 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMehdi Rezagholizadeh
Attribute Controlled Dialogue Prompting
Jul 11, 2023
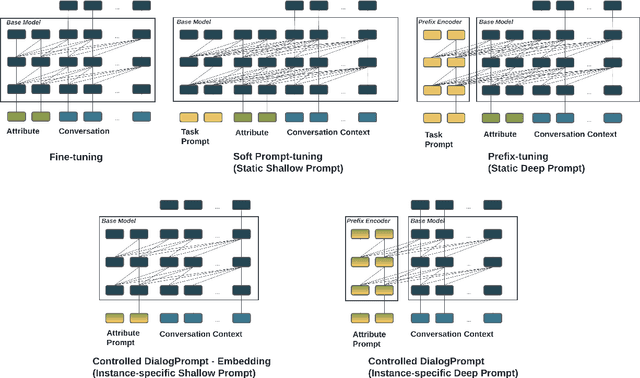


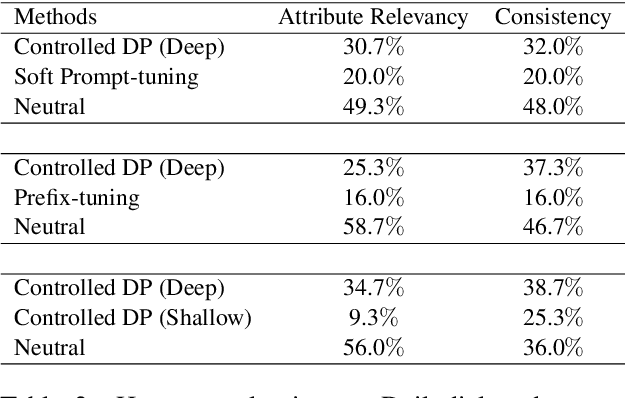
Prompt-tuning has become an increasingly popular parameter-efficient method for adapting large pretrained language models to downstream tasks. However, both discrete prompting and continuous prompting assume fixed prompts for all data samples within a task, neglecting the fact that inputs vary greatly in some tasks such as open-domain dialogue generation. In this paper, we present a novel, instance-specific prompt-tuning algorithm for dialogue generation. Specifically, we generate prompts based on instance-level control code, rather than the conversation history, to explore their impact on controlled dialogue generation. Experiments on popular open-domain dialogue datasets, evaluated on both automated metrics and human evaluation, demonstrate that our method is superior to prompting baselines and comparable to fine-tuning with only 5%-6% of total parameters.
Multimodal Audio-textual Architecture for Robust Spoken Language Understanding
Jun 13, 2023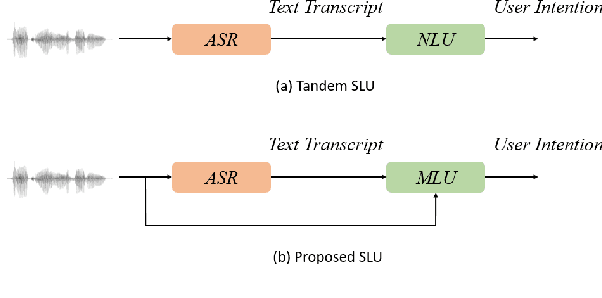
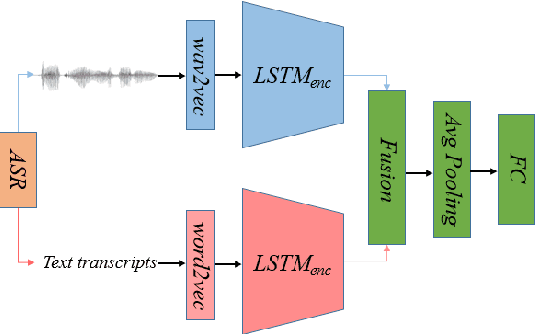
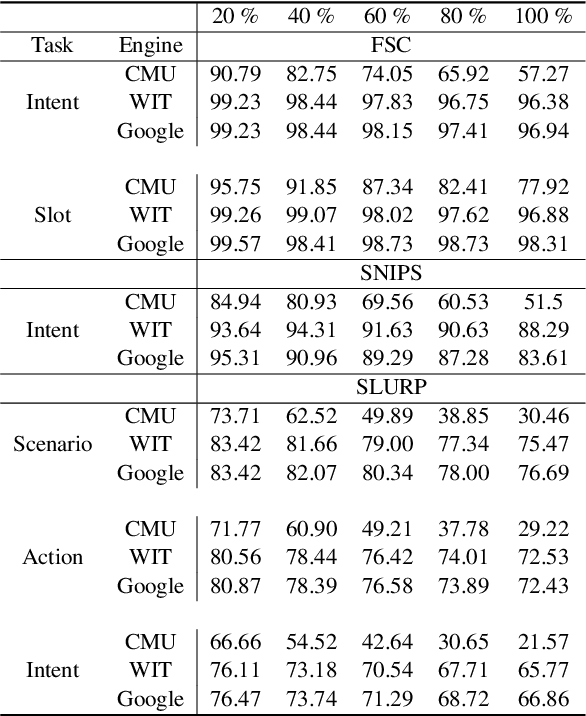
Recent voice assistants are usually based on the cascade spoken language understanding (SLU) solution, which consists of an automatic speech recognition (ASR) engine and a natural language understanding (NLU) system. Because such approach relies on the ASR output, it often suffers from the so-called ASR error propagation. In this work, we investigate impacts of this ASR error propagation on state-of-the-art NLU systems based on pre-trained language models (PLM), such as BERT and RoBERTa. Moreover, a multimodal language understanding (MLU) module is proposed to mitigate SLU performance degradation caused by errors present in the ASR transcript. The MLU benefits from self-supervised features learned from both audio and text modalities, specifically Wav2Vec for speech and Bert/RoBERTa for language. Our MLU combines an encoder network to embed the audio signal and a text encoder to process text transcripts followed by a late fusion layer to fuse audio and text logits. We found that the proposed MLU showed to be robust towards poor quality ASR transcripts, while the performance of BERT and RoBERTa are severely compromised. Our model is evaluated on five tasks from three SLU datasets and robustness is tested using ASR transcripts from three ASR engines. Results show that the proposed approach effectively mitigates the ASR error propagation problem, surpassing the PLM models' performance across all datasets for the academic ASR engine.
AraMUS: Pushing the Limits of Data and Model Scale for Arabic Natural Language Processing
Jun 11, 2023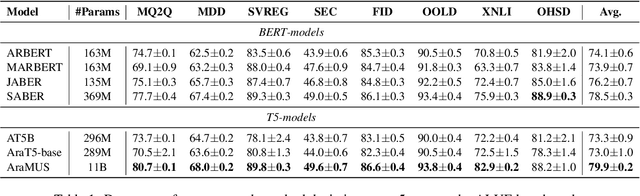
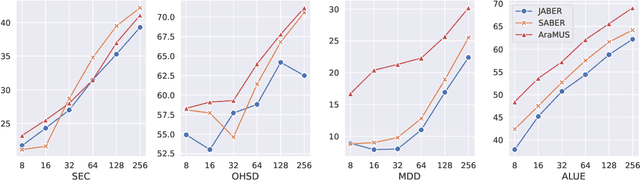
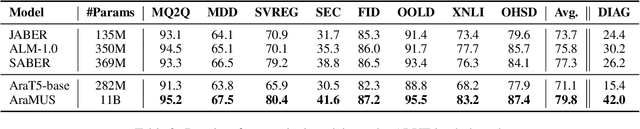

Developing monolingual large Pre-trained Language Models (PLMs) is shown to be very successful in handling different tasks in Natural Language Processing (NLP). In this work, we present AraMUS, the largest Arabic PLM with 11B parameters trained on 529GB of high-quality Arabic textual data. AraMUS achieves state-of-the-art performances on a diverse set of Arabic classification and generative tasks. Moreover, AraMUS shows impressive few-shot learning abilities compared with the best existing Arabic PLMs.
Measuring the Knowledge Acquisition-Utilization Gap in Pretrained Language Models
May 24, 2023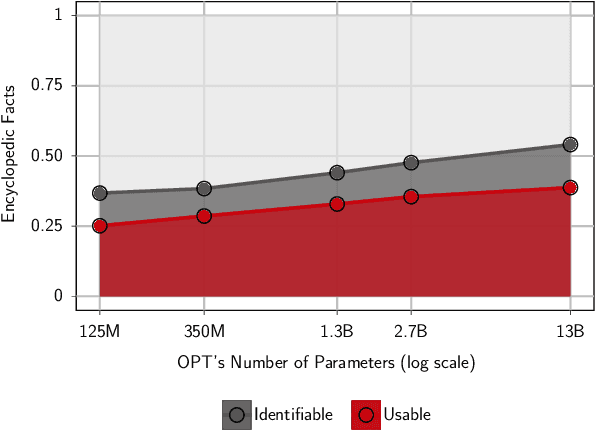

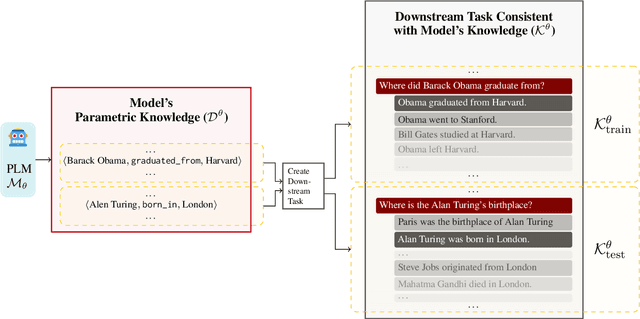

While pre-trained language models (PLMs) have shown evidence of acquiring vast amounts of knowledge, it remains unclear how much of this parametric knowledge is actually usable in performing downstream tasks. We propose a systematic framework to measure parametric knowledge utilization in PLMs. Our framework first extracts knowledge from a PLM's parameters and subsequently constructs a downstream task around this extracted knowledge. Performance on this task thus depends exclusively on utilizing the model's possessed knowledge, avoiding confounding factors like insufficient signal. As an instantiation, we study factual knowledge of PLMs and measure utilization across 125M to 13B parameter PLMs. We observe that: (1) PLMs exhibit two gaps - in acquired vs. utilized knowledge, (2) they show limited robustness in utilizing knowledge under distribution shifts, and (3) larger models close the acquired knowledge gap but the utilized knowledge gap remains. Overall, our study provides insights into PLMs' capabilities beyond their acquired knowledge.
On the Transferability of Whisper-based Representations for "In-the-Wild" Cross-Task Downstream Speech Applications
May 23, 2023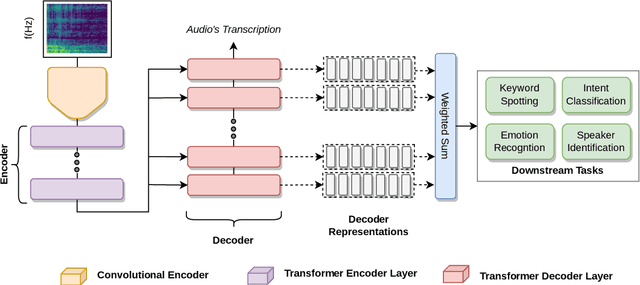
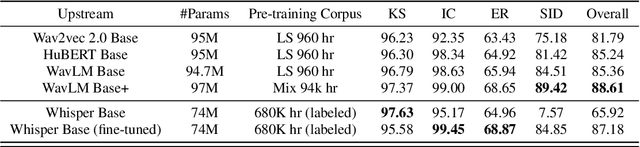

Large self-supervised pre-trained speech models have achieved remarkable success across various speech-processing tasks. The self-supervised training of these models leads to universal speech representations that can be used for different downstream tasks, ranging from automatic speech recognition (ASR) to speaker identification. Recently, Whisper, a transformer-based model was proposed and trained on large amount of weakly supervised data for ASR; it outperformed several state-of-the-art self-supervised models. Given the superiority of Whisper for ASR, in this paper we explore the transferability of the representation for four other speech tasks in SUPERB benchmark. Moreover, we explore the robustness of Whisper representation for ``in the wild'' tasks where speech is corrupted by environment noise and room reverberation. Experimental results show Whisper achieves promising results across tasks and environmental conditions, thus showing potential for cross-task real-world deployment.
Evaluating Embedding APIs for Information Retrieval
May 10, 2023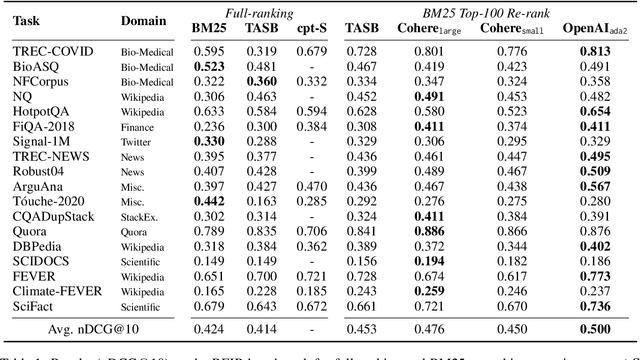
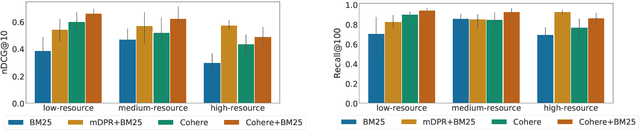
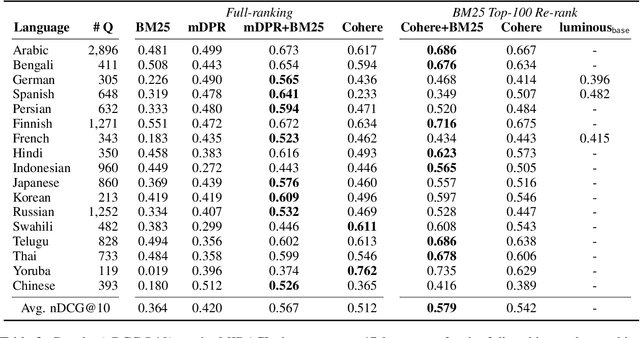
The ever-increasing size of language models curtails their widespread access to the community, thereby galvanizing many companies and startups into offering access to large language models through APIs. One particular API, suitable for dense retrieval, is the semantic embedding API that builds vector representations of a given text. With a growing number of APIs at our disposal, in this paper, our goal is to analyze semantic embedding APIs in realistic retrieval scenarios in order to assist practitioners and researchers in finding suitable services according to their needs. Specifically, we wish to investigate the capabilities of existing APIs on domain generalization and multilingual retrieval. For this purpose, we evaluate the embedding APIs on two standard benchmarks, BEIR, and MIRACL. We find that re-ranking BM25 results using the APIs is a budget-friendly approach and is most effective on English, in contrast to the standard practice, i.e., employing them as first-stage retrievers. For non-English retrieval, re-ranking still improves the results, but a hybrid model with BM25 works best albeit at a higher cost. We hope our work lays the groundwork for thoroughly evaluating APIs that are critical in search and more broadly, in information retrieval.
An Exploration into the Performance of Unsupervised Cross-Task Speech Representations for "In the Wild'' Edge Applications
May 09, 2023
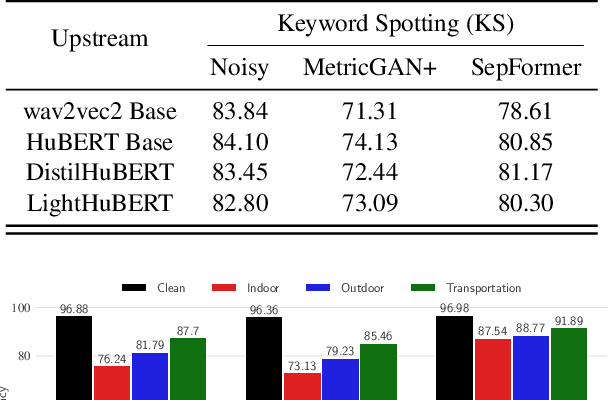
Unsupervised speech models are becoming ubiquitous in the speech and machine learning communities. Upstream models are responsible for learning meaningful representations from raw audio. Later, these representations serve as input to downstream models to solve a number of tasks, such as keyword spotting or emotion recognition. As edge speech applications start to emerge, it is important to gauge how robust these cross-task representations are on edge devices with limited resources and different noise levels. To this end, in this study we evaluate the robustness of four different versions of HuBERT, namely: base, large, and extra-large versions, as well as a recent version termed Robust-HuBERT. Tests are conducted under different additive and convolutive noise conditions for three downstream tasks: keyword spotting, intent classification, and emotion recognition. Our results show that while larger models can provide some important robustness to environmental factors, they may not be applicable to edge applications. Smaller models, on the other hand, showed substantial accuracy drops in noisy conditions, especially in the presence of room reverberation. These findings suggest that cross-task speech representations are not yet ready for edge applications and innovations are still needed.
LABO: Towards Learning Optimal Label Regularization via Bi-level Optimization
May 08, 2023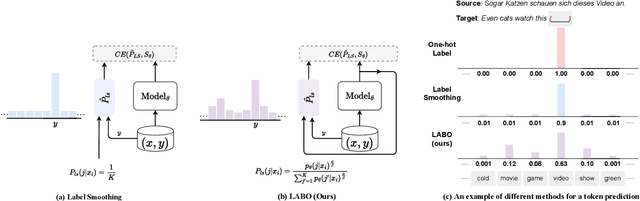
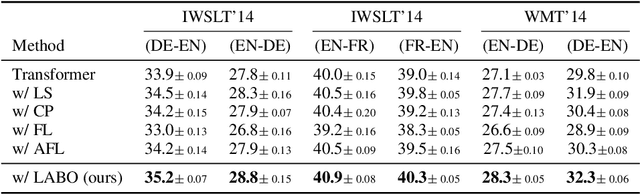
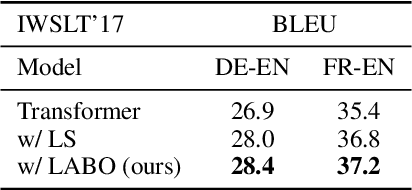
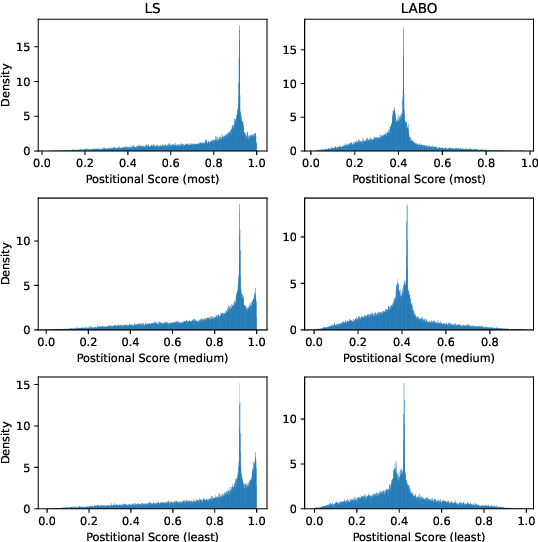
Regularization techniques are crucial to improving the generalization performance and training efficiency of deep neural networks. Many deep learning algorithms rely on weight decay, dropout, batch/layer normalization to converge faster and generalize. Label Smoothing (LS) is another simple, versatile and efficient regularization which can be applied to various supervised classification tasks. Conventional LS, however, regardless of the training instance assumes that each non-target class is equally likely. In this work, we present a general framework for training with label regularization, which includes conventional LS but can also model instance-specific variants. Based on this formulation, we propose an efficient way of learning LAbel regularization by devising a Bi-level Optimization (LABO) problem. We derive a deterministic and interpretable solution of the inner loop as the optimal label smoothing without the need to store the parameters or the output of a trained model. Finally, we conduct extensive experiments and demonstrate our LABO consistently yields improvement over conventional label regularization on various fields, including seven machine translation and three image classification tasks across various
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Apr 03, 2023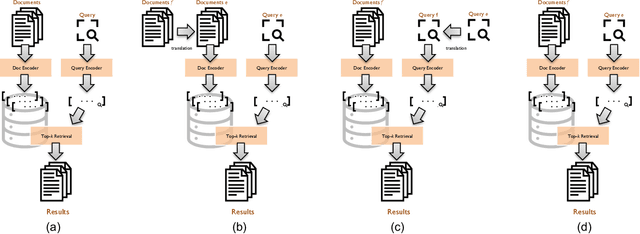
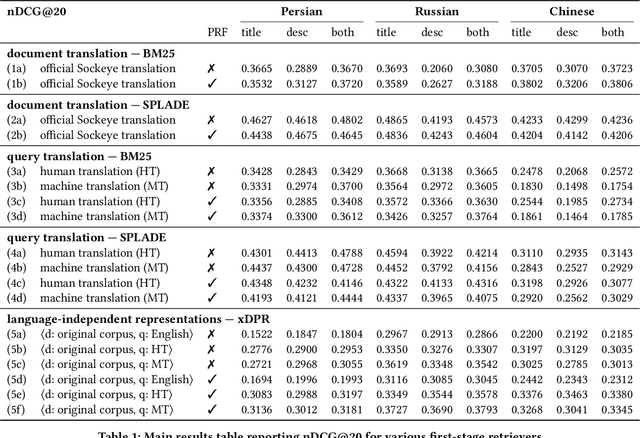
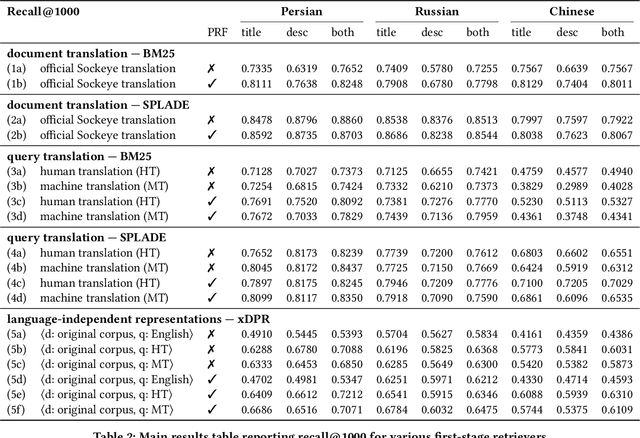
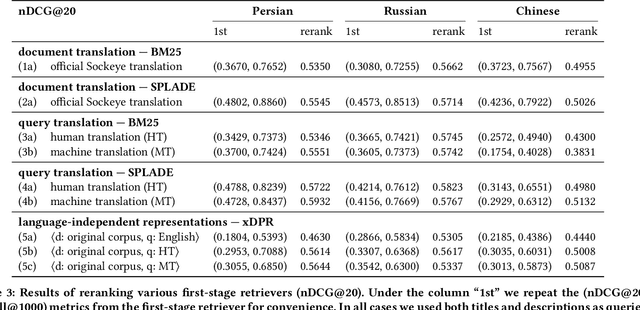
The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.
RobustDistiller: Compressing Universal Speech Representations for Enhanced Environment Robustness
Feb 23, 2023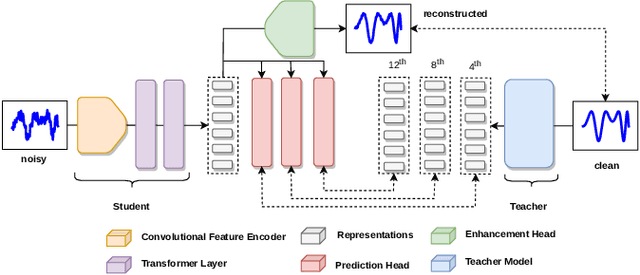
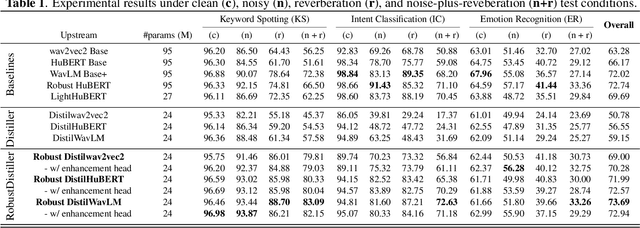

Self-supervised speech pre-training enables deep neural network models to capture meaningful and disentangled factors from raw waveform signals. The learned universal speech representations can then be used across numerous downstream tasks. These representations, however, are sensitive to distribution shifts caused by environmental factors, such as noise and/or room reverberation. Their large sizes, in turn, make them unfeasible for edge applications. In this work, we propose a knowledge distillation methodology termed RobustDistiller which compresses universal representations while making them more robust against environmental artifacts via a multi-task learning objective. The proposed layer-wise distillation recipe is evaluated on top of three well-established universal representations, as well as with three downstream tasks. Experimental results show the proposed methodology applied on top of the WavLM Base+ teacher model outperforming all other benchmarks across noise types and levels, as well as reverberation times. Oftentimes, the obtained results with the student model (24M parameters) achieved results inline with those of the teacher model (95M).