 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Offline Metrics Predict Online Performance in Recommender Systems?
Nov 07, 2020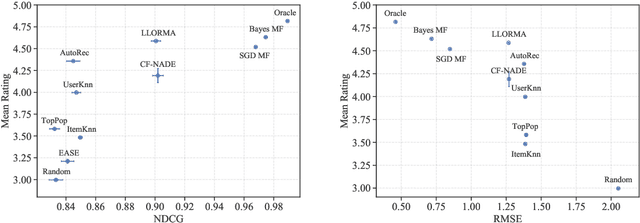
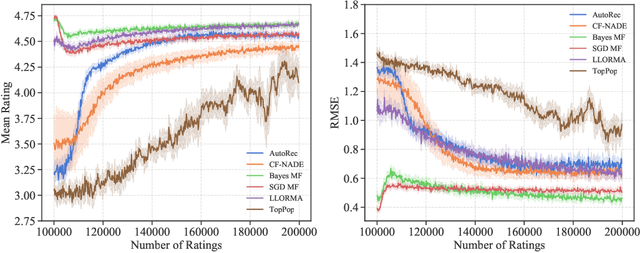
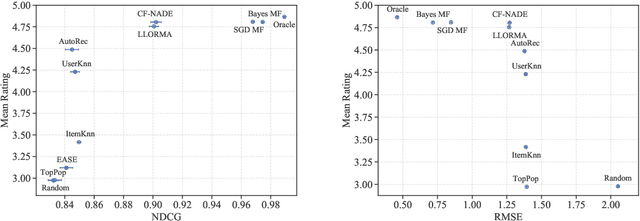
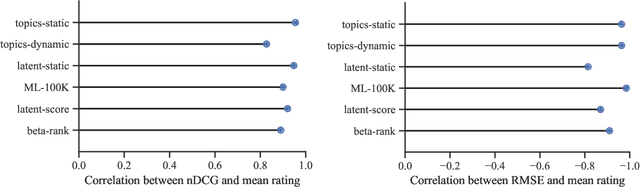
Recommender systems operate in an inherently dynamical setting. Past recommendations influence future behavior, including which data points are observed and how user preferences change. However, experimenting in production systems with real user dynamics is often infeasible, and existing simulation-based approaches have limited scale. As a result, many state-of-the-art algorithms are designed to solve supervised learning problems, and progress is judged only by offline metrics. In this work we investigate the extent to which offline metrics predict online performance by evaluating eleven recommenders across six controlled simulated environments. We observe that offline metrics are correlated with online performance over a range of environments. However, improvements in offline metrics lead to diminishing returns in online performance. Furthermore, we observe that the ranking of recommenders varies depending on the amount of initial offline data available. We study the impact of adding exploration strategies, and observe that their effectiveness, when compared to greedy recommendation, is highly dependent on the recommendation algorithm. We provide the environments and recommenders described in this paper as Reclab: an extensible ready-to-use simulation framework at https://github.com/berkeley-reclab/RecLab.
Efficient Methods for Structured Nonconvex-Nonconcave Min-Max Optimization
Oct 31, 2020
The use of min-max optimization in adversarial training of deep neural network classifiers and training of generative adversarial networks has motivated the study of nonconvex-nonconcave optimization objectives, which frequently arise in these applications. Unfortunately, recent results have established that even approximate first-order stationary points of such objectives are intractable, even under smoothness conditions, motivating the study of min-max objectives with additional structure. We introduce a new class of structured nonconvex-nonconcave min-max optimization problems, proposing a generalization of the extragradient algorithm which provably converges to a stationary point. The algorithm applies not only to Euclidean spaces, but also to general $\ell_p$-normed finite-dimensional real vector spaces. We also discuss its stability under stochastic oracles and provide bounds on its sample complexity. Our iteration complexity and sample complexity bounds either match or improve the best known bounds for the same or less general nonconvex-nonconcave settings, such as those that satisfy variational coherence or in which a weak solution to the associated variational inequality problem is assumed to exist.
Resource Allocation in Multi-armed Bandit Exploration: Overcoming Nonlinear Scaling with Adaptive Parallelism
Oct 31, 2020
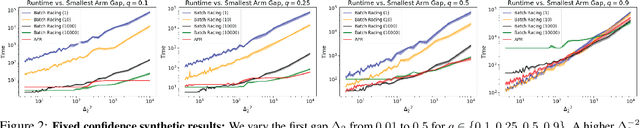
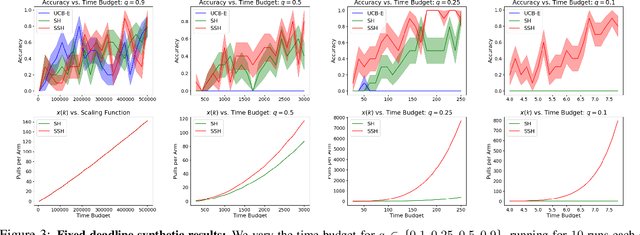
We study exploration in stochastic multi-armed bandits when we have access to a divisible resource, and can allocate varying amounts of this resource to arm pulls. By allocating more resources to a pull, we can compute the outcome faster to inform subsequent decisions about which arms to pull. However, since distributed environments do not scale linearly, executing several arm pulls in parallel, and hence less resources per pull, may result in better throughput. For example, in simulation-based scientific studies, an expensive simulation can be sped up by running it on multiple cores. This speed-up is, however, partly offset by the communication among cores and overheads, which results in lower throughput than if fewer cores were allocated to run more trials in parallel. We explore these trade-offs in the fixed confidence setting, where we need to find the best arm with a given success probability, while minimizing the time to do so. We propose an algorithm which trades off between information accumulation and throughout and show that the time taken can be upper bounded by the solution of a dynamic program whose inputs are the squared gaps between the suboptimal and optimal arms. We prove a matching hardness result which demonstrates that the above dynamic program is fundamental to this problem. Next, we propose and analyze an algorithm for the fixed deadline setting, where we are given a time deadline and need to maximize the success probability of finding the best arm. We corroborate these theoretical insights with an empirical evaluation.
Learning Strategies in Decentralized Matching Markets under Uncertain Preferences
Oct 29, 2020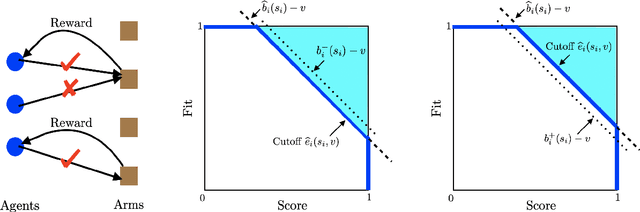

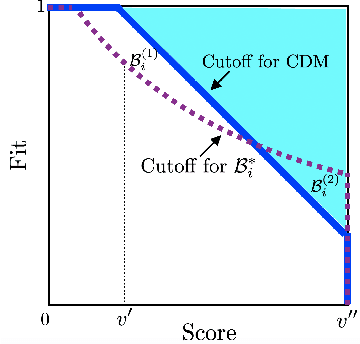
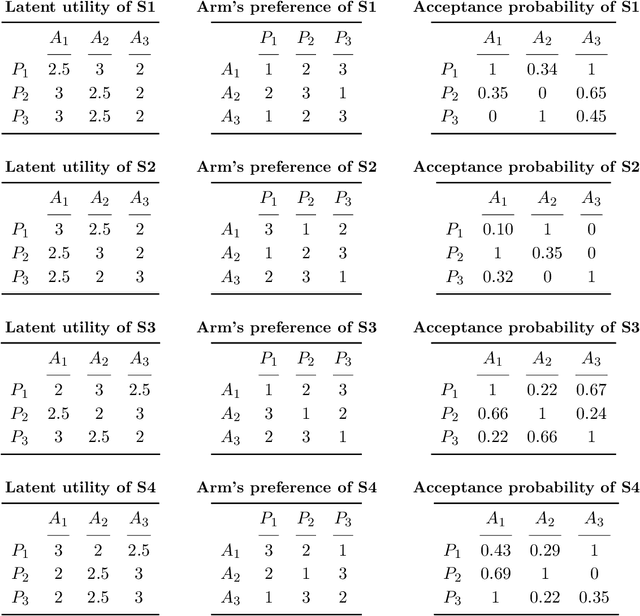
We study two-sided decentralized matching markets in which participants have uncertain preferences. We present a statistical model to learn the preferences. The model incorporates uncertain state and the participants' competition on one side of the market. We derive an optimal strategy that maximizes the agent's expected payoff and calibrate the uncertain state by taking the opportunity costs into account. We discuss the sense in which the matching derived from the proposed strategy has a stability property. We also prove a fairness property that asserts that there exists no justified envy according to the proposed strategy. We provide numerical results to demonstrate the improved payoff, stability and fairness, compared to alternative methods.
Uncertainty Sets for Image Classifiers using Conformal Prediction
Sep 29, 2020
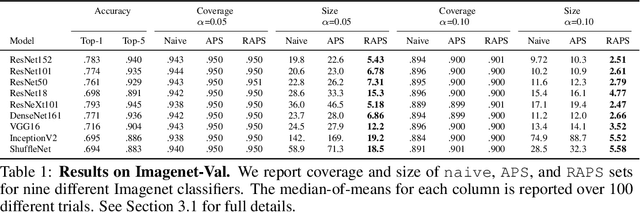
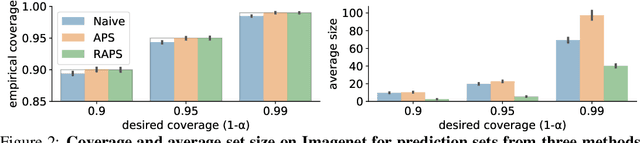
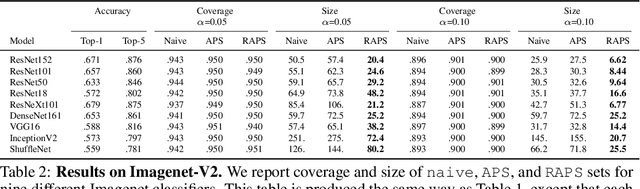
Convolutional image classifiers can achieve high predictive accuracy, but quantifying their uncertainty remains an unresolved challenge, hindering their deployment in consequential settings. Existing uncertainty quantification techniques, such as Platt scaling, attempt to calibrate the network's probability estimates, but they do not have formal guarantees. We present an algorithm that modifies any classifier to output a predictive set containing the true label with a user-specified probability, such as 90%. The algorithm is simple and fast like Platt scaling, but provides a formal finite-sample coverage guarantee for every model and dataset. Furthermore, our method generates much smaller predictive sets than alternative methods, since we introduce a regularizer to stabilize the small scores of unlikely classes after Platt scaling. In experiments on both Imagenet and Imagenet-V2 with a ResNet-152 and other classifiers, our scheme outperforms existing approaches, achieving exact coverage with sets that are often factors of 5 to 10 smaller.
Learning from eXtreme Bandit Feedback
Sep 27, 2020

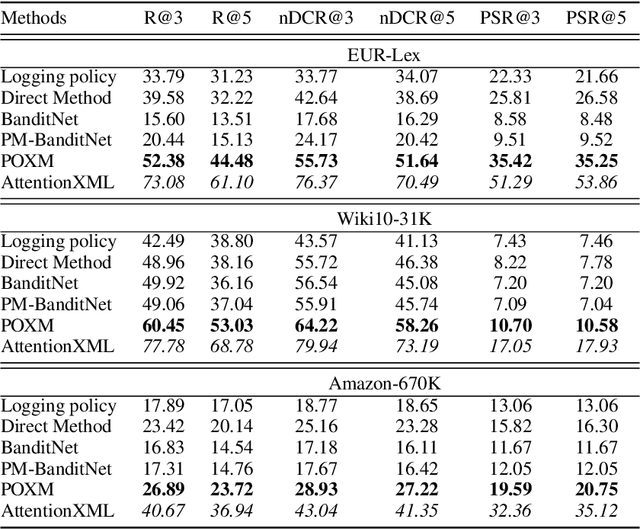
We study the problem of batch learning from bandit feedback in the setting of extremely large action spaces. Learning from extreme bandit feedback is ubiquitous in recommendation systems, in which billions of decisions are made over sets consisting of millions of choices in a single day, yielding massive observational data. In these large-scale real-world applications, supervised learning frameworks such as eXtreme Multi-label Classification (XMC) are widely used despite the fact that they incur significant biases due to the mismatch between bandit feedback and supervised labels. Such biases can be mitigated by importance sampling techniques, but these techniques suffer from impractical variance when dealing with a large number of actions. In this paper, we introduce a selective importance sampling estimator (sIS) that operates in a significantly more favorable bias-variance regime. The sIS estimator is obtained by performing importance sampling on the conditional expectation of the reward with respect to a small subset of actions for each instance (a form of Rao-Blackwellization). We employ this estimator in a novel algorithmic procedure---named Policy Optimization for eXtreme Models (POXM)---for learning from bandit feedback on XMC tasks. In POXM, the selected actions for the sIS estimator are the top-p actions of the logging policy, where p is adjusted from the data and is significantly smaller than the size of the action space. We use a supervised-to-bandit conversion on three XMC datasets to benchmark our POXM method against three competing methods: BanditNet, a previously applied partial matching pruning strategy, and a supervised learning baseline. Whereas BanditNet sometimes improves marginally over the logging policy, our experiments show that POXM systematically and significantly improves over all baselines.
Exploration in two-stage recommender systems
Sep 01, 2020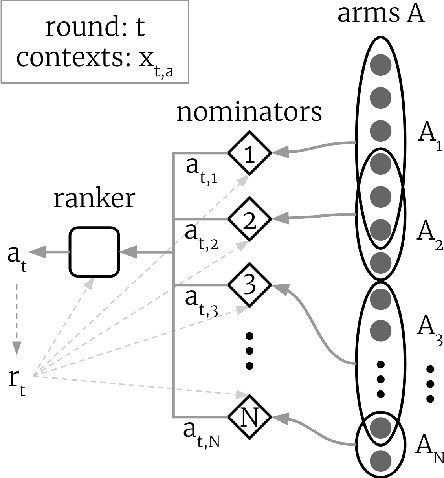
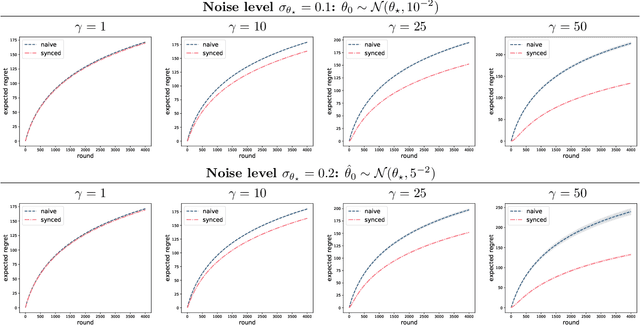
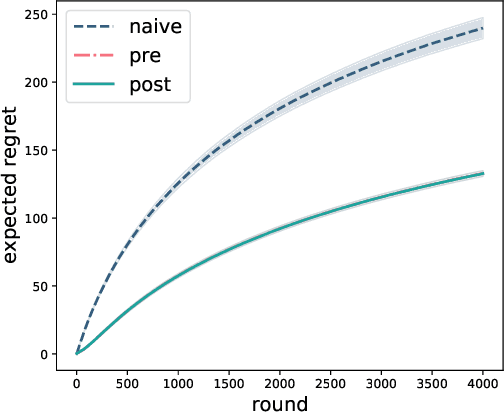
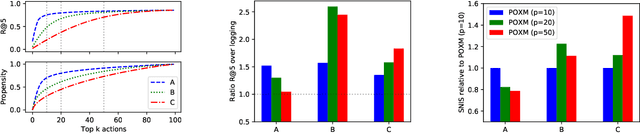
Two-stage recommender systems are widely adopted in industry due to their scalability and maintainability. These systems produce recommendations in two steps: (i) multiple nominators preselect a small number of items from a large pool using cheap-to-compute item embeddings; (ii) with a richer set of features, a ranker rearranges the nominated items and serves them to the user. A key challenge of this setup is that optimal performance of each stage in isolation does not imply optimal global performance. In response to this issue, Ma et al. (2020) proposed a nominator training objective importance weighted by the ranker's probability of recommending each item. In this work, we focus on the complementary issue of exploration. Modeled as a contextual bandit problem, we find LinUCB (a near optimal exploration strategy for single-stage systems) may lead to linear regret when deployed in two-stage recommenders. We therefore propose a method of synchronising the exploration strategies between the ranker and the nominators. Our algorithm only relies on quantities already computed by standard LinUCB at each stage and can be implemented in three lines of additional code. We end by demonstrating the effectiveness of our algorithm experimentally.
ROOT-SGD: Sharp Nonasymptotics and Asymptotic Efficiency in a Single Algorithm
Aug 28, 2020
The theory and practice of stochastic optimization has focused on stochastic gradient descent (SGD) in recent years, retaining the basic first-order stochastic nature of SGD while aiming to improve it via mechanisms such as averaging, momentum, and variance reduction. Improvement can be measured along various dimensions, however, and it has proved difficult to achieve improvements both in terms of nonasymptotic measures of convergence rate and asymptotic measures of distributional tightness. In this work, we consider first-order stochastic optimization from a general statistical point of view, motivating a specific form of recursive averaging of past stochastic gradients. The resulting algorithm, which we refer to as \emph{Recursive One-Over-T SGD} (ROOT-SGD), matches the state-of-the-art convergence rate among online variance-reduced stochastic approximation methods. Moreover, under slightly stronger distributional assumptions, the rescaled last-iterate of ROOT-SGD converges to a zero-mean Gaussian distribution that achieves near-optimal covariance.
On Localized Discrepancy for Domain Adaptation
Aug 14, 2020We propose the discrepancy-based generalization theories for unsupervised domain adaptation. Previous theories introduced distribution discrepancies defined as the supremum over complete hypothesis space. The hypothesis space may contain hypotheses that lead to unnecessary overestimation of the risk bound. This paper studies the localized discrepancies defined on the hypothesis space after localization. First, we show that these discrepancies have desirable properties. They could be significantly smaller than the pervious discrepancies. Their values will be different if we exchange the two domains, thus can reveal asymmetric transfer difficulties. Next, we derive improved generalization bounds with these discrepancies. We show that the discrepancies could influence the rate of the sample complexity. Finally, we further extend the localized discrepancies for achieving super transfer and derive generalization bounds that could be even more sample-efficient on source domain.
Transferable Calibration with Lower Bias and Variance in Domain Adaptation
Jul 16, 2020

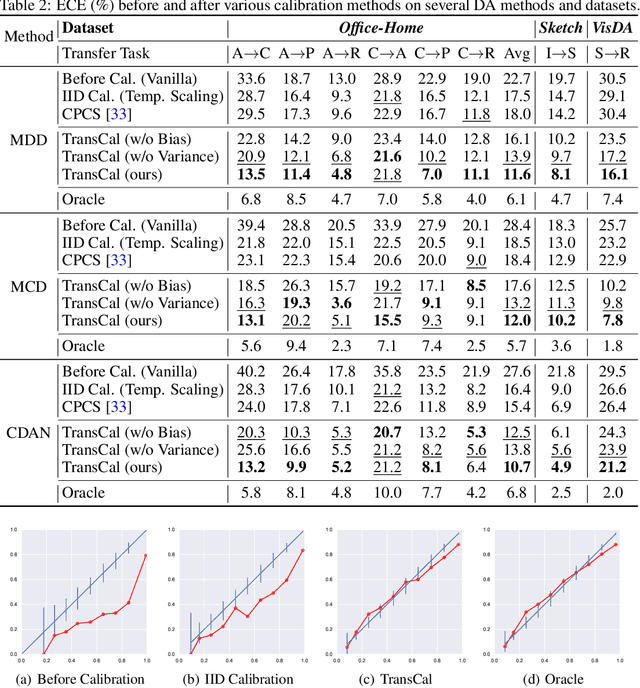
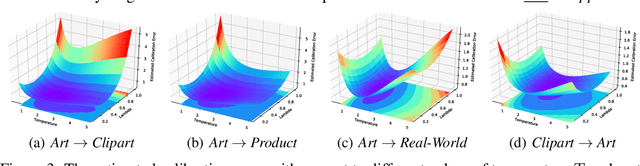
Domain Adaptation (DA) enables transferring a learning machine from a labeled source domain to an unlabeled target domain. While remarkable advances have been made, most of the existing DA methods focus on improving the target accuracy at inference. How to estimate the predictive uncertainty of DA models is vital for decision-making in safety-critical scenarios but remains the boundary to explore. In this paper, we delve into the open problem of Calibration in DA, which is extremely challenging due to the coexistence of domain shift and the lack of target labels. We first reveal the dilemma that DA models learn higher accuracy at the expense of well-calibrated probabilities. Driven by this finding, we propose Transferable Calibration (TransCal) to tackle this dilemma, achieving accurate calibration with lower bias and variance in a unified hyperparameter-free optimization framework. As a general post-hoc calibration method, TransCal can be easily applied to recalibrate existing DA methods. Its efficacy has been justified both theoretically and empirically.