 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-NeRF: Surface-free Human 3D Pose Refinement via Neural Rendering
Feb 11, 2021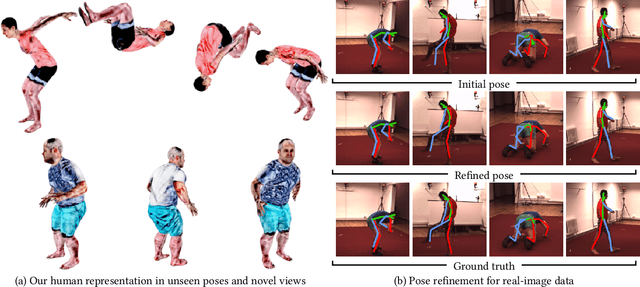
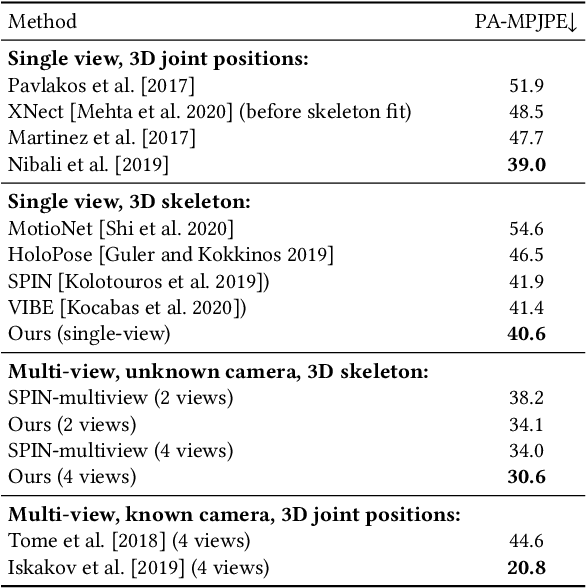

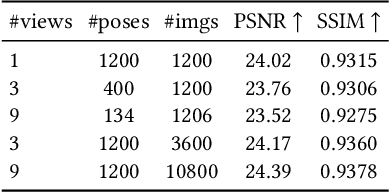
While deep learning has reshaped the classical motion capture pipeline, generative, analysis-by-synthesis elements are still in use to recover fine details if a high-quality 3D model of the user is available. Unfortunately, obtaining such a model for every user a priori is challenging, time-consuming, and limits the application scenarios. We propose a novel test-time optimization approach for monocular motion capture that learns a volumetric body model of the user in a self-supervised manner. To this end, our approach combines the advantages of neural radiance fields with an articulated skeleton representation. Our proposed skeleton embedding serves as a common reference that links constraints across time, thereby reducing the number of required camera views from traditionally dozens of calibrated cameras, down to a single uncalibrated one. As a starting point, we employ the output of an off-the-shelf model that predicts the 3D skeleton pose. The volumetric body shape and appearance is then learned from scratch, while jointly refining the initial pose estimate. Our approach is self-supervised and does not require any additional ground truth labels for appearance, pose, or 3D shape. We demonstrate that our novel combination of a discriminative pose estimation technique with surface-free analysis-by-synthesis outperforms purely discriminative monocular pose estimation approaches and generalizes well to multiple views.
PVA: Pixel-aligned Volumetric Avatars
Jan 07, 2021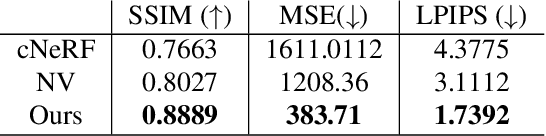
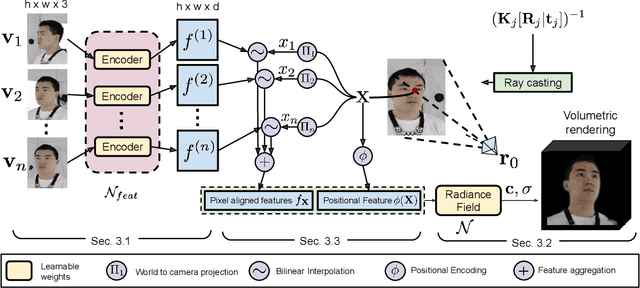


Acquisition and rendering of photo-realistic human heads is a highly challenging research problem of particular importance for virtual telepresence. Currently, the highest quality is achieved by volumetric approaches trained in a person specific manner on multi-view data. These models better represent fine structure, such as hair, compared to simpler mesh-based models. Volumetric models typically employ a global code to represent facial expressions, such that they can be driven by a small set of animation parameters. While such architectures achieve impressive rendering quality, they can not easily be extended to the multi-identity setting. In this paper, we devise a novel approach for predicting volumetric avatars of the human head given just a small number of inputs. We enable generalization across identities by a novel parameterization that combines neural radiance fields with local, pixel-aligned features extracted directly from the inputs, thus sidestepping the need for very deep or complex networks. Our approach is trained in an end-to-end manner solely based on a photometric re-rendering loss without requiring explicit 3D supervision.We demonstrate that our approach outperforms the existing state of the art in terms of quality and is able to generate faithful facial expressions in a multi-identity setting.
DeepCap: Monocular Human Performance Capture Using Weak Supervision
Mar 18, 2020
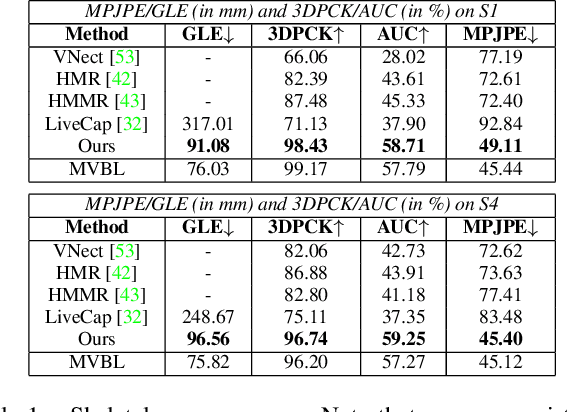
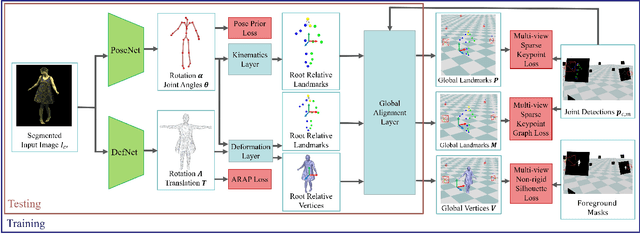
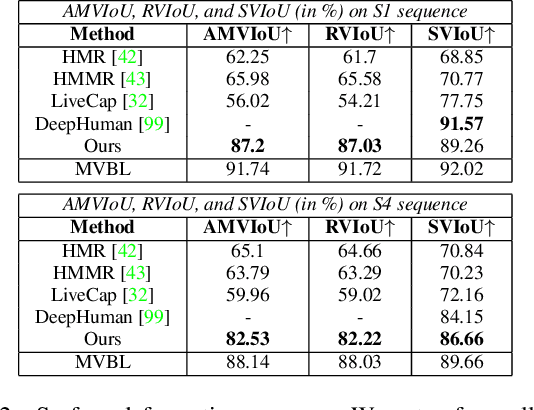
Human performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups or did not recover dense space-time coherent geometry with frame-to-frame correspondences. We propose a novel deep learning approach for monocular dense human performance capture. Our method is trained in a weakly supervised manner based on multi-view supervision completely removing the need for training data with 3D ground truth annotations. The network architecture is based on two separate networks that disentangle the task into a pose estimation and a non-rigid surface deformation step. Extensive qualitative and quantitative evaluations show that our approach outperforms the state of the art in terms of quality and robustness.
Neural Human Video Rendering: Joint Learning of Dynamic Textures and Rendering-to-Video Translation
Jan 14, 2020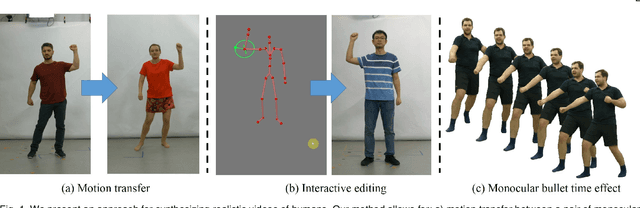
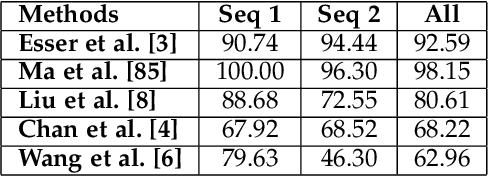
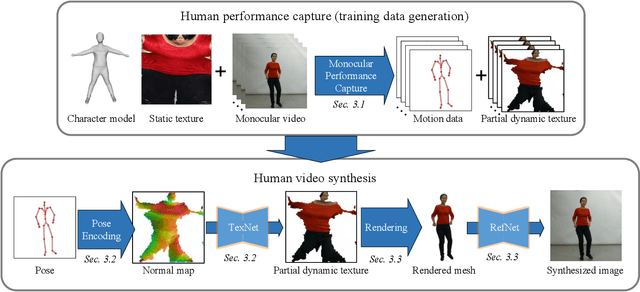
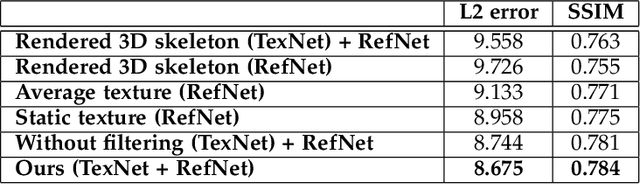
Synthesizing realistic videos of humans using neural networks has been a popular alternative to the conventional graphics-based rendering pipeline due to its high efficiency. Existing works typically formulate this as an image-to-image translation problem in 2D screen space, which leads to artifacts such as over-smoothing, missing body parts, and temporal instability of fine-scale detail, such as pose-dependent wrinkles in the clothing. In this paper, we propose a novel human video synthesis method that approaches these limiting factors by explicitly disentangling the learning of time-coherent fine-scale details from the embedding of the human in 2D screen space. More specifically, our method relies on the combination of two convolutional neural networks (CNNs). Given the pose information, the first CNN predicts a dynamic texture map that contains time-coherent high-frequency details, and the second CNN conditions the generation of the final video on the temporally coherent output of the first CNN. We demonstrate several applications of our approach, such as human reenactment and novel view synthesis from monocular video, where we show significant improvement over the state of the art both qualitatively and quantitatively.
3D Morphable Face Models -- Past, Present and Future
Sep 03, 2019
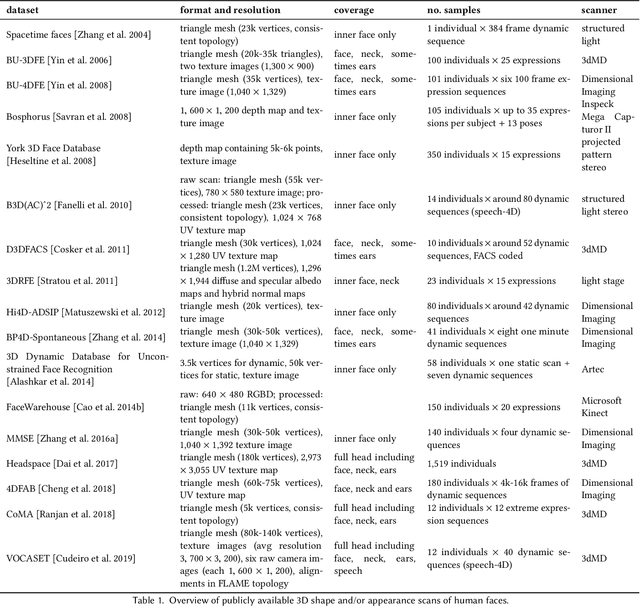
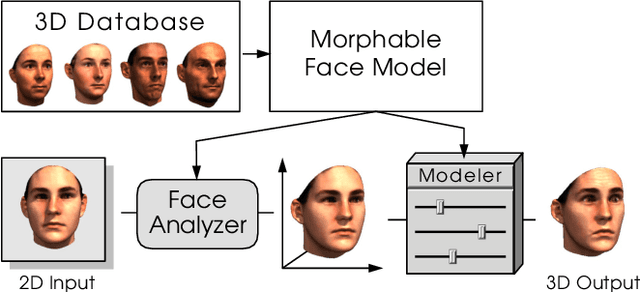
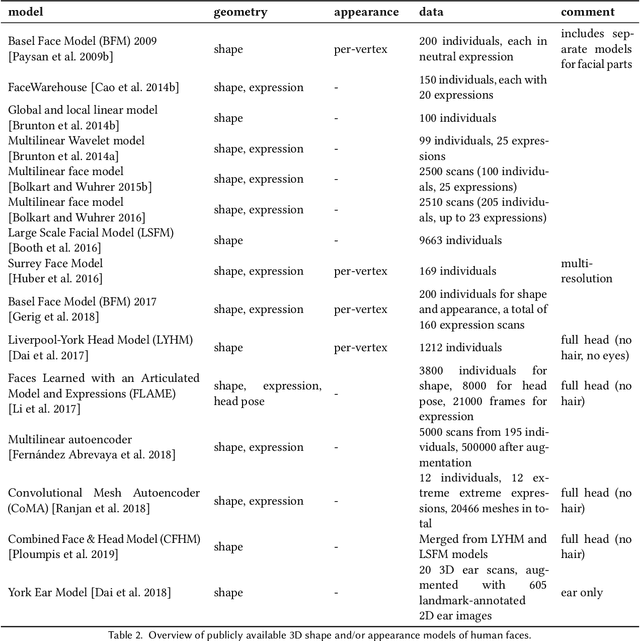
In this paper, we provide a detailed survey of 3D Morphable Face Models over the 20 years since they were first proposed. The challenges in building and applying these models, namely capture, modeling, image formation, and image analysis, are still active research topics, and we review the state-of-the-art in each of these areas. We also look ahead, identifying unsolved challenges, proposing directions for future research and highlighting the broad range of current and future applications.
Live Illumination Decomposition of Videos
Aug 06, 2019
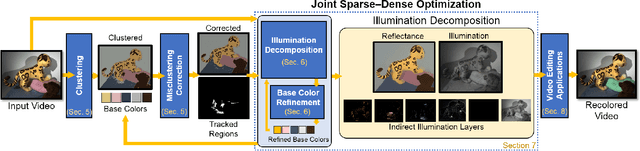
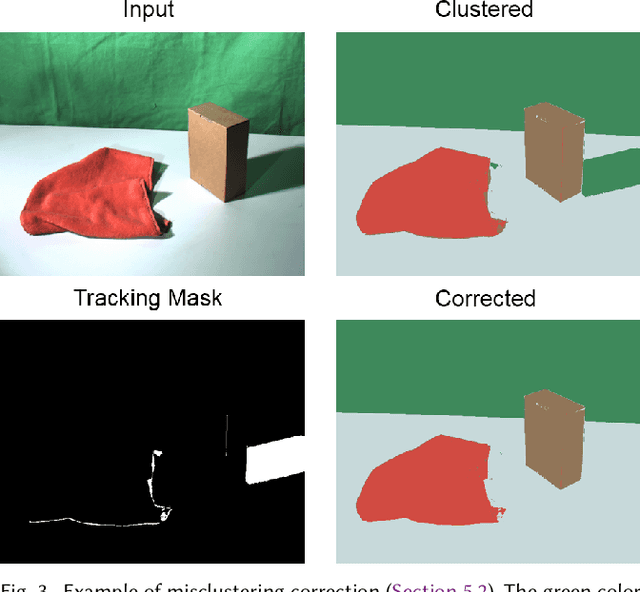
We propose the first approach for the decomposition of a monocular color video into direct and indirect illumination components in real-time. We retrieve, in separate layers, the contribution made to the scene appearance by the scene reflectance, the light sources and the reflections from various coherent scene regions to one another. Existing techniques that invert global light transport require image capture under multiplexed controlled lighting, or only enable the decomposition of a single image at slow off-line frame rates. In contrast, our approach works for regular videos and produces temporally coherent decomposition layers at real-time frame rates. At the core of our approach are several sparsity priors that enable the estimation of the per-pixel direct and indirect illumination layers based on a small set of jointly estimated base reflectance colors. The resulting variational decomposition problem uses a new formulation based on sparse and dense sets of non-linear equations that we solve efficiently using a novel alternating data-parallel optimization strategy. We evaluate our approach qualitatively and quantitatively, and show improvements over the state of the art in this field, in both quality and runtime. In addition, we demonstrate various real-time appearance editing applications for videos with consistent illumination.
Neural Animation and Reenactment of Human Actor Videos
Sep 11, 2018
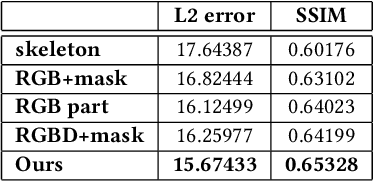
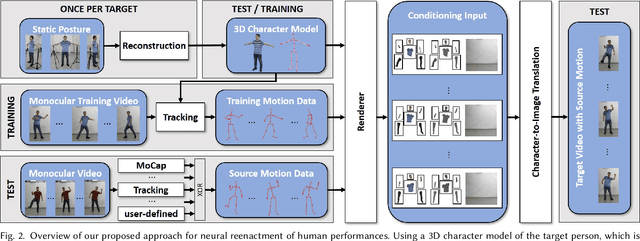
We propose a method for generating (near) video-realistic animations of real humans under user control. In contrast to conventional human character rendering, we do not require the availability of a production-quality photo-realistic 3D model of the human, but instead rely on a video sequence in conjunction with a (medium-quality) controllable 3D template model of the person. With that, our approach significantly reduces production cost compared to conventional rendering approaches based on production-quality 3D models, and can also be used to realistically edit existing videos. Technically, this is achieved by training a neural network that translates simple synthetic images of a human character into realistic imagery. For training our networks, we first track the 3D motion of the person in the video using the template model, and subsequently generate a synthetically rendered version of the video. These images are then used to train a conditional generative adversarial network that translates synthetic images of the 3D model into realistic imagery of the human. We evaluate our method for the reenactment of another person that is tracked in order to obtain the motion data, and show video results generated from artist-designed skeleton motion. Our results outperform the state-of-the-art in learning-based human image synthesis. Project page: http://gvv.mpi-inf.mpg.de/projects/wxu/HumanReenactment/
LIME: Live Intrinsic Material Estimation
May 04, 2018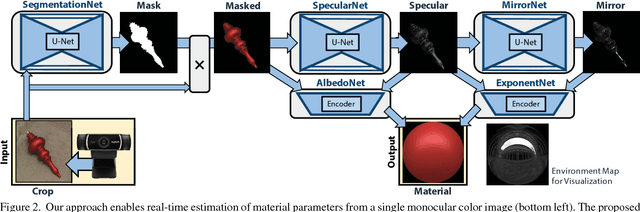
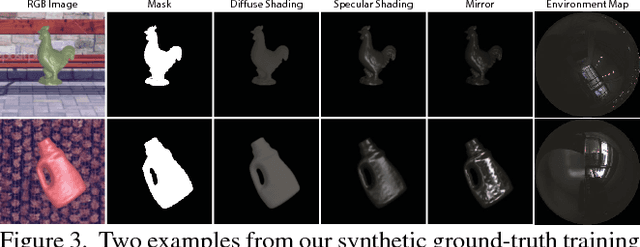


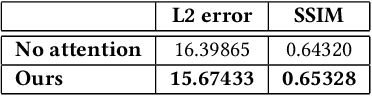
We present the first end to end approach for real time material estimation for general object shapes with uniform material that only requires a single color image as input. In addition to Lambertian surface properties, our approach fully automatically computes the specular albedo, material shininess, and a foreground segmentation. We tackle this challenging and ill posed inverse rendering problem using recent advances in image to image translation techniques based on deep convolutional encoder decoder architectures. The underlying core representations of our approach are specular shading, diffuse shading and mirror images, which allow to learn the effective and accurate separation of diffuse and specular albedo. In addition, we propose a novel highly efficient perceptual rendering loss that mimics real world image formation and obtains intermediate results even during run time. The estimation of material parameters at real time frame rates enables exciting mixed reality applications, such as seamless illumination consistent integration of virtual objects into real world scenes, and virtual material cloning. We demonstrate our approach in a live setup, compare it to the state of the art, and demonstrate its effectiveness through quantitative and qualitative evaluation.
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Mar 15, 2018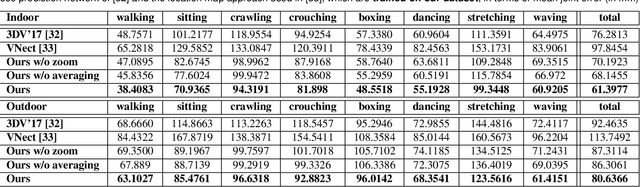


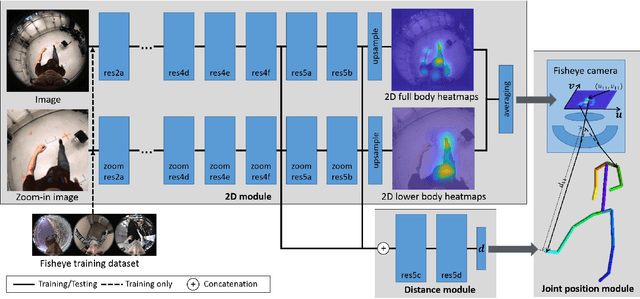
We propose the first real-time approach for the egocentric estimation of 3D human body pose in a wide range of unconstrained everyday activities. This setting has a unique set of challenges, such as mobility of the hardware setup, and robustness to long capture sessions with fast recovery from tracking failures. We tackle these challenges based on a novel lightweight setup that converts a standard baseball cap to a device for high-quality pose estimation based on a single cap-mounted fisheye camera. From the captured egocentric live stream, our CNN based 3D pose estimation approach runs at 60Hz on a consumer-level GPU. In addition to the novel hardware setup, our other main contributions are: 1) a large ground truth training corpus of top-down fisheye images and 2) a novel disentangled 3D pose estimation approach that takes the unique properties of the egocentric viewpoint into account. As shown by our evaluation, we achieve lower 3D joint error as well as better 2D overlay than the existing baselines.