 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvaTr: One-Shot Speaker Extraction with Transformers
May 03, 2021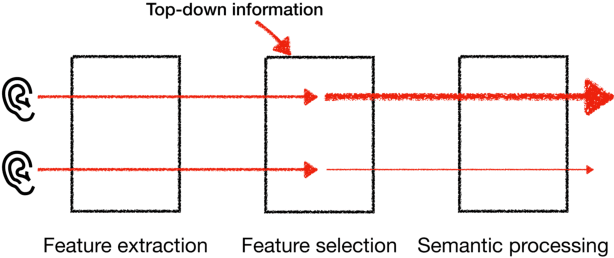

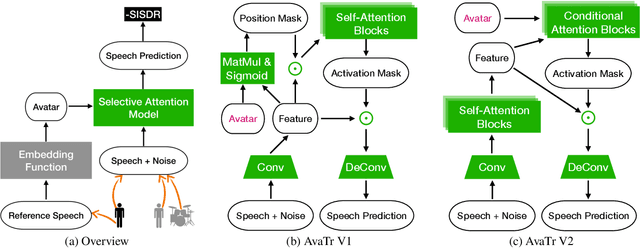
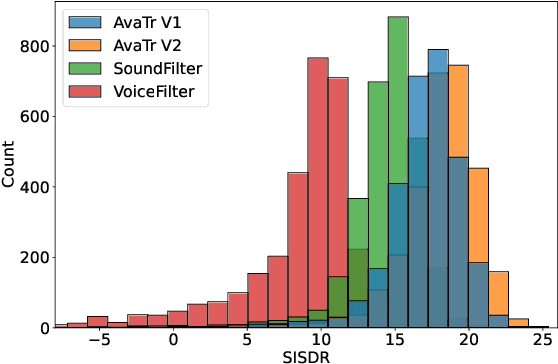
To extract the voice of a target speaker when mixed with a variety of other sounds, such as white and ambient noises or the voices of interfering speakers, we extend the Transformer network to attend the most relevant information with respect to the target speaker given the characteristics of his or her voices as a form of contextual information. The idea has a natural interpretation in terms of the selective attention theory. Specifically, we propose two models to incorporate the voice characteristics in Transformer based on different insights of where the feature selection should take place. Both models yield excellent performance, on par or better than published state-of-the-art models on the speaker extraction task, including separating speech of novel speakers not seen during training.
Deep Variational Generative Models for Audio-visual Speech Separation
Aug 17, 2020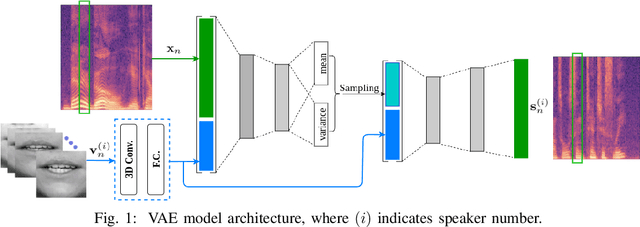
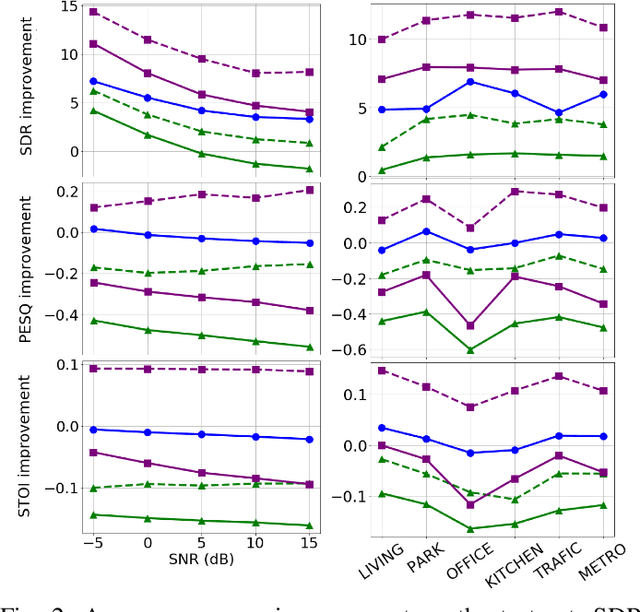
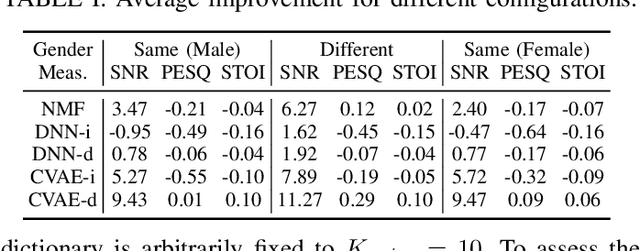
In this paper, we are interested in audio-visual speech separation given a single-channel audio recording as well as visual information (lips movements) associated with each speaker. We propose an unsupervised technique based on audio-visual generative modeling of clean speech. More specifically, during training, a latent variable generative model is learned from clean speech spectrograms using a variational auto-encoder (VAE). To better utilize the visual information, the posteriors of the latent variables are inferred from mixed speech (instead of clean speech) as well as the visual data. The visual modality also serves as a prior for latent variables, through a visual network. At test time, the learned generative model (both for speaker-independent and speaker-dependent scenarios) is combined with an unsupervised non-negative matrix factorization (NMF) variance model for background noise. All the latent variables and noise parameters are then estimated by a Monte Carlo expectation-maximization algorithm. Our experiments show that the proposed unsupervised VAE-based method yields better separation performance than NMF-based approaches as well as a supervised deep learning-based technique.
Instance-Based Model Adaptation For Direct Speech Translation
Oct 23, 2019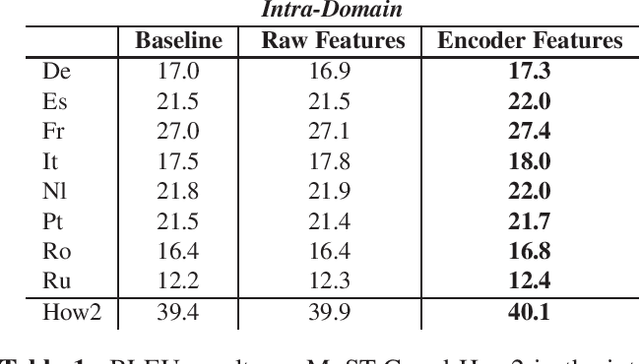
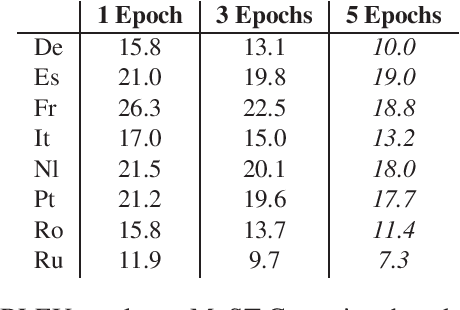
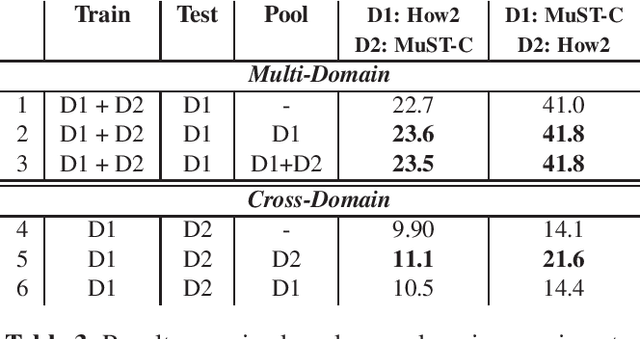
Despite recent technology advancements, the effectiveness of neural approaches to end-to-end speech-to-text translation is still limited by the paucity of publicly available training corpora. We tackle this limitation with a method to improve data exploitation and boost the system's performance at inference time. Our approach allows us to customize "on the fly" an existing model to each incoming translation request. At its core, it exploits an instance selection procedure to retrieve, from a given pool of data, a small set of samples similar to the input query in terms of latent properties of its audio signal. The retrieved samples are then used for an instance-specific fine-tuning of the model. We evaluate our approach in three different scenarios. In all data conditions (different languages, in/out-of-domain adaptation), our instance-based adaptation yields coherent performance gains over static models.