 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much is Brain Data Worth for Machine Learning?
May 10, 2026If a person can solve a task, can measuring their brain make it easier to train a model to solve that task too? Recent NeuroAI work suggests that supplementing task training with neural recordings can modestly improve model performance and robustness. However, it is unclear when there should be a benefit from using neural data and how much benefit to expect. We formulate this question mathematically, and begin to address it theoretically using a simple, analytically tractable linear gaussian model of task targets and neural recordings. For a multimodal estimator trained on both brain data and task labels, we derive scaling laws for how performance scales with the numbers of brain and task samples. From these laws we derive relative value and exchange rates between brain samples and task samples, quantifying how much extra task samples neural data is worth as a function of task-brain alignment, neural and task noise, latent dimension, and brain data sample size. We also analyze test distribution shift, to identify conditions where brain-regularized learning can produce substantial robustness gains through learned invariances. Finally, under a fixed collection budget, we characterize the regimes in which brain data is worth collecting. Our results provide a foundation for understanding how valuable brain data could be for improving machine learning.
Cognitive Models and AI Algorithms Provide Templates for Designing Language Agents
Feb 26, 2026While contemporary large language models (LLMs) are increasingly capable in isolation, there are still many difficult problems that lie beyond the abilities of a single LLM. For such tasks, there is still uncertainty about how best to take many LLMs as parts and combine them into a greater whole. This position paper argues that potential blueprints for designing such modular language agents can be found in the existing literature on cognitive models and artificial intelligence (AI) algorithms. To make this point clear, we formalize the idea of an agent template that specifies roles for individual LLMs and how their functionalities should be composed. We then survey a variety of existing language agents in the literature and highlight their underlying templates derived directly from cognitive models or AI algorithms. By highlighting these designs, we aim to call attention to agent templates inspired by cognitive science and AI as a powerful tool for developing effective, interpretable language agents.
Attention when you need
Jan 13, 2025Being attentive to task-relevant features can improve task performance, but paying attention comes with its own metabolic cost. Therefore, strategic allocation of attention is crucial in performing the task efficiently. This work aims to understand this strategy. Recently, de Gee et al. conducted experiments involving mice performing an auditory sustained attention-value task. This task required the mice to exert attention to identify whether a high-order acoustic feature was present amid the noise. By varying the trial duration and reward magnitude, the task allows us to investigate how an agent should strategically deploy their attention to maximize their benefits and minimize their costs. In our work, we develop a reinforcement learning-based normative model of the mice to understand how it balances attention cost against its benefits. The model is such that at each moment the mice can choose between two levels of attention and decide when to take costly actions that could obtain rewards. Our model suggests that efficient use of attentional resources involves alternating blocks of high attention with blocks of low attention. In the extreme case where the agent disregards sensory input during low attention states, we see that high attention is used rhythmically. Our model provides evidence about how one should deploy attention as a function of task utility, signal statistics, and how attention affects sensory evidence.
How does the brain compute with probabilities?
Sep 01, 2024



This perspective piece is the result of a Generative Adversarial Collaboration (GAC) tackling the question `How does neural activity represent probability distributions?'. We have addressed three major obstacles to progress on answering this question: first, we provide a unified language for defining competing hypotheses. Second, we explain the fundamentals of three prominent proposals for probabilistic computations -- Probabilistic Population Codes (PPCs), Distributed Distributional Codes (DDCs), and Neural Sampling Codes (NSCs) -- and describe similarities and differences in that common language. Third, we review key empirical data previously taken as evidence for at least one of these proposal, and describe how it may or may not be explainable by alternative proposals. Finally, we describe some key challenges in resolving the debate, and propose potential directions to address them through a combination of theory and experiments.
Control when confidence is costly
Jun 20, 2024



We develop a version of stochastic control that accounts for computational costs of inference. Past studies identified efficient coding without control, or efficient control that neglects the cost of synthesizing information. Here we combine these concepts into a framework where agents rationally approximate inference for efficient control. Specifically, we study Linear Quadratic Gaussian (LQG) control with an added internal cost on the relative precision of the posterior probability over the world state. This creates a trade-off: an agent can obtain more utility overall by sacrificing some task performance, if doing so saves enough bits during inference. We discover that the rational strategy that solves the joint inference and control problem goes through phase transitions depending on the task demands, switching from a costly but optimal inference to a family of suboptimal inferences related by rotation transformations, each misestimate the stability of the world. In all cases, the agent moves more to think less. This work provides a foundation for a new type of rational computations that could be used by both brains and machines for efficient but computationally constrained control.
Generalization properties of contrastive world models
Dec 29, 2023



Recent work on object-centric world models aim to factorize representations in terms of objects in a completely unsupervised or self-supervised manner. Such world models are hypothesized to be a key component to address the generalization problem. While self-supervision has shown improved performance however, OOD generalization has not been systematically and explicitly tested. In this paper, we conduct an extensive study on the generalization properties of contrastive world model. We systematically test the model under a number of different OOD generalization scenarios such as extrapolation to new object attributes, introducing new conjunctions or new attributes. Our experiments show that the contrastive world model fails to generalize under the different OOD tests and the drop in performance depends on the extent to which the samples are OOD. When visualizing the transition updates and convolutional feature maps, we observe that any changes in object attributes (such as previously unseen colors, shapes, or conjunctions of color and shape) breaks down the factorization of object representations. Overall, our work highlights the importance of object-centric representations for generalization and current models are limited in their capacity to learn such representations required for human-level generalization.
Inferring Inference
Oct 13, 2023Patterns of microcircuitry suggest that the brain has an array of repeated canonical computational units. Yet neural representations are distributed, so the relevant computations may only be related indirectly to single-neuron transformations. It thus remains an open challenge how to define canonical distributed computations. We integrate normative and algorithmic theories of neural computation into a mathematical framework for inferring canonical distributed computations from large-scale neural activity patterns. At the normative level, we hypothesize that the brain creates a structured internal model of its environment, positing latent causes that explain its sensory inputs, and uses those sensory inputs to infer the latent causes. At the algorithmic level, we propose that this inference process is a nonlinear message-passing algorithm on a graph-structured model of the world. Given a time series of neural activity during a perceptual inference task, our framework finds (i) the neural representation of relevant latent variables, (ii) interactions between these variables that define the brain's internal model of the world, and (iii) message-functions specifying the inference algorithm. These targeted computational properties are then statistically distinguishable due to the symmetries inherent in any canonical computation, up to a global transformation. As a demonstration, we simulate recordings for a model brain that implicitly implements an approximate inference algorithm on a probabilistic graphical model. Given its external inputs and noisy neural activity, we recover the latent variables, their neural representation and dynamics, and canonical message-functions. We highlight features of experimental design needed to successfully extract canonical computations from neural data. Overall, this framework provides a new tool for discovering interpretable structure in neural recordings.
Understanding robustness and generalization of artificial neural networks through Fourier masks
Mar 16, 2022

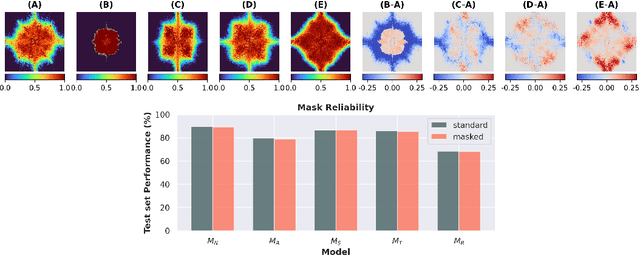
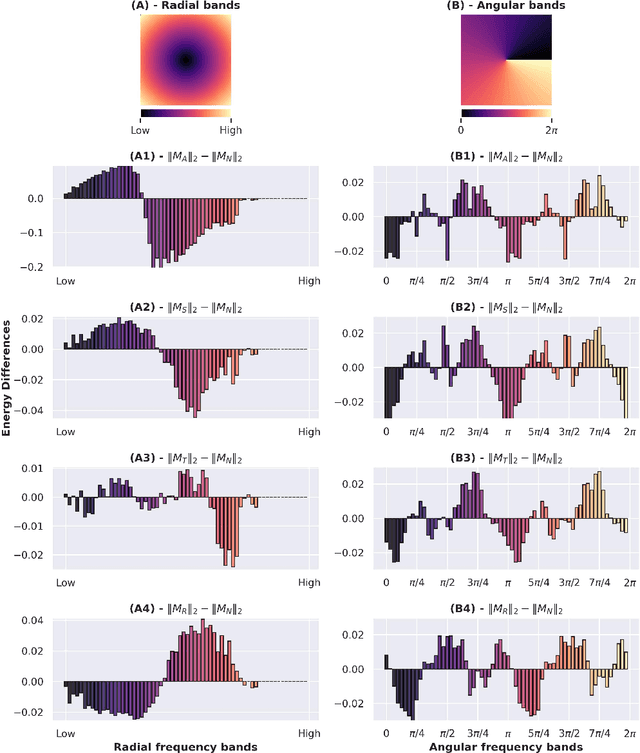
Despite the enormous success of artificial neural networks (ANNs) in many disciplines, the characterization of their computations and the origin of key properties such as generalization and robustness remain open questions. Recent literature suggests that robust networks with good generalization properties tend to be biased towards processing low frequencies in images. To explore the frequency bias hypothesis further, we develop an algorithm that allows us to learn modulatory masks highlighting the essential input frequencies needed for preserving a trained network's performance. We achieve this by imposing invariance in the loss with respect to such modulations in the input frequencies. We first use our method to test the low-frequency preference hypothesis of adversarially trained or data-augmented networks. Our results suggest that adversarially robust networks indeed exhibit a low-frequency bias but we find this bias is also dependent on directions in frequency space. However, this is not necessarily true for other types of data augmentation. Our results also indicate that the essential frequencies in question are effectively the ones used to achieve generalization in the first place. Surprisingly, images seen through these modulatory masks are not recognizable and resemble texture-like patterns.
Learning Dynamics and Structure of Complex Systems Using Graph Neural Networks
Feb 22, 2022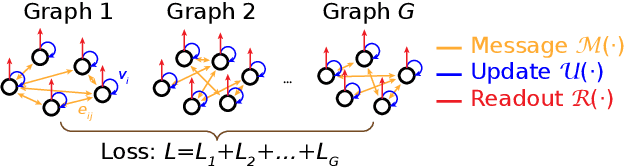
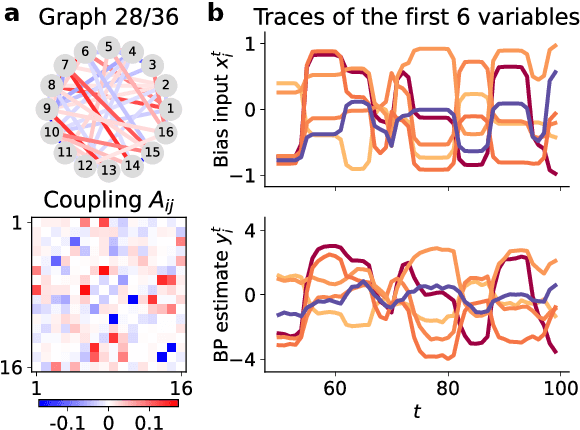
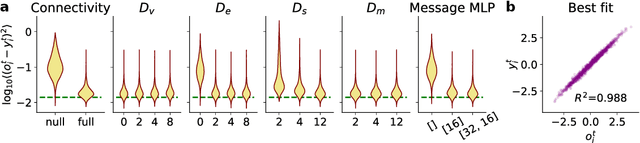
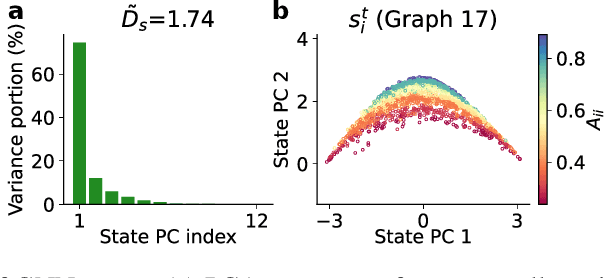
Many complex systems are composed of interacting parts, and the underlying laws are usually simple and universal. While graph neural networks provide a useful relational inductive bias for modeling such systems, generalization to new system instances of the same type is less studied. In this work we trained graph neural networks to fit time series from an example nonlinear dynamical system, the belief propagation algorithm. We found simple interpretations of the learned representation and model components, and they are consistent with core properties of the probabilistic inference algorithm. We successfully identified a `graph translator' between the statistical interactions in belief propagation and parameters of the corresponding trained network, and showed that it enables two types of novel generalization: to recover the underlying structure of a new system instance based solely on time series observations, or to construct a new network from this structure directly. Our results demonstrated a path towards understanding both dynamics and structure of a complex system and how such understanding can be used for generalization.
Interpolating between sampling and variational inference with infinite stochastic mixtures
Oct 18, 2021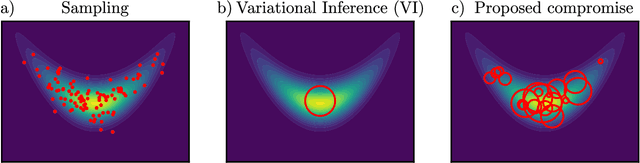
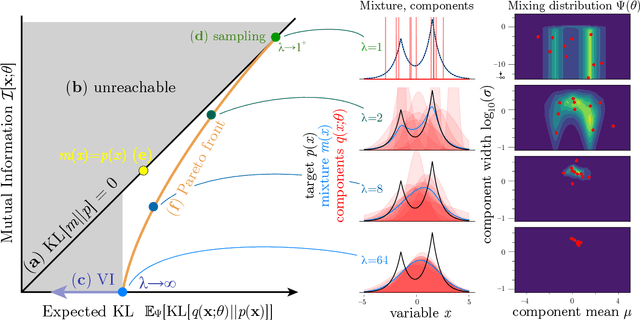
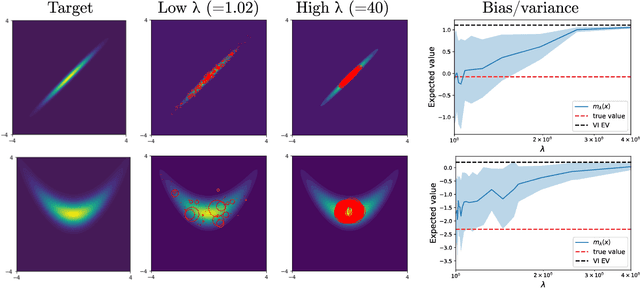
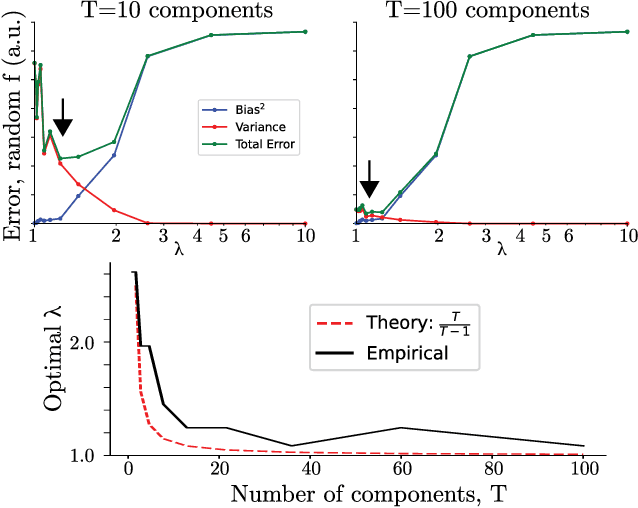
Sampling and Variational Inference (VI) are two large families of methods for approximate inference with complementary strengths. Sampling methods excel at approximating arbitrary probability distributions, but can be inefficient. VI methods are efficient, but can fail when probability distributions are complex. Here, we develop a framework for constructing intermediate algorithms that balance the strengths of both sampling and VI. Both approximate a probability distribution using a mixture of simple component distributions: in sampling, each component is a delta-function and is chosen stochastically, while in standard VI a single component is chosen to minimize divergence. We show that sampling and VI emerge as special cases of an optimization problem over a mixing distribution, and intermediate approximations arise by varying a single parameter. We then derive closed-form sampling dynamics over variational parameters that stochastically build a mixture. Finally, we discuss how to select the optimal compromise between sampling and VI given a computational budget. This work is a first step towards a highly flexible yet simple family of inference methods that combines the complementary strengths of sampling and VI.