 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Recurrent Neural Networks with Weighted Time-Delay Feedback
Dec 01, 2022



We introduce a novel gated recurrent unit (GRU) with a weighted time-delay feedback mechanism in order to improve the modeling of long-term dependencies in sequential data. This model is a discretized version of a continuous-time formulation of a recurrent unit, where the dynamics are governed by delay differential equations (DDEs). By considering a suitable time-discretization scheme, we propose $\tau$-GRU, a discrete-time gated recurrent unit with delay. We prove the existence and uniqueness of solutions for the continuous-time model, and we demonstrate that the proposed feedback mechanism can help improve the modeling of long-term dependencies. Our empirical results show that $\tau$-GRU can converge faster and generalize better than state-of-the-art recurrent units and gated recurrent architectures on a range of tasks, including time-series classification, human activity recognition, and speech recognition.
Fully Stochastic Trust-Region Sequential Quadratic Programming for Equality-Constrained Optimization Problems
Nov 29, 2022


We propose a trust-region stochastic sequential quadratic programming algorithm (TR-StoSQP) to solve nonlinear optimization problems with stochastic objectives and deterministic equality constraints. We consider a fully stochastic setting, where in each iteration a single sample is generated to estimate the objective gradient. The algorithm adaptively selects the trust-region radius and, compared to the existing line-search StoSQP schemes, allows us to employ indefinite Hessian matrices (i.e., Hessians without modification) in SQP subproblems. As a trust-region method for constrained optimization, our algorithm needs to address an infeasibility issue -- the linearized equality constraints and trust-region constraints might lead to infeasible SQP subproblems. In this regard, we propose an \textit{adaptive relaxation technique} to compute the trial step that consists of a normal step and a tangential step. To control the lengths of the two steps, we adaptively decompose the trust-region radius into two segments based on the proportions of the feasibility and optimality residuals to the full KKT residual. The normal step has a closed form, while the tangential step is solved from a trust-region subproblem, to which a solution ensuring the Cauchy reduction is sufficient for our study. We establish the global almost sure convergence guarantee for TR-StoSQP, and illustrate its empirical performance on both a subset of problems in the CUTEst test set and constrained logistic regression problems using data from the LIBSVM collection.
Monotonicity and Double Descent in Uncertainty Estimation with Gaussian Processes
Oct 14, 2022
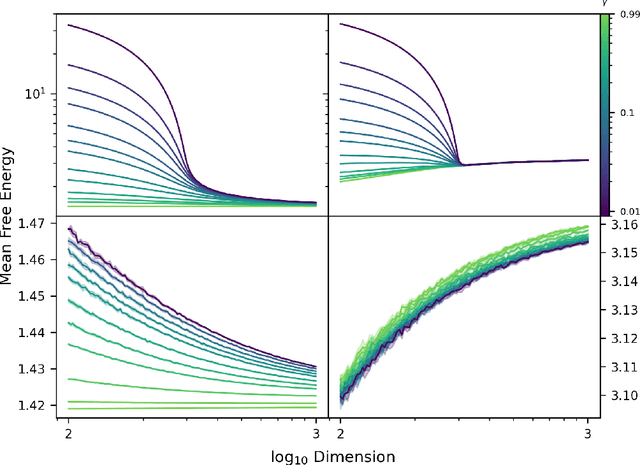
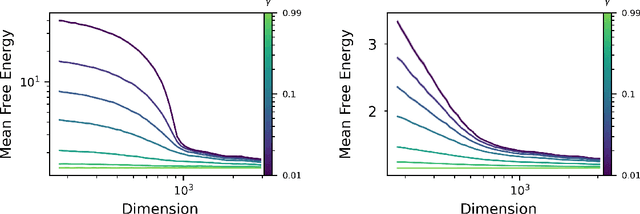
The quality of many modern machine learning models improves as model complexity increases, an effect that has been quantified, for predictive performance, with the non-monotonic double descent learning curve. Here, we address the overarching question: is there an analogous theory of double descent for models which estimate uncertainty? We provide a partially affirmative and partially negative answer in the setting of Gaussian processes (GP). Under standard assumptions, we prove that higher model quality for optimally-tuned GPs (including uncertainty prediction) under marginal likelihood is realized for larger input dimensions, and therefore exhibits a monotone error curve. After showing that marginal likelihood does not naturally exhibit double descent in the input dimension, we highlight related forms of posterior predictive loss that do exhibit non-monotonicity. Finally, we verify empirically that our results hold for real data, beyond our considered assumptions, and we explore consequences involving synthetic covariates.
Gradient Gating for Deep Multi-Rate Learning on Graphs
Oct 02, 2022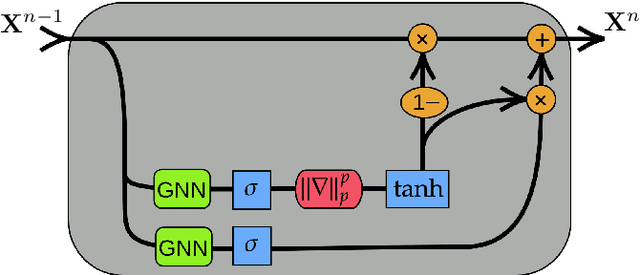
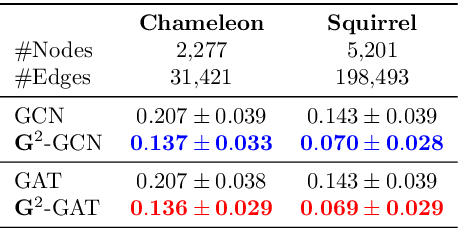
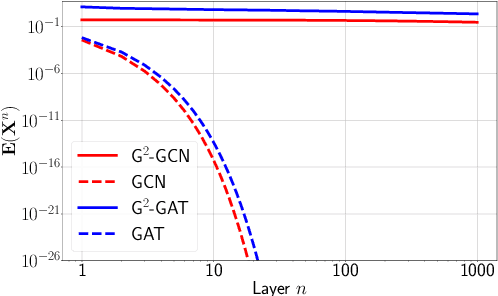
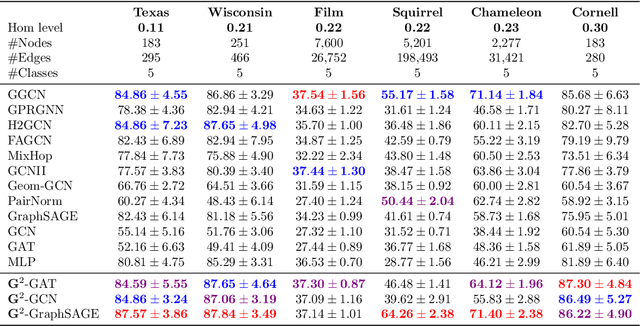
We present Gradient Gating (G$^2$), a novel framework for improving the performance of Graph Neural Networks (GNNs). Our framework is based on gating the output of GNN layers with a mechanism for multi-rate flow of message passing information across nodes of the underlying graph. Local gradients are harnessed to further modulate message passing updates. Our framework flexibly allows one to use any basic GNN layer as a wrapper around which the multi-rate gradient gating mechanism is built. We rigorously prove that G$^2$ alleviates the oversmoothing problem and allows the design of deep GNNs. Empirical results are presented to demonstrate that the proposed framework achieves state-of-the-art performance on a variety of graph learning tasks, including on large-scale heterophilic graphs.
Learning differentiable solvers for systems with hard constraints
Jul 18, 2022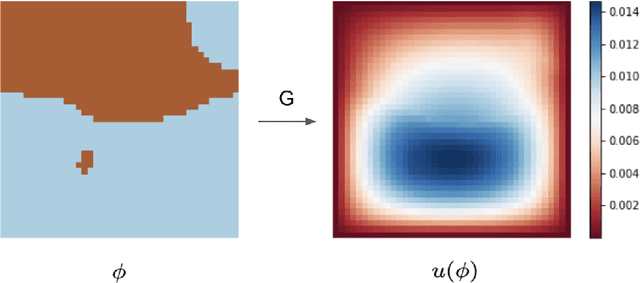
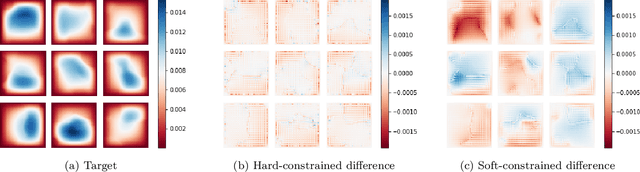
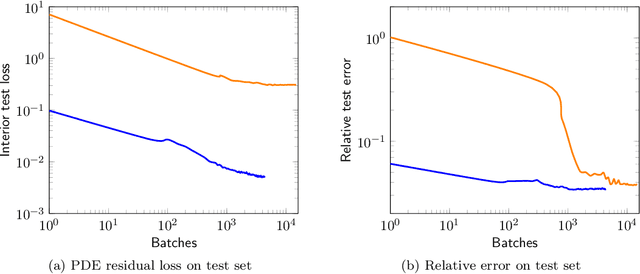
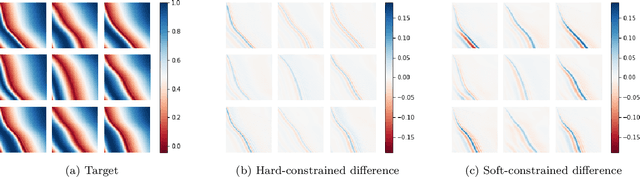
We introduce a practical method to enforce linear partial differential equation (PDE) constraints for functions defined by neural networks (NNs), up to a desired tolerance. By combining methods in differentiable physics and applications of the implicit function theorem to NN models, we develop a differentiable PDE-constrained NN layer. During training, our model learns a family of functions, each of which defines a mapping from PDE parameters to PDE solutions. At inference time, the model finds an optimal linear combination of the functions in the learned family by solving a PDE-constrained optimization problem. Our method provides continuous solutions over the domain of interest that exactly satisfy desired physical constraints. Our results show that incorporating hard constraints directly into the NN architecture achieves much lower test error, compared to training on an unconstrained objective.
Adaptive Self-supervision Algorithms for Physics-informed Neural Networks
Jul 08, 2022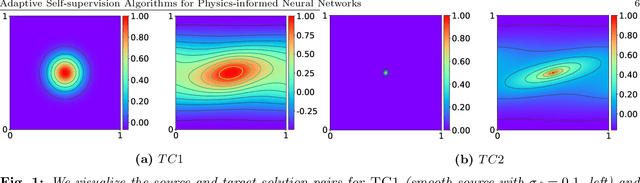

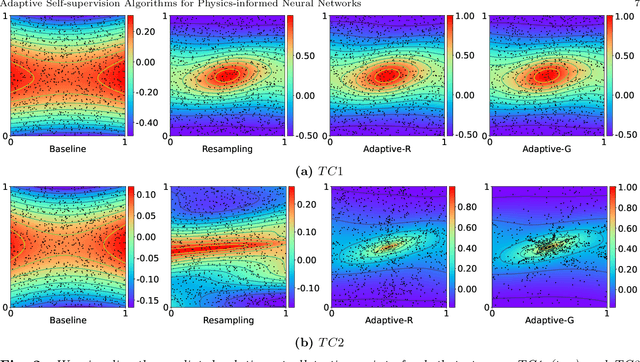

Physics-informed neural networks (PINNs) incorporate physical knowledge from the problem domain as a soft constraint on the loss function, but recent work has shown that this can lead to optimization difficulties. Here, we study the impact of the location of the collocation points on the trainability of these models. We find that the vanilla PINN performance can be significantly boosted by adapting the location of the collocation points as training proceeds. Specifically, we propose a novel adaptive collocation scheme which progressively allocates more collocation points (without increasing their number) to areas where the model is making higher errors (based on the gradient of the loss function in the domain). This, coupled with a judicious restarting of the training during any optimization stalls (by simply resampling the collocation points in order to adjust the loss landscape) leads to better estimates for the prediction error. We present results for several problems, including a 2D Poisson and diffusion-advection system with different forcing functions. We find that training vanilla PINNs for these problems can result in up to 70% prediction error in the solution, especially in the regime of low collocation points. In contrast, our adaptive schemes can achieve up to an order of magnitude smaller error, with similar computational complexity as the baseline. Furthermore, we find that the adaptive methods consistently perform on-par or slightly better than vanilla PINN method, even for large collocation point regimes. The code for all the experiments has been open sourced.
Neurotoxin: Durable Backdoors in Federated Learning
Jun 12, 2022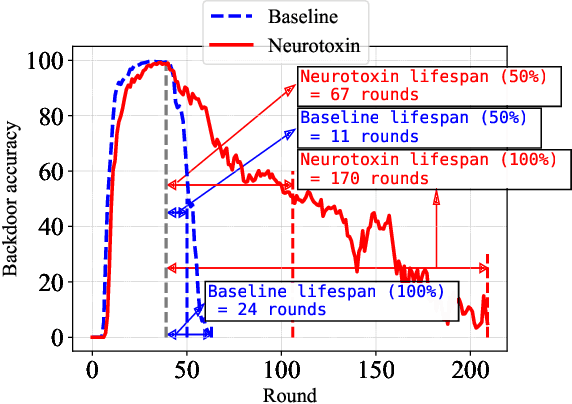

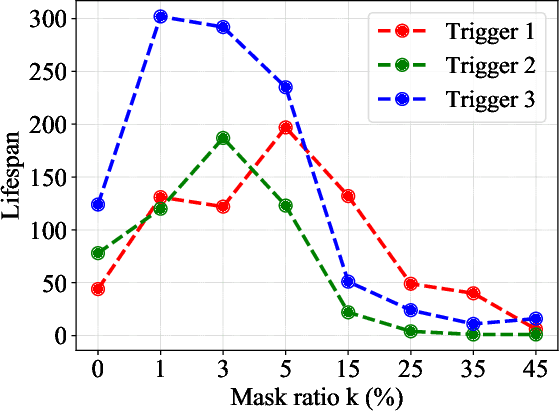
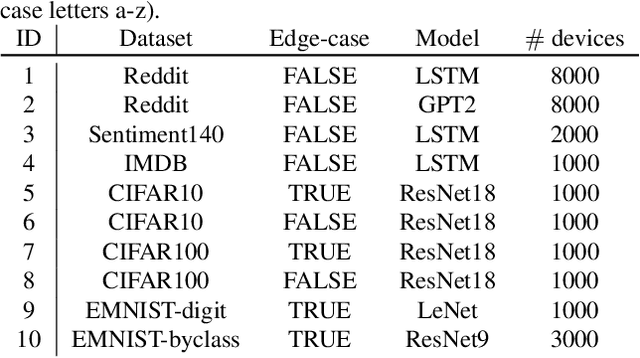
Due to their decentralized nature, federated learning (FL) systems have an inherent vulnerability during their training to adversarial backdoor attacks. In this type of attack, the goal of the attacker is to use poisoned updates to implant so-called backdoors into the learned model such that, at test time, the model's outputs can be fixed to a given target for certain inputs. (As a simple toy example, if a user types "people from New York" into a mobile keyboard app that uses a backdoored next word prediction model, then the model could autocomplete the sentence to "people from New York are rude"). Prior work has shown that backdoors can be inserted into FL models, but these backdoors are often not durable, i.e., they do not remain in the model after the attacker stops uploading poisoned updates. Thus, since training typically continues progressively in production FL systems, an inserted backdoor may not survive until deployment. Here, we propose Neurotoxin, a simple one-line modification to existing backdoor attacks that acts by attacking parameters that are changed less in magnitude during training. We conduct an exhaustive evaluation across ten natural language processing and computer vision tasks, and we find that we can double the durability of state of the art backdoors.
Squeezeformer: An Efficient Transformer for Automatic Speech Recognition
Jun 02, 2022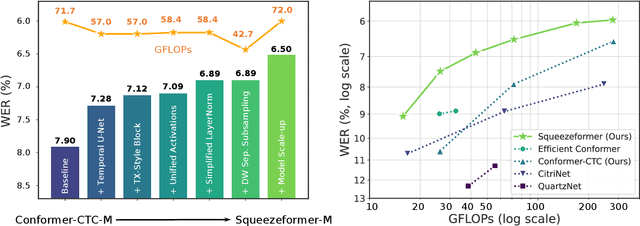
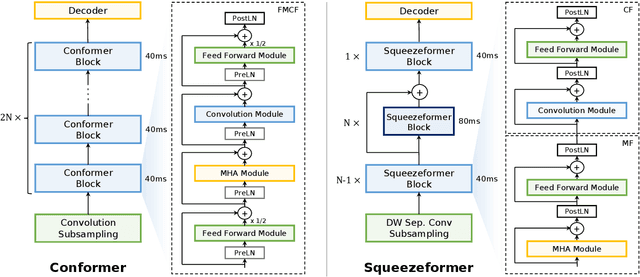
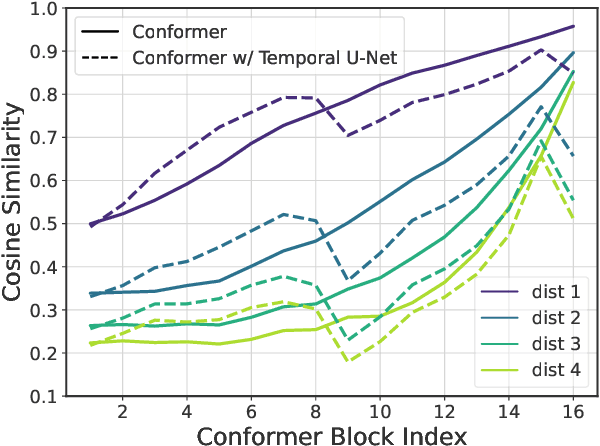
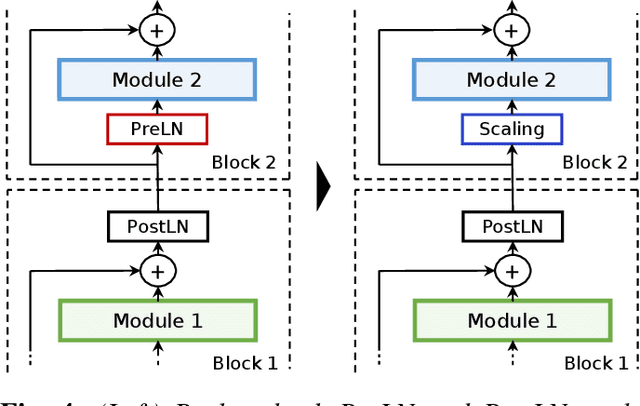
The recently proposed Conformer model has become the de facto backbone model for various downstream speech tasks based on its hybrid attention-convolution architecture that captures both local and global features. However, through a series of systematic studies, we find that the Conformer architecture's design choices are not optimal. After reexamining the design choices for both the macro and micro-architecture of Conformer, we propose the Squeezeformer model, which consistently outperforms the state-of-the-art ASR models under the same training schemes. In particular, for the macro-architecture, Squeezeformer incorporates (i) the Temporal U-Net structure, which reduces the cost of the multi-head attention modules on long sequences, and (ii) a simpler block structure of feed-forward module, followed up by multi-head attention or convolution modules, instead of the Macaron structure proposed in Conformer. Furthermore, for the micro-architecture, Squeezeformer (i) simplifies the activations in the convolutional block, (ii) removes redundant Layer Normalization operations, and (iii) incorporates an efficient depth-wise downsampling layer to efficiently sub-sample the input signal. Squeezeformer achieves state-of-the-art results of 7.5%, 6.5%, and 6.0% word-error-rate on Librispeech test-other without external language models. This is 3.1%, 1.4%, and 0.6% better than Conformer-CTC with the same number of FLOPs. Our code is open-sourced and available online.
Asymptotic Convergence Rate and Statistical Inference for Stochastic Sequential Quadratic Programming
May 27, 2022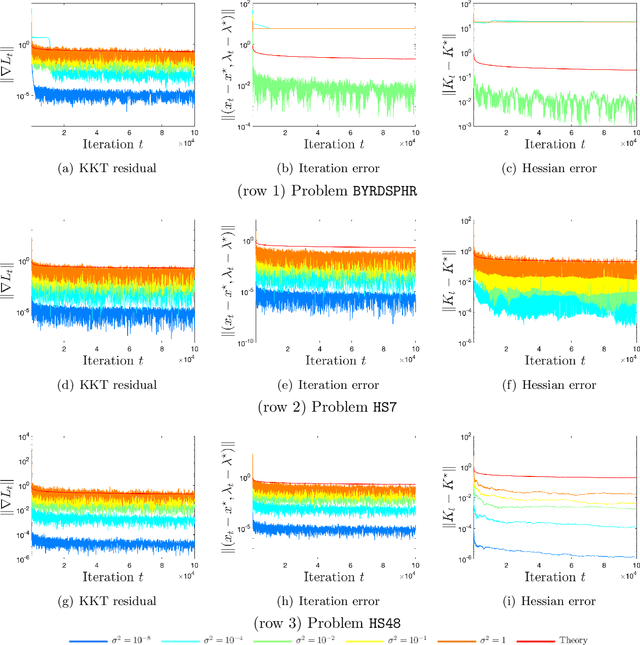
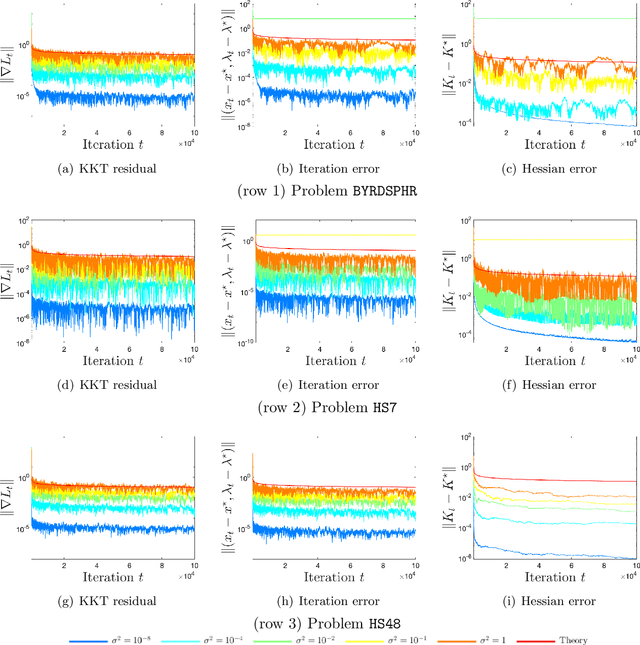
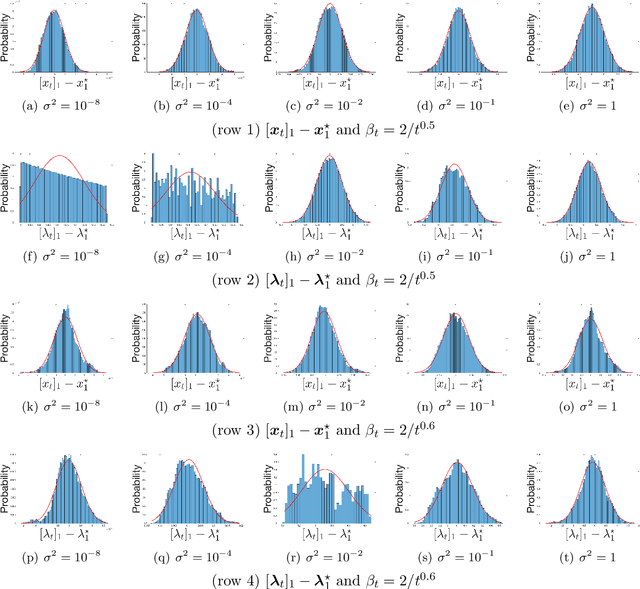
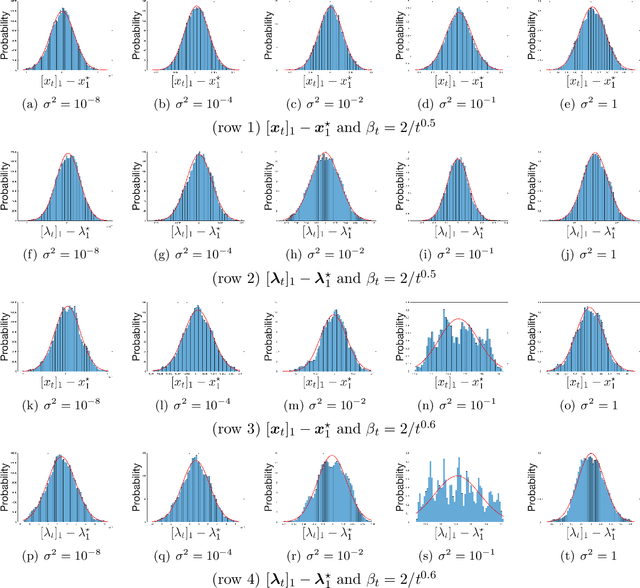
We apply a stochastic sequential quadratic programming (StoSQP) algorithm to solve constrained nonlinear optimization problems, where the objective is stochastic and the constraints are deterministic. We study a fully stochastic setup, where only a single sample is available in each iteration for estimating the gradient and Hessian of the objective. We allow StoSQP to select a random stepsize $\bar{\alpha}_t$ adaptively, such that $\beta_t\leq \bar{\alpha}_t \leq \beta_t+\chi_t$, where $\beta_t$, $\chi_t=o(\beta_t)$ are prespecified deterministic sequences. We also allow StoSQP to solve Newton system inexactly via randomized iterative solvers, e.g., with the sketch-and-project method; and we do not require the approximation error of inexact Newton direction to vanish. For this general StoSQP framework, we establish the asymptotic convergence rate for its last iterate, with the worst-case iteration complexity as a byproduct; and we perform statistical inference. In particular, with proper decaying $\beta_t,\chi_t$, we show that: (i) the StoSQP scheme can take at most $O(1/\epsilon^4)$ iterations to achieve $\epsilon$-stationarity; (ii) asymptotically and almost surely, $\|(x_t -x^\star, \lambda_t - \lambda^\star)\| = O(\sqrt{\beta_t\log(1/\beta_t)})+O(\chi_t/\beta_t)$, where $(x_t,\lambda_t)$ is the primal-dual StoSQP iterate; (iii) the sequence $1/\sqrt{\beta_t}\cdot (x_t -x^\star, \lambda_t - \lambda^\star)$ converges to a mean zero Gaussian distribution with a nontrivial covariance matrix. Moreover, we establish the Berry-Esseen bound for $(x_t, \lambda_t)$ to measure quantitatively the convergence of its distribution function. We also provide a practical estimator for the covariance matrix, from which the confidence intervals of $(x^\star, \lambda^\star)$ can be constructed using iterates $\{(x_t,\lambda_t)\}_t$. Our theorems are validated using nonlinear problems in CUTEst test set.
Fat-Tailed Variational Inference with Anisotropic Tail Adaptive Flows
May 16, 2022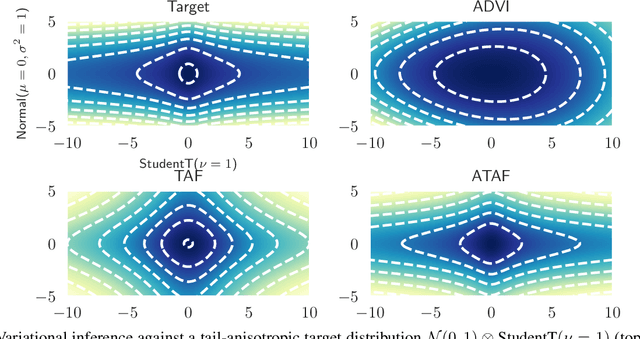

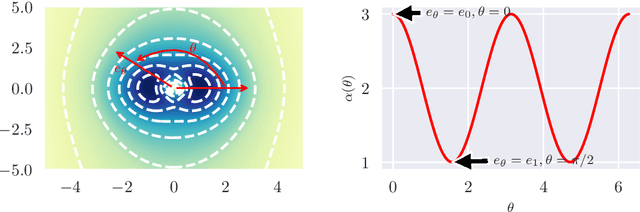

While fat-tailed densities commonly arise as posterior and marginal distributions in robust models and scale mixtures, they present challenges when Gaussian-based variational inference fails to capture tail decay accurately. We first improve previous theory on tails of Lipschitz flows by quantifying how the tails affect the rate of tail decay and by expanding the theory to non-Lipschitz polynomial flows. Then, we develop an alternative theory for multivariate tail parameters which is sensitive to tail-anisotropy. In doing so, we unveil a fundamental problem which plagues many existing flow-based methods: they can only model tail-isotropic distributions (i.e., distributions having the same tail parameter in every direction). To mitigate this and enable modeling of tail-anisotropic targets, we propose anisotropic tail-adaptive flows (ATAF). Experimental results on both synthetic and real-world targets confirm that ATAF is competitive with prior work while also exhibiting appropriate tail-anisotropy.