 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Vision-Language-Action Models for Embodied Manipulation
Aug 21, 2025Embodied intelligence systems, which enhance agent capabilities through continuous environment interactions, have garnered significant attention from both academia and industry. Vision-Language-Action models, inspired by advancements in large foundation models, serve as universal robotic control frameworks that substantially improve agent-environment interaction capabilities in embodied intelligence systems. This expansion has broadened application scenarios for embodied AI robots. This survey comprehensively reviews VLA models for embodied manipulation. Firstly, it chronicles the developmental trajectory of VLA architectures. Subsequently, we conduct a detailed analysis of current research across 5 critical dimensions: VLA model structures, training datasets, pre-training methods, post-training methods, and model evaluation. Finally, we synthesize key challenges in VLA development and real-world deployment, while outlining promising future research directions.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022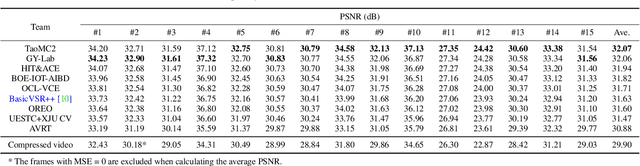
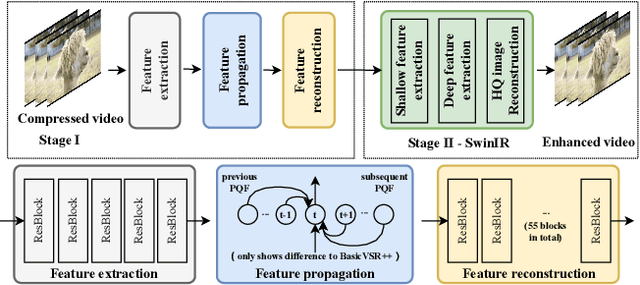
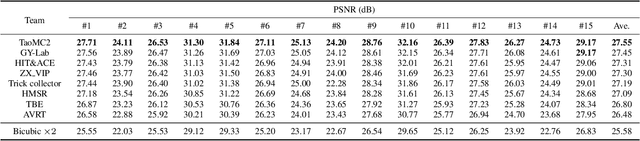

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.