 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Reinforcement Learning with Linear Function Approximation
Aug 08, 2019Modern Reinforcement Learning (RL) is commonly applied to practical problems with an enormous number of states, where function approximation must be deployed to approximate either the value function or the policy. The introduction of function approximation raises a fundamental set of challenges involving computational and statistical efficiency, especially given the need to manage the exploration/exploitation tradeoff. As a result, a core RL question remains open: how can we design provably efficient RL algorithms that incorporate function approximation? This question persists even in a basic setting with linear dynamics and linear rewards, for which only linear function approximation is needed. This paper presents the first provable RL algorithm with both polynomial runtime and polynomial sample complexity in this linear setting, without requiring a "simulator" or additional assumptions. Concretely, we prove that an optimistic modification of Least-Squares Value Iteration (LSVI)---a classical algorithm frequently studied in the linear setting---achieves $\tilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret, where $d$ is the ambient dimension of feature space, $H$ is the length of each episode, and $T$ is the total number of steps. Importantly, such regret is independent of the number of states and actions.
Learning Stages: Phenomenon, Root Cause, Mechanism Hypothesis, and Implications
Aug 05, 2019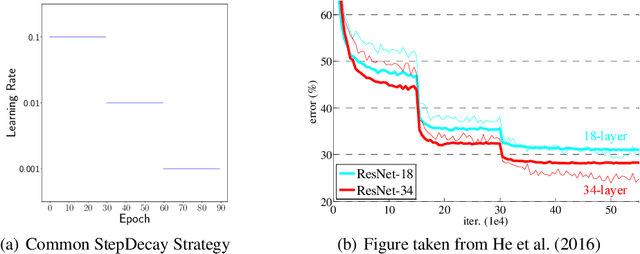
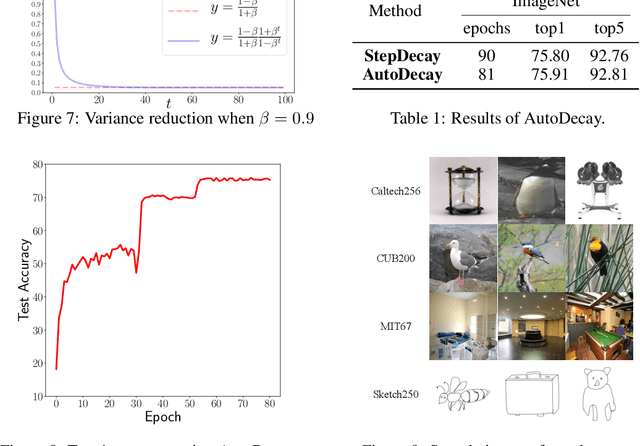

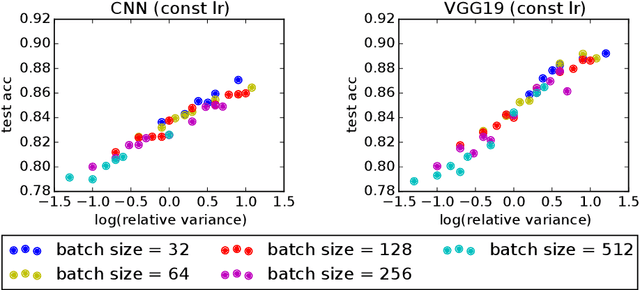
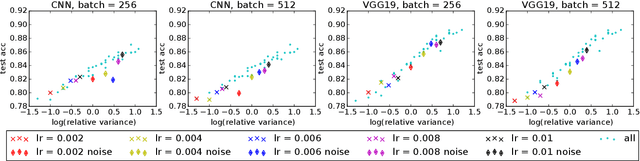
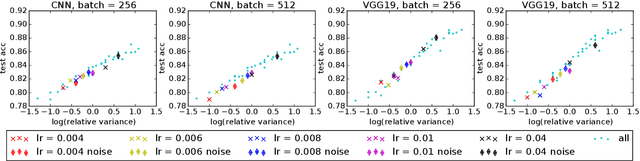
Under StepDecay learning rate strategy (decaying the learning rate after pre-defined epochs), it is a common phenomenon that the trajectories of learning statistics (training loss, test loss, test accuracy, etc.) are divided into several stages by sharp transitions. This paper studies the phenomenon in detail. Carefully designed experiments suggest the root cause to be the stochasticity of SGD. The convincing fact is the phenomenon disappears when Batch Gradient Descend is adopted. We then propose a hypothesis about the mechanism behind the phenomenon: the noise from SGD can be magnified to several levels by different learning rates, and only certain patterns are learnable within a certain level of noise. Patterns that can be learned under large noise are called easy patterns and patterns only learnable under small noise are called complex patterns. We derive several implications inspired by the hypothesis: (1) Since some patterns are not learnable until the next stage, we can design an algorithm to automatically detect the end of the current stage and switch to the next stage to expedite the training. The algorithm we design (called AutoDecay) shortens the time for training ResNet50 on ImageNet by $ 10 $\% without hurting the performance. (2) Since patterns are learned with increasing complexity, it is possible they have decreasing transferability. We study the transferability of models learned in different stages. Although later stage models have superior performance on ImageNet, we do find that they are less transferable. The verification of these two implications supports the hypothesis about the mechanism.
A Higher-Order Swiss Army Infinitesimal Jackknife
Jul 28, 2019
Cross validation (CV) and the bootstrap are ubiquitous model-agnostic tools for assessing the error or variability of machine learning and statistical estimators. However, these methods require repeatedly re-fitting the model with different weighted versions of the original dataset, which can be prohibitively time-consuming. For sufficiently regular optimization problems the optimum depends smoothly on the data weights, and so the process of repeatedly re-fitting can be approximated with a Taylor series that can be often evaluated relatively quickly. The first-order approximation is known as the "infinitesimal jackknife" in the statistics literature and has been the subject of recent interest in machine learning for approximate CV. In this work, we consider high-order approximations, which we call the "higher-order infinitesimal jackknife" (HOIJ). Under mild regularity conditions, we provide a simple recursive procedure to compute approximations of all orders with finite-sample accuracy bounds. Additionally, we show that the HOIJ can be efficiently computed even in high dimensions using forward-mode automatic differentiation. We show that a linear approximation with bootstrap weights approximation is equivalent to those provided by asymptotic normal approximations. Consequently, the HOIJ opens up the possibility of enjoying higher-order accuracy properties of the bootstrap using local approximations. Consistency of the HOIJ for leave-one-out CV under different asymptotic regimes follows as corollaries from our finite-sample bounds under additional regularity assumptions. The generality of the computation and bounds motivate the name "higher-order Swiss Army infinitesimal jackknife."
Bayesian Robustness: A Nonasymptotic Viewpoint
Jul 27, 2019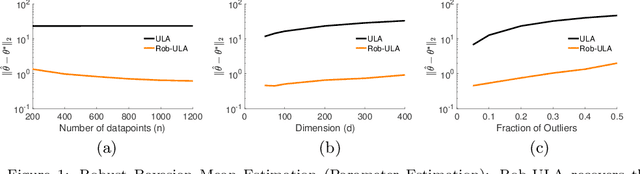
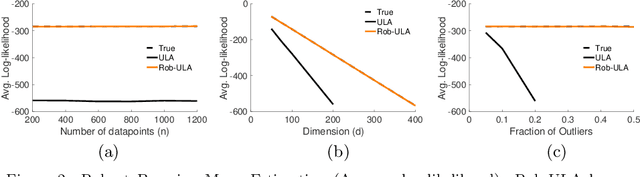
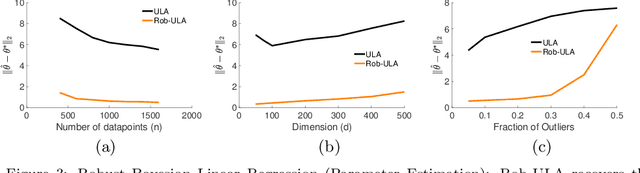
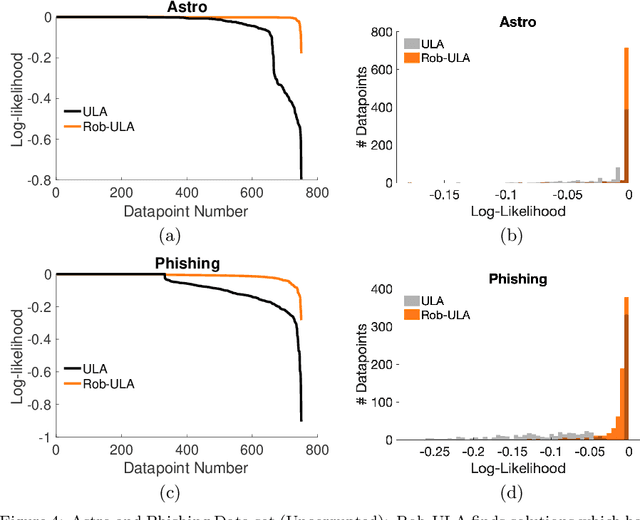
We study the problem of robustly estimating the posterior distribution for the setting where observed data can be contaminated with potentially adversarial outliers. We propose Rob-ULA, a robust variant of the Unadjusted Langevin Algorithm (ULA), and provide a finite-sample analysis of its sampling distribution. In particular, we show that after $T= \tilde{\mathcal{O}}(d/\varepsilon_{\textsf{acc}})$ iterations, we can sample from $p_T$ such that $\text{dist}(p_T, p^*) \leq \varepsilon_{\textsf{acc}} + \tilde{\mathcal{O}}(\epsilon)$, where $\epsilon$ is the fraction of corruptions. We corroborate our theoretical analysis with experiments on both synthetic and real-world data sets for mean estimation, regression and binary classification.
Quantitative $W_1$ Convergence of Langevin-Like Stochastic Processes with Non-Convex Potential State-Dependent Noise
Jul 13, 2019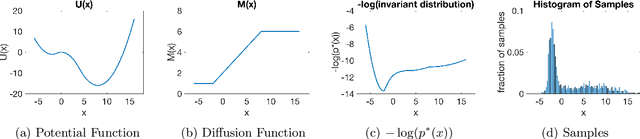
We prove quantitative convergence rates at which discrete Langevin-like processes converge to the invariant distribution of a related stochastic differential equation. We study the setup where the additive noise can be non-Gaussian and state-dependent and the potential function can be non-convex. We show that the key properties of these processes depend on the potential function and the second moment of the additive noise. We apply our theoretical findings to studying the convergence of Stochastic Gradient Descent (SGD) for non-convex problems and corroborate them with experiments using SGD to train deep neural networks on the CIFAR-10 dataset.
Convergence Rates for Gaussian Mixtures of Experts
Jul 09, 2019We provide a theoretical treatment of over-specified Gaussian mixtures of experts with covariate-free gating networks. We establish the convergence rates of the maximum likelihood estimation (MLE) for these models. Our proof technique is based on a novel notion of \emph{algebraic independence} of the expert functions. Drawing on optimal transport theory, we establish a connection between the algebraic independence and a certain class of partial differential equations (PDEs). Exploiting this connection allows us to derive convergence rates and minimax lower bounds for parameter estimation.
Policy-Gradient Algorithms Have No Guarantees of Convergence in Continuous Action and State Multi-Agent Settings
Jul 08, 2019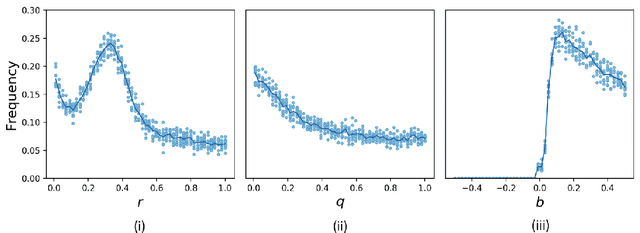
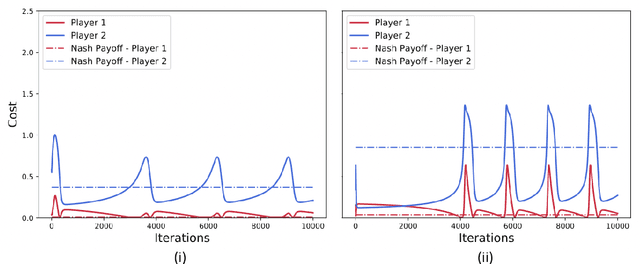
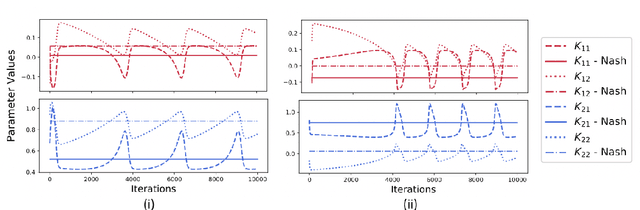
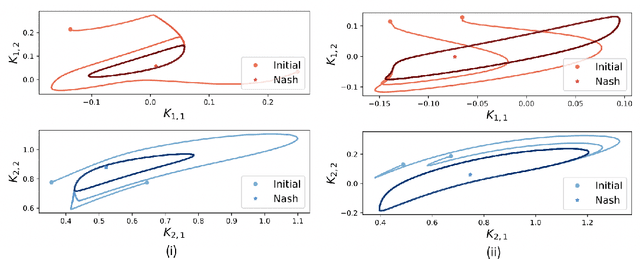
We show by counterexample that policy-gradient algorithms have no guarantees of even local convergence to Nash equilibria in continuous action and state space multi-agent settings. To do so, we analyze gradient-play in $N$-player general-sum linear quadratic games. In such games the state and action spaces are continuous and the unique global Nash equilibrium can be found be solving coupled Ricatti equations. Further, gradient-play in LQ games is equivalent to multi-agent policy gradient. We first prove that the only critical point of the gradient dynamics in these games is the unique global Nash equilibrium. We then give sufficient conditions under which policy gradient will avoid the Nash equilibrium, and generate a large number of general-sum linear quadratic games that satisfy these conditions. The existence of such games indicates that one of the most popular approaches to solving reinforcement learning problems in the classic reinforcement learning setting has no guarantee of convergence in multi-agent settings. Further, the ease with which we can generate these counterexamples suggests that such situations are not mere edge cases and are in fact quite common.
Approximate Sherali-Adams Relaxations for MAP Inference via Entropy Regularization
Jul 02, 2019
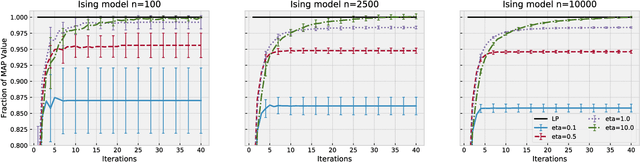
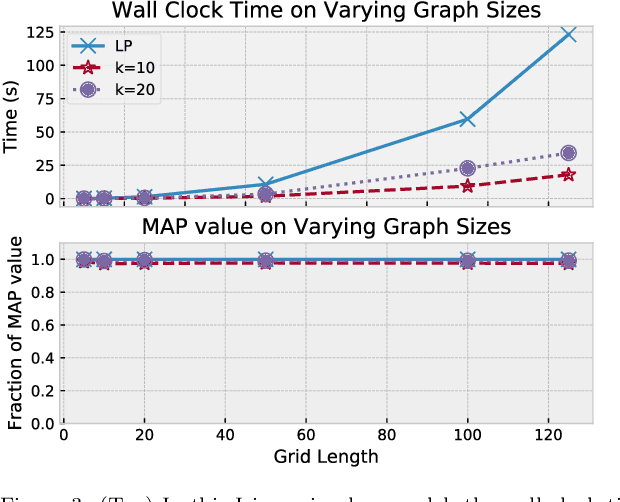

Maximum a posteriori (MAP) inference is a fundamental computational paradigm for statistical inference. In the setting of graphical models, MAP inference entails solving a combinatorial optimization problem to find the most likely configuration of the discrete-valued model. Linear programming (LP) relaxations in the Sherali-Adams hierarchy are widely used to attempt to solve this problem. We leverage recent work in entropy-regularized linear programming to propose an iterative projection algorithm (SMPLP) for large scale MAP inference that is guaranteed to converge to a near-optimal solution to the relaxation. With an appropriately chosen regularization constant, we show the resulting rounded solution solves the exact MAP problem whenever the LP is tight. We further provide theoretical guarantees on the number of iterations sufficient to achieve $\epsilon$-close solutions. Finally, we show in practice that SMPLP is competitive for solving Sherali-Adams relaxations.
Wasserstein Reinforcement Learning
Jun 19, 2019
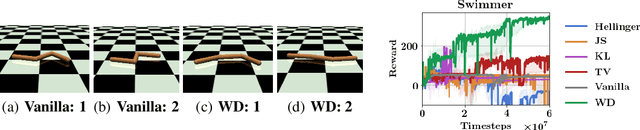
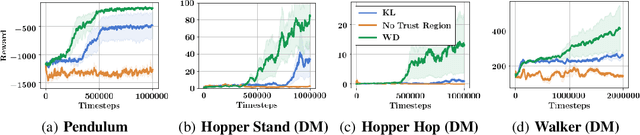
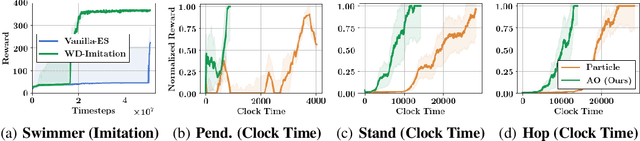
We propose behavior-driven optimization via Wasserstein distances (WDs) to improve several classes of state-of-the-art reinforcement learning (RL) algorithms. We show that WD regularizers acting on appropriate policy embeddings efficiently incorporate behavioral characteristics into policy optimization. We demonstrate that they improve Evolution Strategy methods by encouraging more efficient exploration, can be applied in imitation learning and to speed up training of Trust Region Policy Optimization methods. Since the exact computation of WDs is expensive, we develop approximate algorithms based on the combination of different methods: dual formulation of the optimal transport problem, alternating optimization and random feature maps, to effectively replace exact WD computations in the RL tasks considered. We provide theoretical analysis of our algorithms and exhaustive empirical evaluation in a variety of RL settings.
Competing Bandits in Matching Markets
Jun 12, 2019
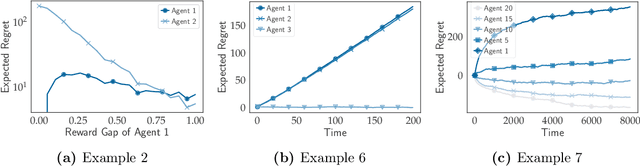
Stable matching, a classical model for two-sided markets, has long been studied with little consideration for how each side's preferences are learned. With the advent of massive online markets powered by data-driven matching platforms, it has become necessary to better understand the interplay between learning and market objectives. We propose a statistical learning model in which one side of the market does not have a priori knowledge about its preferences for the other side and is required to learn these from stochastic rewards. Our model extends the standard multi-armed bandits framework to multiple players, with the added feature that arms have preferences over players. We study both centralized and decentralized approaches to this problem and show surprising exploration-exploitation trade-offs compared to the single player multi-armed bandits setting.