 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond English-Centric Multilingual Machine Translation
Oct 21, 2020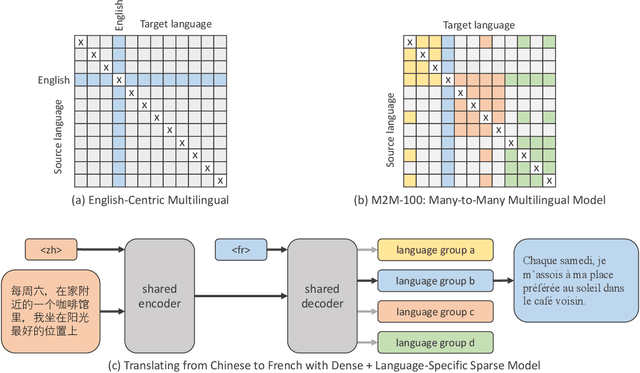

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
Self-training Improves Pre-training for Natural Language Understanding
Oct 05, 2020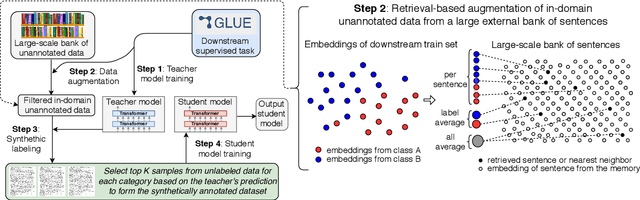
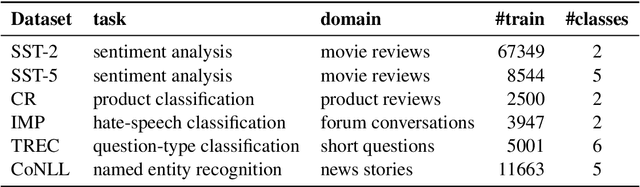
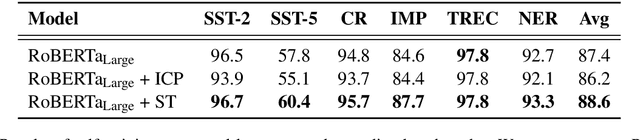

Unsupervised pre-training has led to much recent progress in natural language understanding. In this paper, we study self-training as another way to leverage unlabeled data through semi-supervised learning. To obtain additional data for a specific task, we introduce SentAugment, a data augmentation method which computes task-specific query embeddings from labeled data to retrieve sentences from a bank of billions of unlabeled sentences crawled from the web. Unlike previous semi-supervised methods, our approach does not require in-domain unlabeled data and is therefore more generally applicable. Experiments show that self-training is complementary to strong RoBERTa baselines on a variety of tasks. Our augmentation approach leads to scalable and effective self-training with improvements of up to 2.6% on standard text classification benchmarks. Finally, we also show strong gains on knowledge-distillation and few-shot learning.
Unsupervised Cross-lingual Representation Learning for Speech Recognition
Jun 24, 2020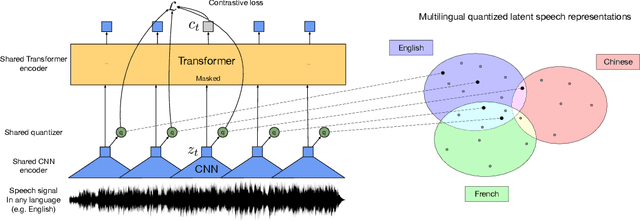
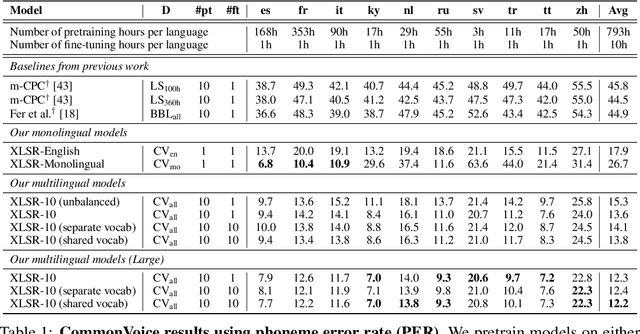
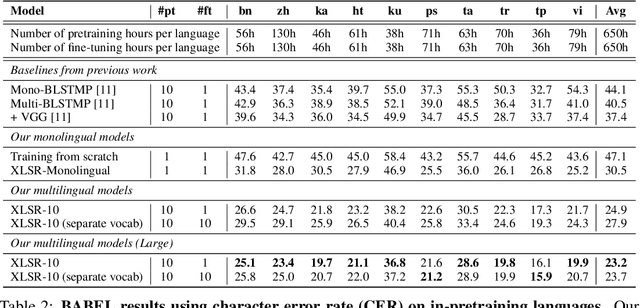
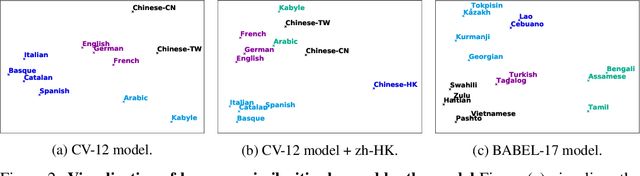
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on a concurrently introduced self-supervised model which is trained by solving a contrastive task over masked latent speech representations and jointly learns a quantization of the latents shared across languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to the strongest comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong individual models. Analysis shows that the latent discrete speech representations are shared across languages with increased sharing for related languages.
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
Jun 20, 2020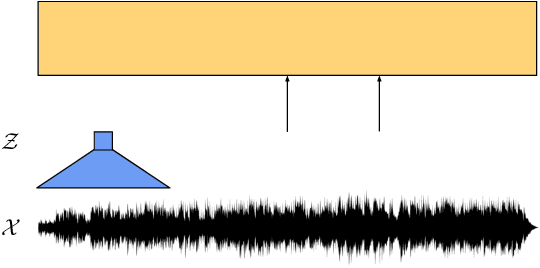
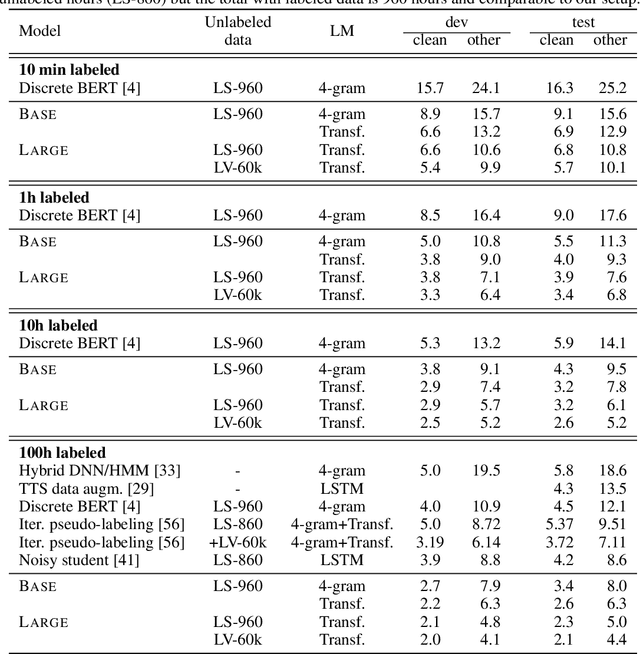
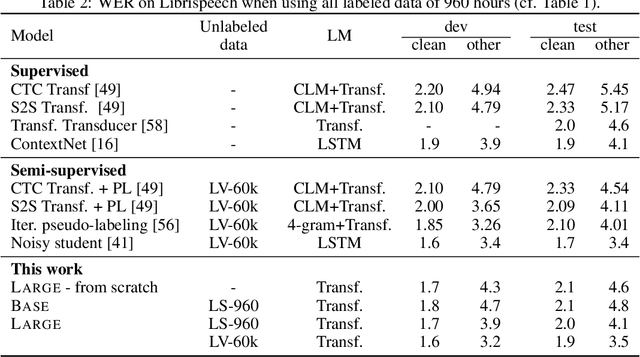
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. We set a new state of the art on both the 100 hour subset of Librispeech as well as on TIMIT phoneme recognition. When lowering the amount of labeled data to one hour, our model outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 5.7/10.1 WER on the noisy/clean test sets of Librispeech. This demonstrates the feasibility of speech recognition with limited amounts of labeled data. Fine-tuning on all of Librispeech achieves 1.9/3.5 WER using a simple baseline model architecture. We will release code and models.
Robust and On-the-fly Dataset Denoising for Image Classification
Apr 09, 2020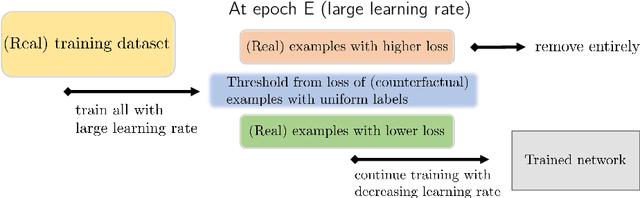
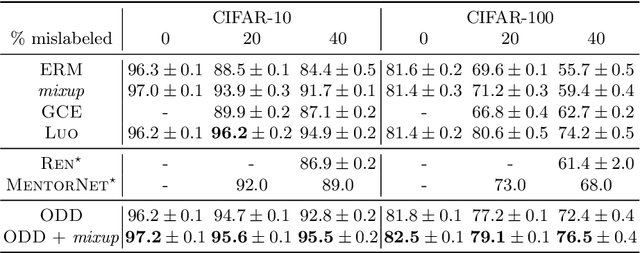

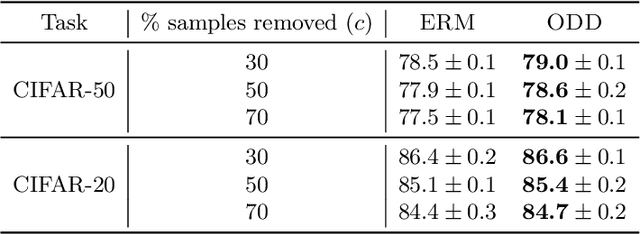
Memorization in over-parameterized neural networks could severely hurt generalization in the presence of mislabeled examples. However, mislabeled examples are hard to avoid in extremely large datasets collected with weak supervision. We address this problem by reasoning counterfactually about the loss distribution of examples with uniform random labels had they were trained with the real examples, and use this information to remove noisy examples from the training set. First, we observe that examples with uniform random labels have higher losses when trained with stochastic gradient descent under large learning rates. Then, we propose to model the loss distribution of the counterfactual examples using only the network parameters, which is able to model such examples with remarkable success. Finally, we propose to remove examples whose loss exceeds a certain quantile of the modeled loss distribution. This leads to On-the-fly Data Denoising (ODD), a simple yet effective algorithm that is robust to mislabeled examples, while introducing almost zero computational overhead compared to standard training. ODD is able to achieve state-of-the-art results on a wide range of datasets including real-world ones such as WebVision and Clothing1M.
Improving Conditioning in Context-Aware Sequence to Sequence Models
Nov 21, 2019
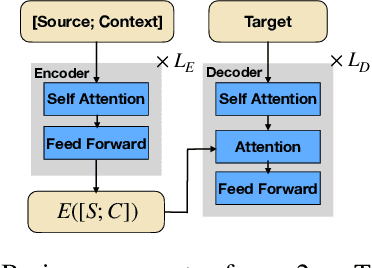
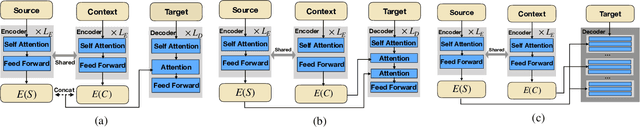
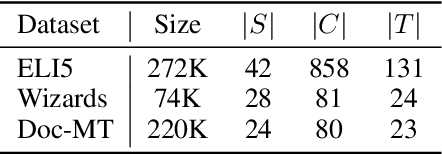
Neural sequence to sequence models are well established for applications which can be cast as mapping a single input sequence into a single output sequence. In this work, we focus on cases where generation is conditioned on both a short query and a long context, such as abstractive question answering or document-level translation. We modify the standard sequence-to-sequence approach to make better use of both the query and the context by expanding the conditioning mechanism to intertwine query and context attention. We also introduce a simple and efficient data augmentation method for the proposed model. Experiments on three different tasks show that both changes lead to consistent improvements.
Effectiveness of self-supervised pre-training for speech recognition
Nov 10, 2019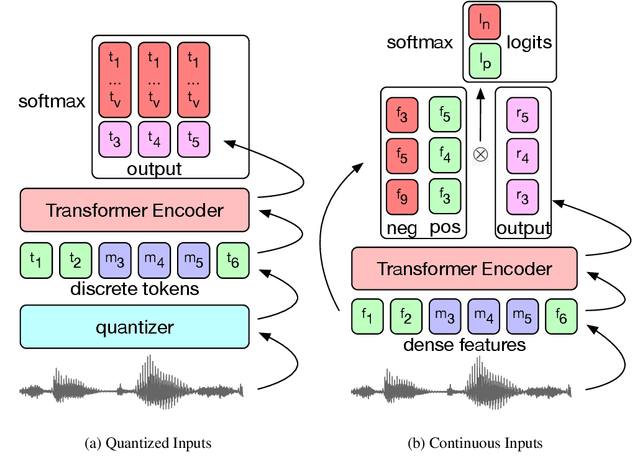
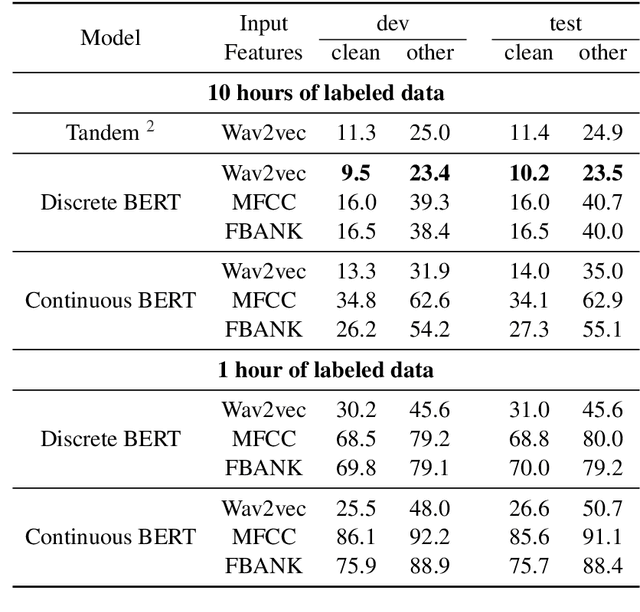
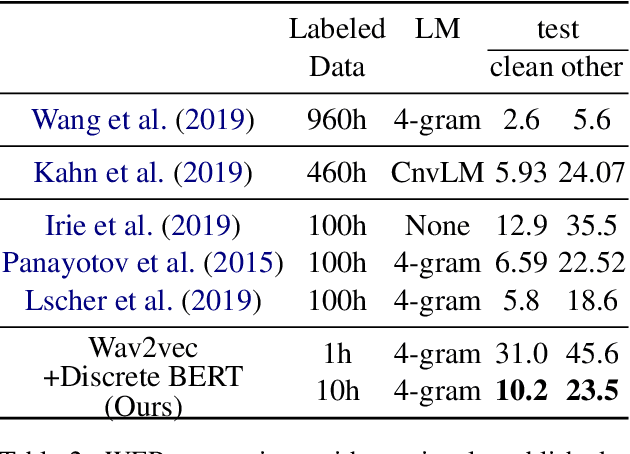
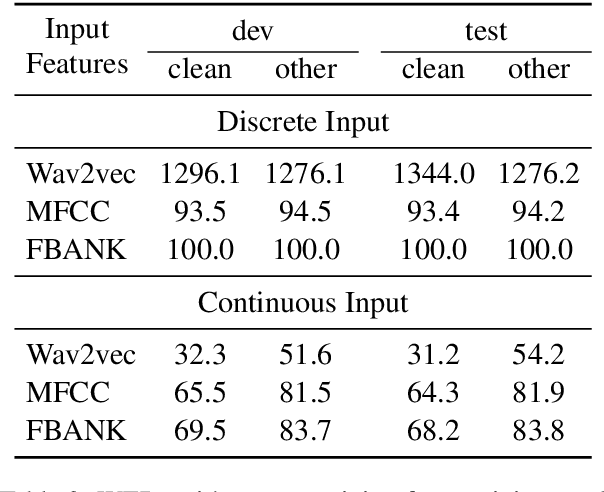
We present pre-training approaches for self-supervised representation learning of speech data. A BERT, masked language model, loss on discrete features is compared with an InfoNCE-based constrastive loss on continuous speech features. The pre-trained models are then fine-tuned with a Connectionist Temporal Classification (CTC) loss to predict target character sequences. To study impact of stacking multiple feature learning modules trained using different self-supervised loss functions, we test the discrete and continuous BERT pre-training approaches on spectral features and on learned acoustic representations, showing synergitic behaviour between acoustically motivated and masked language model loss functions. In low-resource conditions using only 10 hours of labeled data, we achieve Word Error Rates (WER) of 10.2\% and 23.5\% on the standard test "clean" and "other" benchmarks of the Librispeech dataset, which is almost on bar with previously published work that uses 10 times more labeled data. Moreover, compared to previous work that uses two models in tandem, by using one model for both BERT pre-trainining and fine-tuning, our model provides an average relative WER reduction of 9%.
Depth-Adaptive Transformer
Oct 22, 2019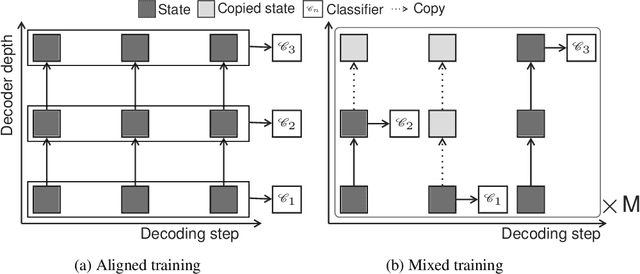
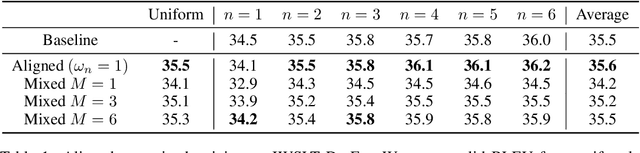
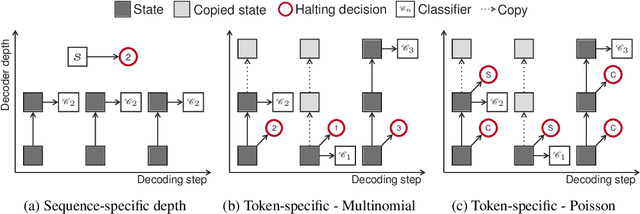
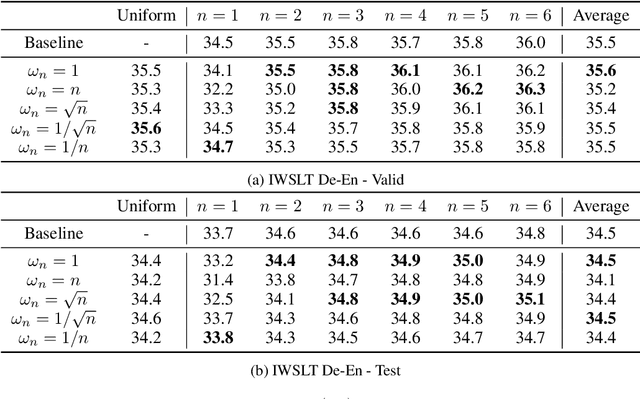
State of the art sequence-to-sequence models perform a fixed number of computations for each input sequence regardless of whether it is easy or hard to process. In this paper, we train Transformer models which can make output predictions at different stages of the network and we investigate different ways to predict how much computation is required for a particular sequence. Unlike dynamic computation in Universal Transformers, which applies the same set of layers iteratively, we apply different layers at every step to adjust both the amount of computation as well as the model capacity. Experiments on machine translation benchmarks show that this approach can match the accuracy of a baseline Transformer while using only half the number of decoder layers.
vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations
Oct 12, 2019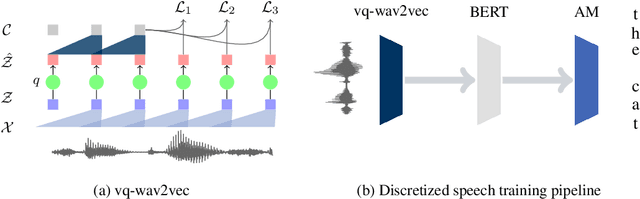
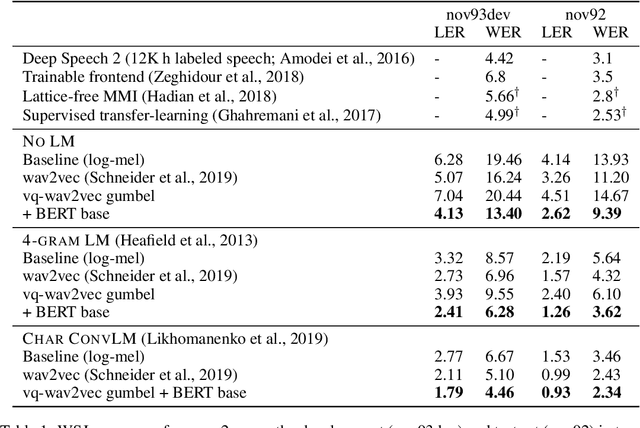
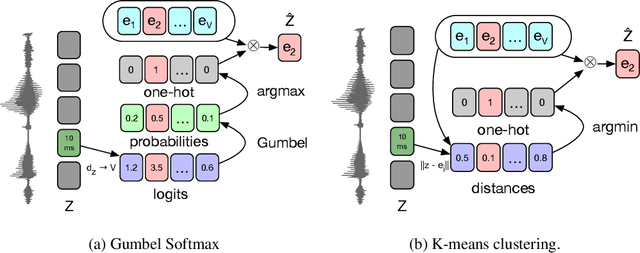
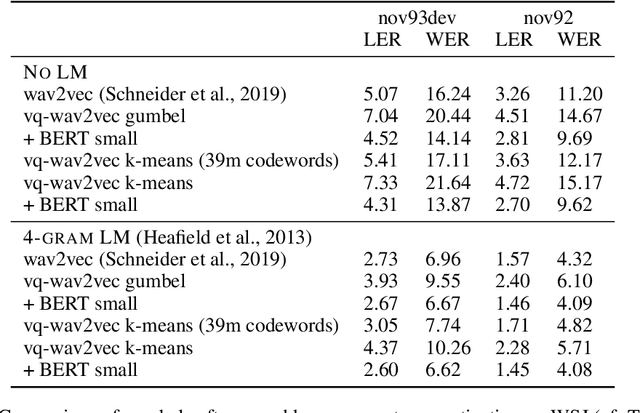
We propose vq-wav2vec to learn discrete representations of audio segments through a wav2vec-style self-supervised context prediction task. The algorithm uses either a gumbel softmax or online k-means clustering to quantize the dense representations. Discretization enables the direct application of algorithms from the NLP community which require discrete inputs. Experiments show that BERT pre-training achieves a new state of the art on TIMIT phoneme classification and WSJ speech recognition.
The Source-Target Domain Mismatch Problem in Machine Translation
Sep 28, 2019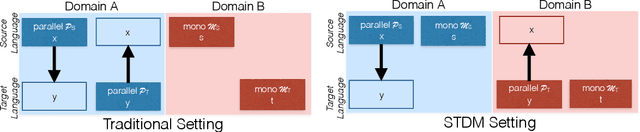
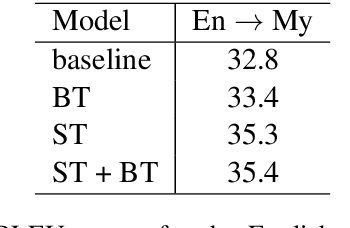
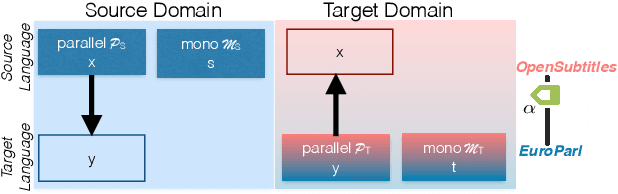
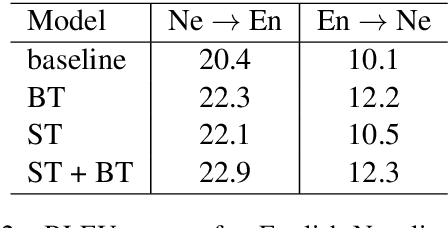
While we live in an increasingly interconnected world, different places still exhibit strikingly different cultures and many events we experience in our every day life pertain only to the specific place we live in. As a result, people often talk about different things in different parts of the world. In this work we study the effect of local context in machine translation and postulate that particularly in low resource settings this causes the domains of the source and target language to greatly mismatch, as the two languages are often spoken in further apart regions of the world with more distinctive cultural traits and unrelated local events. In this work we first propose a controlled setting to carefully analyze the source-target domain mismatch, and its dependence on the amount of parallel and monolingual data. Second, we test both a model trained with back-translation and one trained with self-training. The latter leverages in-domain source monolingual data but uses potentially incorrect target references. We found that these two approaches are often complementary to each other. For instance, on a low-resource Nepali-English dataset the combined approach improves upon the baseline using just parallel data by 2.5 BLEU points, and by 0.6 BLEU point when compared to back-translation.