 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Sequential-Diffusion Learning: An approach to Multi-Scene Instructional Video Synthesis
Jul 16, 2024



Action-centric sequence descriptions like recipe instructions and do-it-yourself projects include non-linear patterns in which the next step may require to be visually consistent not on the immediate previous step but on earlier steps. Current video synthesis approaches fail to generate consistent multi-scene videos for such task descriptions. We propose a contrastive sequential video diffusion method that selects the most suitable previously generated scene to guide and condition the denoising process of the next scene. The result is a multi-scene video that is grounded in the scene descriptions and coherent w.r.t the scenes that require consistent visualisation. Our experiments with real-world data demonstrate the practicality and improved consistency of our model compared to prior work.
VideoPhy: Evaluating Physical Commonsense for Video Generation
Jun 05, 2024



Recent advances in internet-scale video data pretraining have led to the development of text-to-video generative models that can create high-quality videos across a broad range of visual concepts and styles. Due to their ability to synthesize realistic motions and render complex objects, these generative models have the potential to become general-purpose simulators of the physical world. However, it is unclear how far we are from this goal with the existing text-to-video generative models. To this end, we present VideoPhy, a benchmark designed to assess whether the generated videos follow physical commonsense for real-world activities (e.g. marbles will roll down when placed on a slanted surface). Specifically, we curate a list of 688 captions that involve interactions between various material types in the physical world (e.g., solid-solid, solid-fluid, fluid-fluid). We then generate videos conditioned on these captions from diverse state-of-the-art text-to-video generative models, including open models (e.g., VideoCrafter2) and closed models (e.g., Lumiere from Google, Pika). Further, our human evaluation reveals that the existing models severely lack the ability to generate videos adhering to the given text prompts, while also lack physical commonsense. Specifically, the best performing model, Pika, generates videos that adhere to the caption and physical laws for only 19.7% of the instances. VideoPhy thus highlights that the video generative models are far from accurately simulating the physical world. Finally, we also supplement the dataset with an auto-evaluator, VideoCon-Physics, to assess semantic adherence and physical commonsense at scale.
Generating Coherent Sequences of Visual Illustrations for Real-World Manual Tasks
May 16, 2024



Multistep instructions, such as recipes and how-to guides, greatly benefit from visual aids, such as a series of images that accompany the instruction steps. While Large Language Models (LLMs) have become adept at generating coherent textual steps, Large Vision/Language Models (LVLMs) are less capable of generating accompanying image sequences. The most challenging aspect is that each generated image needs to adhere to the relevant textual step instruction, as well as be visually consistent with earlier images in the sequence. To address this problem, we propose an approach for generating consistent image sequences, which integrates a Latent Diffusion Model (LDM) with an LLM to transform the sequence into a caption to maintain the semantic coherence of the sequence. In addition, to maintain the visual coherence of the image sequence, we introduce a copy mechanism to initialise reverse diffusion processes with a latent vector iteration from a previously generated image from a relevant step. Both strategies will condition the reverse diffusion process on the sequence of instruction steps and tie the contents of the current image to previous instruction steps and corresponding images. Experiments show that the proposed approach is preferred by humans in 46.6% of the cases against 26.6% for the second best method. In addition, automatic metrics showed that the proposed method maintains semantic coherence and visual consistency across steps in both domains.
TALC: Time-Aligned Captions for Multi-Scene Text-to-Video Generation
May 07, 2024Recent advances in diffusion-based generative modeling have led to the development of text-to-video (T2V) models that can generate high-quality videos conditioned on a text prompt. Most of these T2V models often produce single-scene video clips that depict an entity performing a particular action (e.g., `a red panda climbing a tree'). However, it is pertinent to generate multi-scene videos since they are ubiquitous in the real-world (e.g., `a red panda climbing a tree' followed by `the red panda sleeps on the top of the tree'). To generate multi-scene videos from the pretrained T2V model, we introduce Time-Aligned Captions (TALC) framework. Specifically, we enhance the text-conditioning mechanism in the T2V architecture to recognize the temporal alignment between the video scenes and scene descriptions. For instance, we condition the visual features of the earlier and later scenes of the generated video with the representations of the first scene description (e.g., `a red panda climbing a tree') and second scene description (e.g., `the red panda sleeps on the top of the tree'), respectively. As a result, we show that the T2V model can generate multi-scene videos that adhere to the multi-scene text descriptions and be visually consistent (e.g., entity and background). Further, we finetune the pretrained T2V model with multi-scene video-text data using the TALC framework. We show that the TALC-finetuned model outperforms the baseline methods by 15.5 points in the overall score, which averages visual consistency and text adherence using human evaluation. The project website is https://talc-mst2v.github.io/.
Transferring Visual Attributes from Natural Language to Verified Image Generation
May 24, 2023Text to image generation methods (T2I) are widely popular in generating art and other creative artifacts. While visual hallucinations can be a positive factor in scenarios where creativity is appreciated, such artifacts are poorly suited for cases where the generated image needs to be grounded in complex natural language without explicit visual elements. In this paper, we propose to strengthen the consistency property of T2I methods in the presence of natural complex language, which often breaks the limits of T2I methods by including non-visual information, and textual elements that require knowledge for accurate generation. To address these phenomena, we propose a Natural Language to Verified Image generation approach (NL2VI) that converts a natural prompt into a visual prompt, which is more suitable for image generation. A T2I model then generates an image for the visual prompt, which is then verified with VQA algorithms. Experimentally, aligning natural prompts with image generation can improve the consistency of the generated images by up to 11% over the state of the art. Moreover, improvements can generalize to challenging domains like cooking and DIY tasks, where the correctness of the generated image is crucial to illustrate actions.
What You See is What You Read? Improving Text-Image Alignment Evaluation
May 22, 2023Automatically determining whether a text and a corresponding image are semantically aligned is a significant challenge for vision-language models, with applications in generative text-to-image and image-to-text tasks. In this work, we study methods for automatic text-image alignment evaluation. We first introduce SeeTRUE: a comprehensive evaluation set, spanning multiple datasets from both text-to-image and image-to-text generation tasks, with human judgements for whether a given text-image pair is semantically aligned. We then describe two automatic methods to determine alignment: the first involving a pipeline based on question generation and visual question answering models, and the second employing an end-to-end classification approach by finetuning multimodal pretrained models. Both methods surpass prior approaches in various text-image alignment tasks, with significant improvements in challenging cases that involve complex composition or unnatural images. Finally, we demonstrate how our approaches can localize specific misalignments between an image and a given text, and how they can be used to automatically re-rank candidates in text-to-image generation.
MyStyle: A Personalized Generative Prior
Mar 31, 2022
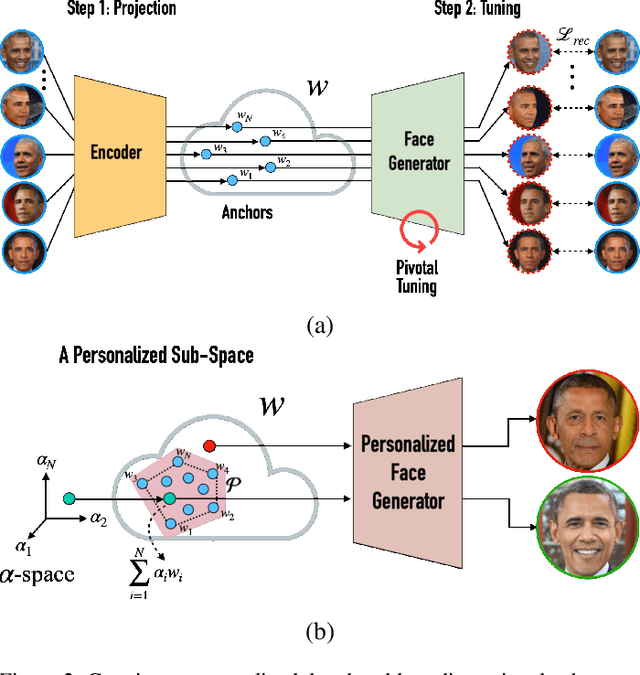
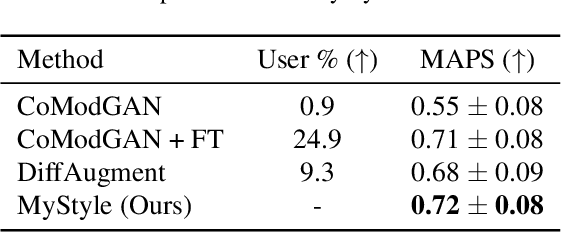

We introduce MyStyle, a personalized deep generative prior trained with a few shots of an individual. MyStyle allows to reconstruct, enhance and edit images of a specific person, such that the output is faithful to the person's key facial characteristics. Given a small reference set of portrait images of a person (~100), we tune the weights of a pretrained StyleGAN face generator to form a local, low-dimensional, personalized manifold in the latent space. We show that this manifold constitutes a personalized region that spans latent codes associated with diverse portrait images of the individual. Moreover, we demonstrate that we obtain a personalized generative prior, and propose a unified approach to apply it to various ill-posed image enhancement problems, such as inpainting and super-resolution, as well as semantic editing. Using the personalized generative prior we obtain outputs that exhibit high-fidelity to the input images and are also faithful to the key facial characteristics of the individual in the reference set. We demonstrate our method with fair-use images of numerous widely recognizable individuals for whom we have the prior knowledge for a qualitative evaluation of the expected outcome. We evaluate our approach against few-shots baselines and show that our personalized prior, quantitatively and qualitatively, outperforms state-of-the-art alternatives.
Self-Distilled StyleGAN: Towards Generation from Internet Photos
Feb 24, 2022
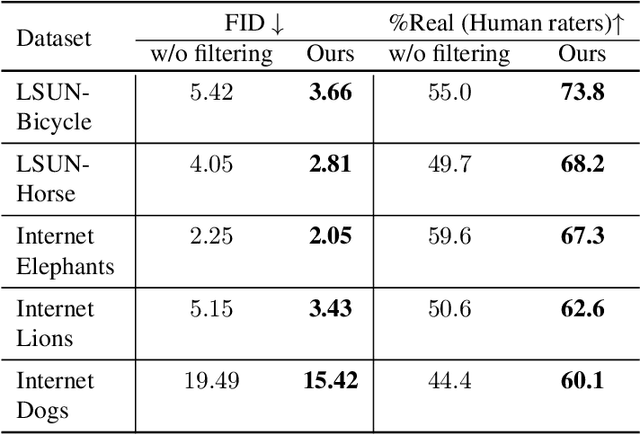
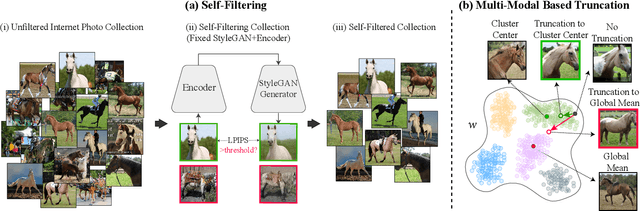
StyleGAN is known to produce high-fidelity images, while also offering unprecedented semantic editing. However, these fascinating abilities have been demonstrated only on a limited set of datasets, which are usually structurally aligned and well curated. In this paper, we show how StyleGAN can be adapted to work on raw uncurated images collected from the Internet. Such image collections impose two main challenges to StyleGAN: they contain many outlier images, and are characterized by a multi-modal distribution. Training StyleGAN on such raw image collections results in degraded image synthesis quality. To meet these challenges, we proposed a StyleGAN-based self-distillation approach, which consists of two main components: (i) A generative-based self-filtering of the dataset to eliminate outlier images, in order to generate an adequate training set, and (ii) Perceptual clustering of the generated images to detect the inherent data modalities, which are then employed to improve StyleGAN's "truncation trick" in the image synthesis process. The presented technique enables the generation of high-quality images, while minimizing the loss in diversity of the data. Through qualitative and quantitative evaluation, we demonstrate the power of our approach to new challenging and diverse domains collected from the Internet. New datasets and pre-trained models are available at https://self-distilled-stylegan.github.io/ .
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021
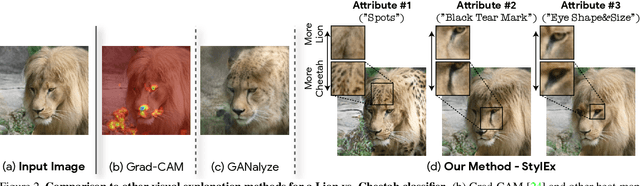
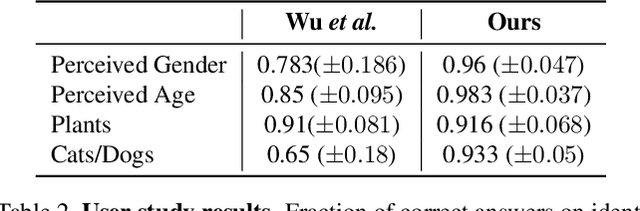
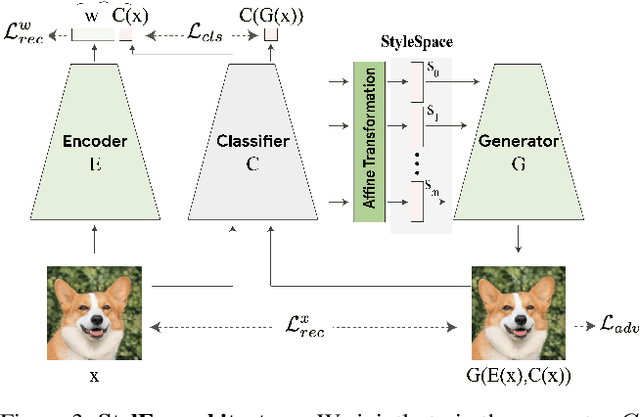
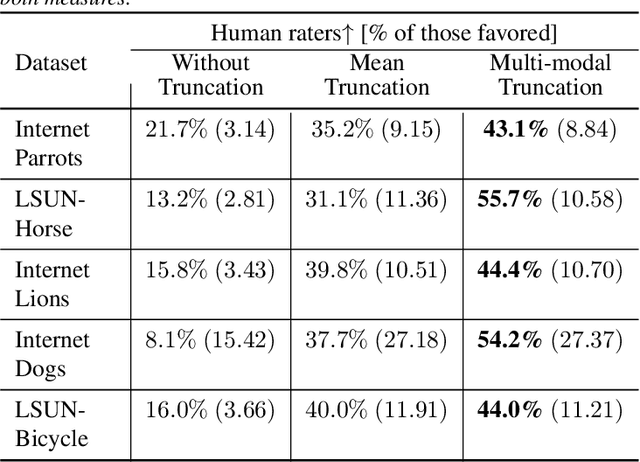
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
Semantic Pyramid for Image Generation
Mar 16, 2020

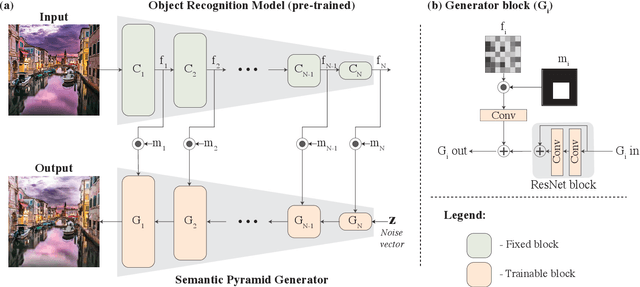
We present a novel GAN-based model that utilizes the space of deep features learned by a pre-trained classification model. Inspired by classical image pyramid representations, we construct our model as a Semantic Generation Pyramid -- a hierarchical framework which leverages the continuum of semantic information encapsulated in such deep features; this ranges from low level information contained in fine features to high level, semantic information contained in deeper features. More specifically, given a set of features extracted from a reference image, our model generates diverse image samples, each with matching features at each semantic level of the classification model. We demonstrate that our model results in a versatile and flexible framework that can be used in various classic and novel image generation tasks. These include: generating images with a controllable extent of semantic similarity to a reference image, and different manipulation tasks such as semantically-controlled inpainting and compositing; all achieved with the same model, with no further training.