 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model
Jun 17, 2021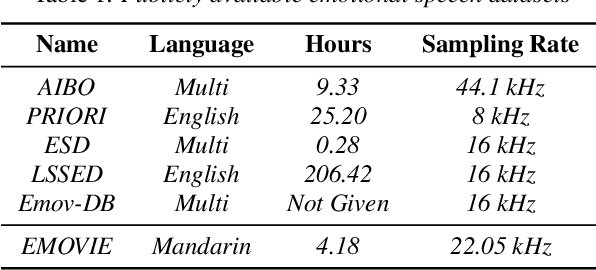
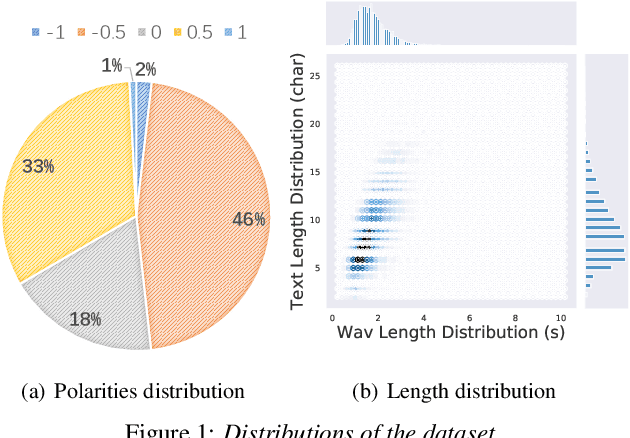

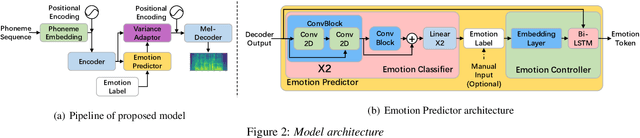
Recently, there has been an increasing interest in neural speech synthesis. While the deep neural network achieves the state-of-the-art result in text-to-speech (TTS) tasks, how to generate a more emotional and more expressive speech is becoming a new challenge to researchers due to the scarcity of high-quality emotion speech dataset and the lack of advanced emotional TTS model. In this paper, we first briefly introduce and publicly release a Mandarin emotion speech dataset including 9,724 samples with audio files and its emotion human-labeled annotation. After that, we propose a simple but efficient architecture for emotional speech synthesis called EMSpeech. Unlike those models which need additional reference audio as input, our model could predict emotion labels just from the input text and generate more expressive speech conditioned on the emotion embedding. In the experiment phase, we first validate the effectiveness of our dataset by an emotion classification task. Then we train our model on the proposed dataset and conduct a series of subjective evaluations. Finally, by showing a comparable performance in the emotional speech synthesis task, we successfully demonstrate the ability of the proposed model.
Extremely Low Footprint End-to-End ASR System for Smart Device
Apr 26, 2021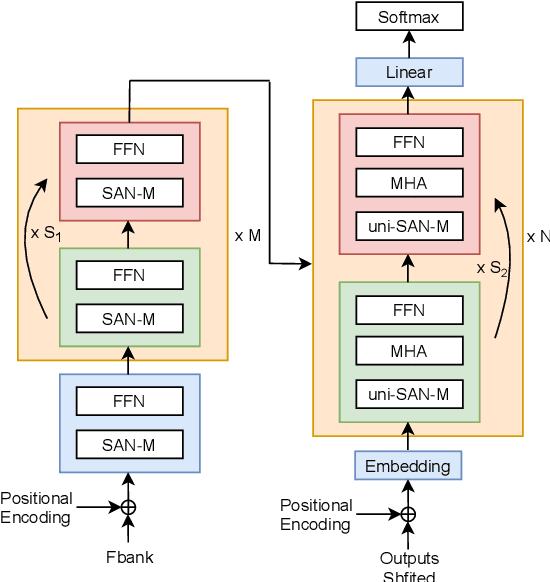
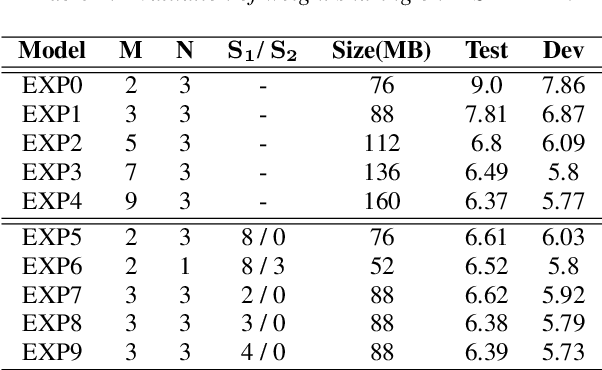
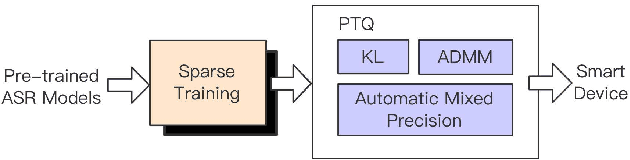
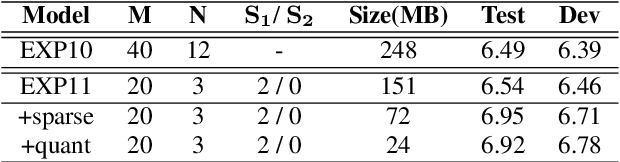
Recently, end-to-end (E2E) speech recognition has become popular, since it can integrate the acoustic, pronunciation and language models into a single neural network, as well as outperforms conventional models. Among E2E approaches, attention-based models, $e.g.$ Transformer, have emerged as being superior. The E2E models have opened the door of deployment of ASR on smart device, however it still suffers from large amount model parameters. This work proposes an extremely low footprint E2E ASR system for smart device, to achieve the goal of satisfying resource constraints without sacrificing recognition accuracy. We adopt cross-layer weight sharing to improve parameter-efficiency. We further exploit the model compression methods including sparsification and quantization, to reduce the memory storage and boost the decoding efficiency on smart device. We have evaluated our approach on the public AISHELL-1 and AISHELL-2 benchmarks. On the AISHELL-2 task, the proposed method achieves more than 10x compression (model size from 248MB to 24MB) while shuffer from small performance loss (CER from 6.49% to 6.92%).
A PDD Decoder for Binary Linear Codes With Neural Check Polytope Projection
Jun 11, 2020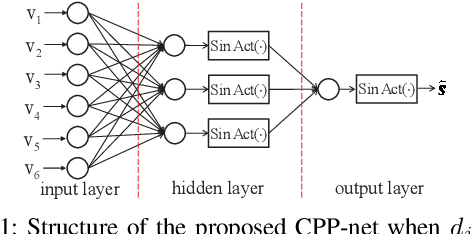
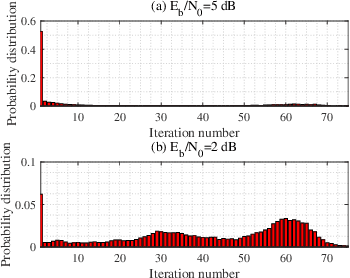
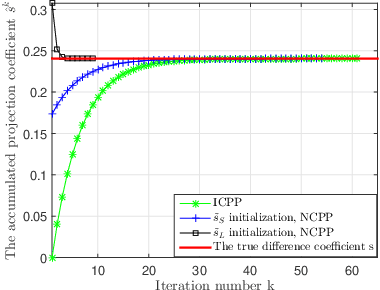
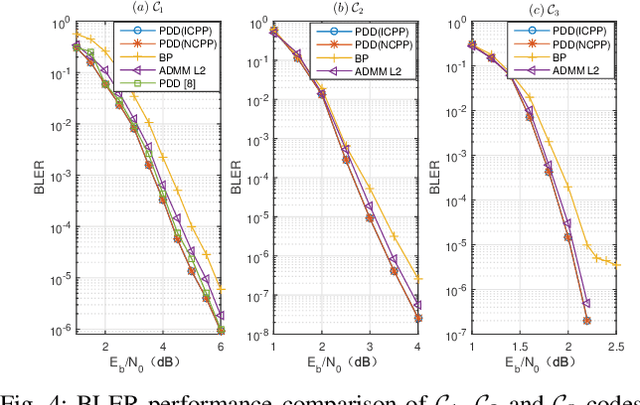
Linear Programming (LP) is an important decoding technique for binary linear codes. However, the advantages of LP decoding, such as low error floor and strong theoretical guarantee, etc., come at the cost of high computational complexity and poor performance at the low signal-to-noise ratio (SNR) region. In this letter, we adopt the penalty dual decomposition (PDD) framework and propose a PDD algorithm to address the fundamental polytope based maximum likelihood (ML) decoding problem. Furthermore, we propose to integrate machine learning techniques into the most time-consuming part of the PDD decoding algorithm, i.e., check polytope projection (CPP). Inspired by the fact that a multi-layer perception (MLP) can theoretically approximate any nonlinear mapping function, we present a specially designed neural CPP (NCPP) algorithm to decrease the decoding latency. Simulation results demonstrate the effectiveness of the proposed algorithms.
Simplified Self-Attention for Transformer-based End-to-End Speech Recognition
May 21, 2020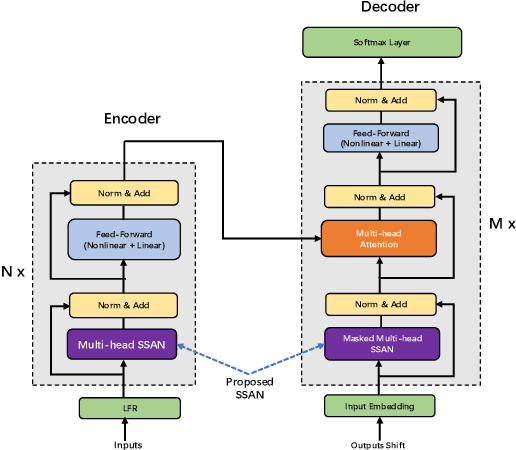
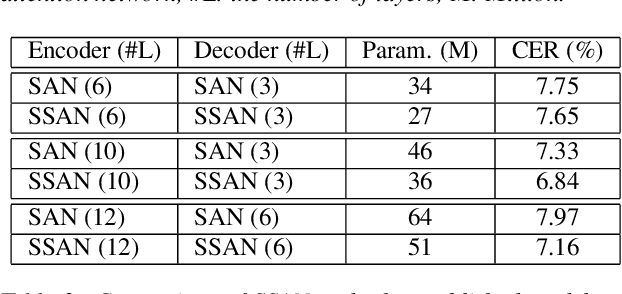
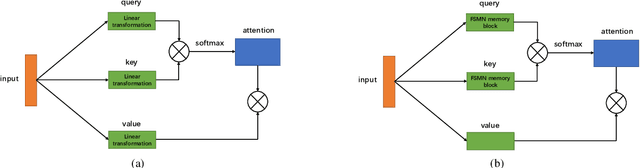
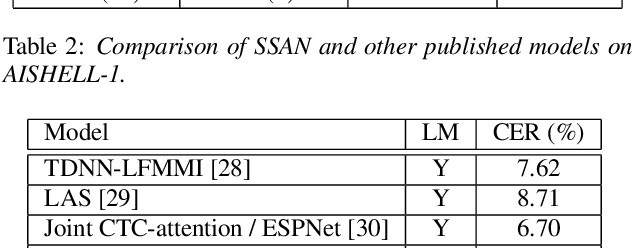
Transformer models have been introduced into end-to-end speech recognition with state-of-the-art performance on various tasks owing to their superiority in modeling long-term dependencies. However, such improvements are usually obtained through the use of very large neural networks. Transformer models mainly include two submodules - position-wise feedforward layers and self-attention (SAN) layers. In this paper, to reduce the model complexity while maintaining good performance, we propose a simplified self-attention (SSAN) layer which employs FSMN memory block instead of projection layers to form query and key vectors for transformer-based end-to-end speech recognition. We evaluate the SSAN-based and the conventional SAN-based transformers on the public AISHELL-1, internal 1000-hour and 20,000-hour large-scale Mandarin tasks. Results show that our proposed SSAN-based transformer model can achieve over 20% relative reduction in model parameters and 6.7% relative CER reduction on the AISHELL-1 task. With impressively 20% parameter reduction, our model shows no loss of recognition performance on the 20,000-hour large-scale task.
ADMM-based Decoder for Binary Linear Codes Aided by Deep Learning
Feb 14, 2020
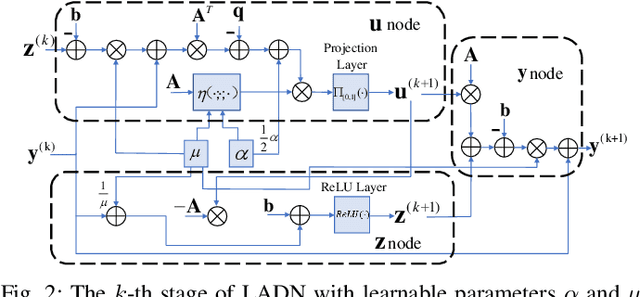
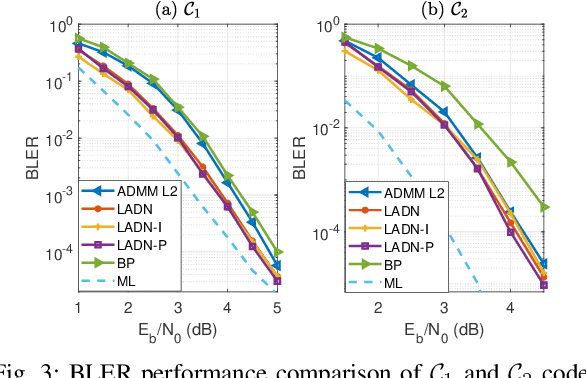
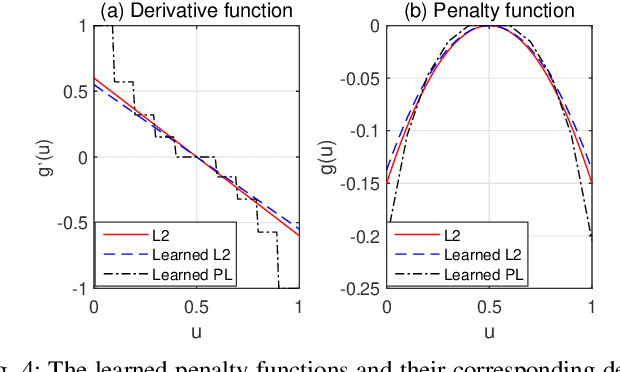
Inspired by the recent advances in deep learning (DL), this work presents a deep neural network aided decoding algorithm for binary linear codes. Based on the concept of deep unfolding, we design a decoding network by unfolding the alternating direction method of multipliers (ADMM)-penalized decoder. In addition, we propose two improved versions of the proposed network. The first one transforms the penalty parameter into a set of iteration-dependent ones, and the second one adopts a specially designed penalty function, which is based on a piecewise linear function with adjustable slopes. Numerical results show that the resulting DL-aided decoders outperform the original ADMM-penalized decoder for various low density parity check (LDPC) codes with similar computational complexity.
Learned Conjugate Gradient Descent Network for Massive MIMO Detection
Jun 11, 2019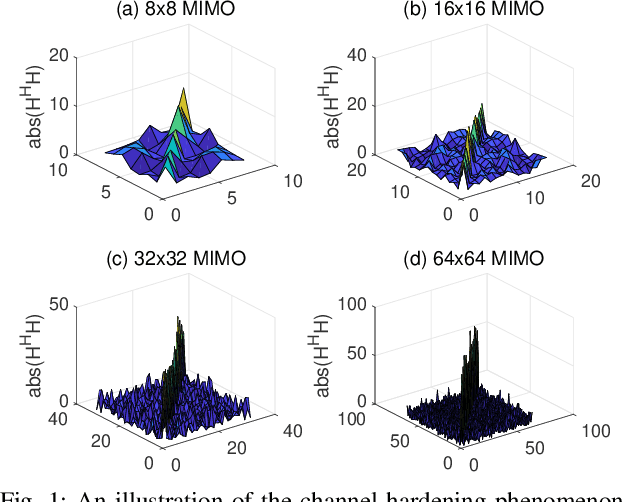
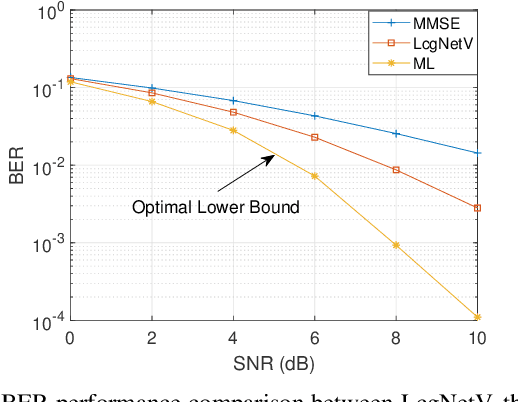
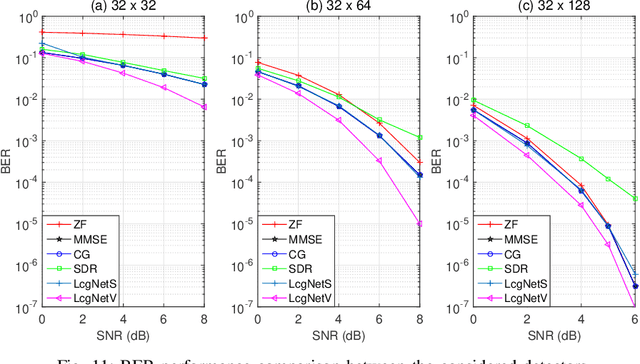
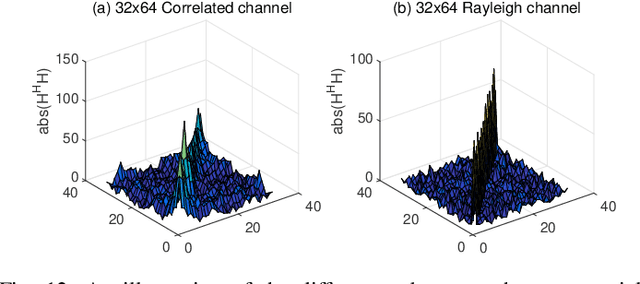
In this work, we consider the use of model-driven deep learning techniques for massive multiple-input multiple-output (MIMO) detection. Compared with conventional MIMO systems, massive MIMO promises improved spectral efficiency, coverage and range. Unfortunately, these benefits are coming at the cost of significantly increased computational complexity. To reduce the complexity of signal detection and guarantee the performance, we present a learned conjugate gradient descent network (LcgNet), which is constructed by unfolding the iterative conjugate gradient descent (CG) detector. In the proposed network, instead of calculating the exact values of the scalar step-sizes, we explicitly learn their universal values. Also, we can enhance the proposed network by augmenting the dimensions of these step-sizes. Furthermore, in order to reduce the memory costs, a novel quantized LcgNet is proposed, where a low-resolution nonuniform quantizer is integrated into the LcgNet to smartly quantize the aforementioned step-sizes. The quantizer is based on a specially designed soft staircase function with learnable parameters to adjust its shape. Meanwhile, due to fact that the number of learnable parameters is limited, the proposed networks are easy and fast to train. Numerical results demonstrate that the proposed network can achieve promising performance with much lower complexity.
Automatic Spelling Correction with Transformer for CTC-based End-to-End Speech Recognition
Mar 27, 2019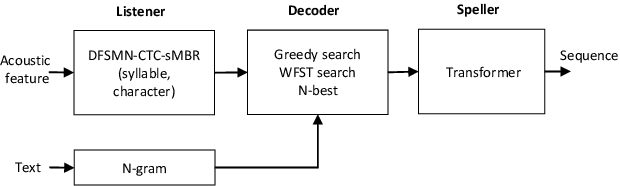

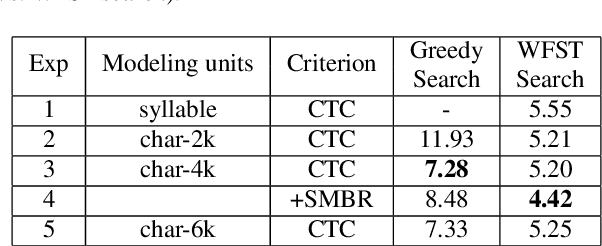
Connectionist Temporal Classification (CTC) based end-to-end speech recognition system usually need to incorporate an external language model by using WFST-based decoding in order to achieve promising results. This is more essential to Mandarin speech recognition since it owns a special phenomenon, namely homophone, which causes a lot of substitution errors. The linguistic information introduced by language model will help to distinguish these substitution errors. In this work, we propose a transformer based spelling correction model to automatically correct errors especially the substitution errors made by CTC-based Mandarin speech recognition system. Specifically, we investigate using the recognition results generated by CTC-based systems as input and the ground-truth transcriptions as output to train a transformer with encoder-decoder architecture, which is much similar to machine translation. Results in a 20,000 hours Mandarin speech recognition task show that the proposed spelling correction model can achieve a CER of 3.41%, which results in 22.9% and 53.2% relative improvement compared to the baseline CTC-based systems decoded with and without language model respectively.
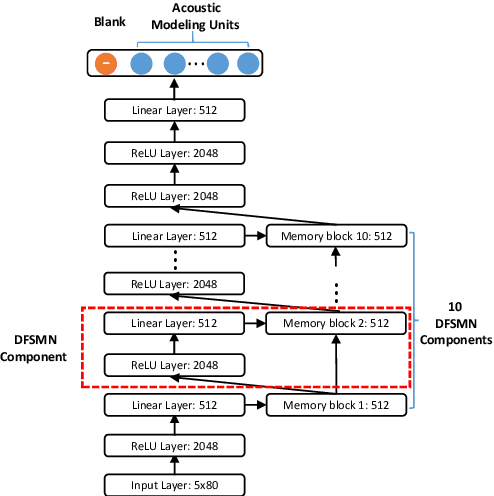
Deep-FSMN for Large Vocabulary Continuous Speech Recognition
Mar 04, 2018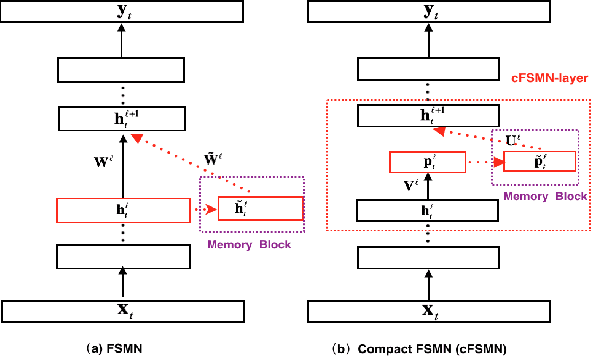
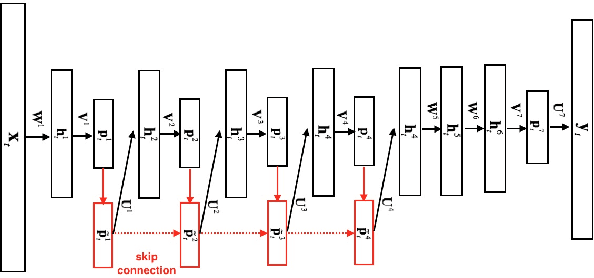
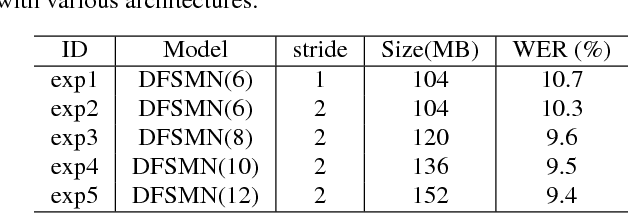
In this paper, we present an improved feedforward sequential memory networks (FSMN) architecture, namely Deep-FSMN (DFSMN), by introducing skip connections between memory blocks in adjacent layers. These skip connections enable the information flow across different layers and thus alleviate the gradient vanishing problem when building very deep structure. As a result, DFSMN significantly benefits from these skip connections and deep structure. We have compared the performance of DFSMN to BLSTM both with and without lower frame rate (LFR) on several large speech recognition tasks, including English and Mandarin. Experimental results shown that DFSMN can consistently outperform BLSTM with dramatic gain, especially trained with LFR using CD-Phone as modeling units. In the 2000 hours Fisher (FSH) task, the proposed DFSMN can achieve a word error rate of 9.4% by purely using the cross-entropy criterion and decoding with a 3-gram language model, which achieves a 1.5% absolute improvement compared to the BLSTM. In a 20000 hours Mandarin recognition task, the LFR trained DFSMN can achieve more than 20% relative improvement compared to the LFR trained BLSTM. Moreover, we can easily design the lookahead filter order of the memory blocks in DFSMN to control the latency for real-time applications.
Deep Feed-forward Sequential Memory Networks for Speech Synthesis
Feb 26, 2018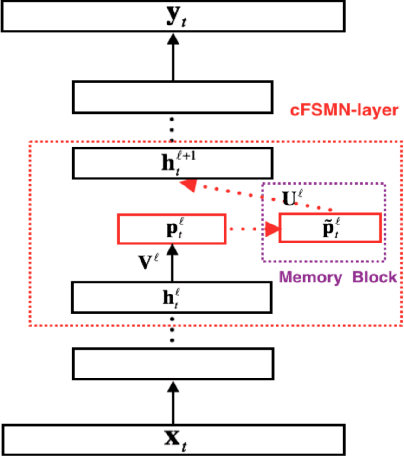
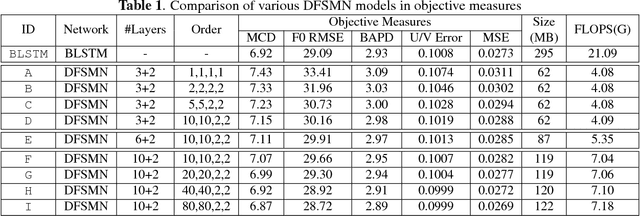
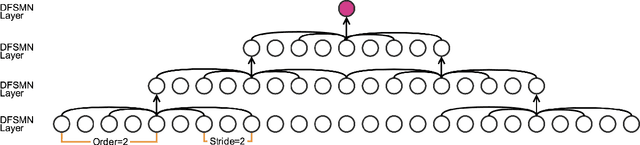
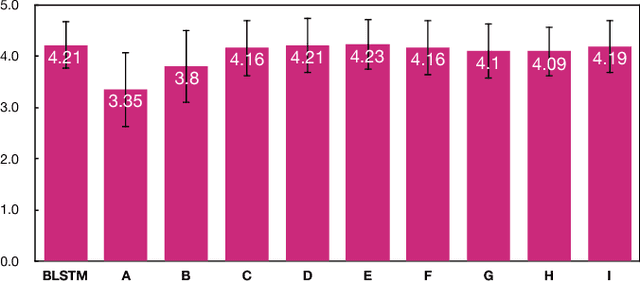
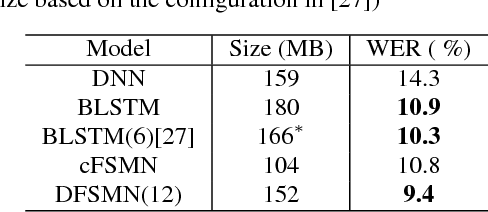
The Bidirectional LSTM (BLSTM) RNN based speech synthesis system is among the best parametric Text-to-Speech (TTS) systems in terms of the naturalness of generated speech, especially the naturalness in prosody. However, the model complexity and inference cost of BLSTM prevents its usage in many runtime applications. Meanwhile, Deep Feed-forward Sequential Memory Networks (DFSMN) has shown its consistent out-performance over BLSTM in both word error rate (WER) and the runtime computation cost in speech recognition tasks. Since speech synthesis also requires to model long-term dependencies compared to speech recognition, in this paper, we investigate the Deep-FSMN (DFSMN) in speech synthesis. Both objective and subjective experiments show that, compared with BLSTM TTS method, the DFSMN system can generate synthesized speech with comparable speech quality while drastically reduce model complexity and speech generation time.
Data preprocessing methods for robust Fourier ptychographic microscopy
Jun 04, 2017Fourier ptychographic microscopy (FPM) is a recently proposed computational imaging technique with both high resolution and wide field-of-view. In current FP experimental setup, the dark-field images with high-angle illuminations are easily submerged by stray light and background noise due to the low signal-to-noise ratio, thus significantly degrading the reconstruction quality and also imposing a major restriction on the synthetic numerical aperture (NA) of the FP approach. To this end, an overall and systematic data preprocessing scheme for noise removal from FP's raw dataset is provided, which involves sampling analysis as well as underexposed/overexposed treatments, then followed by the elimination of unknown stray light and suppression of inevitable background noise, especially Gaussian noise and CCD dark current in our experiments. The reported non-parametric scheme facilitates great enhancements of the FP's performance, which has been demonstrated experimentally that the benefits of noise removal by these methods far outweigh its defects of concomitant signal loss. In addition, it could be flexibly cooperated with the existing state-of-the-art algorithms, producing a stronger robustness of the FP approach in various applications.
* 7 pages, 8 figures