 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You Read is What You Classify: Highlighting Attributions to Text and Text-Like Inputs
Feb 27, 2026At present, there are no easily understood explainable artificial intelligence (AI) methods for discrete token inputs, like text. Most explainable AI techniques do not extend well to token sequences, where both local and global features matter, because state-of-the-art models, like transformers, tend to focus on global connections. Therefore, existing explainable AI algorithms fail by (i) identifying disparate tokens of importance, or (ii) assigning a large number of tokens a low value of importance. This method for explainable AI for tokens-based classifiers generalizes a mask-based explainable AI algorithm for images. It starts with an Explainer neural network that is trained to create masks to hide information not relevant for classification. Then, the Hadamard product of the mask and the continuous values of the classifier's embedding layer is taken and passed through the classifier, changing the magnitude of the embedding vector but keeping the orientation unchanged. The Explainer is trained for a taxonomic classifier for nucleotide sequences and it is shown that the masked segments are less relevant to classification than the unmasked ones. This method focused on the importance the token as a whole (i.e., a segment of the input sequence), producing a human-readable explanation.
CaTE Data Curation for Trustworthy AI
Aug 20, 2025This report provides practical guidance to teams designing or developing AI-enabled systems for how to promote trustworthiness during the data curation phase of development. In this report, the authors first define data, the data curation phase, and trustworthiness. We then describe a series of steps that the development team, especially data scientists, can take to build a trustworthy AI-enabled system. We enumerate the sequence of core steps and trace parallel paths where alternatives exist. The descriptions of these steps include strengths, weaknesses, preconditions, outcomes, and relevant open-source software tool implementations. In total, this report is a synthesis of data curation tools and approaches from relevant academic literature, and our goal is to equip readers with a diverse yet coherent set of practices for improving AI trustworthiness.
Interpreting Deep Neural Networks Through Variable Importance
Jan 28, 2019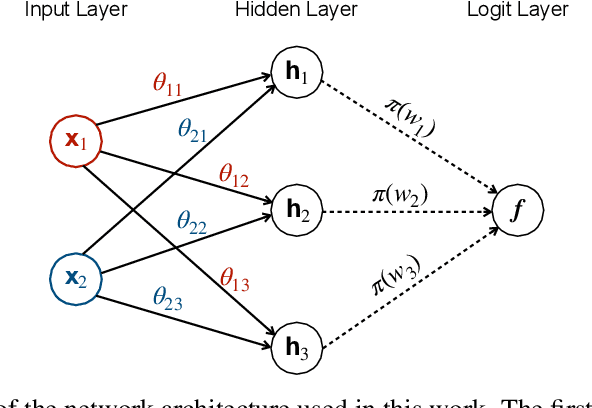
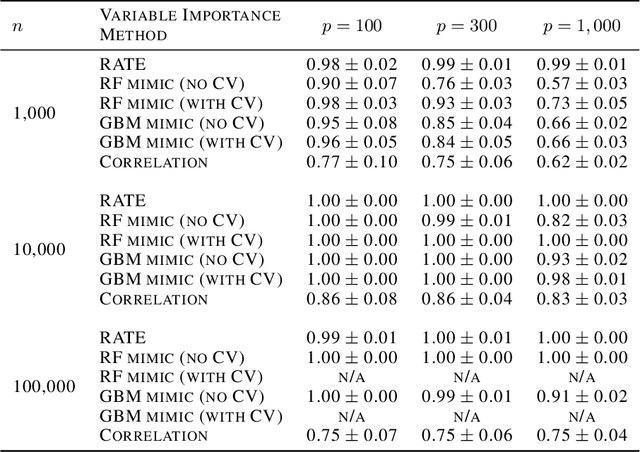
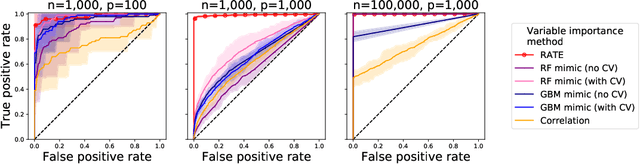
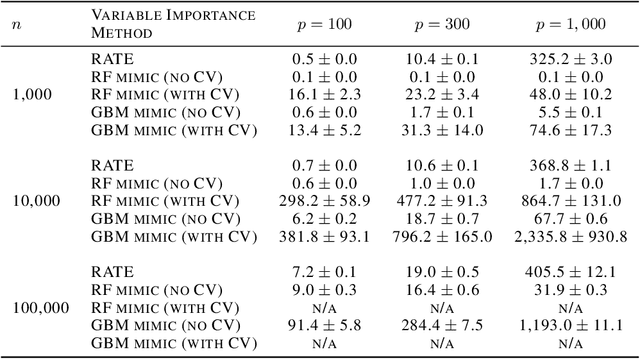
While the success of deep neural networks (DNNs) is well-established across a variety of domains, our ability to explain and interpret these methods is limited. Unlike previously proposed local methods which try to explain particular classification decisions, we focus on global interpretability and ask a universally applicable question: given a trained model, which features are the most important? In the context of neural networks, a feature is rarely important on its own, so our strategy is specifically designed to leverage partial covariance structures and incorporate variable dependence into feature ranking. Our methodological contributions in this paper are two-fold. First, we propose an effect size analogue for DNNs that is appropriate for applications with highly collinear predictors (ubiquitous in computer vision). Second, we extend the recently proposed "RelATive cEntrality" (RATE) measure (Crawford et al., 2019) to the Bayesian deep learning setting. RATE applies an information theoretic criterion to the posterior distribution of effect sizes to assess feature significance. We apply our framework to three broad application areas: computer vision, natural language processing, and social science.