 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Reinforcement Learning with Human Feedback from Pairwise or $K$-wise Comparisons
Jan 30, 2023

We provide a theoretical framework for Reinforcement Learning with Human Feedback (RLHF). Our analysis shows that when the true reward function is linear, the widely used maximum likelihood estimator (MLE) converges under both the Bradley-Terry-Luce (BTL) model and the Plackett-Luce (PL) model. However, we show that when training a policy based on the learned reward model, MLE fails while a pessimistic MLE provides policies with improved performance under certain coverage assumptions. Additionally, we demonstrate that under the PL model, the true MLE and an alternative MLE that splits the $K$-wise comparison into pairwise comparisons both converge. Moreover, the true MLE is asymptotically more efficient. Our results validate the empirical success of existing RLHF algorithms in InstructGPT and provide new insights for algorithm design. Furthermore, our results unify the problem of RLHF and max-entropy Inverse Reinforcement Learning (IRL), and provide the first sample complexity bound for max-entropy IRL.
Online Learning in Stackelberg Games with an Omniscient Follower
Jan 27, 2023We study the problem of online learning in a two-player decentralized cooperative Stackelberg game. In each round, the leader first takes an action, followed by the follower who takes their action after observing the leader's move. The goal of the leader is to learn to minimize the cumulative regret based on the history of interactions. Differing from the traditional formulation of repeated Stackelberg games, we assume the follower is omniscient, with full knowledge of the true reward, and that they always best-respond to the leader's actions. We analyze the sample complexity of regret minimization in this repeated Stackelberg game. We show that depending on the reward structure, the existence of the omniscient follower may change the sample complexity drastically, from constant to exponential, even for linear cooperative Stackelberg games. This poses unique challenges for the learning process of the leader and the subsequent regret analysis.
Incentive-Aware Recommender Systems in Two-Sided Markets
Nov 23, 2022Online platforms in the Internet Economy commonly incorporate recommender systems that recommend arms (e.g., products) to agents (e.g., users). In such platforms, a myopic agent has a natural incentive to exploit, by choosing the best product given the current information rather than to explore various alternatives to collect information that will be used for other agents. We propose a novel recommender system that respects agents' incentives and enjoys asymptotically optimal performances expressed by the regret in repeated games. We model such an incentive-aware recommender system as a multi-agent bandit problem in a two-sided market which is equipped with an incentive constraint induced by agents' opportunity costs. If the opportunity costs are known to the principal, we show that there exists an incentive-compatible recommendation policy, which pools recommendations across a genuinely good arm and an unknown arm via a randomized and adaptive approach. On the other hand, if the opportunity costs are unknown to the principal, we propose a policy that randomly pools recommendations across all arms and uses each arm's cumulative loss as feedback for exploration. We show that both policies also satisfy an ex-post fairness criterion, which protects agents from over-exploitation.
The Sample Complexity of Online Contract Design
Nov 10, 2022We study the hidden-action principal-agent problem in an online setting. In each round, the principal posts a contract that specifies the payment to the agent based on each outcome. The agent then makes a strategic choice of action that maximizes her own utility, but the action is not directly observable by the principal. The principal observes the outcome and receives utility from the agent's choice of action. Based on past observations, the principal dynamically adjusts the contracts with the goal of maximizing her utility. We introduce an online learning algorithm and provide an upper bound on its Stackelberg regret. We show that when the contract space is $[0,1]^m$, the Stackelberg regret is upper bounded by $\widetilde O(\sqrt{m} \cdot T^{1-C/m})$, and lower bounded by $\Omega(T^{1-1/(m+2)})$. This result shows that exponential-in-$m$ samples are both sufficient and necessary to learn a near-optimal contract, resolving an open problem on the hardness of online contract design. When contracts are restricted to some subset $\mathcal{F} \subset [0,1]^m$, we define an intrinsic dimension of $\mathcal{F}$ that depends on the covering number of the spherical code in the space and bound the regret in terms of this intrinsic dimension. When $\mathcal{F}$ is the family of linear contracts, the Stackelberg regret grows exactly as $\Theta(T^{2/3})$. The contract design problem is challenging because the utility function is discontinuous. Bounding the discretization error in this setting has been an open problem. In this paper, we identify a limited set of directions in which the utility function is continuous, allowing us to design a new discretization method and bound its error. This approach enables the first upper bound with no restrictions on the contract and action space.
Nesterov Meets Optimism: Rate-Optimal Optimistic-Gradient-Based Method for Stochastic Bilinearly-Coupled Minimax Optimization
Oct 31, 2022



We provide a novel first-order optimization algorithm for bilinearly-coupled strongly-convex-concave minimax optimization called the AcceleratedGradient OptimisticGradient (AG-OG). The main idea of our algorithm is to leverage the structure of the considered minimax problem and operates Nesterov's acceleration on the individual part and optimistic gradient on the coupling part of the objective. We motivate our method by showing that its continuous-time dynamics corresponds to an organic combination of the dynamics of optimistic gradient and of Nesterov's acceleration. By discretizing the dynamics we conclude polynomial convergence behavior in discrete time. Further enhancement of AG-OG with proper restarting allows us to achieve rate-optimal (up to a constant) convergence rates with respect to the conditioning of the coupling and individual parts, which results in the first single-call algorithm achieving improved convergence in the deterministic setting and rate-optimality in the stochastic setting under bilinearly coupled minimax problem sets.
Revisiting the ACVI Method for Constrained Variational Inequalities
Oct 27, 2022



ACVI is a recently proposed first-order method for solving variational inequalities (VIs) with general constraints. Yang et al. (2022) showed that the gap function of the last iterate decreases at a rate of $\mathcal{O}(\frac{1}{\sqrt{K}})$ when the operator is $L$-Lipschitz, monotone, and at least one constraint is active. In this work, we show that the same guarantee holds when only assuming that the operator is monotone. To our knowledge, this is the first analytically derived last-iterate convergence rate for general monotone VIs, and overall the only one that does not rely on the assumption that the operator is $L$-Lipschitz. Furthermore, when the sub-problems of ACVI are solved approximately, we show that by using a standard warm-start technique the convergence rate stays the same, provided that the errors decrease at appropriate rates. We further provide empirical analyses and insights on its implementation for the latter case.
Explicit Second-Order Min-Max Optimization Methods with Optimal Convergence Guarantee
Oct 23, 2022We propose and analyze exact and inexact regularized Newton-type methods for finding a global saddle point of a \textit{convex-concave} unconstrained min-max optimization problem. Compared to their first-order counterparts, investigations of second-order methods for min-max optimization are relatively limited, as obtaining global rates of convergence with second-order information is much more involved. In this paper, we highlight how second-order information can be used to speed up the dynamics of dual extrapolation methods {despite inexactness}. Specifically, we show that the proposed algorithms generate iterates that remain within a bounded set and the averaged iterates converge to an $\epsilon$-saddle point within $O(\epsilon^{-2/3})$ iterations in terms of a gap function. Our algorithms match the theoretically established lower bound in this context and our analysis provides a simple and intuitive convergence analysis for second-order methods without requiring any compactness assumptions. Finally, we present a series of numerical experiments on synthetic and real data that demonstrate the efficiency of the proposed algorithms.
On-Demand Sampling: Learning Optimally from Multiple Distributions
Oct 22, 2022Social and real-world considerations such as robustness, fairness, social welfare and multi-agent tradeoffs have given rise to multi-distribution learning paradigms, such as collaborative, group distributionally robust, and fair federated learning. In each of these settings, a learner seeks to minimize its worst-case loss over a set of $n$ predefined distributions, while using as few samples as possible. In this paper, we establish the optimal sample complexity of these learning paradigms and give algorithms that meet this sample complexity. Importantly, our sample complexity bounds exceed that of the sample complexity of learning a single distribution only by an additive factor of $n \log(n) / \epsilon^2$. These improve upon the best known sample complexity of agnostic federated learning by Mohri et al. by a multiplicative factor of $n$, the sample complexity of collaborative learning by Nguyen and Zakynthinou by a multiplicative factor $\log n / \epsilon^3$, and give the first sample complexity bounds for the group DRO objective of Sagawa et al. To achieve optimal sample complexity, our algorithms learn to sample and learn from distributions on demand. Our algorithm design and analysis is enabled by our extensions of stochastic optimization techniques for solving stochastic zero-sum games. In particular, we contribute variants of Stochastic Mirror Descent that can trade off between players' access to cheap one-off samples or more expensive reusable ones.
A Reinforcement Learning Approach in Multi-Phase Second-Price Auction Design
Oct 19, 2022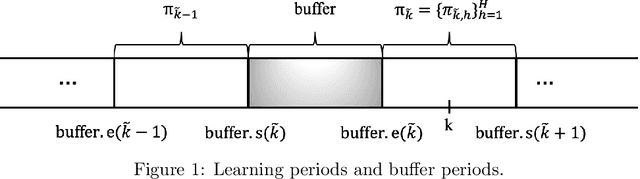
We study reserve price optimization in multi-phase second price auctions, where seller's prior actions affect the bidders' later valuations through a Markov Decision Process (MDP). Compared to the bandit setting in existing works, the setting in ours involves three challenges. First, from the seller's perspective, we need to efficiently explore the environment in the presence of potentially nontruthful bidders who aim to manipulates seller's policy. Second, we want to minimize the seller's revenue regret when the market noise distribution is unknown. Third, the seller's per-step revenue is unknown, nonlinear, and cannot even be directly observed from the environment. We propose a mechanism addressing all three challenges. To address the first challenge, we use a combination of a new technique named "buffer periods" and inspirations from Reinforcement Learning (RL) with low switching cost to limit bidders' surplus from untruthful bidding, thereby incentivizing approximately truthful bidding. The second one is tackled by a novel algorithm that removes the need for pure exploration when the market noise distribution is unknown. The third challenge is resolved by an extension of LSVI-UCB, where we use the auction's underlying structure to control the uncertainty of the revenue function. The three techniques culminate in the $\underline{\rm C}$ontextual-$\underline{\rm L}$SVI-$\underline{\rm U}$CB-$\underline{\rm B}$uffer (CLUB) algorithm which achieves $\tilde{ \mathcal{O}}(H^{5/2}\sqrt{K})$ revenue regret when the market noise is known and $\tilde{ \mathcal{O}}(H^{3}\sqrt{K})$ revenue regret when the noise is unknown with no assumptions on bidders' truthfulness.
QuTE: decentralized multiple testing on sensor networks with false discovery rate control
Oct 09, 2022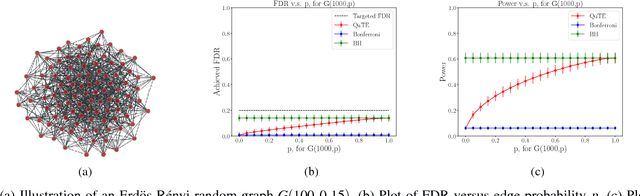
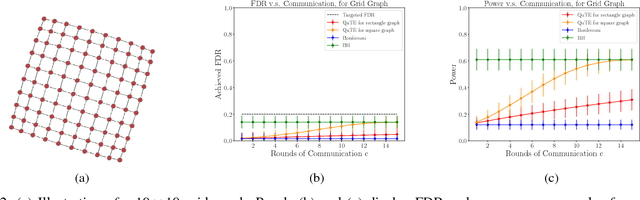
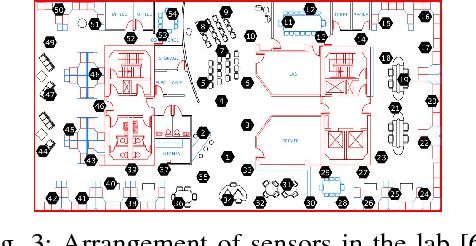
This paper designs methods for decentralized multiple hypothesis testing on graphs that are equipped with provable guarantees on the false discovery rate (FDR). We consider the setting where distinct agents reside on the nodes of an undirected graph, and each agent possesses p-values corresponding to one or more hypotheses local to its node. Each agent must individually decide whether to reject one or more of its local hypotheses by only communicating with its neighbors, with the joint aim that the global FDR over the entire graph must be controlled at a predefined level. We propose a simple decentralized family of Query-Test-Exchange (QuTE) algorithms and prove that they can control FDR under independence or positive dependence of the p-values. Our algorithm reduces to the Benjamini-Hochberg (BH) algorithm when after graph-diameter rounds of communication, and to the Bonferroni procedure when no communication has occurred or the graph is empty. To avoid communicating real-valued p-values, we develop a quantized BH procedure, and extend it to a quantized QuTE procedure. QuTE works seamlessly in streaming data settings, where anytime-valid p-values may be continually updated at each node. Last, QuTE is robust to arbitrary dropping of packets, or a graph that changes at every step, making it particularly suitable to mobile sensor networks involving drones or other multi-agent systems. We study the power of our procedure using a simulation suite of different levels of connectivity and communication on a variety of graph structures, and also provide an illustrative real-world example.