 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Episodes and Semantics: A Novel Framework for Long-Form Video Understanding
Aug 30, 2024



While existing research often treats long-form videos as extended short videos, we propose a novel approach that more accurately reflects human cognition. This paper introduces BREASE: BRidging Episodes And SEmantics for Long-Form Video Understanding, a model that simulates episodic memory accumulation to capture action sequences and reinforces them with semantic knowledge dispersed throughout the video. Our work makes two key contributions: First, we develop an Episodic COmpressor (ECO) that efficiently aggregates crucial representations from micro to semi-macro levels. Second, we propose a Semantics reTRiever (SeTR) that enhances these aggregated representations with semantic information by focusing on the broader context, dramatically reducing feature dimensionality while preserving relevant macro-level information. Extensive experiments demonstrate that BREASE achieves state-of-the-art performance across multiple long video understanding benchmarks in both zero-shot and fully-supervised settings. The project page and code are at: https://joslefaure.github.io/assets/html/hermes.html.
Spatio-Temporal Context Prompting for Zero-Shot Action Detection
Aug 29, 2024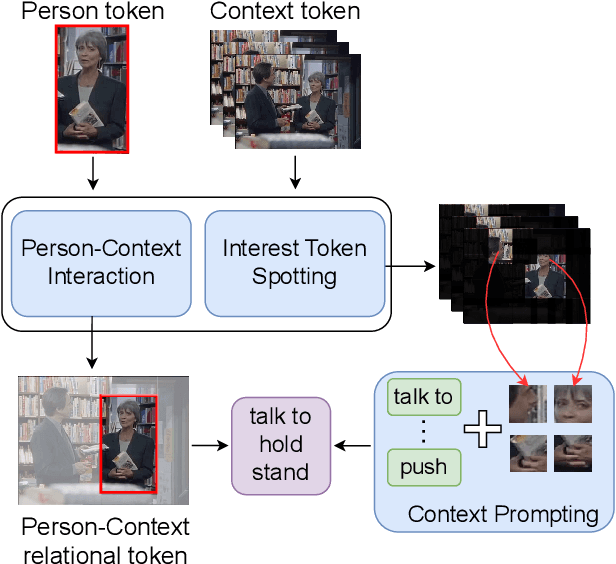
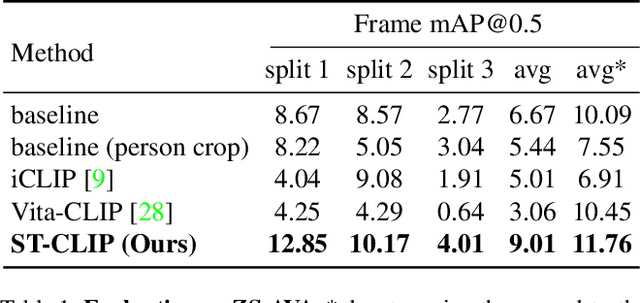
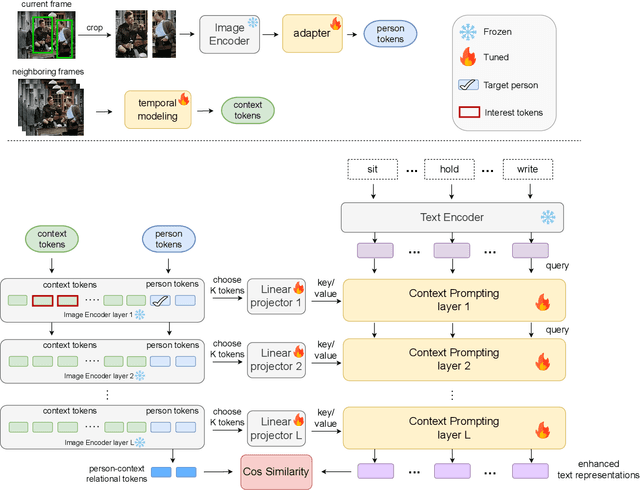
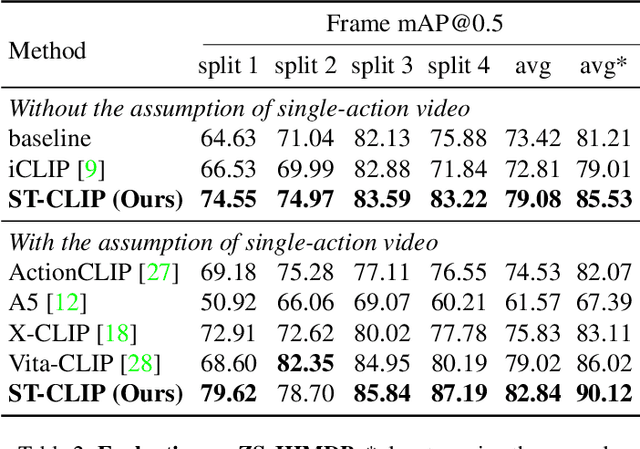
Spatio-temporal action detection encompasses the tasks of localizing and classifying individual actions within a video. Recent works aim to enhance this process by incorporating interaction modeling, which captures the relationship between people and their surrounding context. However, these approaches have primarily focused on fully-supervised learning, and the current limitation lies in the lack of generalization capability to recognize unseen action categories. In this paper, we aim to adapt the pretrained image-language models to detect unseen actions. To this end, we propose a method which can effectively leverage the rich knowledge of visual-language models to perform Person-Context Interaction. Meanwhile, our Context Prompting module will utilize contextual information to prompt labels, thereby enhancing the generation of more representative text features. Moreover, to address the challenge of recognizing distinct actions by multiple people at the same timestamp, we design the Interest Token Spotting mechanism which employs pretrained visual knowledge to find each person's interest context tokens, and then these tokens will be used for prompting to generate text features tailored to each individual. To evaluate the ability to detect unseen actions, we propose a comprehensive benchmark on J-HMDB, UCF101-24, and AVA datasets. The experiments show that our method achieves superior results compared to previous approaches and can be further extended to multi-action videos, bringing it closer to real-world applications. The code and data can be found in https://webber2933.github.io/ST-CLIP-project-page.
SANER: Annotation-free Societal Attribute Neutralizer for Debiasing CLIP
Aug 19, 2024Large-scale vision-language models, such as CLIP, are known to contain harmful societal bias regarding protected attributes (e.g., gender and age). In this paper, we aim to address the problems of societal bias in CLIP. Although previous studies have proposed to debias societal bias through adversarial learning or test-time projecting, our comprehensive study of these works identifies two critical limitations: 1) loss of attribute information when it is explicitly disclosed in the input and 2) use of the attribute annotations during debiasing process. To mitigate societal bias in CLIP and overcome these limitations simultaneously, we introduce a simple-yet-effective debiasing method called SANER (societal attribute neutralizer) that eliminates attribute information from CLIP text features only of attribute-neutral descriptions. Experimental results show that SANER, which does not require attribute annotations and preserves original information for attribute-specific descriptions, demonstrates superior debiasing ability than the existing methods.
GroPrompt: Efficient Grounded Prompting and Adaptation for Referring Video Object Segmentation
Jun 18, 2024



Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence throughout the entire video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we aim to efficiently adapt foundation segmentation models for addressing RVOS from weak supervision with the proposed Grounded Prompting (GroPrompt) framework. More specifically, we propose Text-Aware Prompt Contrastive Learning (TAP-CL) to enhance the association between the position prompts and the referring sentences with only box supervisions, including Text-Contrastive Prompt Learning (TextCon) and Modality-Contrastive Prompt Learning (ModalCon) at frame level and video level, respectively. With the proposed TAP-CL, our GroPrompt framework can generate temporal-consistent yet text-aware position prompts describing locations and movements for the referred object from the video. The experimental results in the standard RVOS benchmarks (Ref-YouTube-VOS, Ref-DAVIS17, A2D-Sentences, and JHMDB-Sentences) demonstrate the competitive performance of our proposed GroPrompt framework given only bounding box weak supervisions.
Diffusion-Reward Adversarial Imitation Learning
May 25, 2024



Imitation learning aims to learn a policy from observing expert demonstrations without access to reward signals from environments. Generative adversarial imitation learning (GAIL) formulates imitation learning as adversarial learning, employing a generator policy learning to imitate expert behaviors and discriminator learning to distinguish the expert demonstrations from agent trajectories. Despite its encouraging results, GAIL training is often brittle and unstable. Inspired by the recent dominance of diffusion models in generative modeling, this work proposes Diffusion-Reward Adversarial Imitation Learning (DRAIL), which integrates a diffusion model into GAIL, aiming to yield more precise and smoother rewards for policy learning. Specifically, we propose a diffusion discriminative classifier to construct an enhanced discriminator; then, we design diffusion rewards based on the classifier's output for policy learning. We conduct extensive experiments in navigation, manipulation, and locomotion, verifying DRAIL's effectiveness compared to prior imitation learning methods. Moreover, additional experimental results demonstrate the generalizability and data efficiency of DRAIL. Visualized learned reward functions of GAIL and DRAIL suggest that DRAIL can produce more precise and smoother rewards.
Image-Text Co-Decomposition for Text-Supervised Semantic Segmentation
Apr 05, 2024This paper addresses text-supervised semantic segmentation, aiming to learn a model capable of segmenting arbitrary visual concepts within images by using only image-text pairs without dense annotations. Existing methods have demonstrated that contrastive learning on image-text pairs effectively aligns visual segments with the meanings of texts. We notice that there is a discrepancy between text alignment and semantic segmentation: A text often consists of multiple semantic concepts, whereas semantic segmentation strives to create semantically homogeneous segments. To address this issue, we propose a novel framework, Image-Text Co-Decomposition (CoDe), where the paired image and text are jointly decomposed into a set of image regions and a set of word segments, respectively, and contrastive learning is developed to enforce region-word alignment. To work with a vision-language model, we present a prompt learning mechanism that derives an extra representation to highlight an image segment or a word segment of interest, with which more effective features can be extracted from that segment. Comprehensive experimental results demonstrate that our method performs favorably against existing text-supervised semantic segmentation methods on six benchmark datasets.
DoRA: Weight-Decomposed Low-Rank Adaptation
Feb 14, 2024Among the widely used parameter-efficient finetuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis to investigate the inherent differences between FT and LoRA. Aiming to resemble the learning capacity of FT from the findings, we propose Weight-Decomposed LowRank Adaptation (DoRA). DoRA decomposes the pre-trained weight into two components, magnitude and direction, for fine-tuning, specifically employing LoRA for directional updates to efficiently minimize the number of trainable parameters. By employing DoRA, we enhance both the learning capacity and training stability of LoRA while avoiding any additional inference overhead. DoRA consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding.
SemPLeS: Semantic Prompt Learning for Weakly-Supervised Semantic Segmentation
Jan 22, 2024Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models using training image data with only image-level supervision. Since precise pixel-level annotations are not accessible, existing methods typically focus on producing pseudo masks for training segmentation models by refining CAM-like heatmaps. However, the produced heatmaps may only capture discriminative image regions of target object categories or the associated co-occurring backgrounds. To address the issues, we propose a Semantic Prompt Learning for WSSS (SemPLeS) framework, which learns to effectively prompt the CLIP space to enhance the semantic alignment between the segmented regions and the target object categories. More specifically, we propose Contrastive Prompt Learning and Class-associated Semantic Refinement to learn the prompts that adequately describe and suppress the image backgrounds associated with each target object category. In this way, our proposed framework is able to perform better semantic matching between object regions and the associated text labels, resulting in desired pseudo masks for training the segmentation model. The proposed SemPLeS framework achieves SOTA performance on the standard WSSS benchmarks, PASCAL VOC and MS COCO, and demonstrated interpretability with the semantic visualization of our learned prompts. The codes will be released.
PartDistill: 3D Shape Part Segmentation by Vision-Language Model Distillation
Dec 07, 2023This paper proposes a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models (VLMs) to facilitate 3D shape part segmentation. PartDistill addresses three major challenges in this task: the lack of 3D segmentation in invisible or undetected regions in the 2D projections, inaccurate and inconsistent 2D predictions by VLMs, and the lack of knowledge accumulation across different 3D shapes. PartDistill consists of a teacher network that uses a VLM to make 2D predictions and a student network that learns from the 2D predictions while extracting geometrical features from multiple 3D shapes to carry out 3D part segmentation. A bi-directional distillation, including forward and backward distillations, is carried out within the framework, where the former forward distills the 2D predictions to the student network, and the latter improves the quality of the 2D predictions, which subsequently enhances the final 3D part segmentation. Moreover, PartDistill can exploit generative models that facilitate effortless 3D shape creation for generating knowledge sources to be distilled. Through extensive experiments, PartDistill boosts the existing methods with substantial margins on widely used ShapeNetPart and PartE datasets, by more than 15% and 12% higher mIoU scores, respectively.
Conditional Modeling Based Automatic Video Summarization
Nov 20, 2023The aim of video summarization is to shorten videos automatically while retaining the key information necessary to convey the overall story. Video summarization methods mainly rely on visual factors, such as visual consecutiveness and diversity, which may not be sufficient to fully understand the content of the video. There are other non-visual factors, such as interestingness, representativeness, and storyline consistency that should also be considered for generating high-quality video summaries. Current methods do not adequately take into account these non-visual factors, resulting in suboptimal performance. In this work, a new approach to video summarization is proposed based on insights gained from how humans create ground truth video summaries. The method utilizes a conditional modeling perspective and introduces multiple meaningful random variables and joint distributions to characterize the key components of video summarization. Helper distributions are employed to improve the training of the model. A conditional attention module is designed to mitigate potential performance degradation in the presence of multi-modal input. The proposed video summarization method incorporates the above innovative design choices that aim to narrow the gap between human-generated and machine-generated video summaries. Extensive experiments show that the proposed approach outperforms existing methods and achieves state-of-the-art performance on commonly used video summarization datasets.