 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalcony: A Lightweight Approach to Dynamic Inference of Generative Language Models
Mar 06, 2025Deploying large language models (LLMs) in real-world applications is often hindered by strict computational and latency constraints. While dynamic inference offers the flexibility to adjust model behavior based on varying resource budgets, existing methods are frequently limited by hardware inefficiencies or performance degradation. In this paper, we introduce Balcony, a simple yet highly effective framework for depth-based dynamic inference. By freezing the pretrained LLM and inserting additional transformer layers at selected exit points, Balcony maintains the full model's performance while enabling real-time adaptation to different computational budgets. These additional layers are trained using a straightforward self-distillation loss, aligning the sub-model outputs with those of the full model. This approach requires significantly fewer training tokens and tunable parameters, drastically reducing computational costs compared to prior methods. When applied to the LLaMA3-8B model, using only 0.2% of the original pretraining data, Balcony achieves minimal performance degradation while enabling significant speedups. Remarkably, we show that Balcony outperforms state-of-the-art methods such as Flextron and Layerskip as well as other leading compression techniques on multiple models and at various scales, across a variety of benchmarks.
QDyLoRA: Quantized Dynamic Low-Rank Adaptation for Efficient Large Language Model Tuning
Feb 16, 2024



Finetuning large language models requires huge GPU memory, restricting the choice to acquire Larger models. While the quantized version of the Low-Rank Adaptation technique, named QLoRA, significantly alleviates this issue, finding the efficient LoRA rank is still challenging. Moreover, QLoRA is trained on a pre-defined rank and, therefore, cannot be reconfigured for its lower ranks without requiring further fine-tuning steps. This paper proposes QDyLoRA -Quantized Dynamic Low-Rank Adaptation-, as an efficient quantization approach for dynamic low-rank adaptation. Motivated by Dynamic LoRA, QDyLoRA is able to efficiently finetune LLMs on a set of pre-defined LoRA ranks. QDyLoRA enables fine-tuning Falcon-40b for ranks 1 to 64 on a single 32 GB V100-GPU through one round of fine-tuning. Experimental results show that QDyLoRA is competitive to QLoRA and outperforms when employing its optimal rank.
Sorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic Inference Using Sorted Fine-Tuning (SoFT)
Sep 16, 2023



The rapid advancement of large language models (LLMs) has revolutionized natural language processing (NLP). While these models excel at understanding and generating human-like text, their widespread deployment can be prohibitively expensive. SortedNet is a recent training technique for enabling dynamic inference for deep neural networks. It leverages network modularity to create sub-models with varying computational loads, sorting them based on computation/accuracy characteristics in a nested manner. We extend SortedNet to generative NLP tasks, making large language models dynamic without any pretraining and by only replacing standard Supervised Fine-Tuning (SFT) with Sorted Fine-Tuning (SoFT) at the same costs. Our approach boosts model efficiency, eliminating the need for multiple models for various scenarios during inference. We show that using this approach, we are able to unlock the potential of intermediate layers of transformers in generating the target output. Our sub-models remain integral components of the original model, minimizing storage requirements and transition costs between different computational/latency budgets. By applying this approach on LLaMa 2 13B for tuning on the Stanford Alpaca dataset and comparing it to normal tuning and early exit via PandaLM benchmark, we show that Sorted Fine-Tuning can deliver models twice as fast as the original model while maintaining or exceeding performance.
SortedNet, a Place for Every Network and Every Network in its Place: Towards a Generalized Solution for Training Many-in-One Neural Networks
Sep 01, 2023As the size of deep learning models continues to grow, finding optimal models under memory and computation constraints becomes increasingly more important. Although usually the architecture and constituent building blocks of neural networks allow them to be used in a modular way, their training process is not aware of this modularity. Consequently, conventional neural network training lacks the flexibility to adapt the computational load of the model during inference. This paper proposes SortedNet, a generalized and scalable solution to harness the inherent modularity of deep neural networks across various dimensions for efficient dynamic inference. Our training considers a nested architecture for the sub-models with shared parameters and trains them together with the main model in a sorted and probabilistic manner. This sorted training of sub-networks enables us to scale the number of sub-networks to hundreds using a single round of training. We utilize a novel updating scheme during training that combines random sampling of sub-networks with gradient accumulation to improve training efficiency. Furthermore, the sorted nature of our training leads to a search-free sub-network selection at inference time; and the nested architecture of the resulting sub-networks leads to minimal storage requirement and efficient switching between sub-networks at inference. Our general dynamic training approach is demonstrated across various architectures and tasks, including large language models and pre-trained vision models. Experimental results show the efficacy of the proposed approach in achieving efficient sub-networks while outperforming state-of-the-art dynamic training approaches. Our findings demonstrate the feasibility of training up to 160 different sub-models simultaneously, showcasing the extensive scalability of our proposed method while maintaining 96% of the model performance.
On the Transferability of Whisper-based Representations for "In-the-Wild" Cross-Task Downstream Speech Applications
May 23, 2023Large self-supervised pre-trained speech models have achieved remarkable success across various speech-processing tasks. The self-supervised training of these models leads to universal speech representations that can be used for different downstream tasks, ranging from automatic speech recognition (ASR) to speaker identification. Recently, Whisper, a transformer-based model was proposed and trained on large amount of weakly supervised data for ASR; it outperformed several state-of-the-art self-supervised models. Given the superiority of Whisper for ASR, in this paper we explore the transferability of the representation for four other speech tasks in SUPERB benchmark. Moreover, we explore the robustness of Whisper representation for ``in the wild'' tasks where speech is corrupted by environment noise and room reverberation. Experimental results show Whisper achieves promising results across tasks and environmental conditions, thus showing potential for cross-task real-world deployment.
KronA: Parameter Efficient Tuning with Kronecker Adapter
Dec 20, 2022



Fine-tuning a Pre-trained Language Model (PLM) on a specific downstream task has been a well-known paradigm in Natural Language Processing. However, with the ever-growing size of PLMs, training the entire model on several downstream tasks becomes very expensive and resource-hungry. Recently, different Parameter Efficient Tuning (PET) techniques are proposed to improve the efficiency of fine-tuning PLMs. One popular category of PET methods is the low-rank adaptation methods which insert learnable truncated SVD modules into the original model either sequentially or in parallel. However, low-rank decomposition suffers from limited representation power. In this work, we address this problem using the Kronecker product instead of the low-rank representation. We introduce KronA, a Kronecker product-based adapter module for efficient fine-tuning of Transformer-based PLMs. We apply the proposed methods for fine-tuning T5 on the GLUE benchmark to show that incorporating the Kronecker-based modules can outperform state-of-the-art PET methods.
Kronecker Decomposition for GPT Compression
Oct 15, 2021



GPT is an auto-regressive Transformer-based pre-trained language model which has attracted a lot of attention in the natural language processing (NLP) domain due to its state-of-the-art performance in several downstream tasks. The success of GPT is mostly attributed to its pre-training on huge amount of data and its large number of parameters (from ~100M to billions of parameters). Despite the superior performance of GPT (especially in few-shot or zero-shot setup), this overparameterized nature of GPT can be very prohibitive for deploying this model on devices with limited computational power or memory. This problem can be mitigated using model compression techniques; however, compressing GPT models has not been investigated much in the literature. In this work, we use Kronecker decomposition to compress the linear mappings of the GPT-22 model. Our Kronecker GPT-2 model (KnGPT2) is initialized based on the Kronecker decomposed version of the GPT-2 model and then is undergone a very light pre-training on only a small portion of the training data with intermediate layer knowledge distillation (ILKD). Finally, our KnGPT2 is fine-tuned on down-stream tasks using ILKD as well. We evaluate our model on both language modeling and General Language Understanding Evaluation benchmark tasks and show that with more efficient pre-training and similar number of parameters, our KnGPT2 outperforms the existing DistilGPT2 model significantly.
FoCL: Feature-Oriented Continual Learning for Generative Models
Mar 09, 2020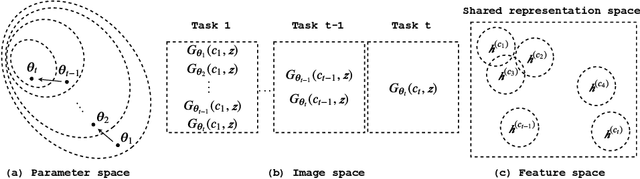



In this paper, we propose a general framework in continual learning for generative models: Feature-oriented Continual Learning (FoCL). Unlike previous works that aim to solve the catastrophic forgetting problem by introducing regularization in the parameter space or image space, FoCL imposes regularization in the feature space. We show in our experiments that FoCL has faster adaptation to distributional changes in sequentially arriving tasks, and achieves the state-of-the-art performance for generative models in task incremental learning. We discuss choices of combined regularization spaces towards different use case scenarios for boosted performance, e.g., tasks that have high variability in the background. Finally, we introduce a forgetfulness measure that fairly evaluates the degree to which a model suffers from forgetting. Interestingly, the analysis of our proposed forgetfulness score also implies that FoCL tends to have a mitigated forgetting for future tasks.