 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Uncertainty-Guided Composed Image Retrieval with Fine-Grained Probabilistic Learning
Jan 16, 2026Composed Image Retrieval (CIR) enables image search by combining a reference image with modification text. Intrinsic noise in CIR triplets incurs intrinsic uncertainty and threatens the model's robustness. Probabilistic learning approaches have shown promise in addressing such issues; however, they fall short for CIR due to their instance-level holistic modeling and homogeneous treatment of queries and targets. This paper introduces a Heterogeneous Uncertainty-Guided (HUG) paradigm to overcome these limitations. HUG utilizes a fine-grained probabilistic learning framework, where queries and targets are represented by Gaussian embeddings that capture detailed concepts and uncertainties. We customize heterogeneous uncertainty estimations for multi-modal queries and uni-modal targets. Given a query, we capture uncertainties not only regarding uni-modal content quality but also multi-modal coordination, followed by a provable dynamic weighting mechanism to derive comprehensive query uncertainty. We further design uncertainty-guided objectives, including query-target holistic contrast and fine-grained contrasts with comprehensive negative sampling strategies, which effectively enhance discriminative learning. Experiments on benchmarks demonstrate HUG's effectiveness beyond state-of-the-art baselines, with faithful analysis justifying the technical contributions.
Effectively Enhancing Vision Language Large Models by Prompt Augmentation and Caption Utilization
Sep 22, 2024Recent studies have shown that Vision Language Large Models (VLLMs) may output content not relevant to the input images. This problem, called the hallucination phenomenon, undoubtedly degrades VLLM performance. Therefore, various anti-hallucination techniques have been proposed to make model output more reasonable and accurate. Despite their successes, from extensive tests we found that augmenting the prompt (e.g. word appending, rewriting, and spell error etc.) may change model output and make the output hallucinate again. To cure this drawback, we propose a new instruct-tuning framework called Prompt Augmentation and Caption Utilization (PACU) to boost VLLM's generation ability under the augmented prompt scenario. Concretely, on the one hand, PACU exploits existing LLMs to augment and evaluate diverse prompts automatically. The resulting high-quality prompts are utilized to enhance VLLM's ability to process different prompts. On the other hand, PACU exploits image captions to jointly work with image features as well as the prompts for response generation. When the visual feature is inaccurate, LLM can capture useful information from the image captions for response generation. Extensive experiments on hallucination evaluation and prompt-augmented datasets demonstrate that our PACU method can work well with existing schemes to effectively boost VLLM model performance. Code is available in https://github.com/zhaominyiz/PACU.
One Model for Two Tasks: Cooperatively Recognizing and Recovering Low-Resolution Scene Text Images by Iterative Mutual Guidance
Sep 22, 2024Scene text recognition (STR) from high-resolution (HR) images has been significantly successful, however text reading on low-resolution (LR) images is still challenging due to insufficient visual information. Therefore, recently many scene text image super-resolution (STISR) models have been proposed to generate super-resolution (SR) images for the LR ones, then STR is done on the SR images, which thus boosts recognition performance. Nevertheless, these methods have two major weaknesses. On the one hand, STISR approaches may generate imperfect or even erroneous SR images, which mislead the subsequent recognition of STR models. On the other hand, as the STISR and STR models are jointly optimized, to pursue high recognition accuracy, the fidelity of SR images may be spoiled. As a result, neither the recognition performance nor the fidelity of STISR models are desirable. Then, can we achieve both high recognition performance and good fidelity? To this end, in this paper we propose a novel method called IMAGE (the abbreviation of Iterative MutuAl GuidancE) to effectively recognize and recover LR scene text images simultaneously. Concretely, IMAGE consists of a specialized STR model for recognition and a tailored STISR model to recover LR images, which are optimized separately. And we develop an iterative mutual guidance mechanism, with which the STR model provides high-level semantic information as clue to the STISR model for better super-resolution, meanwhile the STISR model offers essential low-level pixel clue to the STR model for more accurate recognition. Extensive experiments on two LR datasets demonstrate the superiority of our method over the existing works on both recognition performance and super-resolution fidelity.
CIEM: Contrastive Instruction Evaluation Method for Better Instruction Tuning
Sep 05, 2023



Nowadays, the research on Large Vision-Language Models (LVLMs) has been significantly promoted thanks to the success of Large Language Models (LLM). Nevertheless, these Vision-Language Models (VLMs) are suffering from the drawback of hallucination -- due to insufficient understanding of vision and language modalities, VLMs may generate incorrect perception information when doing downstream applications, for example, captioning a non-existent entity. To address the hallucination phenomenon, on the one hand, we introduce a Contrastive Instruction Evaluation Method (CIEM), which is an automatic pipeline that leverages an annotated image-text dataset coupled with an LLM to generate factual/contrastive question-answer pairs for the evaluation of the hallucination of VLMs. On the other hand, based on CIEM, we further propose a new instruction tuning method called CIT (the abbreviation of Contrastive Instruction Tuning) to alleviate the hallucination of VLMs by automatically producing high-quality factual/contrastive question-answer pairs and corresponding justifications for model tuning. Through extensive experiments on CIEM and CIT, we pinpoint the hallucination issues commonly present in existing VLMs, the disability of the current instruction-tuning dataset to handle the hallucination phenomenon and the superiority of CIT-tuned VLMs over both CIEM and public datasets.
Privacy-Preserving Face Recognition Using Random Frequency Components
Aug 21, 2023



The ubiquitous use of face recognition has sparked increasing privacy concerns, as unauthorized access to sensitive face images could compromise the information of individuals. This paper presents an in-depth study of the privacy protection of face images' visual information and against recovery. Drawing on the perceptual disparity between humans and models, we propose to conceal visual information by pruning human-perceivable low-frequency components. For impeding recovery, we first elucidate the seeming paradox between reducing model-exploitable information and retaining high recognition accuracy. Based on recent theoretical insights and our observation on model attention, we propose a solution to the dilemma, by advocating for the training and inference of recognition models on randomly selected frequency components. We distill our findings into a novel privacy-preserving face recognition method, PartialFace. Extensive experiments demonstrate that PartialFace effectively balances privacy protection goals and recognition accuracy. Code is available at: https://github.com/Tencent/TFace.
HiREN: Towards Higher Supervision Quality for Better Scene Text Image Super-Resolution
Jul 31, 2023



Scene text image super-resolution (STISR) is an important pre-processing technique for text recognition from low-resolution scene images. Nowadays, various methods have been proposed to extract text-specific information from high-resolution (HR) images to supervise STISR model training. However, due to uncontrollable factors (e.g. shooting equipment, focus, and environment) in manually photographing HR images, the quality of HR images cannot be guaranteed, which unavoidably impacts STISR performance. Observing the quality issue of HR images, in this paper we propose a novel idea to boost STISR by first enhancing the quality of HR images and then using the enhanced HR images as supervision to do STISR. Concretely, we develop a new STISR framework, called High-Resolution ENhancement (HiREN) that consists of two branches and a quality estimation module. The first branch is developed to recover the low-resolution (LR) images, and the other is an HR quality enhancement branch aiming at generating high-quality (HQ) text images based on the HR images to provide more accurate supervision to the LR images. As the degradation from HQ to HR may be diverse, and there is no pixel-level supervision for HQ image generation, we design a kernel-guided enhancement network to handle various degradation, and exploit the feedback from a recognizer and text-level annotations as weak supervision signal to train the HR enhancement branch. Then, a quality estimation module is employed to evaluate the qualities of HQ images, which are used to suppress the erroneous supervision information by weighting the loss of each image. Extensive experiments on TextZoom show that HiREN can work well with most existing STISR methods and significantly boost their performances.
Keyword-Based Diverse Image Retrieval by Semantics-aware Contrastive Learning and Transformer
May 06, 2023



In addition to relevance, diversity is an important yet less studied performance metric of cross-modal image retrieval systems, which is critical to user experience. Existing solutions for diversity-aware image retrieval either explicitly post-process the raw retrieval results from standard retrieval systems or try to learn multi-vector representations of images to represent their diverse semantics. However, neither of them is good enough to balance relevance and diversity. On the one hand, standard retrieval systems are usually biased to common semantics and seldom exploit diversity-aware regularization in training, which makes it difficult to promote diversity by post-processing. On the other hand, multi-vector representation methods are not guaranteed to learn robust multiple projections. As a result, irrelevant images and images of rare or unique semantics may be projected inappropriately, which degrades the relevance and diversity of the results generated by some typical algorithms like top-k. To cope with these problems, this paper presents a new method called CoLT that tries to generate much more representative and robust representations for accurately classifying images. Specifically, CoLT first extracts semantics-aware image features by enhancing the preliminary representations of an existing one-to-one cross-modal system with semantics-aware contrastive learning. Then, a transformer-based token classifier is developed to subsume all the features into their corresponding categories. Finally, a post-processing algorithm is designed to retrieve images from each category to form the final retrieval result. Extensive experiments on two real-world datasets Div400 and Div150Cred show that CoLT can effectively boost diversity, and outperforms the existing methods as a whole (with a higher F1 score).
C3-STISR: Scene Text Image Super-resolution with Triple Clues
Apr 29, 2022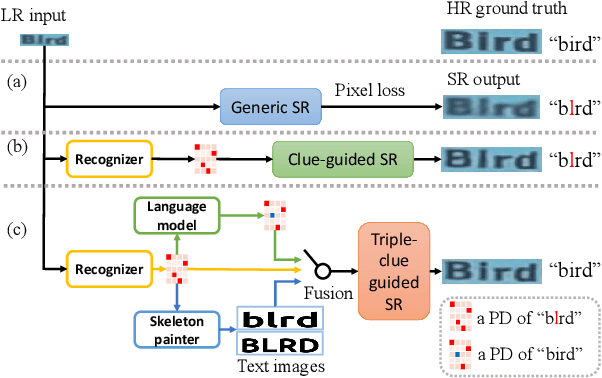
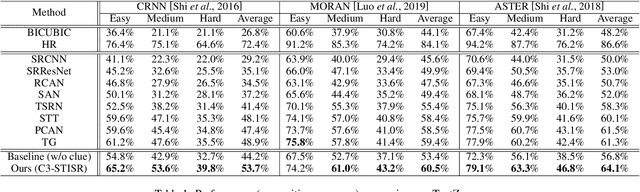
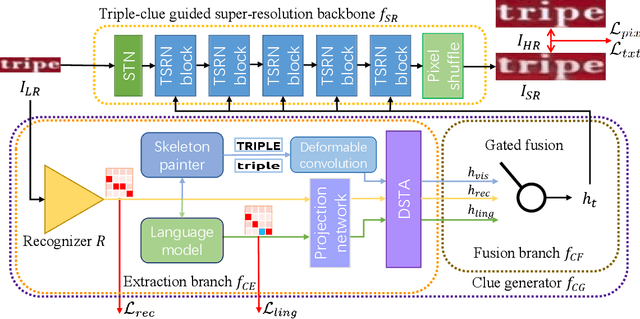
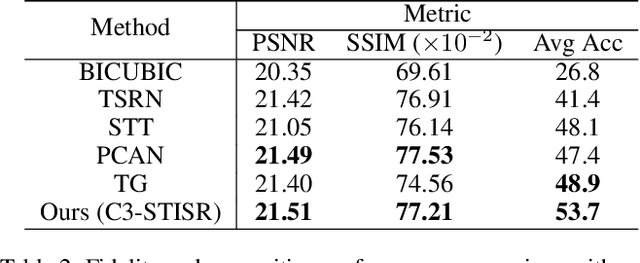
Scene text image super-resolution (STISR) has been regarded as an important pre-processing task for text recognition from low-resolution scene text images. Most recent approaches use the recognizer's feedback as clues to guide super-resolution. However, directly using recognition clue has two problems: 1) Compatibility. It is in the form of probability distribution, has an obvious modal gap with STISR - a pixel-level task; 2) Inaccuracy. it usually contains wrong information, thus will mislead the main task and degrade super-resolution performance. In this paper, we present a novel method C3-STISR that jointly exploits the recognizer's feedback, visual and linguistical information as clues to guide super-resolution. Here, visual clue is from the images of texts predicted by the recognizer, which is informative and more compatible with the STISR task; while linguistical clue is generated by a pre-trained character-level language model, which is able to correct the predicted texts. We design effective extraction and fusion mechanisms for the triple cross-modal clues to generate a comprehensive and unified guidance for super-resolution. Extensive experiments on TextZoom show that C3-STISR outperforms the SOTA methods in fidelity and recognition performance. Code is available in https://github.com/zhaominyiz/C3-STISR.
EPiDA: An Easy Plug-in Data Augmentation Framework for High Performance Text Classification
Apr 24, 2022
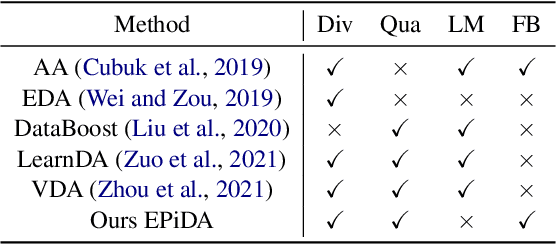

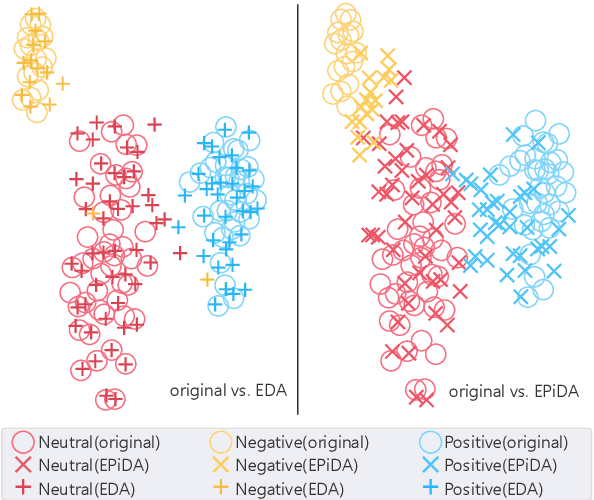
Recent works have empirically shown the effectiveness of data augmentation (DA) in NLP tasks, especially for those suffering from data scarcity. Intuitively, given the size of generated data, their diversity and quality are crucial to the performance of targeted tasks. However, to the best of our knowledge, most existing methods consider only either the diversity or the quality of augmented data, thus cannot fully mine the potential of DA for NLP. In this paper, we present an easy and plug-in data augmentation framework EPiDA to support effective text classification. EPiDA employs two mechanisms: relative entropy maximization (REM) and conditional entropy minimization (CEM) to control data generation, where REM is designed to enhance the diversity of augmented data while CEM is exploited to ensure their semantic consistency. EPiDA can support efficient and continuous data generation for effective classifier training. Extensive experiments show that EPiDA outperforms existing SOTA methods in most cases, though not using any agent networks or pre-trained generation networks, and it works well with various DA algorithms and classification models. Code is available at https://github.com/zhaominyiz/EPiDA.
Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
Aug 12, 2021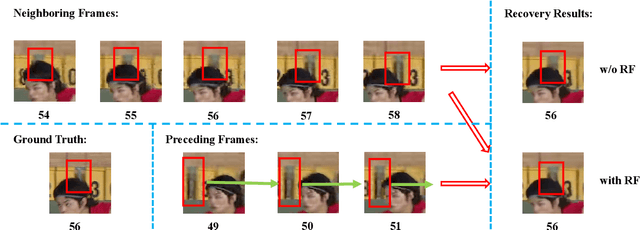
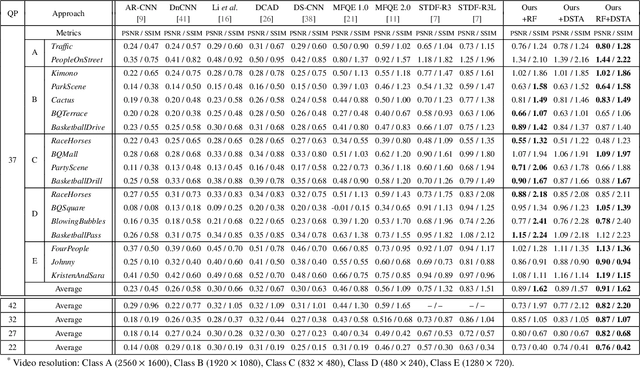
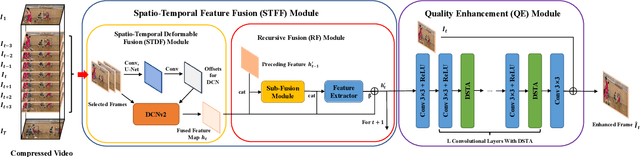
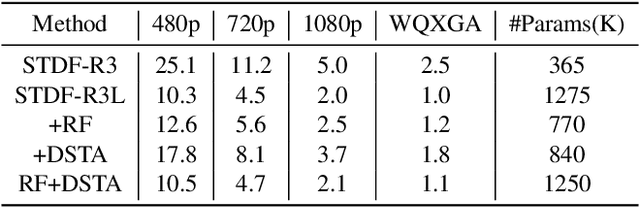
A number of deep learning based algorithms have been proposed to recover high-quality videos from low-quality compressed ones. Among them, some restore the missing details of each frame via exploring the spatiotemporal information of neighboring frames. However, these methods usually suffer from a narrow temporal scope, thus may miss some useful details from some frames outside the neighboring ones. In this paper, to boost artifact removal, on the one hand, we propose a Recursive Fusion (RF) module to model the temporal dependency within a long temporal range. Specifically, RF utilizes both the current reference frames and the preceding hidden state to conduct better spatiotemporal compensation. On the other hand, we design an efficient and effective Deformable Spatiotemporal Attention (DSTA) module such that the model can pay more effort on restoring the artifact-rich areas like the boundary area of a moving object. Extensive experiments show that our method outperforms the existing ones on the MFQE 2.0 dataset in terms of both fidelity and perceptual effect. Code is available at https://github.com/zhaominyiz/RFDA-PyTorch.