 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Communicate and Correct Pose Errors
Nov 10, 2020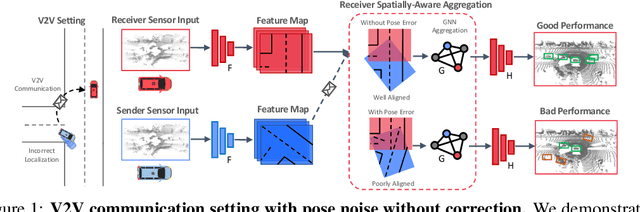
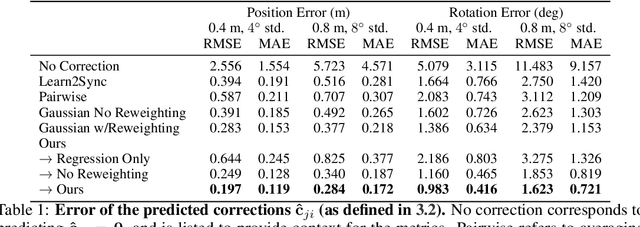
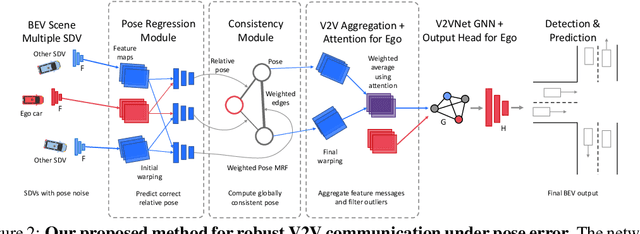
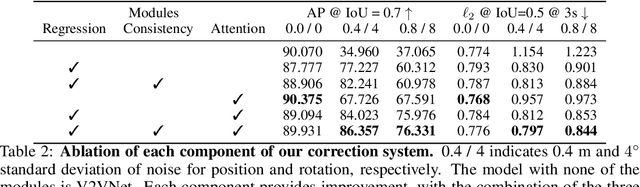
Learned communication makes multi-agent systems more effective by aggregating distributed information. However, it also exposes individual agents to the threat of erroneous messages they might receive. In this paper, we study the setting proposed in V2VNet, where nearby self-driving vehicles jointly perform object detection and motion forecasting in a cooperative manner. Despite a huge performance boost when the agents solve the task together, the gain is quickly diminished in the presence of pose noise since the communication relies on spatial transformations. Hence, we propose a novel neural reasoning framework that learns to communicate, to estimate potential errors, and finally, to reach a consensus about those errors. Experiments confirm that our proposed framework significantly improves the robustness of multi-agent self-driving perception and motion forecasting systems under realistic and severe localization noise.
Perceive, Attend, and Drive: Learning Spatial Attention for Safe Self-Driving
Nov 02, 2020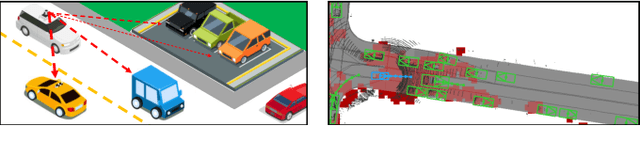
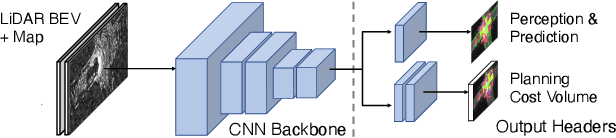
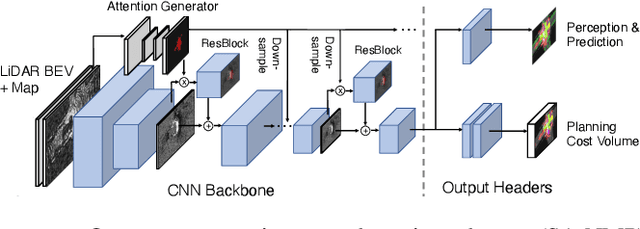
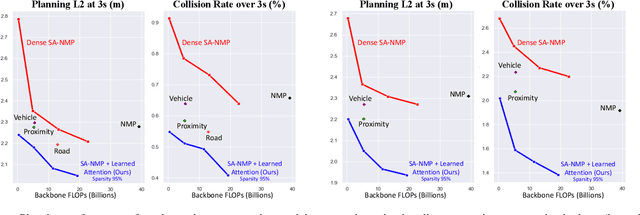
In this paper, we propose an end-to-end self-driving network featuring a sparse attention module that learns to automatically attend to important regions of the input. The attention module specifically targets motion planning, whereas prior literature only applied attention in perception tasks. Learning an attention mask directly targeted for motion planning significantly improves the planner safety by performing more focused computation. Furthermore, visualizing the attention improves interpretability of end-to-end self-driving.
Theoretical bounds on estimation error for meta-learning
Oct 14, 2020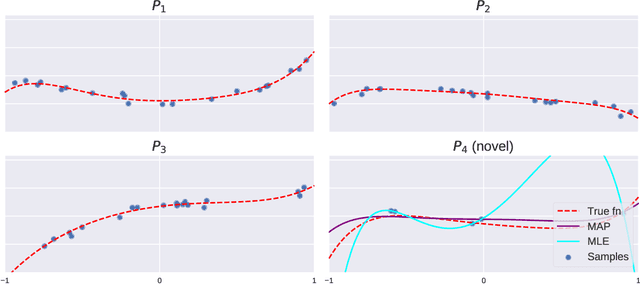

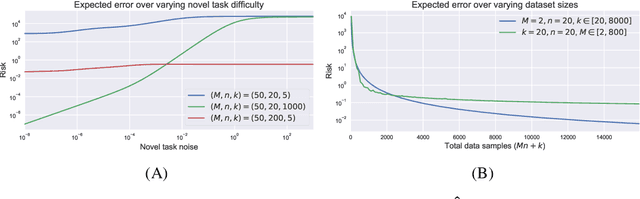

Machine learning models have traditionally been developed under the assumption that the training and test distributions match exactly. However, recent success in few-shot learning and related problems are encouraging signs that these models can be adapted to more realistic settings where train and test distributions differ. Unfortunately, there is severely limited theoretical support for these algorithms and little is known about the difficulty of these problems. In this work, we provide novel information-theoretic lower-bounds on minimax rates of convergence for algorithms that are trained on data from multiple sources and tested on novel data. Our bounds depend intuitively on the information shared between sources of data, and characterize the difficulty of learning in this setting for arbitrary algorithms. We demonstrate these bounds on a hierarchical Bayesian model of meta-learning, computing both upper and lower bounds on parameter estimation via maximum-a-posteriori inference.
SketchEmbedNet: Learning Novel Concepts by Imitating Drawings
Aug 27, 2020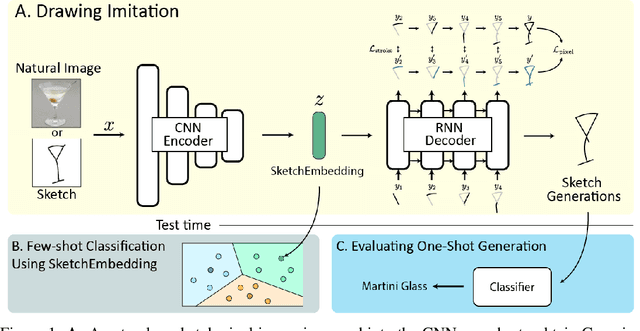
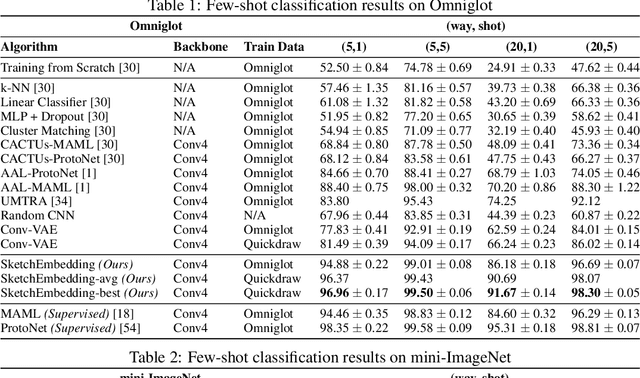

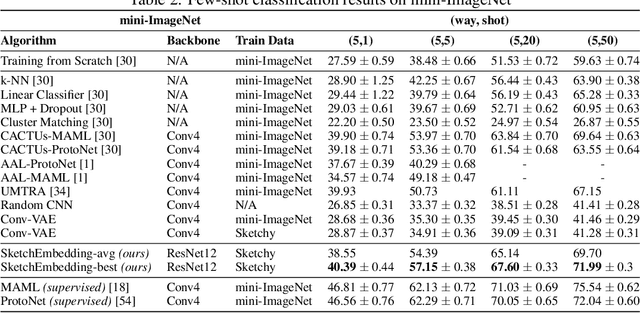
Sketch drawings are an intuitive visual domain that generally preserves semantics. Previous work has shown that recurrent neural networks are capable of producing sketch drawings of a single or few classes at a time. In this work we focus on the representations developed by training a generative model to produce sketches from pixel images across many classes in a sketch domain. We find that the embeddings learned by this sketching model are extremely informative for visual tasks and infer compositional information. We then use them to exceed state-of-the-art performance in unsupervised few-shot classification on the Omniglot and mini-ImageNet benchmarks. We also leverage the generative capacity of our model to produce high quality sketches of novel classes based on just a single example.
Perceive, Predict, and Plan: Safe Motion Planning Through Interpretable Semantic Representations
Aug 13, 2020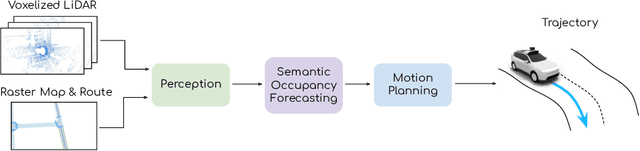
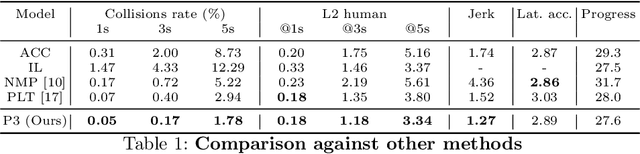
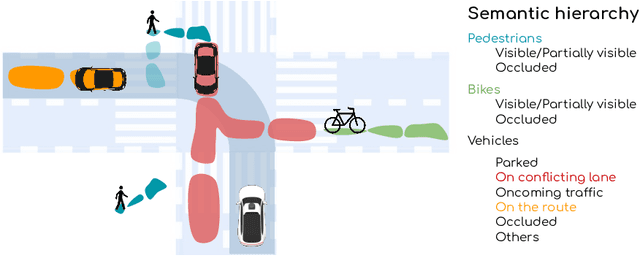
In this paper we propose a novel end-to-end learnable network that performs joint perception, prediction and motion planning for self-driving vehicles and produces interpretable intermediate representations. Unlike existing neural motion planners, our motion planning costs are consistent with our perception and prediction estimates. This is achieved by a novel differentiable semantic occupancy representation that is explicitly used as cost by the motion planning process. Our network is learned end-to-end from human demonstrations. The experiments in a large-scale manual-driving dataset and closed-loop simulation show that the proposed model significantly outperforms state-of-the-art planners in imitating the human behaviors while producing much safer trajectories.
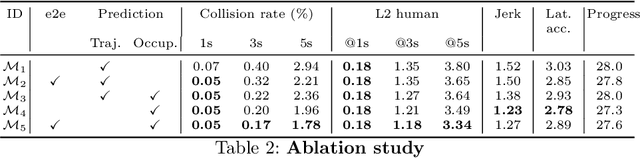
End-to-end Contextual Perception and Prediction with Interaction Transformer
Aug 13, 2020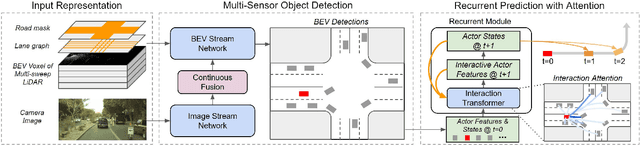
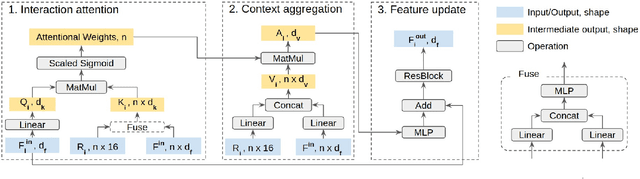
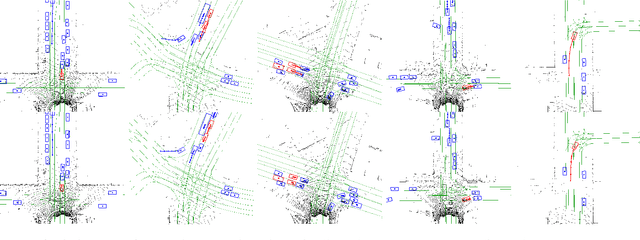
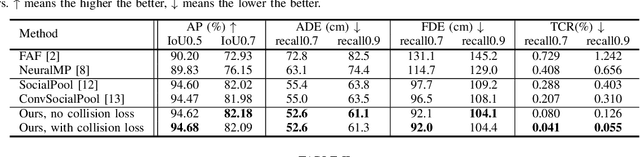
In this paper, we tackle the problem of detecting objects in 3D and forecasting their future motion in the context of self-driving. Towards this goal, we design a novel approach that explicitly takes into account the interactions between actors. To capture their spatial-temporal dependencies, we propose a recurrent neural network with a novel Transformer architecture, which we call the Interaction Transformer. Importantly, our model can be trained end-to-end, and runs in real-time. We validate our approach on two challenging real-world datasets: ATG4D and nuScenes. We show that our approach can outperform the state-of-the-art on both datasets. In particular, we significantly improve the social compliance between the estimated future trajectories, resulting in far fewer collisions between the predicted actors.
LoCo: Local Contrastive Representation Learning
Aug 04, 2020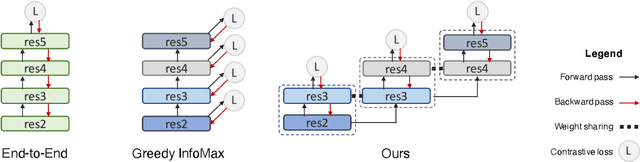
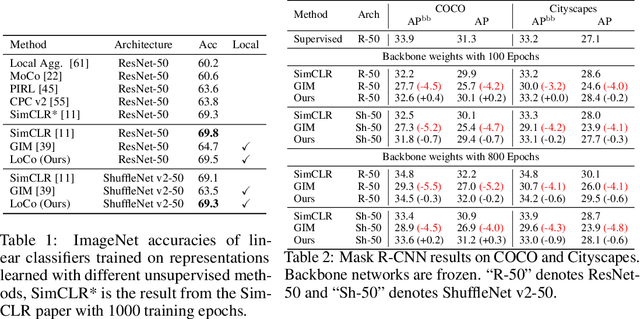
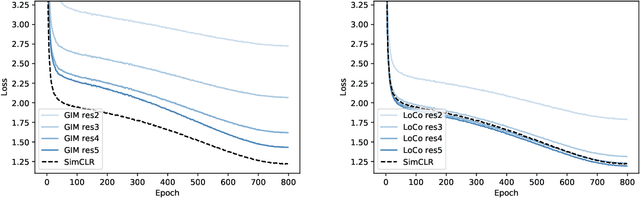
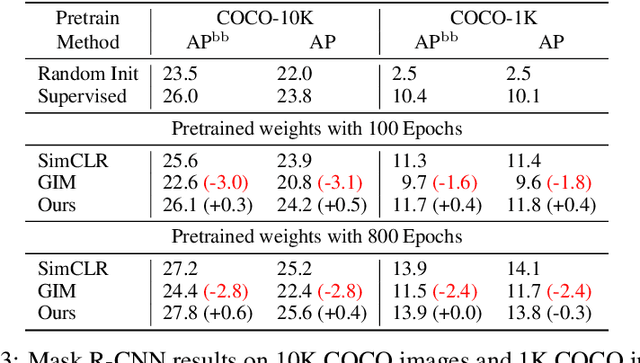
Deep neural nets typically perform end-to-end backpropagation to learn the weights, a procedure that creates synchronization constraints in the weight update step across layers and is not biologically plausible. Recent advances in unsupervised contrastive representation learning point to the question of whether a learning algorithm can also be made local, that is, the updates of lower layers do not directly depend on the computation of upper layers. While Greedy InfoMax separately learns each block with a local objective, we found that it consistently hurts readout accuracy in state-of-the-art unsupervised contrastive learning algorithms, possibly due to the greedy objective as well as gradient isolation. In this work, we discover that by overlapping local blocks stacking on top of each other, we effectively increase the decoder depth and allow upper blocks to implicitly send feedbacks to lower blocks. This simple design closes the performance gap between local learning and end-to-end contrastive learning algorithms for the first time. Aside from standard ImageNet experiments, we also show results on complex downstream tasks such as object detection and instance segmentation directly using readout features.
Multi-Agent Routing Value Iteration Network
Jul 09, 2020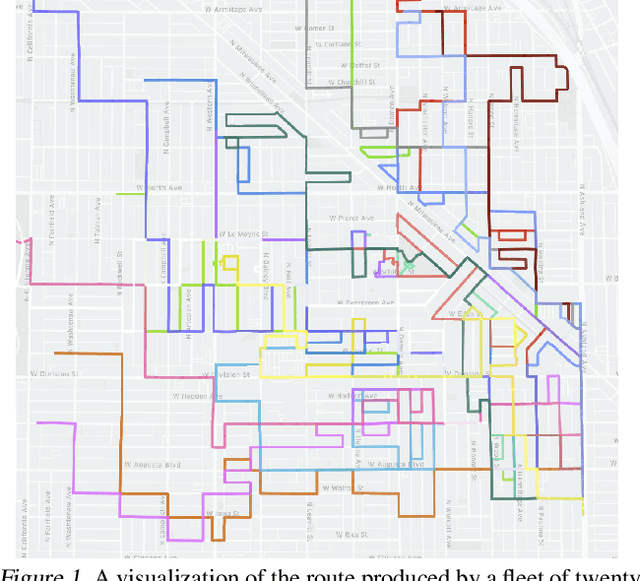

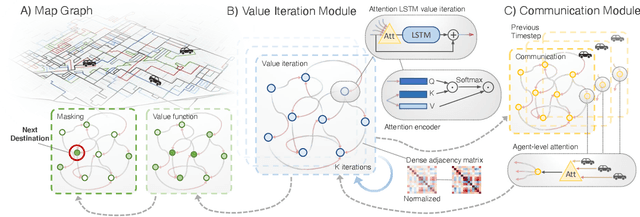
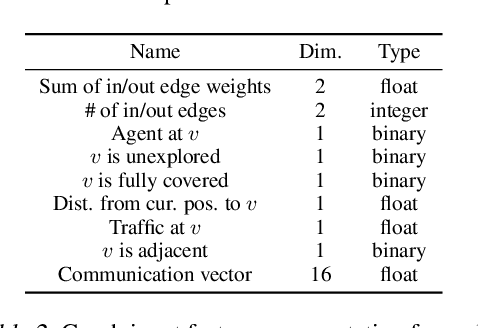
In this paper we tackle the problem of routing multiple agents in a coordinated manner. This is a complex problem that has a wide range of applications in fleet management to achieve a common goal, such as mapping from a swarm of robots and ride sharing. Traditional methods are typically not designed for realistic environments hich contain sparsely connected graphs and unknown traffic, and are often too slow in runtime to be practical. In contrast, we propose a graph neural network based model that is able to perform multi-agent routing based on learned value iteration in a sparsely connected graph with dynamically changing traffic conditions. Moreover, our learned communication module enables the agents to coordinate online and adapt to changes more effectively. We created a simulated environment to mimic realistic mapping performed by autonomous vehicles with unknown minimum edge coverage and traffic conditions; our approach significantly outperforms traditional solvers both in terms of total cost and runtime. We also show that our model trained with only two agents on graphs with a maximum of 25 nodes can easily generalize to situations with more agents and/or nodes.
Wandering Within a World: Online Contextualized Few-Shot Learning
Jul 09, 2020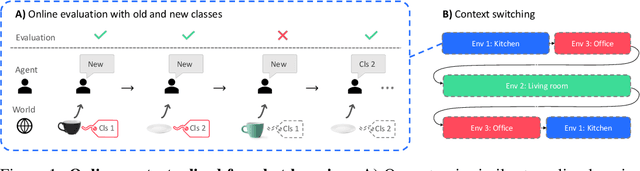


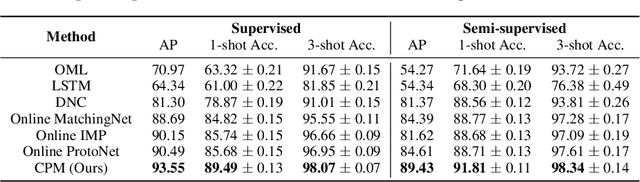
We aim to bridge the gap between typical human and machine-learning environments by extending the standard framework of few-shot learning to an online, continual setting. In this setting, episodes do not have separate training and testing phases, and instead models are evaluated online while learning novel classes. As in real world, where the presence of spatiotemporal context helps us retrieve learned skills in the past, our online few-shot learning setting also features an underlying context that changes throughout time. Object classes are correlated within a context and inferring the correct context can lead to better performance. Building upon this setting, we propose a new few-shot learning dataset based on large scale indoor imagery that mimics the visual experience of an agent wandering within a world. Furthermore, we convert popular few-shot learning approaches into online versions and we also propose a new model named contextual prototypical memory that can make use of spatiotemporal contextual information from the recent past.
Physically Realizable Adversarial Examples for LiDAR Object Detection
Apr 02, 2020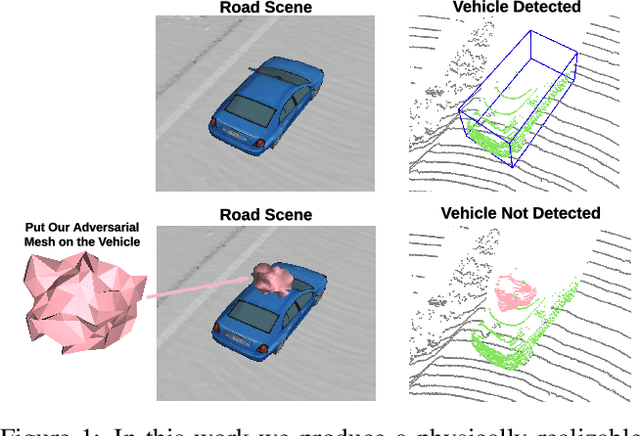
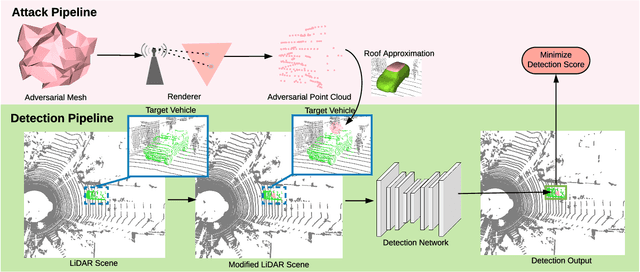
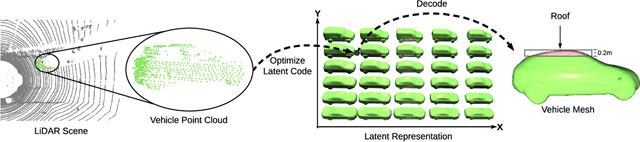

Modern autonomous driving systems rely heavily on deep learning models to process point cloud sensory data; meanwhile, deep models have been shown to be susceptible to adversarial attacks with visually imperceptible perturbations. Despite the fact that this poses a security concern for the self-driving industry, there has been very little exploration in terms of 3D perception, as most adversarial attacks have only been applied to 2D flat images. In this paper, we address this issue and present a method to generate universal 3D adversarial objects to fool LiDAR detectors. In particular, we demonstrate that placing an adversarial object on the rooftop of any target vehicle to hide the vehicle entirely from LiDAR detectors with a success rate of 80%. We report attack results on a suite of detectors using various input representation of point clouds. We also conduct a pilot study on adversarial defense using data augmentation. This is one step closer towards safer self-driving under unseen conditions from limited training data.