 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePapaya: Practical, Private, and Scalable Federated Learning
Nov 08, 2021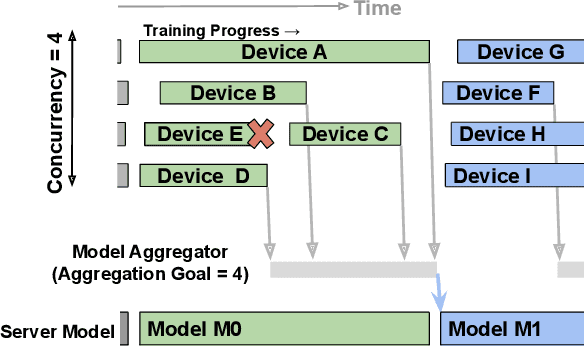
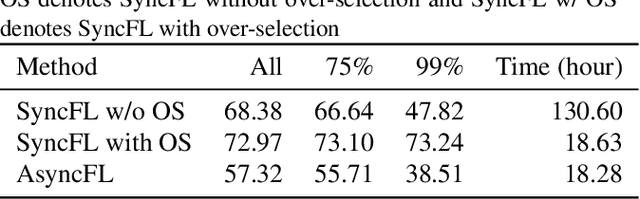
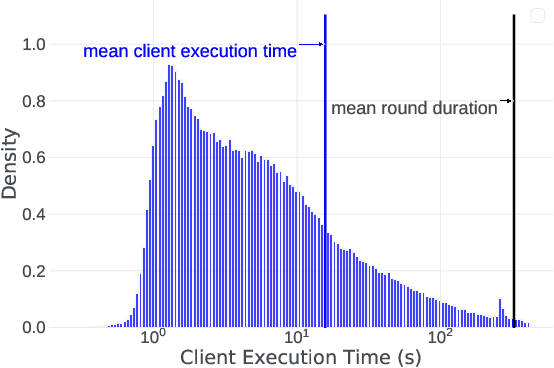
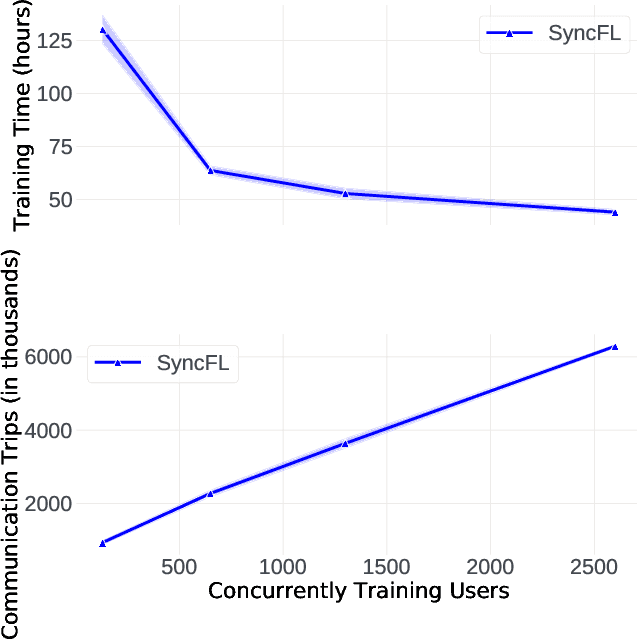
Cross-device Federated Learning (FL) is a distributed learning paradigm with several challenges that differentiate it from traditional distributed learning, variability in the system characteristics on each device, and millions of clients coordinating with a central server being primary ones. Most FL systems described in the literature are synchronous - they perform a synchronized aggregation of model updates from individual clients. Scaling synchronous FL is challenging since increasing the number of clients training in parallel leads to diminishing returns in training speed, analogous to large-batch training. Moreover, stragglers hinder synchronous FL training. In this work, we outline a production asynchronous FL system design. Our work tackles the aforementioned issues, sketches of some of the system design challenges and their solutions, and touches upon principles that emerged from building a production FL system for millions of clients. Empirically, we demonstrate that asynchronous FL converges faster than synchronous FL when training across nearly one hundred million devices. In particular, in high concurrency settings, asynchronous FL is 5x faster and has nearly 8x less communication overhead than synchronous FL.
Sustainable AI: Environmental Implications, Challenges and Opportunities
Oct 30, 2021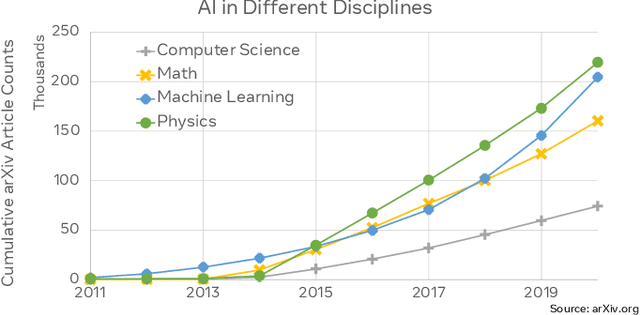
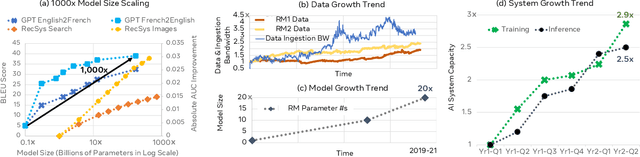
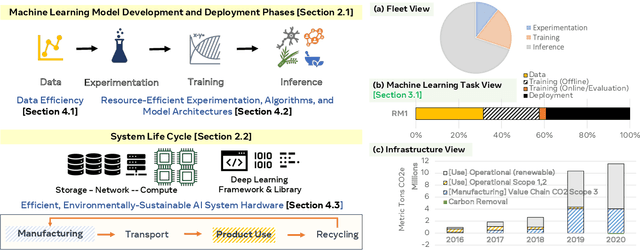
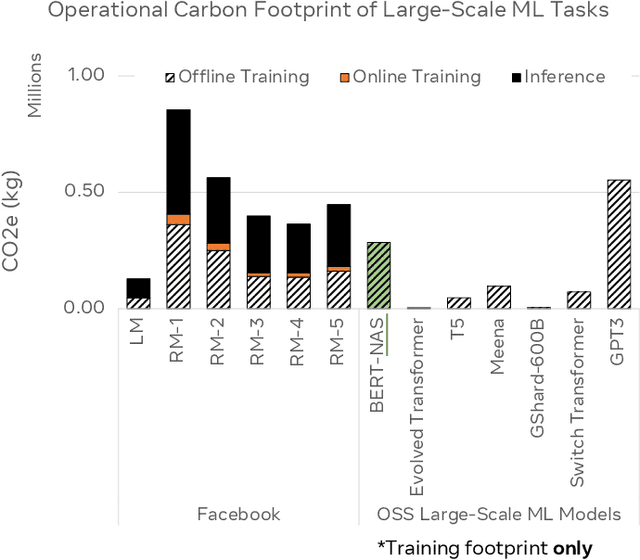
This paper explores the environmental impact of the super-linear growth trends for AI from a holistic perspective, spanning Data, Algorithms, and System Hardware. We characterize the carbon footprint of AI computing by examining the model development cycle across industry-scale machine learning use cases and, at the same time, considering the life cycle of system hardware. Taking a step further, we capture the operational and manufacturing carbon footprint of AI computing and present an end-to-end analysis for what and how hardware-software design and at-scale optimization can help reduce the overall carbon footprint of AI. Based on the industry experience and lessons learned, we share the key challenges and chart out important development directions across the many dimensions of AI. We hope the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.
Trade-offs of Local SGD at Scale: An Empirical Study
Oct 15, 2021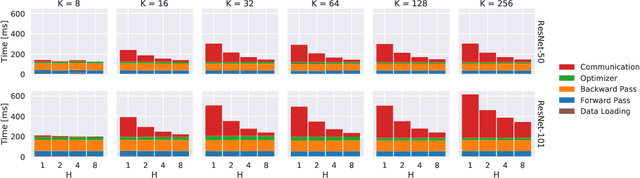
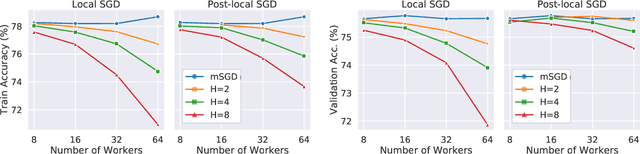
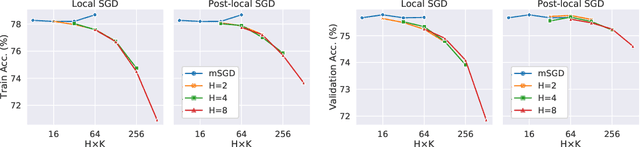
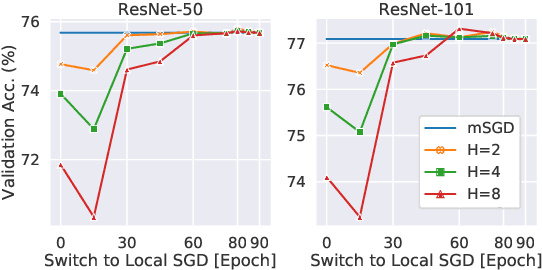
As datasets and models become increasingly large, distributed training has become a necessary component to allow deep neural networks to train in reasonable amounts of time. However, distributed training can have substantial communication overhead that hinders its scalability. One strategy for reducing this overhead is to perform multiple unsynchronized SGD steps independently on each worker between synchronization steps, a technique known as local SGD. We conduct a comprehensive empirical study of local SGD and related methods on a large-scale image classification task. We find that performing local SGD comes at a price: lower communication costs (and thereby faster training) are accompanied by lower accuracy. This finding is in contrast from the smaller-scale experiments in prior work, suggesting that local SGD encounters challenges at scale. We further show that incorporating the slow momentum framework of Wang et al. (2020) consistently improves accuracy without requiring additional communication, hinting at future directions for potentially escaping this trade-off.
Learning with Gradient Descent and Weakly Convex Losses
Jan 13, 2021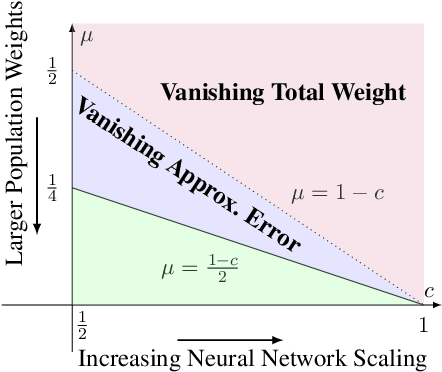
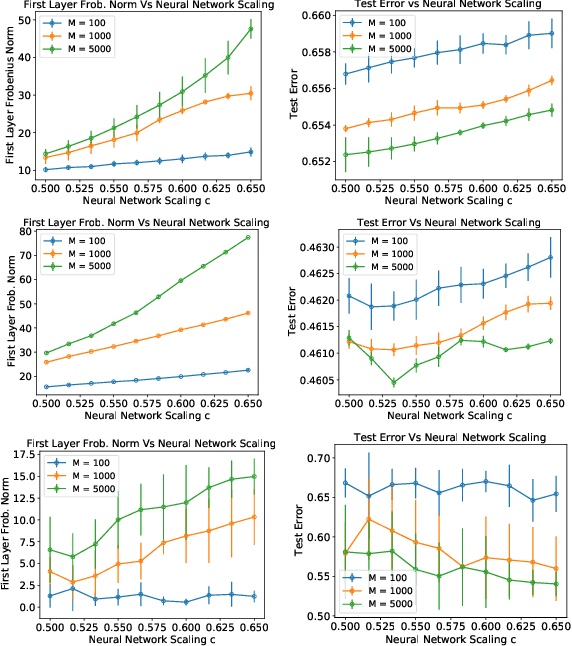
We study the learning performance of gradient descent when the empirical risk is weakly convex, namely, the smallest negative eigenvalue of the empirical risk's Hessian is bounded in magnitude. By showing that this eigenvalue can control the stability of gradient descent, generalisation error bounds are proven that hold under a wider range of step sizes compared to previous work. Out of sample guarantees are then achieved by decomposing the test error into generalisation, optimisation and approximation errors, each of which can be bounded and traded off with respect to algorithmic parameters, sample size and magnitude of this eigenvalue. In the case of a two layer neural network, we demonstrate that the empirical risk can satisfy a notion of local weak convexity, specifically, the Hessian's smallest eigenvalue during training can be controlled by the normalisation of the layers, i.e., network scaling. This allows test error guarantees to then be achieved when the population risk minimiser satisfies a complexity assumption. By trading off the network complexity and scaling, insights are gained into the implicit bias of neural network scaling, which are further supported by experimental findings.
CPR: Understanding and Improving Failure Tolerant Training for Deep Learning Recommendation with Partial Recovery
Nov 05, 2020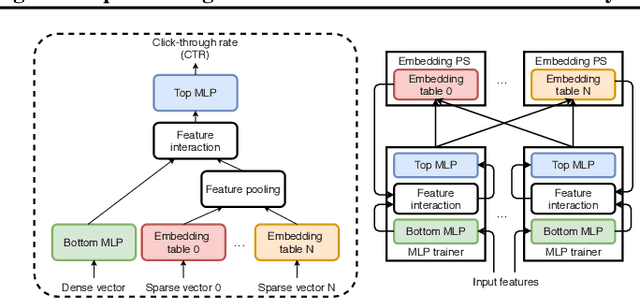
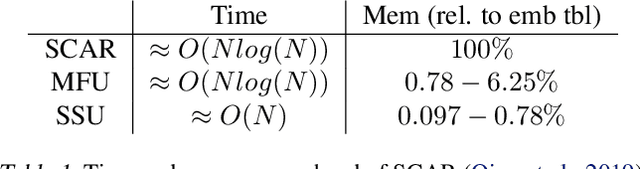
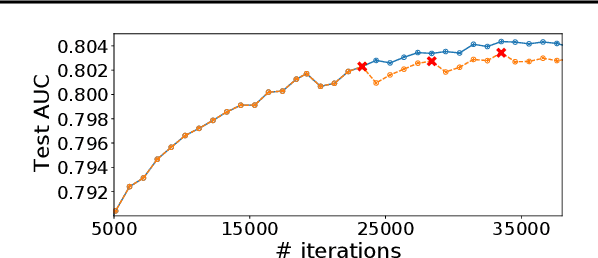
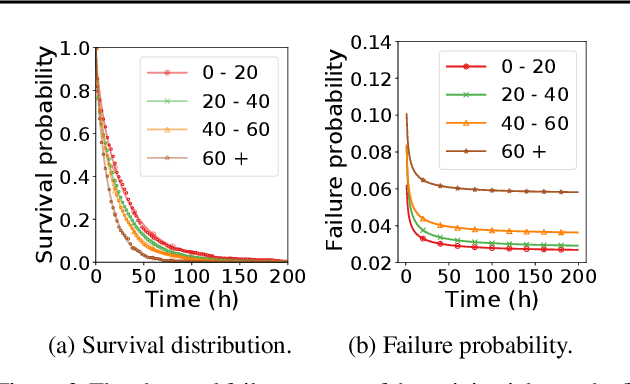
The paper proposes and optimizes a partial recovery training system, CPR, for recommendation models. CPR relaxes the consistency requirement by enabling non-failed nodes to proceed without loading checkpoints when a node fails during training, improving failure-related overheads. The paper is the first to the extent of our knowledge to perform a data-driven, in-depth analysis of applying partial recovery to recommendation models and identified a trade-off between accuracy and performance. Motivated by the analysis, we present CPR, a partial recovery training system that can reduce the training time and maintain the desired level of model accuracy by (1) estimating the benefit of partial recovery, (2) selecting an appropriate checkpoint saving interval, and (3) prioritizing to save updates of more frequently accessed parameters. Two variants of CPR, CPR-MFU and CPR-SSU, reduce the checkpoint-related overhead from 8.2-8.5% to 0.53-0.68% compared to full recovery, on a configuration emulating the failure pattern and overhead of a production-scale cluster. While reducing overhead significantly, CPR achieves model quality on par with the more expensive full recovery scheme, training the state-of-the-art recommendation model using Criteo's Ads CTR dataset. Our preliminary results also suggest that CPR can speed up training on a real production-scale cluster, without notably degrading the accuracy.
MVFST-RL: An Asynchronous RL Framework for Congestion Control with Delayed Actions
Oct 30, 2019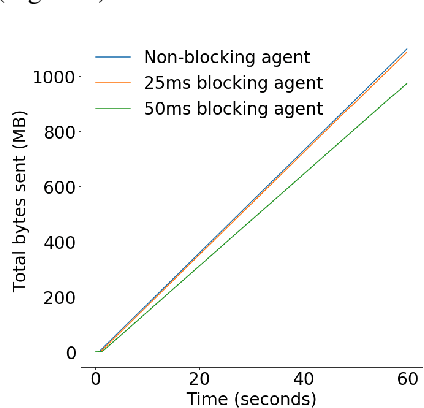
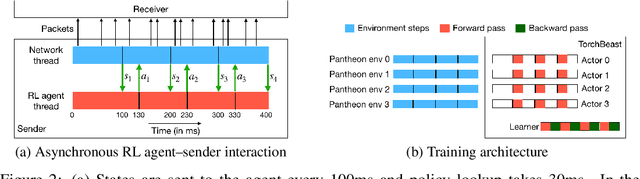
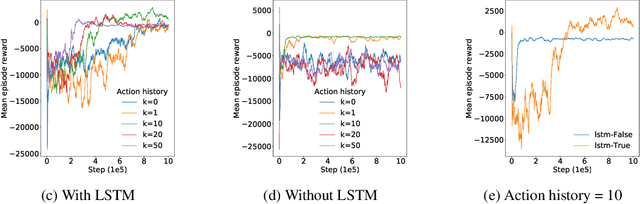
Effective network congestion control strategies are key to keeping the Internet (or any large computer network) operational. Network congestion control has been dominated by hand-crafted heuristics for decades. Recently, ReinforcementLearning (RL) has emerged as an alternative to automatically optimize such control strategies. Research so far has primarily considered RL interfaces which block the sender while an agent considers its next action. This is largely an artifact of building on top of frameworks designed for RL in games (e.g. OpenAI Gym). However, this does not translate to real-world networking environments, where a network sender waiting on a policy without sending data leads to under-utilization of bandwidth. We instead propose to formulate congestion control with an asynchronous RL agent that handles delayed actions. We present MVFST-RL, a scalable framework for congestion control in the QUIC transport protocol that leverages state-of-the-art in asynchronous RL training with off-policy correction. We analyze modeling improvements to mitigate the deviation from Markovian dynamics, and evaluate our method on emulated networks from the Pantheon benchmark platform. The source code is publicly available at https://github.com/facebookresearch/mvfst-rl.
Gossip-based Actor-Learner Architectures for Deep Reinforcement Learning
Jun 09, 2019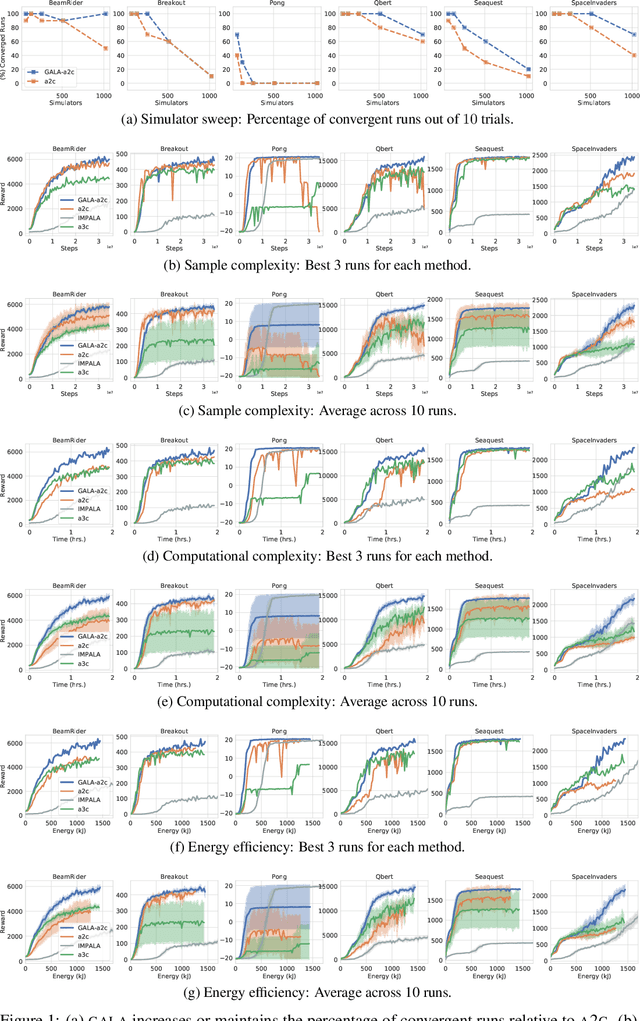
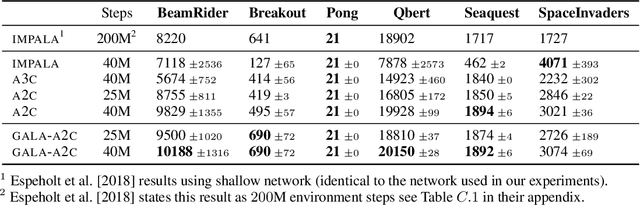
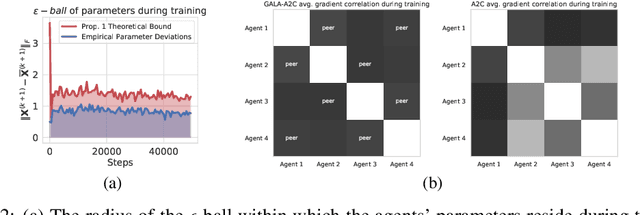
Multi-simulator training has contributed to the recent success of Deep Reinforcement Learning by stabilizing learning and allowing for higher training throughputs. We propose Gossip-based Actor-Learner Architectures (GALA) where several actor-learners (such as A2C agents) are organized in a peer-to-peer communication topology, and exchange information through asynchronous gossip in order to take advantage of a large number of distributed simulators. We prove that GALA agents remain within an epsilon-ball of one-another during training when using loosely coupled asynchronous communication. By reducing the amount of synchronization between agents, GALA is more computationally efficient and scalable compared to A2C, its fully-synchronous counterpart. GALA also outperforms A2C, being more robust and sample efficient. We show that we can run several loosely coupled GALA agents in parallel on a single GPU and achieve significantly higher hardware utilization and frame-rates than vanilla A2C at comparable power draws.