 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Risk-Sensitive Reinforcement Learning Agents for Trading Markets
Jul 16, 2021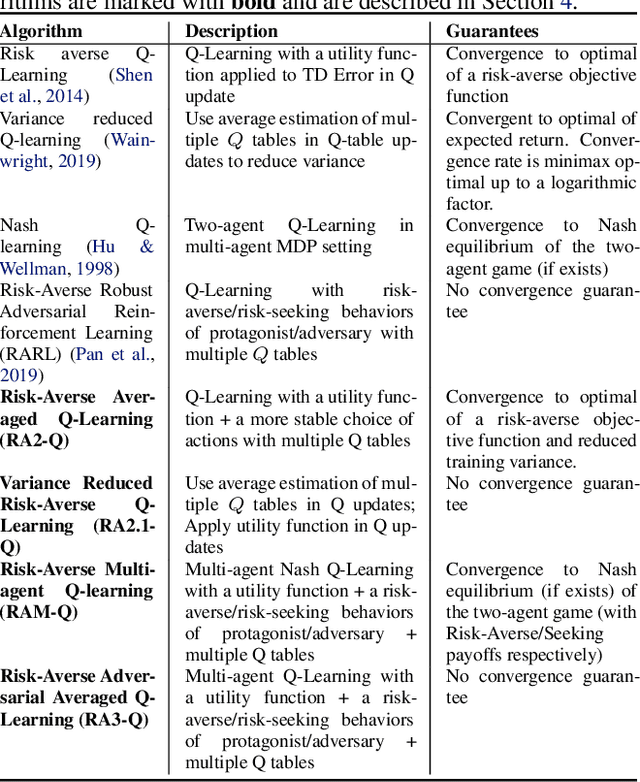
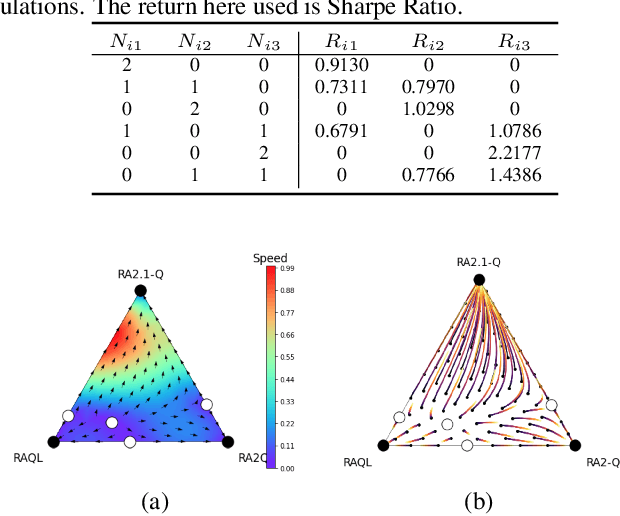
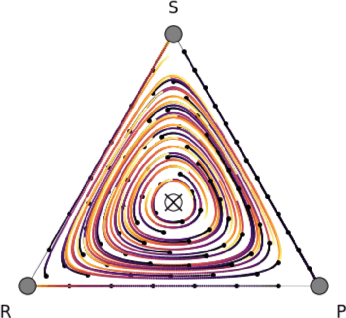
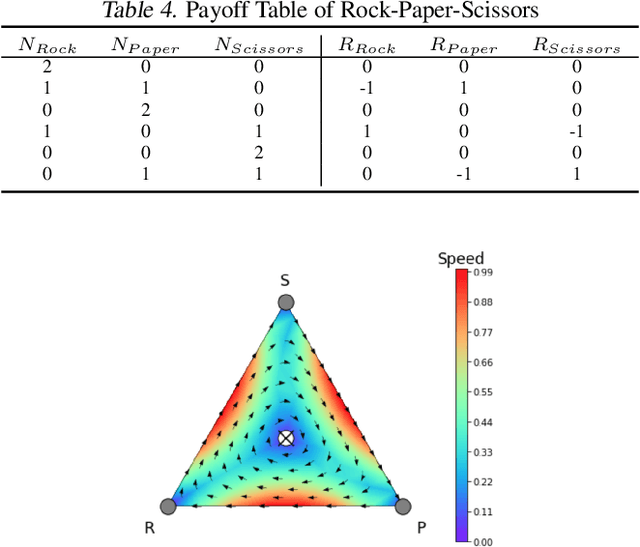
Trading markets represent a real-world financial application to deploy reinforcement learning agents, however, they carry hard fundamental challenges such as high variance and costly exploration. Moreover, markets are inherently a multiagent domain composed of many actors taking actions and changing the environment. To tackle these type of scenarios agents need to exhibit certain characteristics such as risk-awareness, robustness to perturbations and low learning variance. We take those as building blocks and propose a family of four algorithms. First, we contribute with two algorithms that use risk-averse objective functions and variance reduction techniques. Then, we augment the framework to multi-agent learning and assume an adversary which can take over and perturb the learning process. Our third and fourth algorithms perform well under this setting and balance theoretical guarantees with practical use. Additionally, we consider the multi-agent nature of the environment and our work is the first one extending empirical game theory analysis for multi-agent learning by considering risk-sensitive payoffs.
CDT: Cascading Decision Trees for Explainable Reinforcement Learning
Nov 15, 2020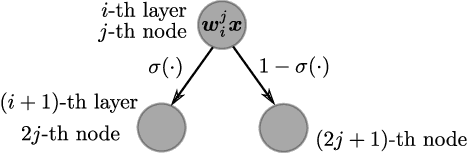
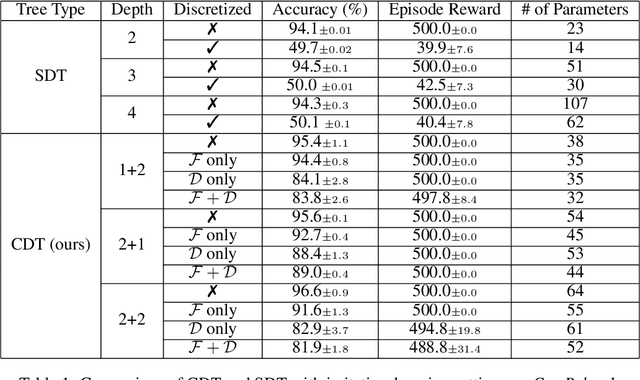
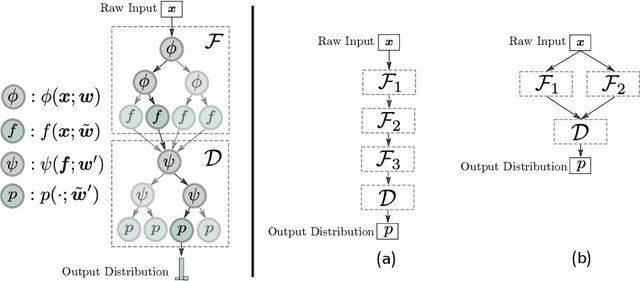
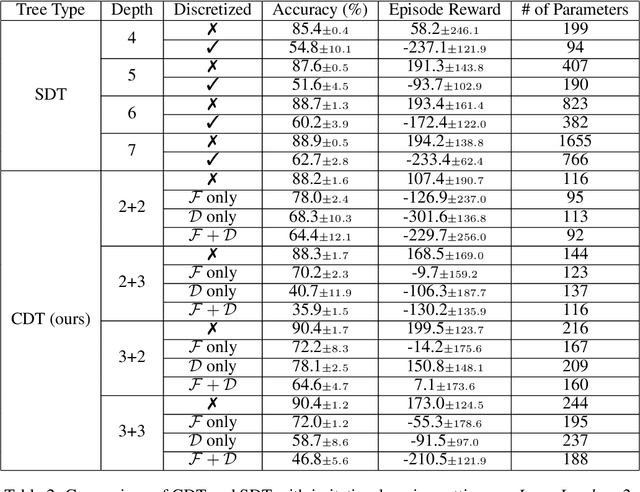
Deep Reinforcement Learning (DRL) has recently achieved significant advances in various domains. However, explaining the policy of RL agents still remains an open problem due to several factors, one being the complexity of explaining neural networks decisions. Recently, a group of works have used decision-tree-based models to learn explainable policies. Soft decision trees (SDTs) and discretized differentiable decision trees (DDTs) have been demonstrated to achieve both good performance and share the benefit of having explainable policies. In this work, we further improve the results for tree-based explainable RL in both performance and explainability. Our proposal, Cascading Decision Trees (CDTs) apply representation learning on the decision path to allow richer expressivity. Empirical results show that in both situations, where CDTs are used as policy function approximators or as imitation learners to explain black-box policies, CDTs can achieve better performances with more succinct and explainable models than SDTs. As a second contribution our study reveals limitations of explaining black-box policies via imitation learning with tree-based explainable models, due to its inherent instability.
Work in Progress: Temporally Extended Auxiliary Tasks
Apr 16, 2020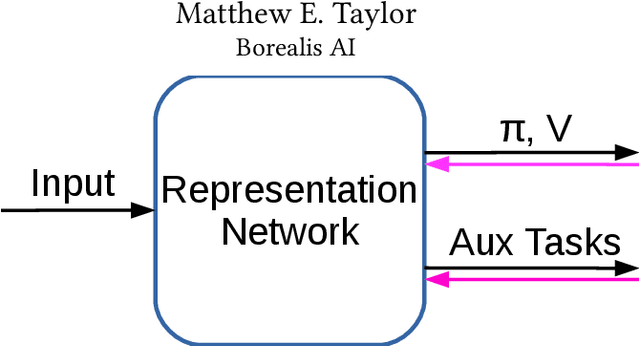

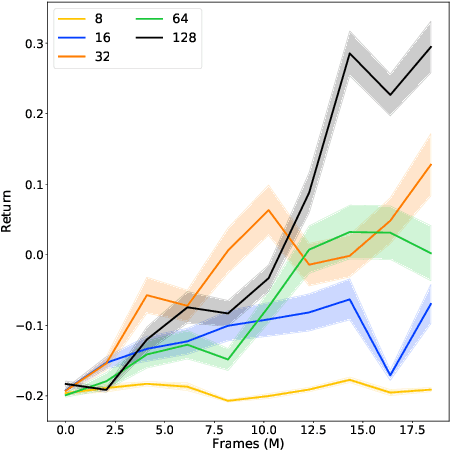
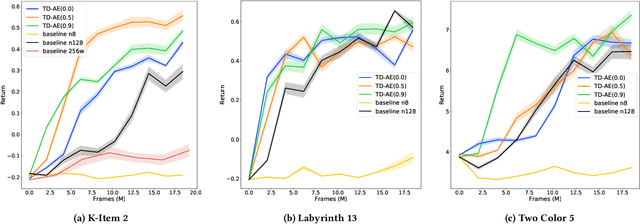
Predictive auxiliary tasks have been shown to improve performance in numerous reinforcement learning works, however, this effect is still not well understood. The primary purpose of the work presented here is to investigate the impact that an auxiliary task's prediction timescale has on the agent's policy performance. We consider auxiliary tasks which learn to make on-policy predictions using temporal difference learning. We test the impact of prediction timescale using a specific form of auxiliary task in which the input image is used as the prediction target, which we refer to as temporal difference autoencoders (TD-AE). We empirically evaluate the effect of TD-AE on the A2C algorithm in the VizDoom environment using different prediction timescales. While we do not observe a clear relationship between the prediction timescale on performance, we make the following observations: 1) using auxiliary tasks allows us to reduce the trajectory length of the A2C algorithm, 2) in some cases temporally extended TD-AE performs better than a straight autoencoder, 3) performance with auxiliary tasks is sensitive to the weight placed on the auxiliary loss, 4) despite this sensitivity, auxiliary tasks improved performance without extensive hyper-parameter tuning. Our overall conclusions are that TD-AE increases the robustness of the A2C algorithm to the trajectory length and while promising, further study is required to fully understand the relationship between auxiliary task prediction timescale and the agent's performance.
On Hard Exploration for Reinforcement Learning: a Case Study in Pommerman
Jul 26, 2019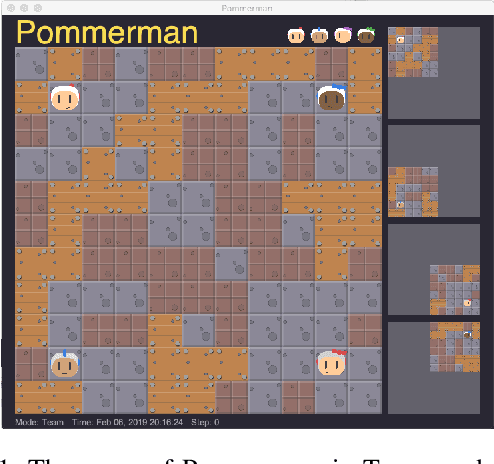
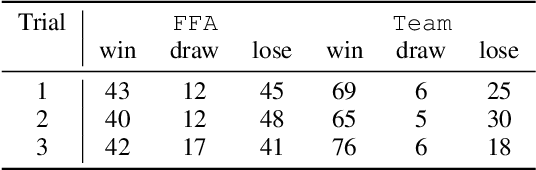
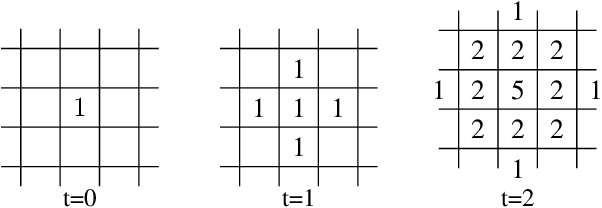
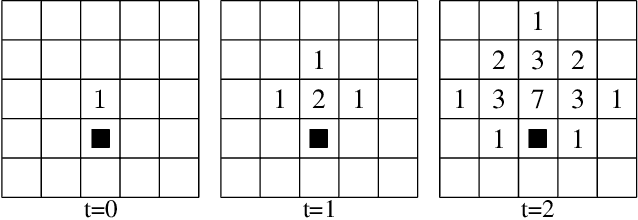
How to best explore in domains with sparse, delayed, and deceptive rewards is an important open problem for reinforcement learning (RL). This paper considers one such domain, the recently-proposed multi-agent benchmark of Pommerman. This domain is very challenging for RL --- past work has shown that model-free RL algorithms fail to achieve significant learning without artificially reducing the environment's complexity. In this paper, we illuminate reasons behind this failure by providing a thorough analysis on the hardness of random exploration in Pommerman. While model-free random exploration is typically futile, we develop a model-based automatic reasoning module that can be used for safer exploration by pruning actions that will surely lead the agent to death. We empirically demonstrate that this module can significantly improve learning.
Action Guidance with MCTS for Deep Reinforcement Learning
Jul 25, 2019
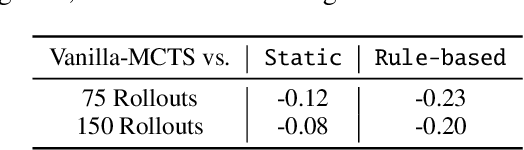
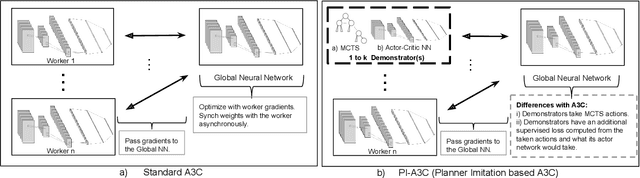
Deep reinforcement learning has achieved great successes in recent years, however, one main challenge is the sample inefficiency. In this paper, we focus on how to use action guidance by means of a non-expert demonstrator to improve sample efficiency in a domain with sparse, delayed, and possibly deceptive rewards: the recently-proposed multi-agent benchmark of Pommerman. We propose a new framework where even a non-expert simulated demonstrator, e.g., planning algorithms such as Monte Carlo tree search with a small number rollouts, can be integrated within asynchronous distributed deep reinforcement learning methods. Compared to a vanilla deep RL algorithm, our proposed methods both learn faster and converge to better policies on a two-player mini version of the Pommerman game.
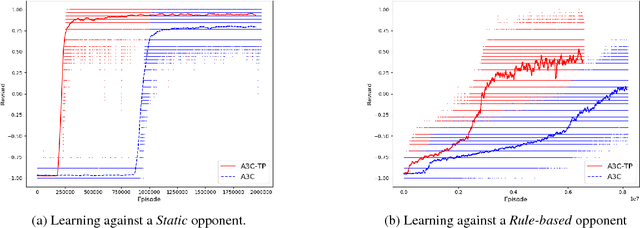
Terminal Prediction as an Auxiliary Task for Deep Reinforcement Learning
Jul 24, 2019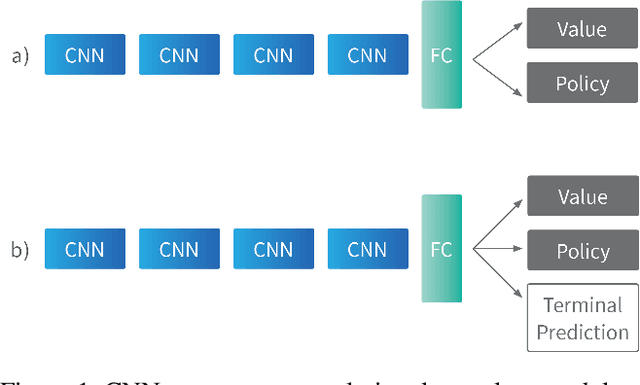

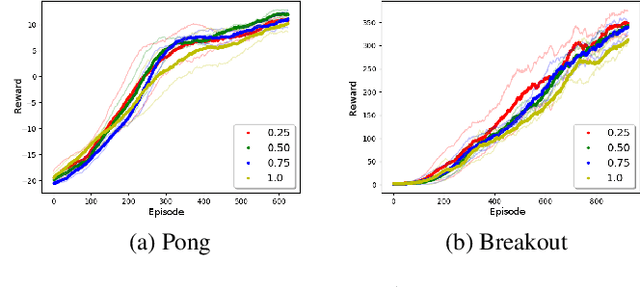

Deep reinforcement learning has achieved great successes in recent years, but there are still open challenges, such as convergence to locally optimal policies and sample inefficiency. In this paper, we contribute a novel self-supervised auxiliary task, i.e., Terminal Prediction (TP), estimating temporal closeness to terminal states for episodic tasks. The intuition is to help representation learning by letting the agent predict how close it is to a terminal state, while learning its control policy. Although TP could be integrated with multiple algorithms, this paper focuses on Asynchronous Advantage Actor-Critic (A3C) and demonstrating the advantages of A3C-TP. Our extensive evaluation includes: a set of Atari games, the BipedalWalker domain, and a mini version of the recently proposed multi-agent Pommerman game. Our results on Atari games and the BipedalWalker domain suggest that A3C-TP outperforms standard A3C in most of the tested domains and in others it has similar performance. In Pommerman, our proposed method provides significant improvement both in learning efficiency and converging to better policies against different opponents.
Agent Modeling as Auxiliary Task for Deep Reinforcement Learning
Jul 22, 2019
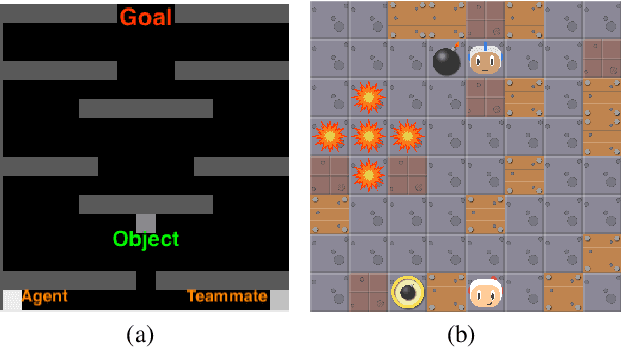
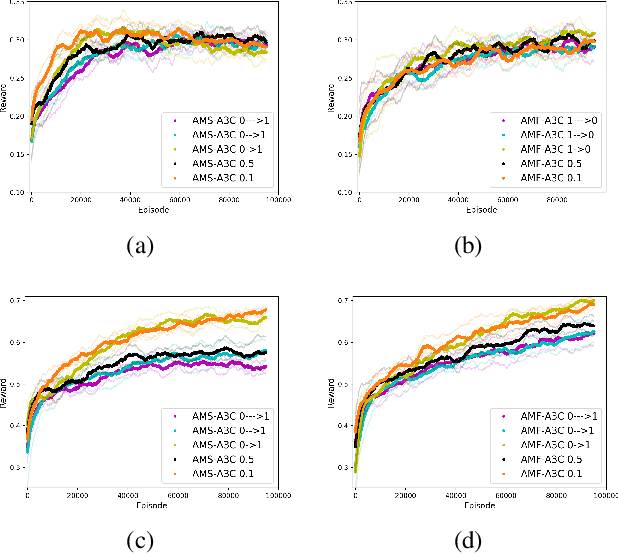
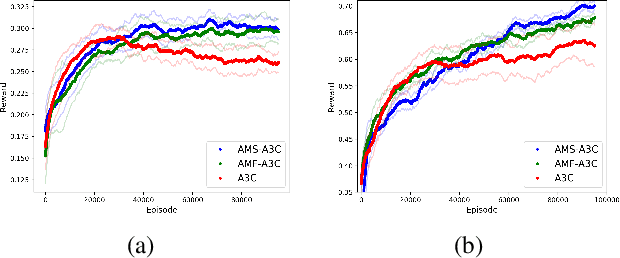
In this paper we explore how actor-critic methods in deep reinforcement learning, in particular Asynchronous Advantage Actor-Critic (A3C), can be extended with agent modeling. Inspired by recent works on representation learning and multiagent deep reinforcement learning, we propose two architectures to perform agent modeling: the first one based on parameter sharing, and the second one based on agent policy features. Both architectures aim to learn other agents' policies as auxiliary tasks, besides the standard actor (policy) and critic (values). We performed experiments in both cooperative and competitive domains. The former is a problem of coordinated multiagent object transportation and the latter is a two-player mini version of the Pommerman game. Our results show that the proposed architectures stabilize learning and outperform the standard A3C architecture when learning a best response in terms of expected rewards.
Skynet: A Top Deep RL Agent in the Inaugural Pommerman Team Competition
Apr 20, 2019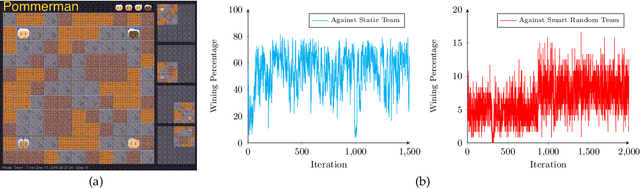

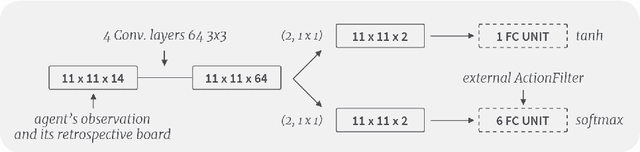

The Pommerman Team Environment is a recently proposed benchmark which involves a multi-agent domain with challenges such as partial observability, decentralized execution (without communication), and very sparse and delayed rewards. The inaugural Pommerman Team Competition held at NeurIPS 2018 hosted 25 participants who submitted a team of 2 agents. Our submission nn_team_skynet955_skynet955 won 2nd place of the "learning agents'' category. Our team is composed of 2 neural networks trained with state of the art deep reinforcement learning algorithms and makes use of concepts like reward shaping, curriculum learning, and an automatic reasoning module for action pruning. Here, we describe these elements and additionally we present a collection of open-sourced agents that can be used for training and testing in the Pommerman environment. Code available at: https://github.com/BorealisAI/pommerman-baseline
Safer Deep RL with Shallow MCTS: A Case Study in Pommerman
Apr 10, 2019
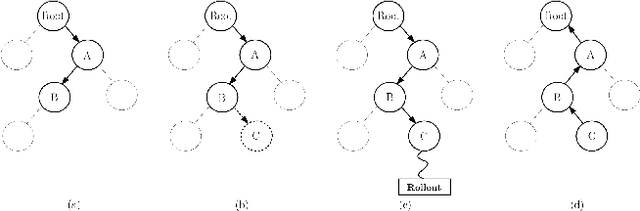
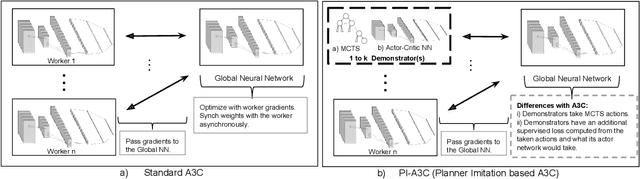
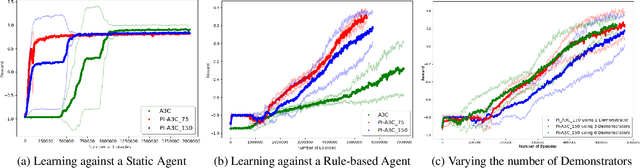
Safe reinforcement learning has many variants and it is still an open research problem. Here, we focus on how to use action guidance by means of a non-expert demonstrator to avoid catastrophic events in a domain with sparse, delayed, and deceptive rewards: the recently-proposed multi-agent benchmark of Pommerman. This domain is very challenging for reinforcement learning (RL) --- past work has shown that model-free RL algorithms fail to achieve significant learning. In this paper, we shed light into the reasons behind this failure by exemplifying and analyzing the high rate of catastrophic events (i.e., suicides) that happen under random exploration in this domain. While model-free random exploration is typically futile, we propose a new framework where even a non-expert simulated demonstrator, e.g., planning algorithms such as Monte Carlo tree search with small number of rollouts, can be integrated to asynchronous distributed deep reinforcement learning methods. Compared to vanilla deep RL algorithms, our proposed methods both learn faster and converge to better policies on a two-player mini version of the Pommerman game.
Using Monte Carlo Tree Search as a Demonstrator within Asynchronous Deep RL
Nov 30, 2018
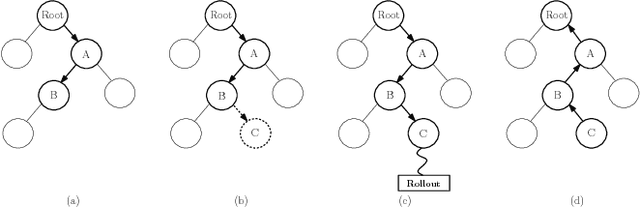
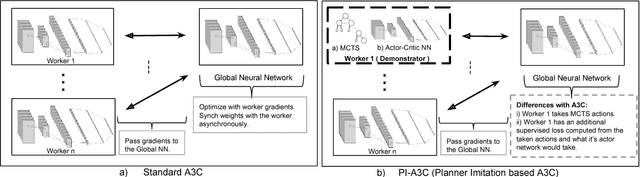
Deep reinforcement learning (DRL) has achieved great successes in recent years with the help of novel methods and higher compute power. However, there are still several challenges to be addressed such as convergence to locally optimal policies and long training times. In this paper, firstly, we augment Asynchronous Advantage Actor-Critic (A3C) method with a novel self-supervised auxiliary task, i.e. \emph{Terminal Prediction}, measuring temporal closeness to terminal states, namely A3C-TP. Secondly, we propose a new framework where planning algorithms such as Monte Carlo tree search or other sources of (simulated) demonstrators can be integrated to asynchronous distributed DRL methods. Compared to vanilla A3C, our proposed methods both learn faster and converge to better policies on a two-player mini version of the Pommerman game.