 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Skill Policies: Learning an Adaptable Skill-based Action Space for Reinforcement Learning for Robotics
Nov 04, 2022



Skill-based reinforcement learning (RL) has emerged as a promising strategy to leverage prior knowledge for accelerated robot learning. Skills are typically extracted from expert demonstrations and are embedded into a latent space from which they can be sampled as actions by a high-level RL agent. However, this skill space is expansive, and not all skills are relevant for a given robot state, making exploration difficult. Furthermore, the downstream RL agent is limited to learning structurally similar tasks to those used to construct the skill space. We firstly propose accelerating exploration in the skill space using state-conditioned generative models to directly bias the high-level agent towards only sampling skills relevant to a given state based on prior experience. Next, we propose a low-level residual policy for fine-grained skill adaptation enabling downstream RL agents to adapt to unseen task variations. Finally, we validate our approach across four challenging manipulation tasks that differ from those used to build the skill space, demonstrating our ability to learn across task variations while significantly accelerating exploration, outperforming prior works. Code and videos are available on our project website: https://krishanrana.github.io/reskill.
Boosting Performance of a Baseline Visual Place Recognition Technique by Predicting the Maximally Complementary Technique
Oct 14, 2022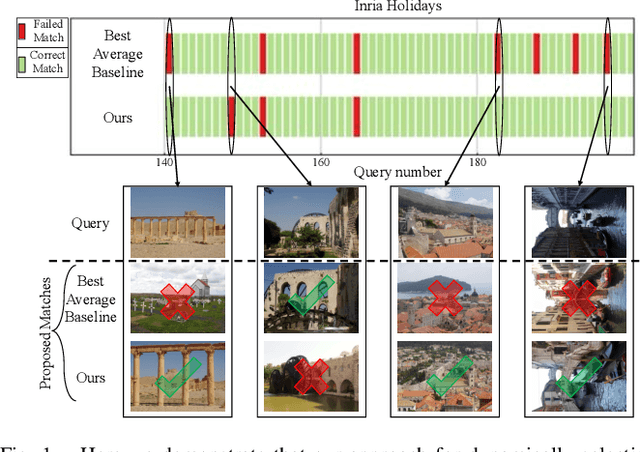
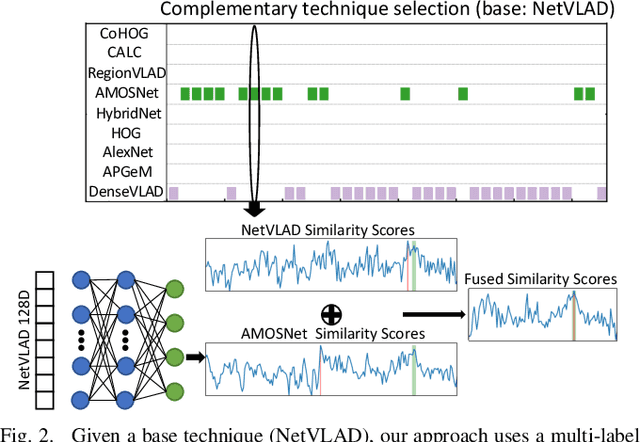
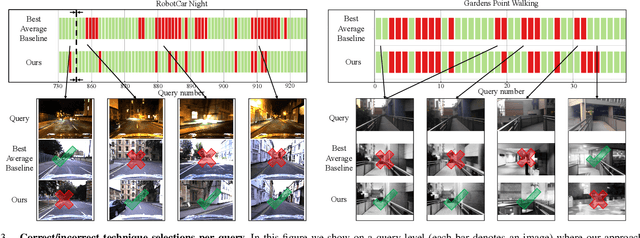
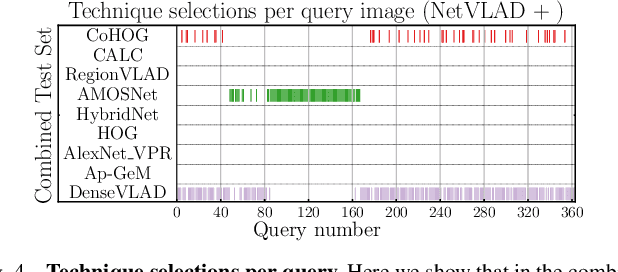
One recent promising approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques using methods such as SRAL and multi-process fusion. These approaches come with a substantial practical limitation: they require all potential VPR methods to be brute-force run before they are selectively fused. The obvious solution to this limitation is to predict the viable subset of methods ahead of time, but this is challenging because it requires a predictive signal within the imagery itself that is indicative of high performance methods. Here we propose an alternative approach that instead starts with a known single base VPR technique, and learns to predict the most complementary additional VPR technique to fuse with it, that results in the largest improvement in performance. The key innovation here is to use a dimensionally reduced difference vector between the query image and the top-retrieved reference image using this baseline technique as the predictive signal of the most complementary additional technique, both during training and inference. We demonstrate that our approach can train a single network to select performant, complementary technique pairs across datasets which span multiple modes of transportation (train, car, walking) as well as to generalise to unseen datasets, outperforming multiple baseline strategies for manually selecting the best technique pairs based on the same training data.
Merging Classification Predictions with Sequential Information for Lightweight Visual Place Recognition in Changing Environments
Oct 03, 2022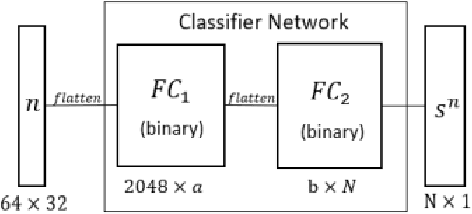
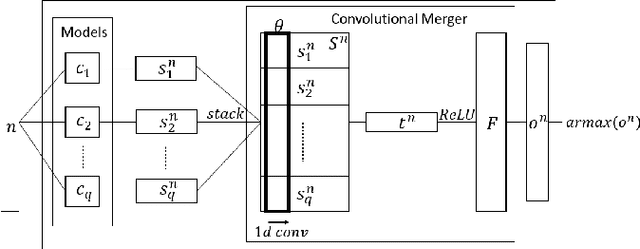
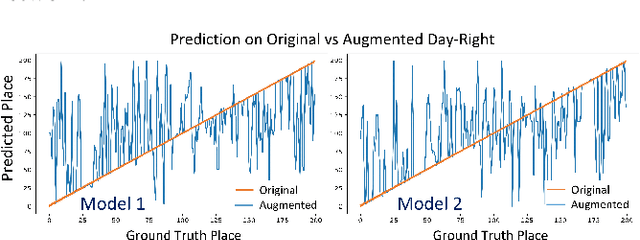
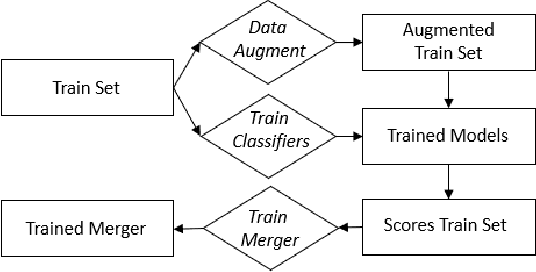
Low-overhead visual place recognition (VPR) is a highly active research topic. Mobile robotics applications often operate under low-end hardware, and even more hardware capable systems can still benefit from freeing up onboard system resources for other navigation tasks. This work addresses lightweight VPR by proposing a novel system based on the combination of binary-weighted classifier networks with a one-dimensional convolutional network, dubbed merger. Recent work in fusing multiple VPR techniques has mainly focused on increasing VPR performance, with computational efficiency not being highly prioritized. In contrast, we design our technique prioritizing low inference times, taking inspiration from the machine learning literature where the efficient combination of classifiers is a heavily researched topic. Our experiments show that the merger achieves inference times as low as 1 millisecond, being significantly faster than other well-established lightweight VPR techniques, while achieving comparable or superior VPR performance on several visual changes such as seasonal variations and viewpoint lateral shifts.
Ensembles of Compact, Region-specific & Regularized Spiking Neural Networks for Scalable Place Recognition
Sep 19, 2022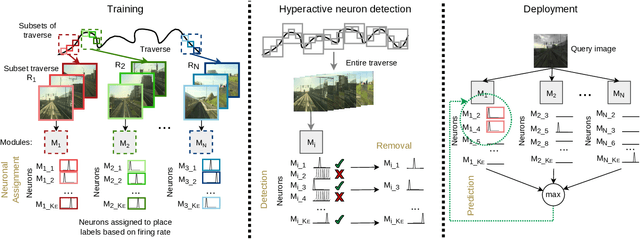
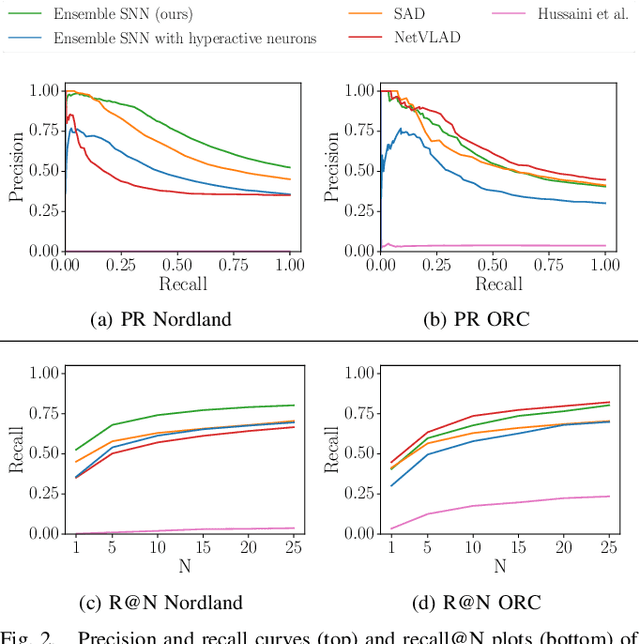
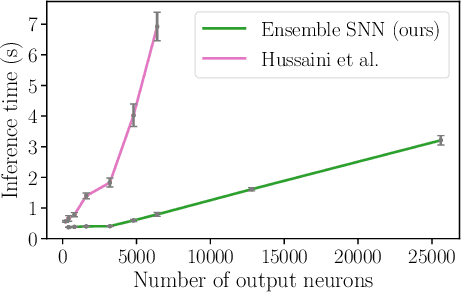
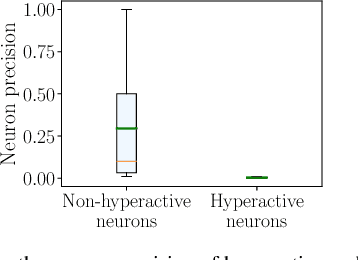
Spiking neural networks have significant potential utility in robotics due to their high energy efficiency on specialized hardware, but proof-of-concept implementations have not yet typically achieved competitive performance or capability with conventional approaches. In this paper, we tackle one of the key practical challenges of scalability by introducing a novel modular ensemble network approach, where compact, localized spiking networks each learn and are solely responsible for recognizing places in a local region of the environment only. This modular approach creates a highly scalable system. However, it comes with a high-performance cost where a lack of global regularization at deployment time leads to hyperactive neurons that erroneously respond to places outside their learned region. Our second contribution introduces a regularization approach that detects and removes these problematic hyperactive neurons during the initial environmental learning phase. We evaluate this new scalable modular system on benchmark localization datasets Nordland and Oxford RobotCar, with comparisons to both standard techniques NetVLAD and SAD, and a previous spiking neural network system. Our system substantially outperforms the previous SNN system on its small dataset, but also maintains performance on 27 times larger benchmark datasets where the operation of the previous system is computationally infeasible, and performs competitively with the conventional localization systems.
Data Efficient Visual Place Recognition Using Extremely JPEG-Compressed Images
Sep 17, 2022
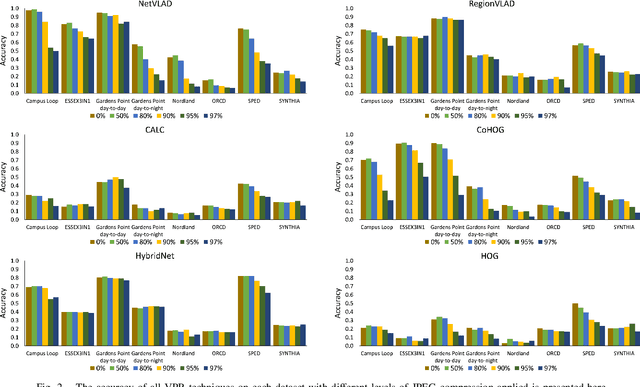
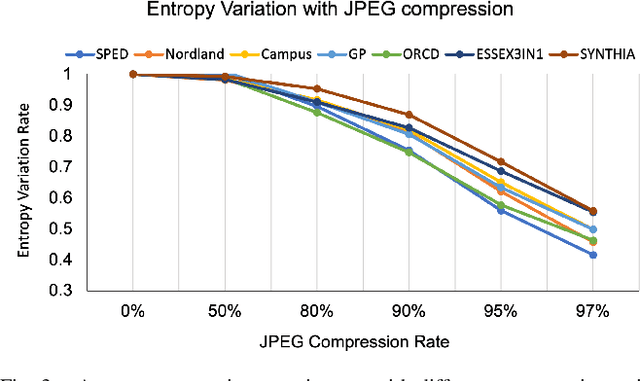

Visual Place Recognition (VPR) is the ability of a robotic platform to correctly interpret visual stimuli from its on-board cameras in order to determine whether it is currently located in a previously visited place, despite different viewpoint, illumination and appearance changes. JPEG is a widely used image compression standard that is capable of significantly reducing the size of an image at the cost of image clarity. For applications where several robotic platforms are simultaneously deployed, the visual data gathered must be transmitted remotely between each robot. Hence, JPEG compression can be employed to drastically reduce the amount of data transmitted over a communication channel, as working with limited bandwidth for VPR can be proven to be a challenging task. However, the effects of JPEG compression on the performance of current VPR techniques have not been previously studied. For this reason, this paper presents an in-depth study of JPEG compression in VPR related scenarios. We use a selection of well-established VPR techniques on 8 datasets with various amounts of compression applied. We show that by introducing compression, the VPR performance is drastically reduced, especially in the higher spectrum of compression. To overcome the negative effects of JPEG compression on the VPR performance, we present a fine-tuned CNN which is optimized for JPEG compressed data and show that it performs more consistently with the image transformations detected in extremely compressed JPEG images.
Improving Worst Case Visual Localization Coverage via Place-specific Sub-selection in Multi-camera Systems
Jun 28, 2022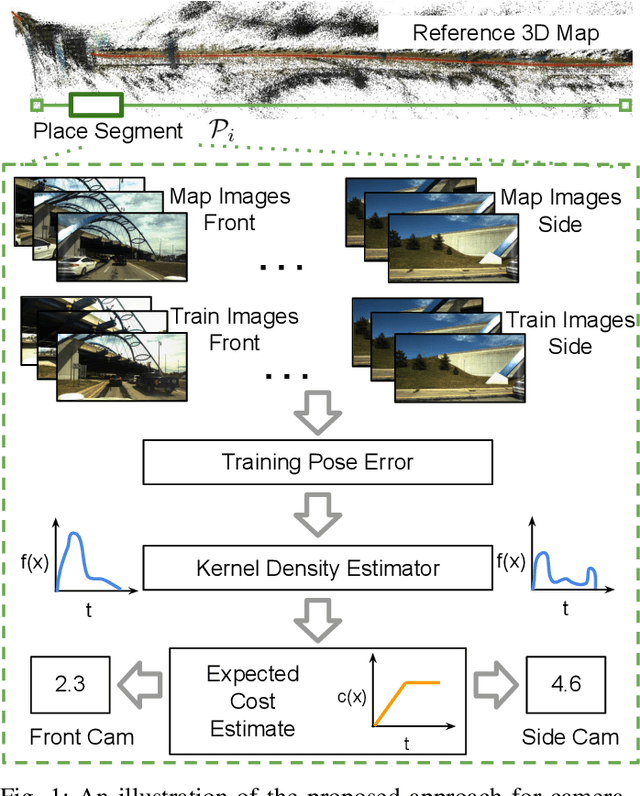
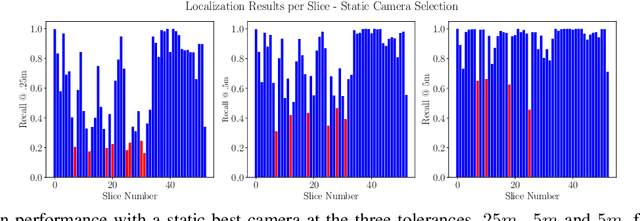
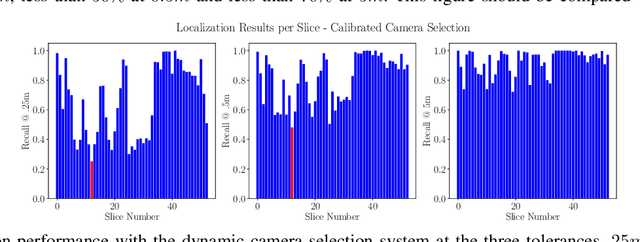
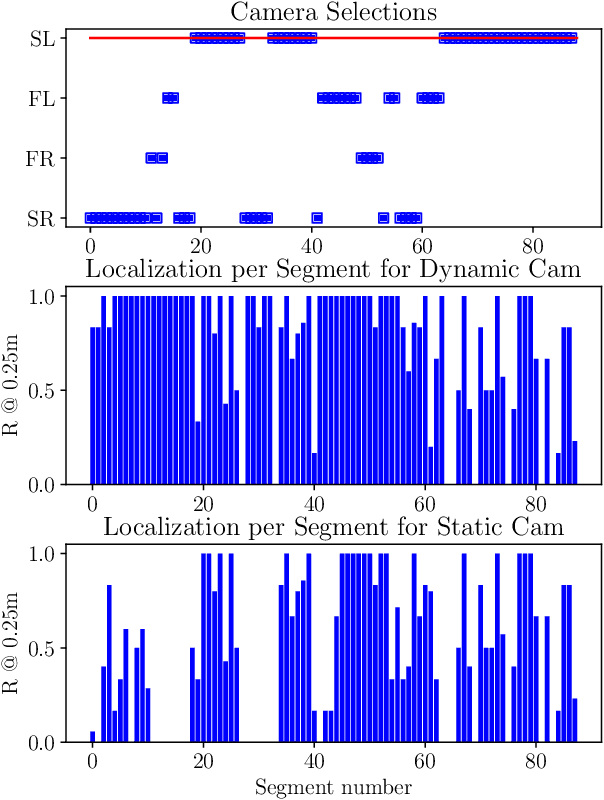
6-DoF visual localization systems utilize principled approaches rooted in 3D geometry to perform accurate camera pose estimation of images to a map. Current techniques use hierarchical pipelines and learned 2D feature extractors to improve scalability and increase performance. However, despite gains in typical recall@0.25m type metrics, these systems still have limited utility for real-world applications like autonomous vehicles because of their `worst' areas of performance - the locations where they provide insufficient recall at a certain required error tolerance. Here we investigate the utility of using `place specific configurations', where a map is segmented into a number of places, each with its own configuration for modulating the pose estimation step, in this case selecting a camera within a multi-camera system. On the Ford AV benchmark dataset, we demonstrate substantially improved worst-case localization performance compared to using off-the-shelf pipelines - minimizing the percentage of the dataset which has low recall at a certain error tolerance, as well as improved overall localization performance. Our proposed approach is particularly applicable to the crowdsharing model of autonomous vehicle deployment, where a fleet of AVs are regularly traversing a known route.
How Many Events do You Need? Event-based Visual Place Recognition Using Sparse But Varying Pixels
Jun 28, 2022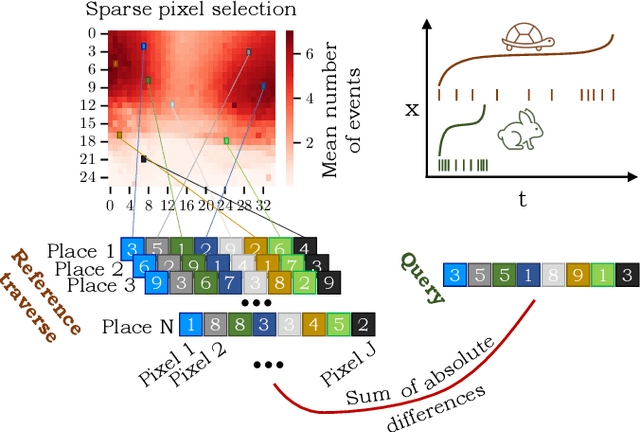
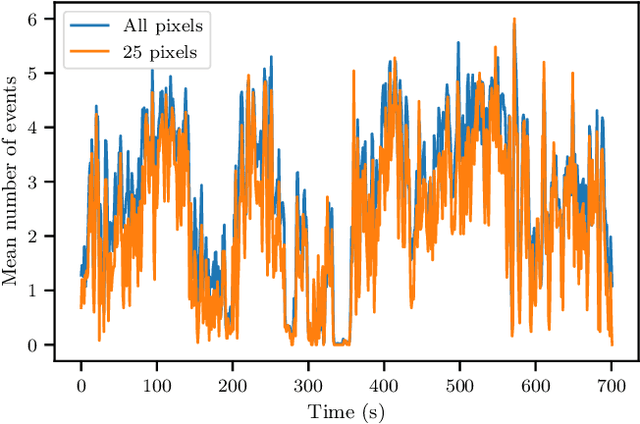
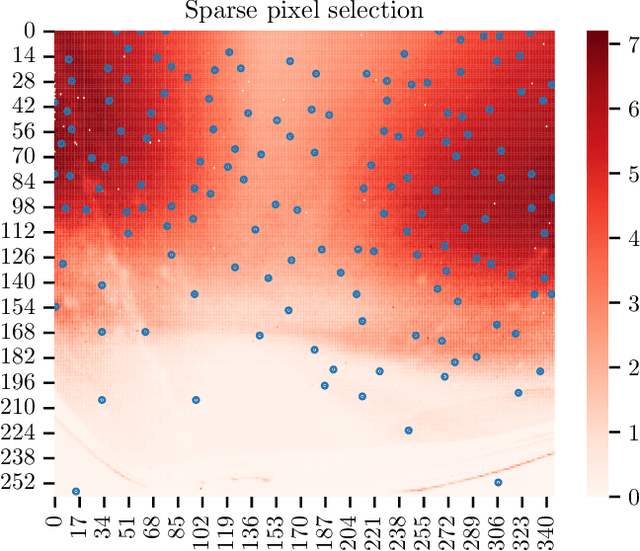

Event cameras continue to attract interest due to desirable characteristics such as high dynamic range, low latency, virtually no motion blur, and high energy efficiency. One of the potential applications of event camera research lies in visual place recognition for robot localization, where a query observation has to be matched to the corresponding reference place in the database. In this letter, we explore the distinctiveness of event streams from a small subset of pixels (in the tens or hundreds). We demonstrate that the absolute difference in the number of events at those pixel locations accumulated into event frames can be sufficient for the place recognition task, when pixels that display large variations in the reference set are used. Using such sparse (over image coordinates) but varying (variance over the number of events per pixel location) pixels enables frequent and computationally cheap updates of the location estimates. Furthermore, when event frames contain a constant number of events, our method takes full advantage of the event-driven nature of the sensory stream and displays promising robustness to changes in velocity. We evaluate our proposed approach on the Brisbane-Event-VPR dataset in an outdoor driving scenario, as well as the newly contributed indoor QCR-Event-VPR dataset that was captured with a DAVIS346 camera mounted on a mobile robotic platform. Our results show that our approach achieves competitive performance when compared to several baseline methods on those datasets, and is particularly well suited for compute- and energy-constrained platforms such as interplanetary rovers.
Improving Road Segmentation in Challenging Domains Using Similar Place Priors
May 27, 2022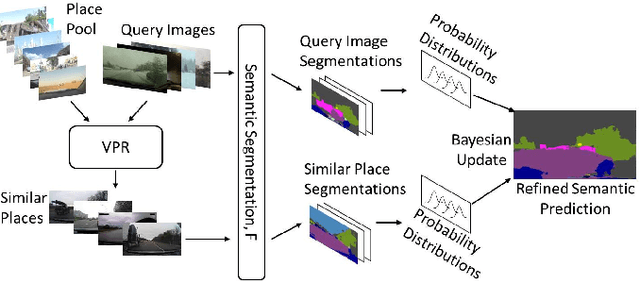
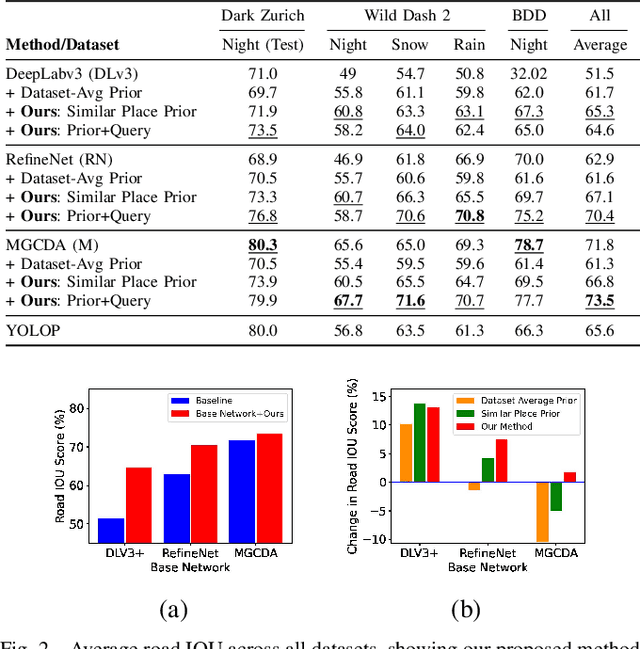
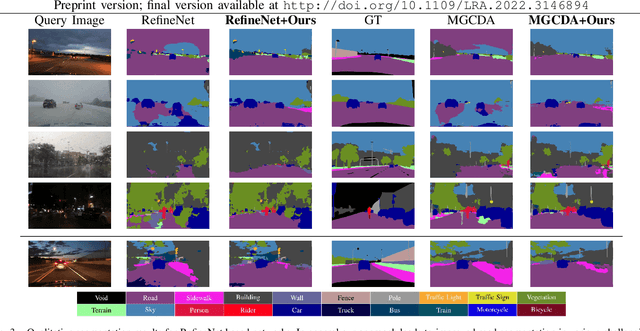
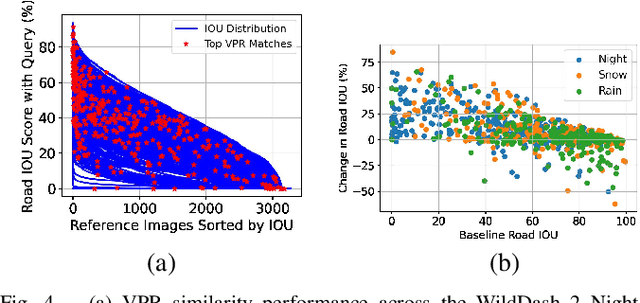
Road segmentation in challenging domains, such as night, snow or rain, is a difficult task. Most current approaches boost performance using fine-tuning, domain adaptation, style transfer, or by referencing previously acquired imagery. These approaches share one or more of three significant limitations: a reliance on large amounts of annotated training data that can be costly to obtain, both anticipation of and training data from the type of environmental conditions expected at inference time, and/or imagery captured from a previous visit to the location. In this research, we remove these restrictions by improving road segmentation based on similar places. We use Visual Place Recognition (VPR) to find similar but geographically distinct places, and fuse segmentations for query images and these similar place priors using a Bayesian approach and novel segmentation quality metric. Ablation studies show the need to re-evaluate notions of VPR utility for this task. We demonstrate the system achieving state-of-the-art road segmentation performance across multiple challenging condition scenarios including night time and snow, without requiring any prior training or previous access to the same geographical locations. Furthermore, we show that this method is network agnostic, improves multiple baseline techniques and is competitive against methods specialised for road prediction.
* Accepted into IEEE Robotics and Automation Letters (RA-L) and presented at IEEE International Conference on Robotics and Automation (ICRA 2022)
ReF -- Rotation Equivariant Features for Local Feature Matching
Mar 10, 2022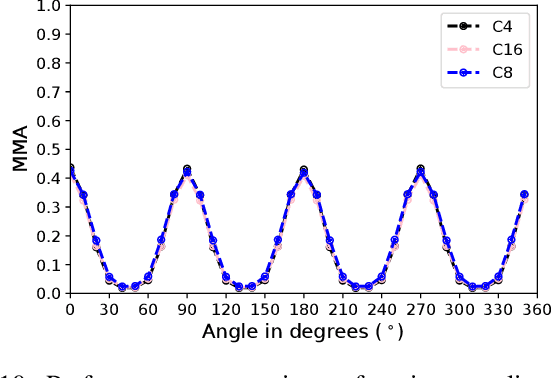
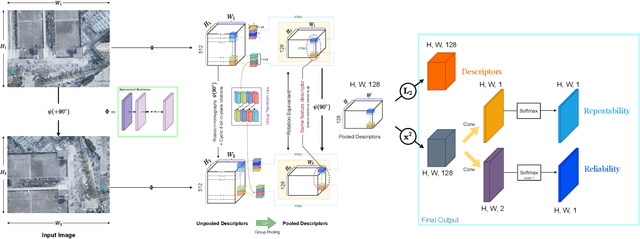

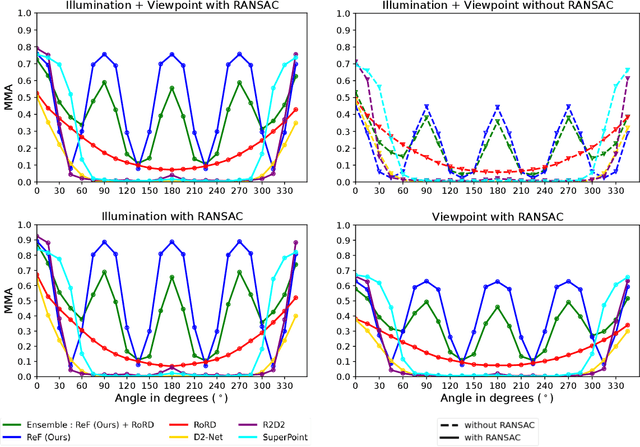
Sparse local feature matching is pivotal for many computer vision and robotics tasks. To improve their invariance to challenging appearance conditions and viewing angles, and hence their usefulness, existing learning-based methods have primarily focused on data augmentation-based training. In this work, we propose an alternative, complementary approach that centers on inducing bias in the model architecture itself to generate `rotation-specific' features using Steerable E2-CNNs, that are then group-pooled to achieve rotation-invariant local features. We demonstrate that this high performance, rotation-specific coverage from the steerable CNNs can be expanded to all rotation angles by combining it with augmentation-trained standard CNNs which have broader coverage but are often inaccurate, thus creating a state-of-the-art rotation-robust local feature matcher. We benchmark our proposed methods against existing techniques on HPatches and a newly proposed UrbanScenes3D-Air dataset for visual place recognition. Furthermore, we present a detailed analysis of the performance effects of ensembling, robust estimation, network architecture variations, and the use of rotation priors.
SwitchHit: A Probabilistic, Complementarity-Based Switching System for Improved Visual Place Recognition in Changing Environments
Mar 01, 2022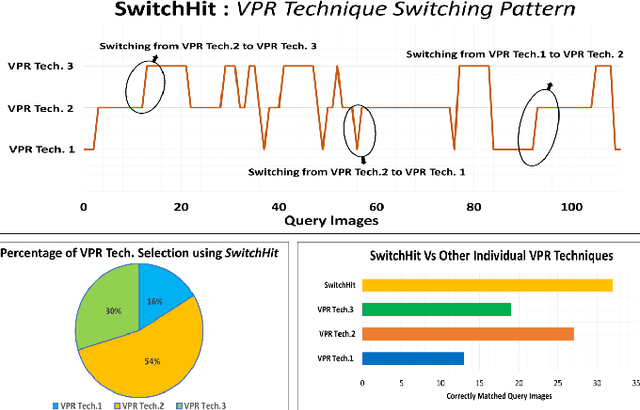
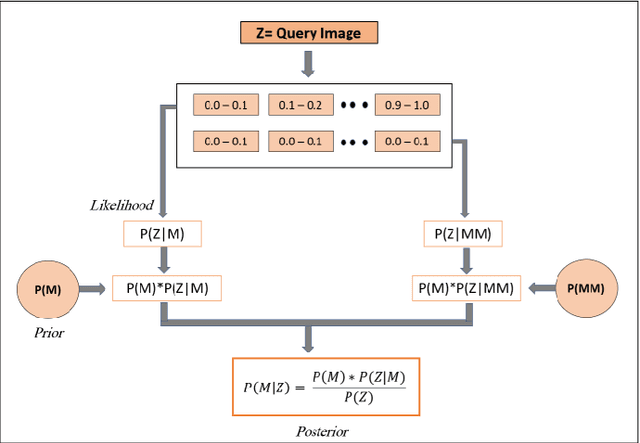
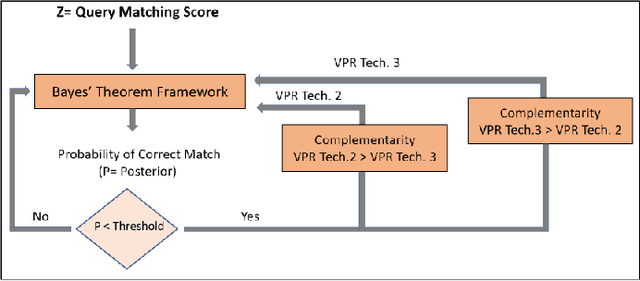
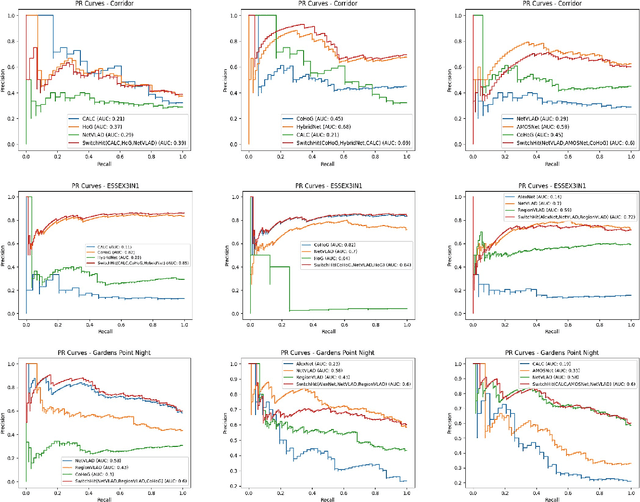
Visual place recognition (VPR), a fundamental task in computer vision and robotics, is the problem of identifying a place mainly based on visual information. Viewpoint and appearance changes, such as due to weather and seasonal variations, make this task challenging. Currently, there is no universal VPR technique that can work in all types of environments, on a variety of robotic platforms, and under a wide range of viewpoint and appearance changes. Recent work has shown the potential of combining different VPR methods intelligently by evaluating complementarity for some specific VPR datasets to achieve better performance. This, however, requires ground truth information (correct matches) which is not available when a robot is deployed in a real-world scenario. Moreover, running multiple VPR techniques in parallel may be prohibitive for resource-constrained embedded platforms. To overcome these limitations, this paper presents a probabilistic complementarity based switching VPR system, SwitchHit. Our proposed system consists of multiple VPR techniques, however, it does not simply run all techniques at once, rather predicts the probability of correct match for an incoming query image and dynamically switches to another complementary technique if the probability of correctly matching the query is below a certain threshold. This innovative use of multiple VPR techniques allow our system to be more efficient and robust than other combined VPR approaches employing brute force and running multiple VPR techniques at once. Thus making it more suitable for resource constrained embedded systems and achieving an overall superior performance from what any individual VPR method in the system could have by achieved running independently.