 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst-Order Algorithms for Nonlinear Generalized Nash Equilibrium Problems
Apr 07, 2022
We consider the problem of computing an equilibrium in a class of nonlinear generalized Nash equilibrium problems (NGNEPs) in which the strategy sets for each player are defined by equality and inequality constraints that may depend on the choices of rival players. While the asymptotic global convergence and local convergence rate of solution procedures have been studied in this setting, the analysis of iteration complexity is still in its infancy. Our contribution is to provide two simple first-order algorithmic frameworks based on the quadratic penalty method and the augmented Lagrangian method, respectively, with an accelerated mirror-prox algorithm as the inner loop. We provide nonasymptotic theoretical guarantees for these algorithms. More specifically, we establish the global convergence rate of our algorithms for solving (strongly) monotone NGNEPs and we provide iteration complexity bounds expressed in terms of the number of gradient evaluations. Experimental results demonstrate the efficiency of our algorithms.
Geometric Methods for Sampling, Optimisation, Inference and Adaptive Agents
Mar 20, 2022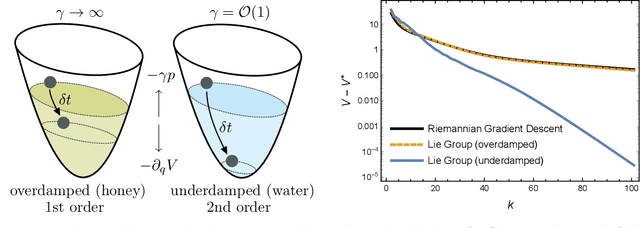
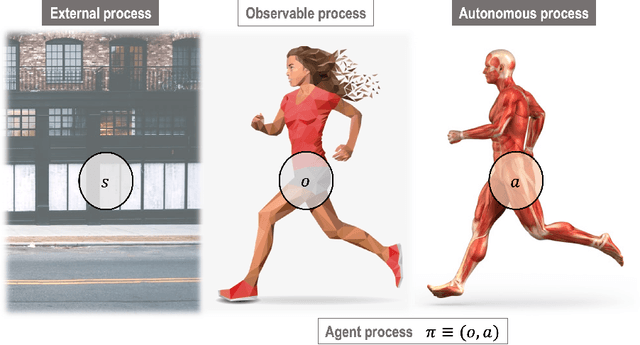
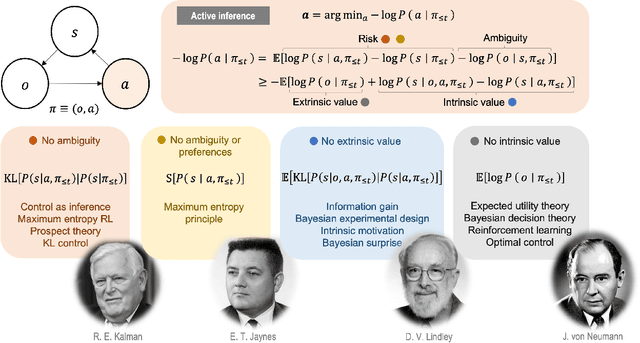
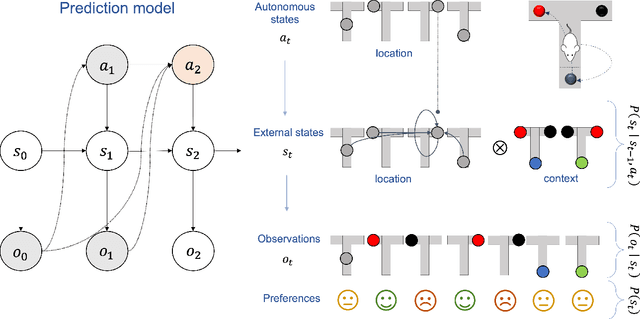
In this chapter, we identify fundamental geometric structures that underlie the problems of sampling, optimisation, inference and adaptive decision-making. Based on this identification, we derive algorithms that exploit these geometric structures to solve these problems efficiently. We show that a wide range of geometric theories emerge naturally in these fields, ranging from measure-preserving processes, information divergences, Poisson geometry, and geometric integration. Specifically, we explain how \emph{(i)} leveraging the symplectic geometry of Hamiltonian systems enable us to construct (accelerated) sampling and optimisation methods, \emph{(ii)} the theory of Hilbertian subspaces and Stein operators provides a general methodology to obtain robust estimators, \emph{(iii)} preserving the information geometry of decision-making yields adaptive agents that perform active inference. Throughout, we emphasise the rich connections between these fields; e.g., inference draws on sampling and optimisation, and adaptive decision-making assesses decisions by inferring their counterfactual consequences. Our exposition provides a conceptual overview of underlying ideas, rather than a technical discussion, which can be found in the references herein.
Learn to Match with No Regret: Reinforcement Learning in Markov Matching Markets
Mar 07, 2022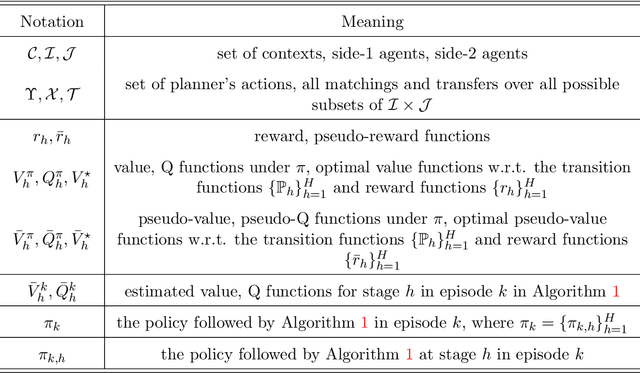
We study a Markov matching market involving a planner and a set of strategic agents on the two sides of the market. At each step, the agents are presented with a dynamical context, where the contexts determine the utilities. The planner controls the transition of the contexts to maximize the cumulative social welfare, while the agents aim to find a myopic stable matching at each step. Such a setting captures a range of applications including ridesharing platforms. We formalize the problem by proposing a reinforcement learning framework that integrates optimistic value iteration with maximum weight matching. The proposed algorithm addresses the coupled challenges of sequential exploration, matching stability, and function approximation. We prove that the algorithm achieves sublinear regret.
Improving Generalization via Uncertainty Driven Perturbations
Feb 28, 2022
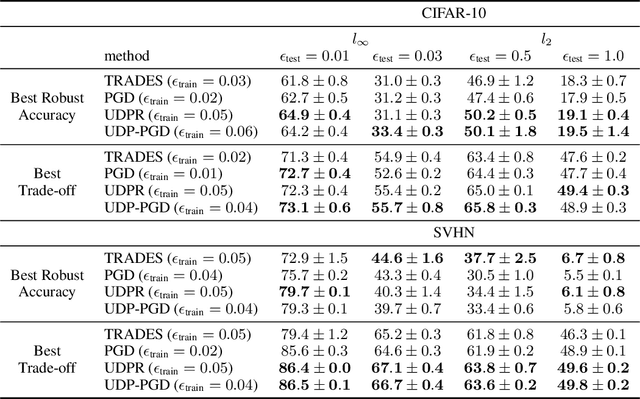
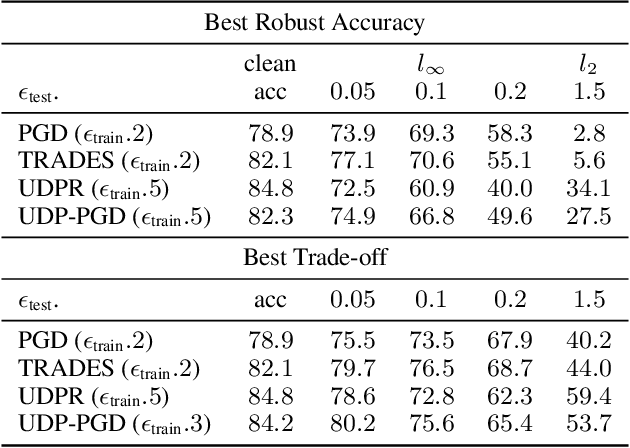
Recently Shah et al., 2020 pointed out the pitfalls of the simplicity bias - the tendency of gradient-based algorithms to learn simple models - which include the model's high sensitivity to small input perturbations, as well as sub-optimal margins. In particular, while Stochastic Gradient Descent yields max-margin boundary on linear models, such guarantee does not extend to non-linear models. To mitigate the simplicity bias, we consider uncertainty-driven perturbations (UDP) of the training data points, obtained iteratively by following the direction that maximizes the model's estimated uncertainty. The uncertainty estimate does not rely on the input's label and it is highest at the decision boundary, and - unlike loss-driven perturbations - it allows for using a larger range of values for the perturbation magnitude. Furthermore, as real-world datasets have non-isotropic distances between data points of different classes, the above property is particularly appealing for increasing the margin of the decision boundary, which in turn improves the model's generalization. We show that UDP is guaranteed to achieve the maximum margin decision boundary on linear models and that it notably increases it on challenging simulated datasets. For nonlinear models, we show empirically that UDP reduces the simplicity bias and learns more exhaustive features. Interestingly, it also achieves competitive loss-based robustness and generalization trade-off on several datasets.
Off-Policy Evaluation with Policy-Dependent Optimization Response
Feb 25, 2022
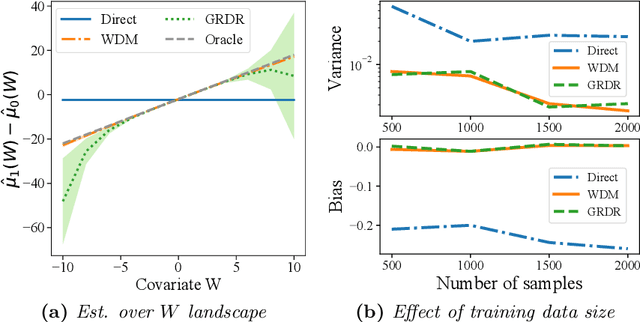
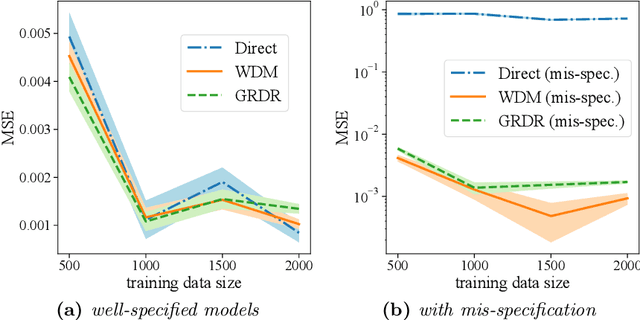
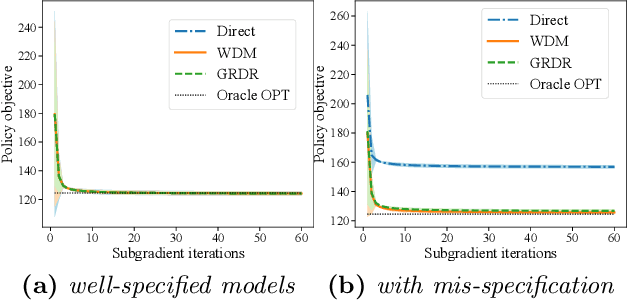
The intersection of causal inference and machine learning for decision-making is rapidly expanding, but the default decision criterion remains an \textit{average} of individual causal outcomes across a population. In practice, various operational restrictions ensure that a decision-maker's utility is not realized as an \textit{average} but rather as an \textit{output} of a downstream decision-making problem (such as matching, assignment, network flow, minimizing predictive risk). In this work, we develop a new framework for off-policy evaluation with a \textit{policy-dependent} linear optimization response: causal outcomes introduce stochasticity in objective function coefficients. In this framework, a decision-maker's utility depends on the policy-dependent optimization, which introduces a fundamental challenge of \textit{optimization} bias even for the case of policy evaluation. We construct unbiased estimators for the policy-dependent estimand by a perturbation method. We also discuss the asymptotic variance properties for a set of plug-in regression estimators adjusted to be compatible with that perturbation method. Lastly, attaining unbiased policy evaluation allows for policy optimization, and we provide a general algorithm for optimizing causal interventions. We corroborate our theoretical results with numerical simulations.
Learning Dynamic Mechanisms in Unknown Environments: A Reinforcement Learning Approach
Feb 25, 2022
Dynamic mechanism design studies how mechanism designers should allocate resources among agents in a time-varying environment. We consider the problem where the agents interact with the mechanism designer according to an unknown Markov Decision Process (MDP), where agent rewards and the mechanism designer's state evolve according to an episodic MDP with unknown reward functions and transition kernels. We focus on the online setting with linear function approximation and attempt to recover the dynamic Vickrey-Clarke-Grove (VCG) mechanism over multiple rounds of interaction. A key contribution of our work is incorporating reward-free online Reinforcement Learning (RL) to aid exploration over a rich policy space to estimate prices in the dynamic VCG mechanism. We show that the regret of our proposed method is upper bounded by $\tilde{\mathcal{O}}(T^{2/3})$ and further devise a lower bound to show that our algorithm is efficient, incurring the same $\tilde{\mathcal{O}}(T^{2 / 3})$ regret as the lower bound, where $T$ is the total number of rounds. Our work establishes the regret guarantee for online RL in solving dynamic mechanism design problems without prior knowledge of the underlying model.
Sequential Information Design: Markov Persuasion Process and Its Efficient Reinforcement Learning
Feb 22, 2022In today's economy, it becomes important for Internet platforms to consider the sequential information design problem to align its long term interest with incentives of the gig service providers. This paper proposes a novel model of sequential information design, namely the Markov persuasion processes (MPPs), where a sender, with informational advantage, seeks to persuade a stream of myopic receivers to take actions that maximizes the sender's cumulative utilities in a finite horizon Markovian environment with varying prior and utility functions. Planning in MPPs thus faces the unique challenge in finding a signaling policy that is simultaneously persuasive to the myopic receivers and inducing the optimal long-term cumulative utilities of the sender. Nevertheless, in the population level where the model is known, it turns out that we can efficiently determine the optimal (resp. $\epsilon$-optimal) policy with finite (resp. infinite) states and outcomes, through a modified formulation of the Bellman equation. Our main technical contribution is to study the MPP under the online reinforcement learning (RL) setting, where the goal is to learn the optimal signaling policy by interacting with with the underlying MPP, without the knowledge of the sender's utility functions, prior distributions, and the Markov transition kernels. We design a provably efficient no-regret learning algorithm, the Optimism-Pessimism Principle for Persuasion Process (OP4), which features a novel combination of both optimism and pessimism principles. Our algorithm enjoys sample efficiency by achieving a sublinear $\sqrt{T}$-regret upper bound. Furthermore, both our algorithm and theory can be applied to MPPs with large space of outcomes and states via function approximation, and we showcase such a success under the linear setting.
Partial Identification with Noisy Covariates: A Robust Optimization Approach
Feb 22, 2022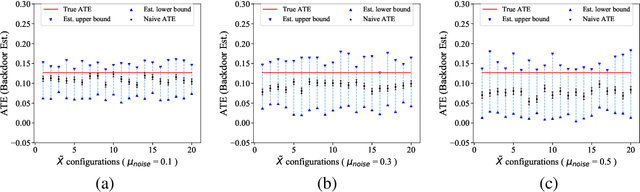
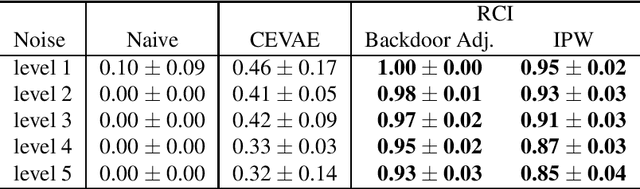

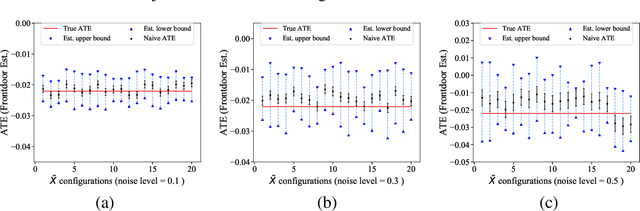
Causal inference from observational datasets often relies on measuring and adjusting for covariates. In practice, measurements of the covariates can often be noisy and/or biased, or only measurements of their proxies may be available. Directly adjusting for these imperfect measurements of the covariates can lead to biased causal estimates. Moreover, without additional assumptions, the causal effects are not point-identifiable due to the noise in these measurements. To this end, we study the partial identification of causal effects given noisy covariates, under a user-specified assumption on the noise level. The key observation is that we can formulate the identification of the average treatment effects (ATE) as a robust optimization problem. This formulation leads to an efficient robust optimization algorithm that bounds the ATE with noisy covariates. We show that this robust optimization approach can extend a wide range of causal adjustment methods to perform partial identification, including backdoor adjustment, inverse propensity score weighting, double machine learning, and front door adjustment. Across synthetic and real datasets, we find that this approach provides ATE bounds with a higher coverage probability than existing methods.
No-Regret Learning in Partially-Informed Auctions
Feb 22, 2022
Auctions with partially-revealed information about items are broadly employed in real-world applications, but the underlying mechanisms have limited theoretical support. In this work, we study a machine learning formulation of these types of mechanisms, presenting algorithms that are no-regret from the buyer's perspective. Specifically, a buyer who wishes to maximize his utility interacts repeatedly with a platform over a series of $T$ rounds. In each round, a new item is drawn from an unknown distribution and the platform publishes a price together with incomplete, "masked" information about the item. The buyer then decides whether to purchase the item. We formalize this problem as an online learning task where the goal is to have low regret with respect to a myopic oracle that has perfect knowledge of the distribution over items and the seller's masking function. When the distribution over items is known to the buyer and the mask is a SimHash function mapping $\mathbb{R}^d$ to $\{0,1\}^{\ell}$, our algorithm has regret $\tilde {\mathcal{O}}((Td\ell)^{\frac{1}{2}})$. In a fully agnostic setting when the mask is an arbitrary function mapping to a set of size $n$, our algorithm has regret $\tilde {\mathcal{O}}(T^{\frac{3}{4}}n^{\frac{1}{2}})$. Finally, when the prices are stochastic, the algorithm has regret $\tilde {\mathcal{O}}((Tn)^{\frac{1}{2}})$.
Conformal prediction for the design problem
Feb 11, 2022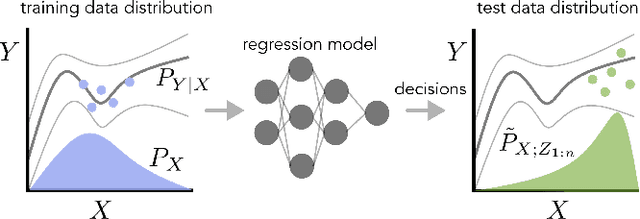
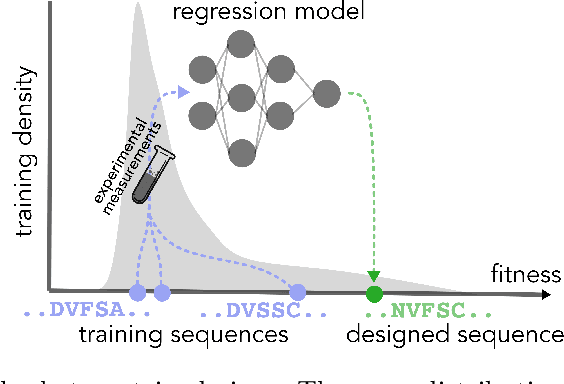
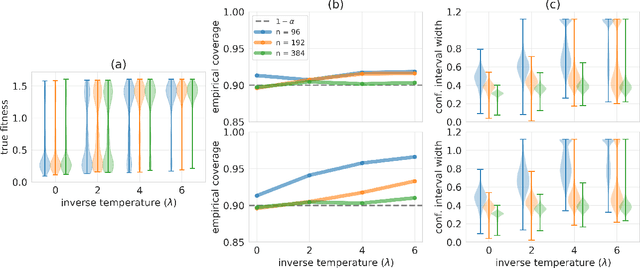
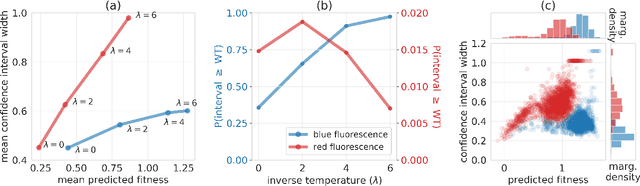
In many real-world deployments of machine learning, we use a prediction algorithm to choose what data to test next. For example, in the protein design problem, we have a regression model that predicts some real-valued property of a protein sequence, which we use to propose new sequences believed to exhibit higher property values than observed in the training data. Since validating designed sequences in the wet lab is typically costly, it is important to know how much we can trust the model's predictions. In such settings, however, there is a distinct type of distribution shift between the training and test data: one where the training and test data are statistically dependent, as the latter is chosen based on the former. Consequently, the model's error on the test data -- that is, the designed sequences -- has some non-trivial relationship with its error on the training data. Herein, we introduce a method to quantify predictive uncertainty in such settings. We do so by constructing confidence sets for predictions that account for the dependence between the training and test data. The confidence sets we construct have finite-sample guarantees that hold for any prediction algorithm, even when a trained model chooses the test-time input distribution. As a motivating use case, we demonstrate how our method quantifies uncertainty for the predicted fitness of designed protein using several real data sets.