 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Sample-Efficient Function Approximation in Reinforcement Learning
Sep 30, 2022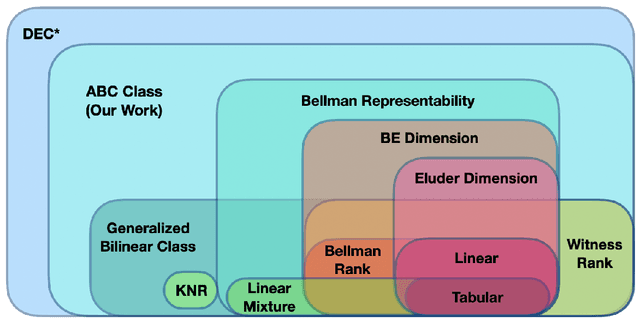
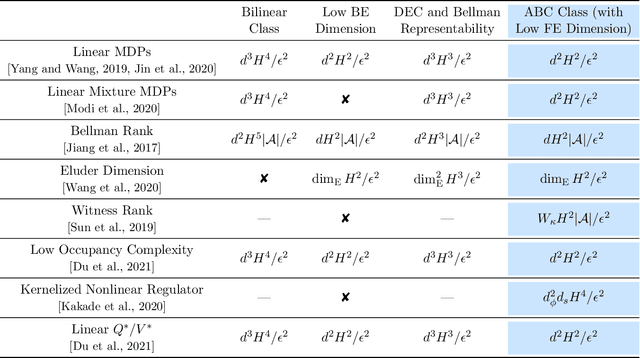
With the increasing need for handling large state and action spaces, general function approximation has become a key technique in reinforcement learning (RL). In this paper, we propose a general framework that unifies model-based and model-free RL, and an Admissible Bellman Characterization (ABC) class that subsumes nearly all Markov Decision Process (MDP) models in the literature for tractable RL. We propose a novel estimation function with decomposable structural properties for optimization-based exploration and the functional eluder dimension as a complexity measure of the ABC class. Under our framework, a new sample-efficient algorithm namely OPtimization-based ExploRation with Approximation (OPERA) is proposed, achieving regret bounds that match or improve over the best-known results for a variety of MDP models. In particular, for MDPs with low Witness rank, under a slightly stronger assumption, OPERA improves the state-of-the-art sample complexity results by a factor of $dH$. Our framework provides a generic interface to design and analyze new RL models and algorithms.
Gradient-Free Methods for Deterministic and Stochastic Nonsmooth Nonconvex Optimization
Sep 12, 2022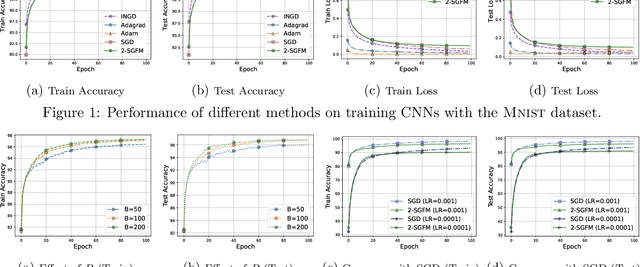
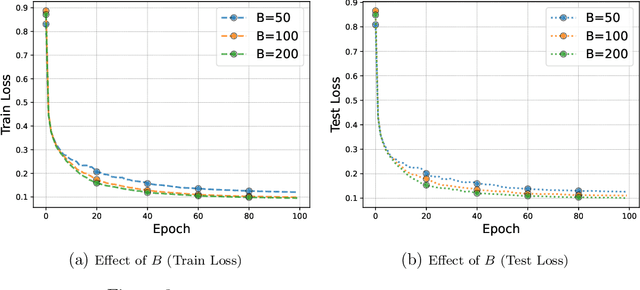
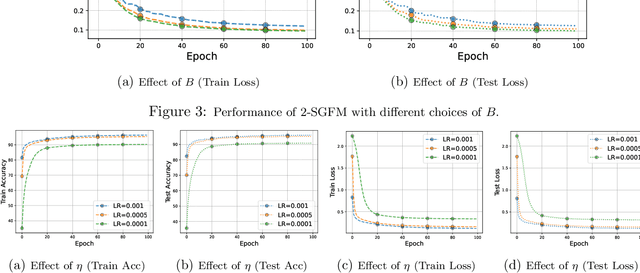
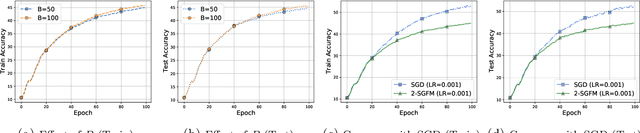
Nonsmooth nonconvex optimization problems broadly emerge in machine learning and business decision making, whereas two core challenges impede the development of efficient solution methods with finite-time convergence guarantee: the lack of computationally tractable optimality criterion and the lack of computationally powerful oracles. The contributions of this paper are two-fold. First, we establish the relationship between the celebrated Goldstein subdifferential~\citep{Goldstein-1977-Optimization} and uniform smoothing, thereby providing the basis and intuition for the design of gradient-free methods that guarantee the finite-time convergence to a set of Goldstein stationary points. Second, we propose the gradient-free method (GFM) and stochastic GFM for solving a class of nonsmooth nonconvex optimization problems and prove that both of them can return a $(\delta,\epsilon)$-Goldstein stationary point of a Lipschitz function $f$ at an expected convergence rate at $O(d^{3/2}\delta^{-1}\epsilon^{-4})$ where $d$ is the problem dimension. Two-phase versions of GFM and SGFM are also proposed and proven to achieve improved large-deviation results. Finally, we demonstrate the effectiveness of 2-SGFM on training ReLU neural networks with the \textsc{Minst} dataset.
Empirical Gateaux Derivatives for Causal Inference
Aug 31, 2022
We study a constructive algorithm that approximates Gateaux derivatives for statistical functionals by finite-differencing, with a focus on causal inference functionals. We consider the case where probability distributions are not known a priori but also need to be estimated from data. These estimated distributions lead to empirical Gateaux derivatives, and we study the relationships between empirical, numerical, and analytical Gateaux derivatives. Starting with a case study of estimating the mean potential outcome (hence average treatment effect), we instantiate the exact relationship between finite-differences and the analytical Gateaux derivative. We then derive requirements on the rates of numerical approximation in perturbation and smoothing that preserve the statistical benefits of one-step adjustments, such as rate-double-robustness. We then study more complicated functionals such as dynamic treatment regimes and the linear-programming formulation for policy optimization in infinite-horizon Markov decision processes. The newfound ability to approximate bias adjustments in the presence of arbitrary constraints illustrates the usefulness of constructive approaches for Gateaux derivatives. We also find that the statistical structure of the functional (rate-double robustness) can permit less conservative rates of finite-difference approximation. This property, however, can be specific to particular functionals, e.g. it occurs for the mean potential outcome (hence average treatment effect) but not the infinite-horizon MDP policy value.
Competition, Alignment, and Equilibria in Digital Marketplaces
Aug 30, 2022
Competition between traditional platforms is known to improve user utility by aligning the platform's actions with user preferences. But to what extent is alignment exhibited in data-driven marketplaces? To study this question from a theoretical perspective, we introduce a duopoly market where platform actions are bandit algorithms and the two platforms compete for user participation. A salient feature of this market is that the quality of recommendations depends on both the bandit algorithm and the amount of data provided by interactions from users. This interdependency between the algorithm performance and the actions of users complicates the structure of market equilibria and their quality in terms of user utility. Our main finding is that competition in this market does not perfectly align market outcomes with user utility. Interestingly, market outcomes exhibit misalignment not only when the platforms have separate data repositories, but also when the platforms have a shared data repository. Nonetheless, the data sharing assumptions impact what mechanism drives misalignment and also affect the specific form of misalignment (e.g. the quality of the best-case and worst-case market outcomes). More broadly, our work illustrates that competition in digital marketplaces has subtle consequences for user utility that merit further investigation.
Valid Inference after Causal Discovery
Aug 11, 2022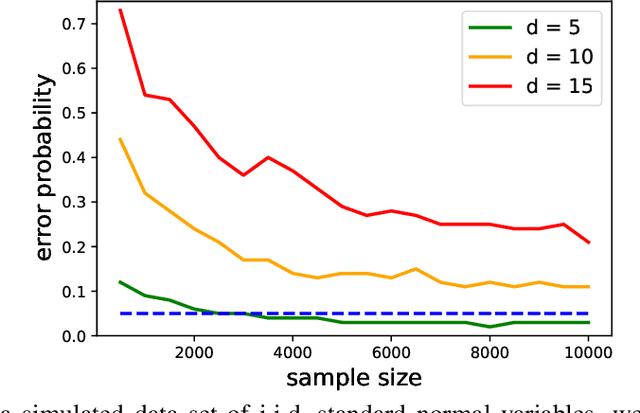

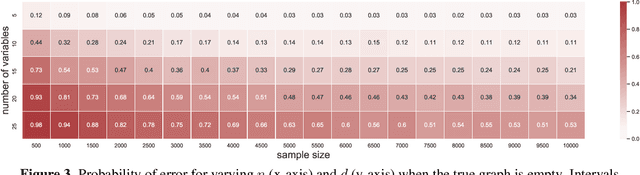
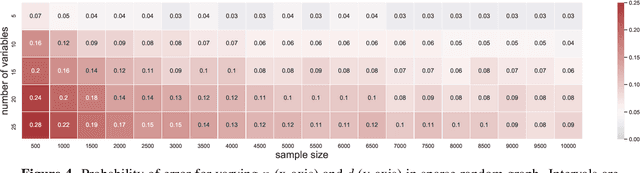
Causal graph discovery and causal effect estimation are two fundamental tasks in causal inference. While many methods have been developed for each task individually, statistical challenges arise when applying these methods jointly: estimating causal effects after running causal discovery algorithms on the same data leads to "double dipping," invalidating coverage guarantees of classical confidence intervals. To this end, we develop tools for valid post-causal-discovery inference. One key contribution is a randomized version of the greedy equivalence search (GES) algorithm, which permits a valid, finite-sample correction of classical confidence intervals. Across empirical studies, we show that a naive combination of causal discovery and subsequent inference algorithms typically leads to highly inflated miscoverage rates; at the same time, our noisy GES method provides reliable coverage control while achieving more accurate causal graph recovery than data splitting.
Learning Two-Player Mixture Markov Games: Kernel Function Approximation and Correlated Equilibrium
Aug 10, 2022We consider learning Nash equilibria in two-player zero-sum Markov Games with nonlinear function approximation, where the action-value function is approximated by a function in a Reproducing Kernel Hilbert Space (RKHS). The key challenge is how to do exploration in the high-dimensional function space. We propose a novel online learning algorithm to find a Nash equilibrium by minimizing the duality gap. At the core of our algorithms are upper and lower confidence bounds that are derived based on the principle of optimism in the face of uncertainty. We prove that our algorithm is able to attain an $O(\sqrt{T})$ regret with polynomial computational complexity, under very mild assumptions on the reward function and the underlying dynamic of the Markov Games. We also propose several extensions of our algorithm, including an algorithm with Bernstein-type bonus that can achieve a tighter regret bound, and another algorithm for model misspecification that can be applied to neural function approximation.
Breaking Feedback Loops in Recommender Systems with Causal Inference
Jul 15, 2022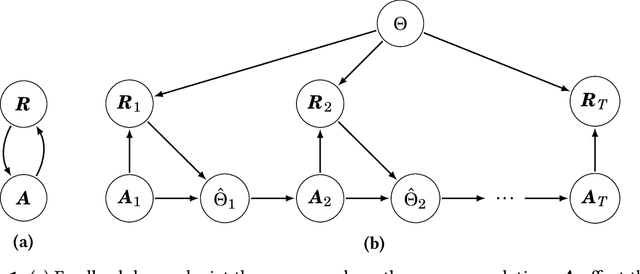
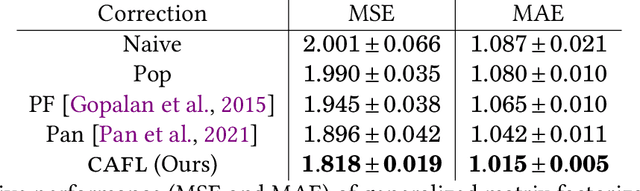
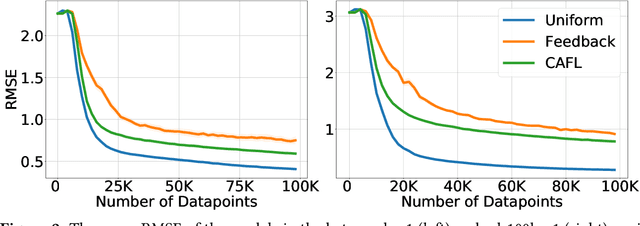
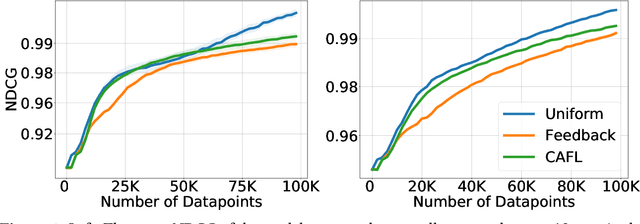
Recommender systems play a key role in shaping modern web ecosystems. These systems alternate between (1) making recommendations (2) collecting user responses to these recommendations, and (3) retraining the recommendation algorithm based on this feedback. During this process the recommender system influences the user behavioral data that is subsequently used to update it, thus creating a feedback loop. Recent work has shown that feedback loops may compromise recommendation quality and homogenize user behavior, raising ethical and performance concerns when deploying recommender systems. To address these issues, we propose the Causal Adjustment for Feedback Loops (CAFL), an algorithm that provably breaks feedback loops using causal inference and can be applied to any recommendation algorithm that optimizes a training loss. Our main observation is that a recommender system does not suffer from feedback loops if it reasons about causal quantities, namely the intervention distributions of recommendations on user ratings. Moreover, we can calculate this intervention distribution from observational data by adjusting for the recommender system's predictions of user preferences. Using simulated environments, we demonstrate that CAFL improves recommendation quality when compared to prior correction methods.
Continuous-time Analysis for Variational Inequalities: An Overview and Desiderata
Jul 14, 2022Algorithms that solve zero-sum games, multi-objective agent objectives, or, more generally, variational inequality (VI) problems are notoriously unstable on general problems. Owing to the increasing need for solving such problems in machine learning, this instability has been highlighted in recent years as a significant research challenge. In this paper, we provide an overview of recent progress in the use of continuous-time perspectives in the analysis and design of methods targeting the broad VI problem class. Our presentation draws parallels between single-objective problems and multi-objective problems, highlighting the challenges of the latter. We also formulate various desiderata for algorithms that apply to general VIs and we argue that achieving these desiderata may profit from an understanding of the associated continuous-time dynamics.
TCT: Convexifying Federated Learning using Bootstrapped Neural Tangent Kernels
Jul 13, 2022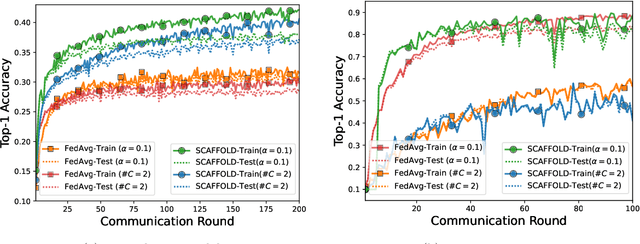
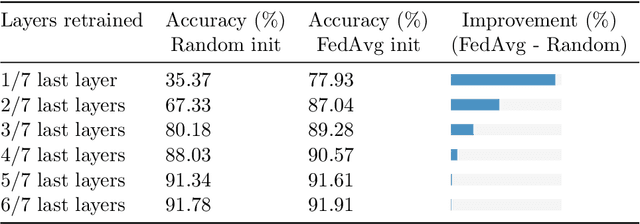

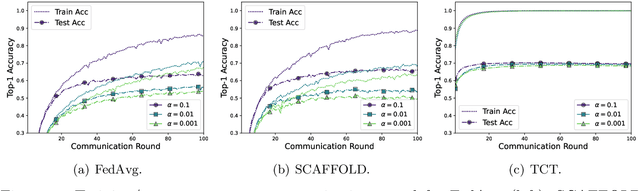
State-of-the-art federated learning methods can perform far worse than their centralized counterparts when clients have dissimilar data distributions. For neural networks, even when centralized SGD easily finds a solution that is simultaneously performant for all clients, current federated optimization methods fail to converge to a comparable solution. We show that this performance disparity can largely be attributed to optimization challenges presented by nonconvexity. Specifically, we find that the early layers of the network do learn useful features, but the final layers fail to make use of them. That is, federated optimization applied to this non-convex problem distorts the learning of the final layers. Leveraging this observation, we propose a Train-Convexify-Train (TCT) procedure to sidestep this issue: first, learn features using off-the-shelf methods (e.g., FedAvg); then, optimize a convexified problem obtained from the network's empirical neural tangent kernel approximation. Our technique yields accuracy improvements of up to +36% on FMNIST and +37% on CIFAR10 when clients have dissimilar data.
Mechanisms that Incentivize Data Sharing in Federated Learning
Jul 10, 2022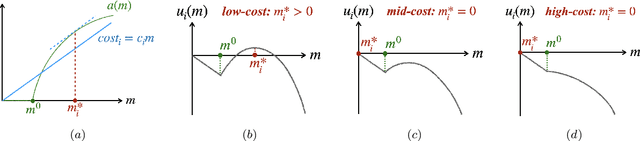
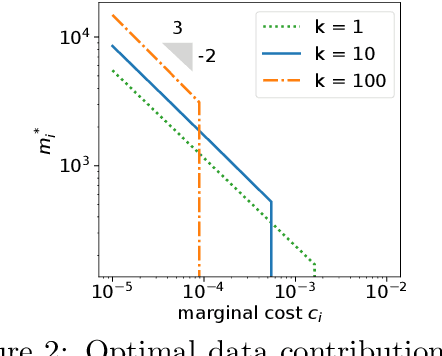
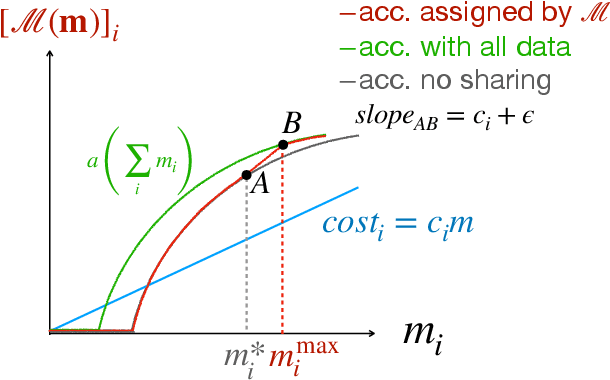
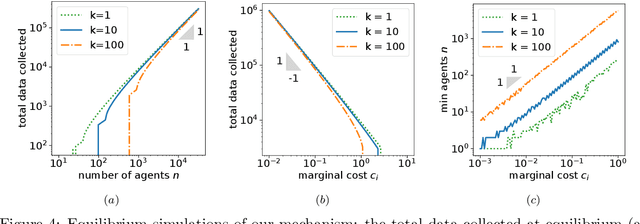
Federated learning is typically considered a beneficial technology which allows multiple agents to collaborate with each other, improve the accuracy of their models, and solve problems which are otherwise too data-intensive / expensive to be solved individually. However, under the expectation that other agents will share their data, rational agents may be tempted to engage in detrimental behavior such as free-riding where they contribute no data but still enjoy an improved model. In this work, we propose a framework to analyze the behavior of such rational data generators. We first show how a naive scheme leads to catastrophic levels of free-riding where the benefits of data sharing are completely eroded. Then, using ideas from contract theory, we introduce accuracy shaping based mechanisms to maximize the amount of data generated by each agent. These provably prevent free-riding without needing any payment mechanism.