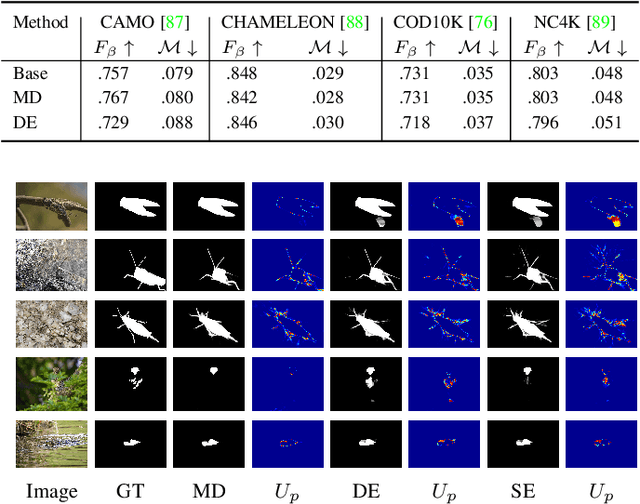
Camouflaged object detection (COD) aims to segment camouflaged objects hiding in the environment, which is challenging due to the similar appearance of camouflaged objects and their surroundings. Research in biology suggests that depth can provide useful object localization cues for camouflaged object discovery, as all the animals have 3D perception ability. However, the depth information has not been exploited for camouflaged object detection. To explore the contribution of depth for camouflage detection, we present a depth-guided camouflaged object detection network with pre-computed depth maps from existing monocular depth estimation methods. Due to the domain gap between the depth estimation dataset and our camouflaged object detection dataset, the generated depth may not be accurate enough to be directly used in our framework. We then introduce a depth quality assessment module to evaluate the quality of depth based on the model prediction from both RGB COD branch and RGB-D COD branch. During training, only high-quality depth is used to update the modal interaction module for multi-modal learning. During testing, our depth quality assessment module can effectively determine the contribution of depth and select the RGB branch or RGB-D branch for camouflage prediction. Extensive experiments on various camouflaged object detection datasets prove the effectiveness of our solution in exploring the depth information for camouflaged object detection. Our code and data is publicly available at: \url{https://github.com/JingZhang617/RGBD-COD}.