 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Thompson Sampling with Langevin Algorithms
Feb 23, 2020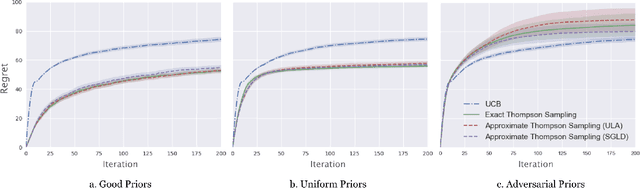
Thompson sampling is a methodology for multi-armed bandit problems that is known to enjoy favorable performance in both theory and practice. It does, however, have a significant limitation computationally, arising from the need for samples from posterior distributions at every iteration. We propose two Markov Chain Monte Carlo (MCMC) methods tailored to Thompson sampling to address this issue. We construct quickly converging Langevin algorithms to generate approximate samples that have accuracy guarantees, and we leverage novel posterior concentration rates to analyze the regret of the resulting approximate Thompson sampling algorithm. Further, we specify the necessary hyper-parameters for the MCMC procedure to guarantee optimal instance-dependent frequentist regret while having low computational complexity. In particular, our algorithms take advantage of both posterior concentration and a sample reuse mechanism to ensure that only a constant number of iterations and a constant amount of data is needed in each round. The resulting approximate Thompson sampling algorithm has logarithmic regret and its computational complexity does not scale with the time horizon of the algorithm.
Robust Optimization for Fairness with Noisy Protected Groups
Feb 21, 2020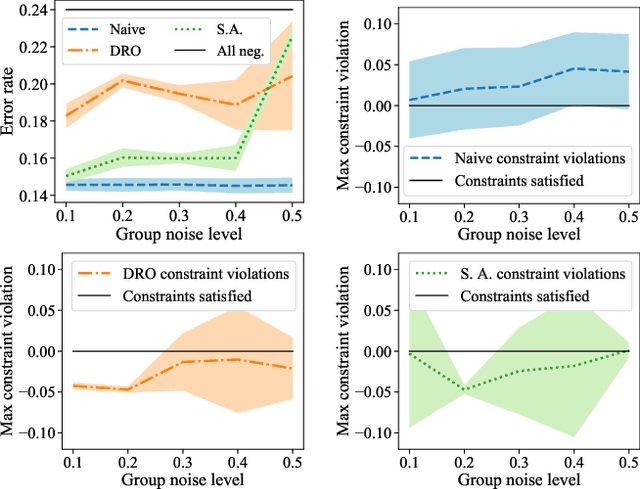
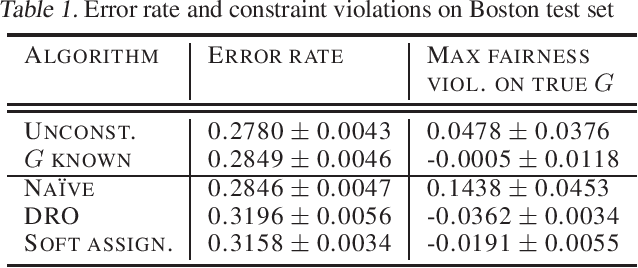

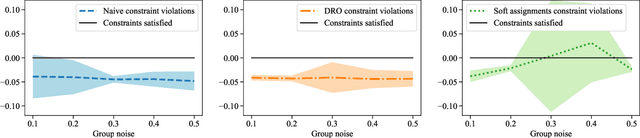
Many existing fairness criteria for machine learning involve equalizing or achieving some metric across \textit{protected groups} such as race or gender groups. However, practitioners trying to audit or enforce such group-based criteria can easily face the problem of noisy or biased protected group information. We study this important practical problem in two ways. First, we study the consequences of na{\"i}vely only relying on noisy protected groups: we provide an upper bound on the fairness violations on the true groups $G$ when the fairness criteria are satisfied on noisy groups $\hat{G}$. Second, we introduce two new approaches using robust optimization that, unlike the na{\"i}ve approach of only relying on $\hat{G}$, are guaranteed to satisfy fairness criteria on the true protected groups $G$ while minimizing a training objective. We provide theoretical guarantees that one such approach converges to an optimal feasible solution. Using two case studies, we empirically show that the robust approaches achieve better true group fairness guarantees than the na{\"i}ve approach.
Decision-Making with Auto-Encoding Variational Bayes
Feb 17, 2020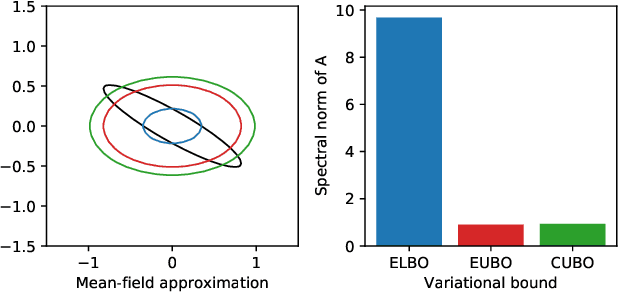

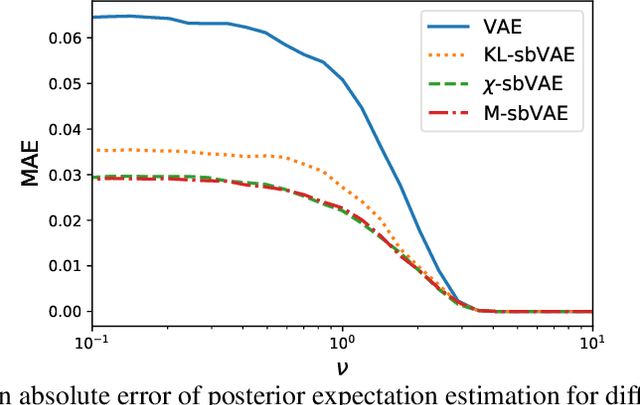

To make decisions based on a model fit by Auto-Encoding Variational Bayes (AEVB), practitioners typically use importance sampling to estimate a functional of the posterior distribution. The variational distribution found by AEVB serves as the proposal distribution for importance sampling. However, this proposal distribution may give unreliable (high variance) importance sampling estimates, thus leading to poor decisions. We explore how changing the objective function for learning the variational distribution, while continuing to learn the generative model based on the ELBO, affects the quality of downstream decisions. For a particular model, we characterize the error of importance sampling as a function of posterior variance and show that proposal distributions learned with evidence upper bounds are better. Motivated by these theoretical results, we propose a novel variant of the VAE. In addition to experimenting with MNIST, we present a full-fledged application of the proposed method to single-cell RNA sequencing. In this challenging instance of multiple hypothesis testing, the proposed method surpasses the current state of the art.
Adaptivity of Stochastic Gradient Methods for Nonconvex Optimization
Feb 13, 2020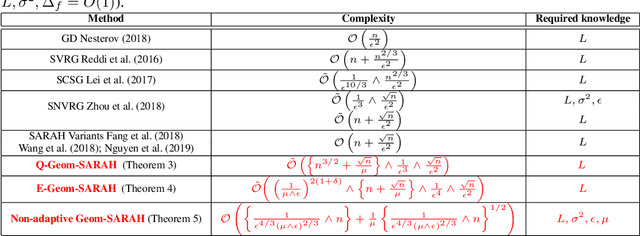
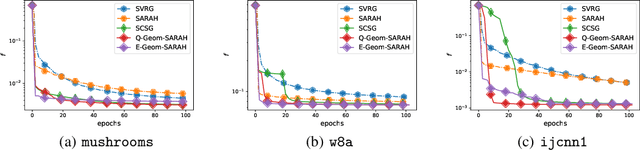
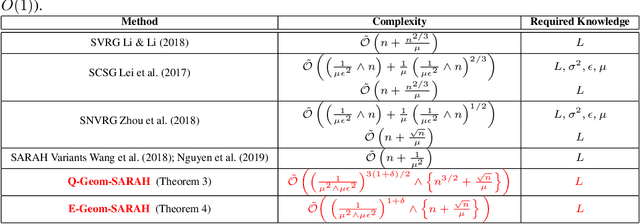
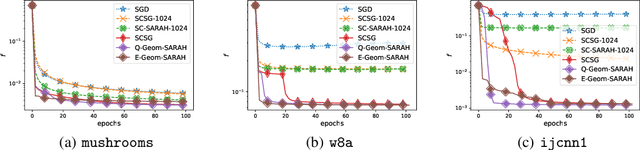
Adaptivity is an important yet under-studied property in modern optimization theory. The gap between the state-of-the-art theory and the current practice is striking in that algorithms with desirable theoretical guarantees typically involve drastically different settings of hyperparameters, such as step-size schemes and batch sizes, in different regimes. Despite the appealing theoretical results, such divisive strategies provide little, if any, insight to practitioners to select algorithms that work broadly without tweaking the hyperparameters. In this work, blending the "geometrization" technique introduced by Lei & Jordan 2016 and the \texttt{SARAH} algorithm of Nguyen et al., 2017, we propose the Geometrized \texttt{SARAH} algorithm for non-convex finite-sum and stochastic optimization. Our algorithm is proved to achieve adaptivity to both the magnitude of the target accuracy and the Polyak-\L{}ojasiewicz (PL) constant if present. In addition, it achieves the best-available convergence rate for non-PL objectives simultaneously while outperforming existing algorithms for PL objectives.
Variance Reduction with Sparse Gradients
Jan 27, 2020
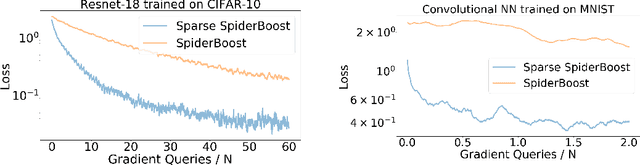
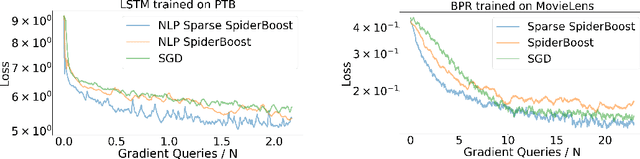
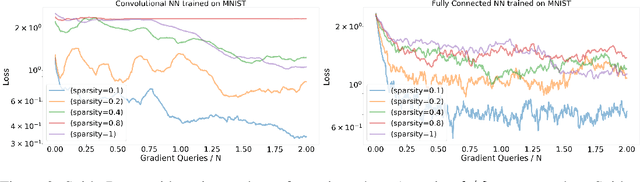
Variance reduction methods such as SVRG and SpiderBoost use a mixture of large and small batch gradients to reduce the variance of stochastic gradients. Compared to SGD, these methods require at least double the number of operations per update to model parameters. To reduce the computational cost of these methods, we introduce a new sparsity operator: The random-top-k operator. Our operator reduces computational complexity by estimating gradient sparsity exhibited in a variety of applications by combining the top-k operator and the randomized coordinate descent operator. With this operator, large batch gradients offer an extra benefit beyond variance reduction: A reliable estimate of gradient sparsity. Theoretically, our algorithm is at least as good as the best algorithm (SpiderBoost), and further excels in performance whenever the random-top-k operator captures gradient sparsity. Empirically, our algorithm consistently outperforms SpiderBoost using various models on various tasks including image classification, natural language processing, and sparse matrix factorization. We also provide empirical evidence to support the intuition behind our algorithm via a simple gradient entropy computation, which serves to quantify gradient sparsity at every iteration.
Sampling for Bayesian Mixture Models: MCMC with Polynomial-Time Mixing
Dec 11, 2019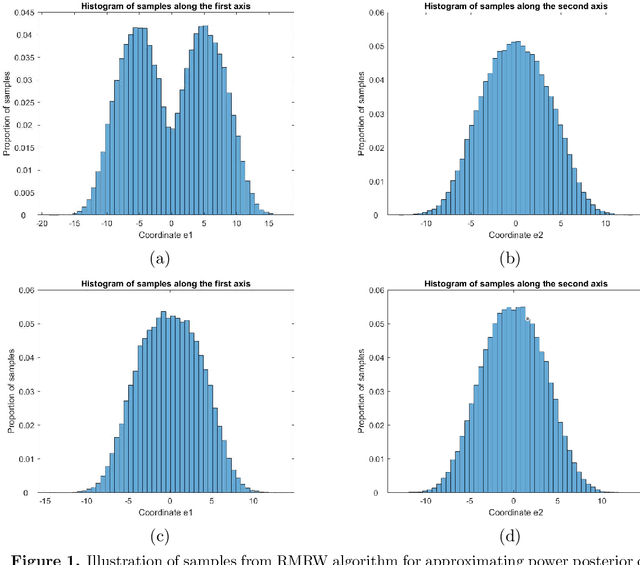
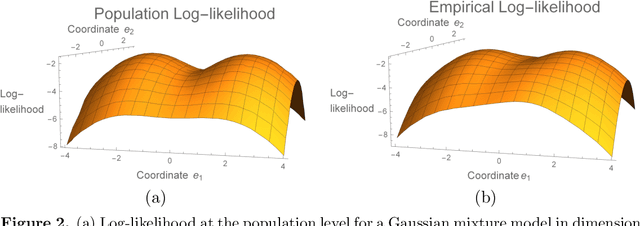
We study the problem of sampling from the power posterior distribution in Bayesian Gaussian mixture models, a robust version of the classical posterior. This power posterior is known to be non-log-concave and multi-modal, which leads to exponential mixing times for some standard MCMC algorithms. We introduce and study the Reflected Metropolis-Hastings Random Walk (RMRW) algorithm for sampling. For symmetric two-component Gaussian mixtures, we prove that its mixing time is bounded as $d^{1.5}(d + \Vert \theta_{0} \Vert^2)^{4.5}$ as long as the sample size $n$ is of the order $d (d + \Vert \theta_{0} \Vert^2)$. Notably, this result requires no conditions on the separation of the two means. En route to proving this bound, we establish some new results of possible independent interest that allow for combining Poincar\'{e} inequalities for conditional and marginal densities.
The Power of Batching in Multiple Hypothesis Testing
Nov 01, 2019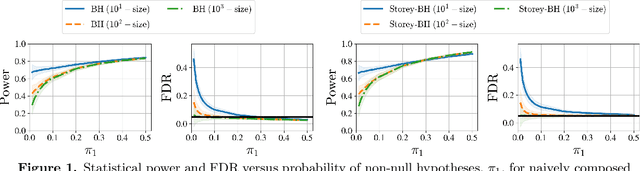
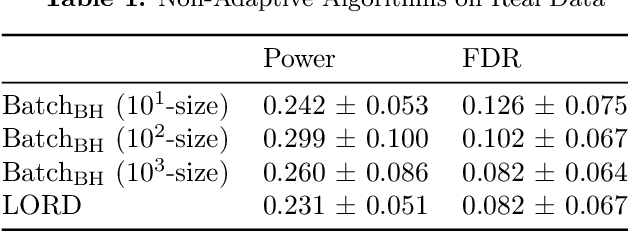
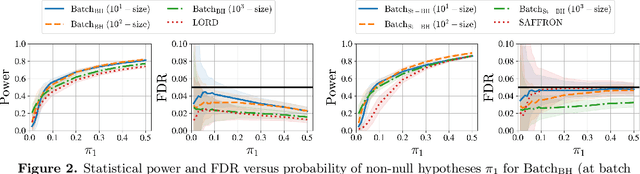
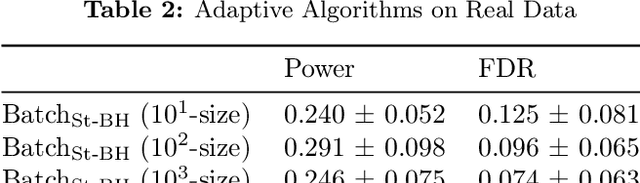
One important partition of algorithms for controlling the false discovery rate (FDR) in multiple testing is into offline and online algorithms. The first generally achieve significantly higher power of discovery, while the latter allow making decisions sequentially as well as adaptively formulating hypotheses based on past observations. Using existing methodology, it is unclear how one could trade off the benefits of these two broad families of algorithms, all the while preserving their formal FDR guarantees. To this end, we introduce $\text{Batch}_{\text{BH}}$ and $\text{Batch}_{\text{St-BH}}$, algorithms for controlling the FDR when a possibly infinite sequence of batches of hypotheses is tested by repeated application of one of the most widely used offline algorithms, the Benjamini-Hochberg (BH) method or Storey's improvement of the BH method. We show that our algorithms interpolate between existing online and offline methodology, thus trading off the best of both worlds.
On the Complexity of Approximating Multimarginal Optimal Transport
Sep 30, 2019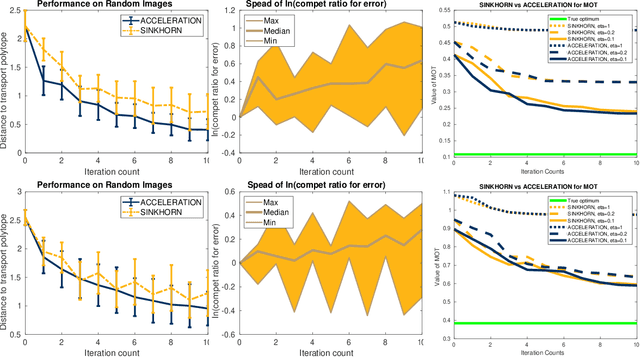

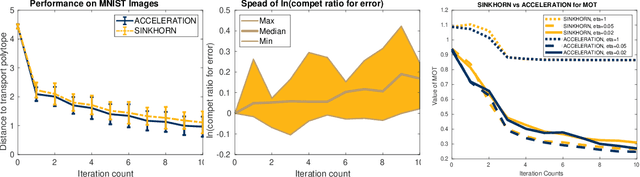

We study the complexity of approximating the multimarginal optimal transport (OT) problem, a generalization of the classical optimal transport distance, considered here between $m$ discrete probability distributions supported each on $n$ support points. First, we show that the multimarginal OT problem is not a minimum-cost flow problem when $m \geq 3$. This implies that many of the combinatorial algorithms developed for classical OT are not applicable to multimarginal OT, and therefore the standard interior-point algorithm bounds result in an intractable complexity bound of $\widetilde{\mathcal{O}}(n^{3m})$. Second, we propose and analyze two simple algorithms for approximating the multimarginal OT problem. The first algorithm, which we refer to as multimarginal Sinkhorn, improves upon previous multimarginal generalizations of the celebrated Sinkhorn algorithm. We show that it achieves a near-linear time complexity bound of $\widetilde{\mathcal{O}}(m^3 n^m / \varepsilon^2)$ for a tolerance $\varepsilon \in (0, 1)$. This matches the best known complexity bound for the Sinkhorn algorithm when $m = 2$ for approximating the classical OT distance. The second algorithm, which we refer to as multimarginal Randkhorn, accelerates the first algorithm by incorporating a randomized estimate sequence and achieves a complexity bound of $\widetilde{\mathcal{O}}(m^{8/3} n^{m+1/3}/\varepsilon)$. This improves on the complexity bound of the first algorithm by $1/\varepsilon$ and matches the best known complexity bound for the Randkhorn algorithm when $m=2$ for approximating the classical OT distance.
Towards Understanding the Transferability of Deep Representations
Sep 26, 2019
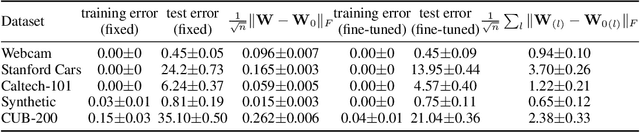
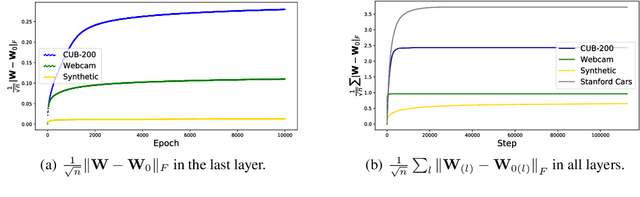
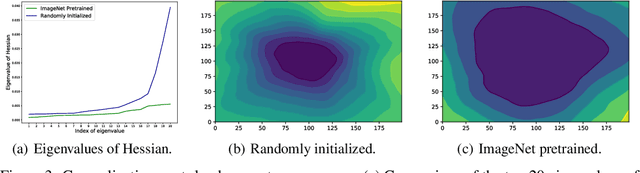
Deep neural networks trained on a wide range of datasets demonstrate impressive transferability. Deep features appear general in that they are applicable to many datasets and tasks. Such property is in prevalent use in real-world applications. A neural network pretrained on large datasets, such as ImageNet, can significantly boost generalization and accelerate training if fine-tuned to a smaller target dataset. Despite its pervasiveness, few effort has been devoted to uncovering the reason of transferability in deep feature representations. This paper tries to understand transferability from the perspectives of improved generalization, optimization and the feasibility of transferability. We demonstrate that 1) Transferred models tend to find flatter minima, since their weight matrices stay close to the original flat region of pretrained parameters when transferred to a similar target dataset; 2) Transferred representations make the loss landscape more favorable with improved Lipschitzness, which accelerates and stabilizes training substantially. The improvement largely attributes to the fact that the principal component of gradient is suppressed in the pretrained parameters, thus stabilizing the magnitude of gradient in back-propagation. 3) The feasibility of transferability is related to the similarity of both input and label. And a surprising discovery is that the feasibility is also impacted by the training stages in that the transferability first increases during training, and then declines. We further provide a theoretical analysis to verify our observations.
High-Order Langevin Diffusion Yields an Accelerated MCMC Algorithm
Aug 28, 2019We propose a Markov chain Monte Carlo (MCMC) algorithm based on third-order Langevin dynamics for sampling from distributions with log-concave and smooth densities. The higher-order dynamics allow for more flexible discretization schemes, and we develop a specific method that combines splitting with more accurate integration. For a broad class of $d$-dimensional distributions arising from generalized linear models, we prove that the resulting third-order algorithm produces samples from a distribution that is at most $\varepsilon > 0$ in Wasserstein distance from the target distribution in $O\left(\frac{d^{1/3}}{ \varepsilon^{2/3}} \right)$ steps. This result requires only Lipschitz conditions on the gradient. For general strongly convex potentials with $\alpha$-th order smoothness, we prove that the mixing time scales as $O \left(\frac{d^{1/3}}{\varepsilon^{2/3}} + \frac{d^{1/2}}{\varepsilon^{1/(\alpha - 1)}} \right)$.