 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Logical Query Reasoning on any Knowledge Graph
Apr 10, 2024Complex logical query answering (CLQA) in knowledge graphs (KGs) goes beyond simple KG completion and aims at answering compositional queries comprised of multiple projections and logical operations. Existing CLQA methods that learn parameters bound to certain entity or relation vocabularies can only be applied to the graph they are trained on which requires substantial training time before being deployed on a new graph. Here we present UltraQuery, an inductive reasoning model that can zero-shot answer logical queries on any KG. The core idea of UltraQuery is to derive both projections and logical operations as vocabulary-independent functions which generalize to new entities and relations in any KG. With the projection operation initialized from a pre-trained inductive KG reasoning model, UltraQuery can solve CLQA on any KG even if it is only finetuned on a single dataset. Experimenting on 23 datasets, UltraQuery in the zero-shot inference mode shows competitive or better query answering performance than best available baselines and sets a new state of the art on 14 of them.
Graph Foundation Models
Feb 06, 2024



Graph Foundation Model (GFM) is a new trending research topic in the graph domain, aiming to develop a graph model capable of generalizing across different graphs and tasks. However, a versatile GFM has not yet been achieved. The key challenge in building GFM is how to enable positive transfer across graphs with diverse structural patterns. Inspired by the existing foundation models in the CV and NLP domains, we propose a novel perspective for the GFM development by advocating for a "graph vocabulary", in which the basic transferable units underlying graphs encode the invariance on graphs. We ground the graph vocabulary construction from essential aspects including network analysis, theoretical foundations, and stability. Such a vocabulary perspective can potentially advance the future GFM design following the neural scaling laws.
Improving Compositional Generalization Using Iterated Learning and Simplicial Embeddings
Oct 28, 2023Compositional generalization, the ability of an agent to generalize to unseen combinations of latent factors, is easy for humans but hard for deep neural networks. A line of research in cognitive science has hypothesized a process, ``iterated learning,'' to help explain how human language developed this ability; the theory rests on simultaneous pressures towards compressibility (when an ignorant agent learns from an informed one) and expressivity (when it uses the representation for downstream tasks). Inspired by this process, we propose to improve the compositional generalization of deep networks by using iterated learning on models with simplicial embeddings, which can approximately discretize representations. This approach is further motivated by an analysis of compositionality based on Kolmogorov complexity. We show that this combination of changes improves compositional generalization over other approaches, demonstrating these improvements both on vision tasks with well-understood latent factors and on real molecular graph prediction tasks where the latent structure is unknown.
Towards Foundation Models for Knowledge Graph Reasoning
Oct 06, 2023



Foundation models in language and vision have the ability to run inference on any textual and visual inputs thanks to the transferable representations such as a vocabulary of tokens in language. Knowledge graphs (KGs) have different entity and relation vocabularies that generally do not overlap. The key challenge of designing foundation models on KGs is to learn such transferable representations that enable inference on any graph with arbitrary entity and relation vocabularies. In this work, we make a step towards such foundation models and present ULTRA, an approach for learning universal and transferable graph representations. ULTRA builds relational representations as a function conditioned on their interactions. Such a conditioning strategy allows a pre-trained ULTRA model to inductively generalize to any unseen KG with any relation vocabulary and to be fine-tuned on any graph. Conducting link prediction experiments on 57 different KGs, we find that the zero-shot inductive inference performance of a single pre-trained ULTRA model on unseen graphs of various sizes is often on par or better than strong baselines trained on specific graphs. Fine-tuning further boosts the performance.
MatSciML: A Broad, Multi-Task Benchmark for Solid-State Materials Modeling
Sep 12, 2023



We propose MatSci ML, a novel benchmark for modeling MATerials SCIence using Machine Learning (MatSci ML) methods focused on solid-state materials with periodic crystal structures. Applying machine learning methods to solid-state materials is a nascent field with substantial fragmentation largely driven by the great variety of datasets used to develop machine learning models. This fragmentation makes comparing the performance and generalizability of different methods difficult, thereby hindering overall research progress in the field. Building on top of open-source datasets, including large-scale datasets like the OpenCatalyst, OQMD, NOMAD, the Carolina Materials Database, and Materials Project, the MatSci ML benchmark provides a diverse set of materials systems and properties data for model training and evaluation, including simulated energies, atomic forces, material bandgaps, as well as classification data for crystal symmetries via space groups. The diversity of properties in MatSci ML makes the implementation and evaluation of multi-task learning algorithms for solid-state materials possible, while the diversity of datasets facilitates the development of new, more generalized algorithms and methods across multiple datasets. In the multi-dataset learning setting, MatSci ML enables researchers to combine observations from multiple datasets to perform joint prediction of common properties, such as energy and forces. Using MatSci ML, we evaluate the performance of different graph neural networks and equivariant point cloud networks on several benchmark tasks spanning single task, multitask, and multi-data learning scenarios. Our open-source code is available at https://github.com/IntelLabs/matsciml.
Approximate Answering of Graph Queries
Aug 12, 2023Knowledge graphs (KGs) are inherently incomplete because of incomplete world knowledge and bias in what is the input to the KG. Additionally, world knowledge constantly expands and evolves, making existing facts deprecated or introducing new ones. However, we would still want to be able to answer queries as if the graph were complete. In this chapter, we will give an overview of several methods which have been proposed to answer queries in such a setting. We will first provide an overview of the different query types which can be supported by these methods and datasets typically used for evaluation, as well as an insight into their limitations. Then, we give an overview of the different approaches and describe them in terms of expressiveness, supported graph types, and inference capabilities.
Neural Graph Reasoning: Complex Logical Query Answering Meets Graph Databases
Mar 26, 2023



Complex logical query answering (CLQA) is a recently emerged task of graph machine learning that goes beyond simple one-hop link prediction and solves a far more complex task of multi-hop logical reasoning over massive, potentially incomplete graphs in a latent space. The task received a significant traction in the community; numerous works expanded the field along theoretical and practical axes to tackle different types of complex queries and graph modalities with efficient systems. In this paper, we provide a holistic survey of CLQA with a detailed taxonomy studying the field from multiple angles, including graph types (modality, reasoning domain, background semantics), modeling aspects (encoder, processor, decoder), supported queries (operators, patterns, projected variables), datasets, evaluation metrics, and applications. Refining the CLQA task, we introduce the concept of Neural Graph Databases (NGDBs). Extending the idea of graph databases (graph DBs), NGDB consists of a Neural Graph Storage and a Neural Graph Engine. Inside Neural Graph Storage, we design a graph store, a feature store, and further embed information in a latent embedding store using an encoder. Given a query, Neural Query Engine learns how to perform query planning and execution in order to efficiently retrieve the correct results by interacting with the Neural Graph Storage. Compared with traditional graph DBs, NGDBs allow for a flexible and unified modeling of features in diverse modalities using the embedding store. Moreover, when the graph is incomplete, they can provide robust retrieval of answers which a normal graph DB cannot recover. Finally, we point out promising directions, unsolved problems and applications of NGDB for future research.
Attending to Graph Transformers
Feb 08, 2023Recently, transformer architectures for graphs emerged as an alternative to established techniques for machine learning with graphs, such as graph neural networks. So far, they have shown promising empirical results, e.g., on molecular prediction datasets, often attributed to their ability to circumvent graph neural networks' shortcomings, such as over-smoothing and over-squashing. Here, we derive a taxonomy of graph transformer architectures, bringing some order to this emerging field. We overview their theoretical properties, survey structural and positional encodings, and discuss extensions for important graph classes, e.g., 3D molecular graphs. Empirically, we probe how well graph transformers can recover various graph properties, how well they can deal with heterophilic graphs, and to what extent they prevent over-squashing. Further, we outline open challenges and research direction to stimulate future work. Our code is available at https://github.com/luis-mueller/probing-graph-transformers.
Weisfeiler and Leman Go Relational
Nov 30, 2022Knowledge graphs, modeling multi-relational data, improve numerous applications such as question answering or graph logical reasoning. Many graph neural networks for such data emerged recently, often outperforming shallow architectures. However, the design of such multi-relational graph neural networks is ad-hoc, driven mainly by intuition and empirical insights. Up to now, their expressivity, their relation to each other, and their (practical) learning performance is poorly understood. Here, we initiate the study of deriving a more principled understanding of multi-relational graph neural networks. Namely, we investigate the limitations in the expressive power of the well-known Relational GCN and Compositional GCN architectures and shed some light on their practical learning performance. By aligning both architectures with a suitable version of the Weisfeiler-Leman test, we establish under which conditions both models have the same expressive power in distinguishing non-isomorphic (multi-relational) graphs or vertices with different structural roles. Further, by leveraging recent progress in designing expressive graph neural networks, we introduce the $k$-RN architecture that provably overcomes the expressiveness limitations of the above two architectures. Empirically, we confirm our theoretical findings in a vertex classification setting over small and large multi-relational graphs.
Inductive Logical Query Answering in Knowledge Graphs
Oct 13, 2022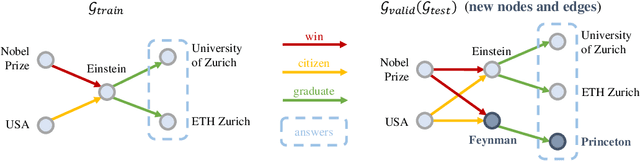
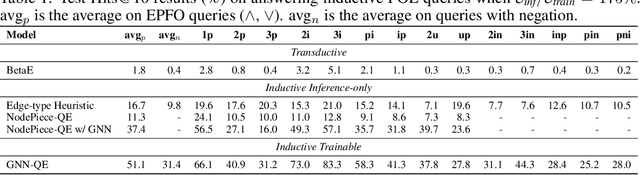
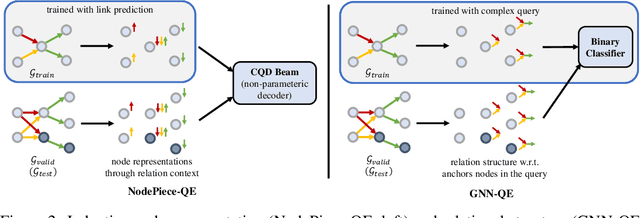

Formulating and answering logical queries is a standard communication interface for knowledge graphs (KGs). Alleviating the notorious incompleteness of real-world KGs, neural methods achieved impressive results in link prediction and complex query answering tasks by learning representations of entities, relations, and queries. Still, most existing query answering methods rely on transductive entity embeddings and cannot generalize to KGs containing new entities without retraining the entity embeddings. In this work, we study the inductive query answering task where inference is performed on a graph containing new entities with queries over both seen and unseen entities. To this end, we devise two mechanisms leveraging inductive node and relational structure representations powered by graph neural networks (GNNs). Experimentally, we show that inductive models are able to perform logical reasoning at inference time over unseen nodes generalizing to graphs up to 500% larger than training ones. Exploring the efficiency--effectiveness trade-off, we find the inductive relational structure representation method generally achieves higher performance, while the inductive node representation method is able to answer complex queries in the inference-only regime without any training on queries and scales to graphs of millions of nodes. Code is available at https://github.com/DeepGraphLearning/InductiveQE.