 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022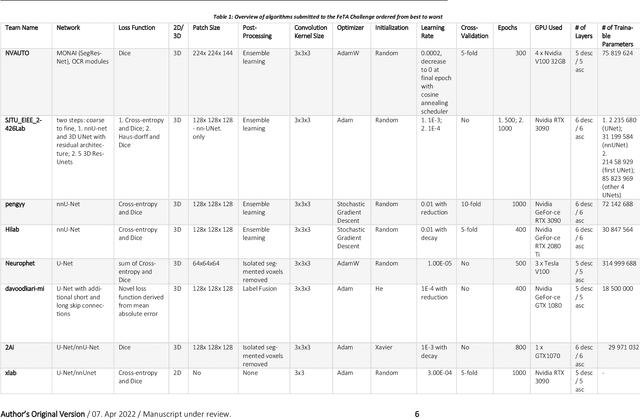
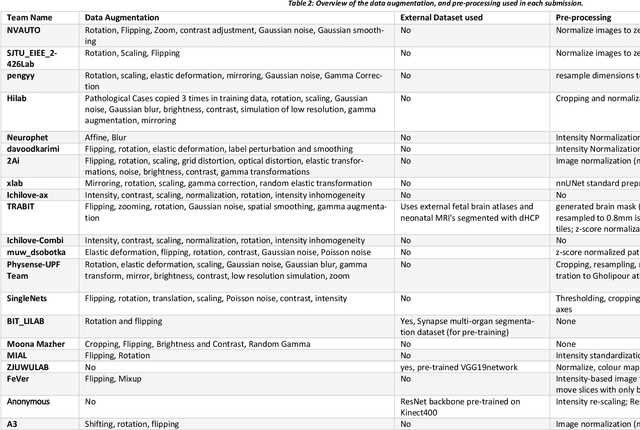
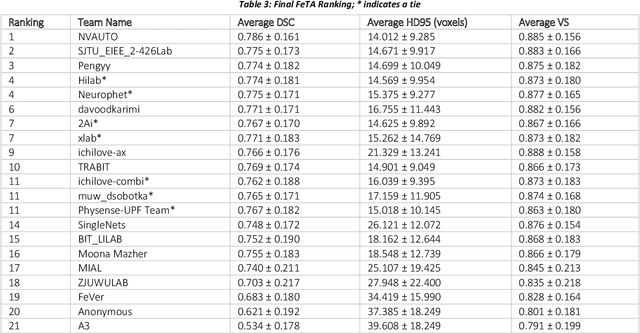
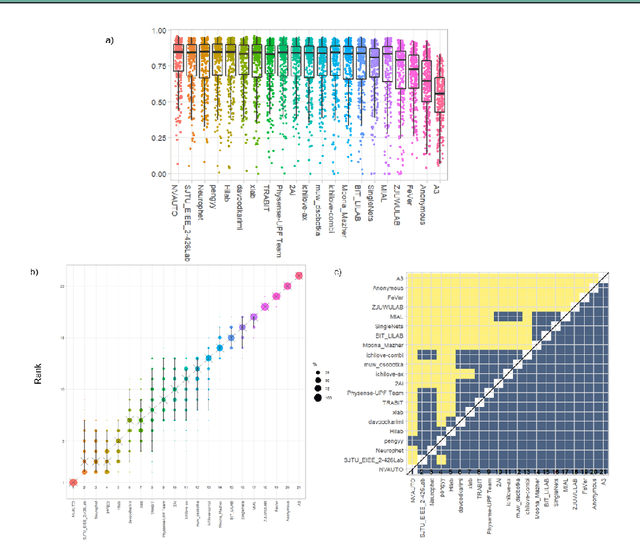
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.
HyperSegNAS: Bridging One-Shot Neural Architecture Search with 3D Medical Image Segmentation using HyperNet
Dec 20, 2021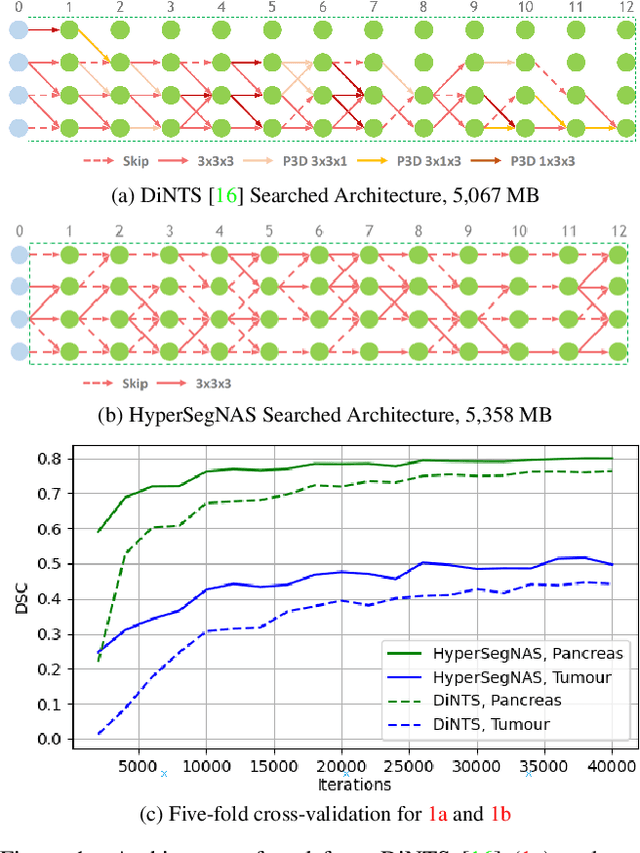
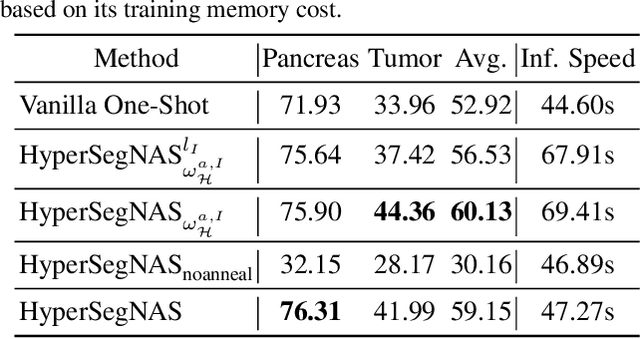
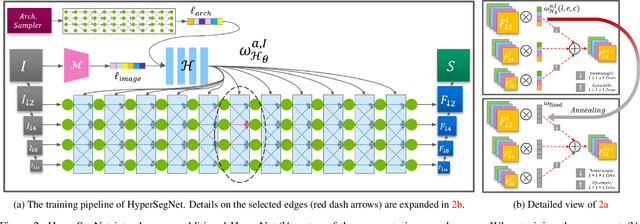
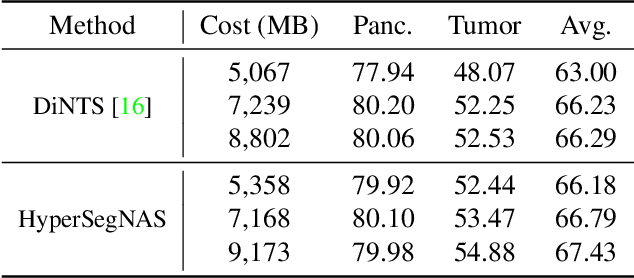
Semantic segmentation of 3D medical images is a challenging task due to the high variability of the shape and pattern of objects (such as organs or tumors). Given the recent success of deep learning in medical image segmentation, Neural Architecture Search (NAS) has been introduced to find high-performance 3D segmentation network architectures. However, because of the massive computational requirements of 3D data and the discrete optimization nature of architecture search, previous NAS methods require a long search time or necessary continuous relaxation, and commonly lead to sub-optimal network architectures. While one-shot NAS can potentially address these disadvantages, its application in the segmentation domain has not been well studied in the expansive multi-scale multi-path search space. To enable one-shot NAS for medical image segmentation, our method, named HyperSegNAS, introduces a HyperNet to assist super-net training by incorporating architecture topology information. Such a HyperNet can be removed once the super-net is trained and introduces no overhead during architecture search. We show that HyperSegNAS yields better performing and more intuitive architectures compared to the previous state-of-the-art (SOTA) segmentation networks; furthermore, it can quickly and accurately find good architecture candidates under different computing constraints. Our method is evaluated on public datasets from the Medical Segmentation Decathlon (MSD) challenge, and achieves SOTA performances.
Redundancy Reduction in Semantic Segmentation of 3D Brain Tumor MRIs
Nov 01, 2021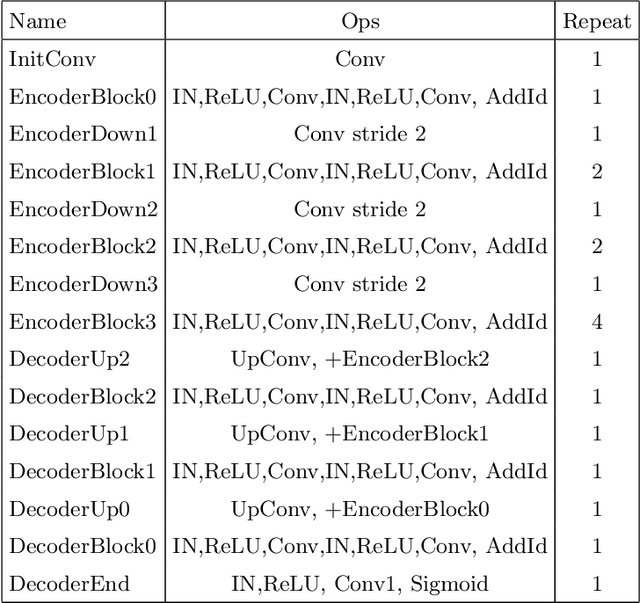
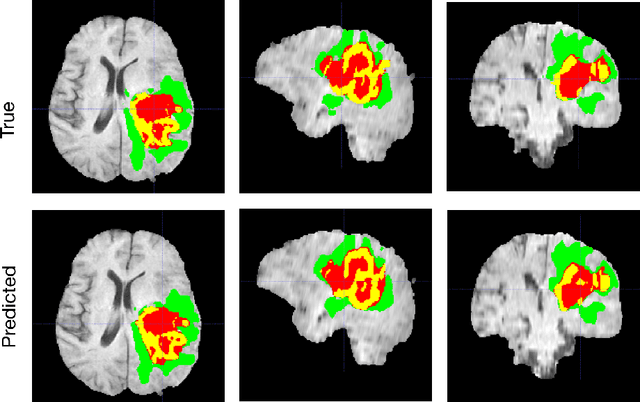
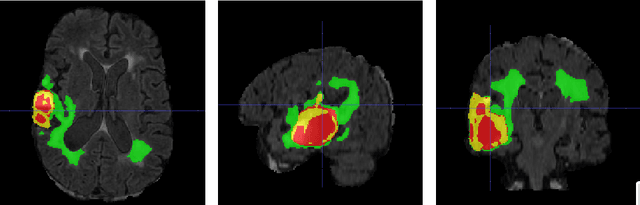
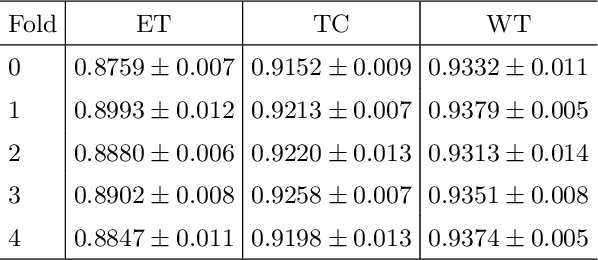
Another year of the multimodal brain tumor segmentation challenge (BraTS) 2021 provides an even larger dataset to facilitate collaboration and research of brain tumor segmentation methods, which are necessary for disease analysis and treatment planning. A large dataset size of BraTS 2021 and the advent of modern GPUs provide a better opportunity for deep-learning based approaches to learn tumor representation from the data. In this work, we maintained an encoder-decoder based segmentation network, but focused on a modification of network training process that minimizes redundancy under perturbations. Given a set trained networks, we further introduce a confidence based ensembling techniques to further improve the performance. We evaluated the method on BraTS 2021 validation board, and achieved 0.8600, 0.8868 and 0.9265 average dice for enhanced tumor core, tumor core and whole tumor, respectively. Our team (NVAUTO) submission was the top performing in terms of ET and TC scores and within top 10 performing teams in terms of WT scores.
UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation
Jan 28, 2020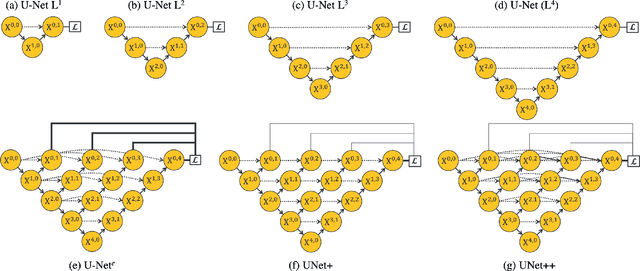

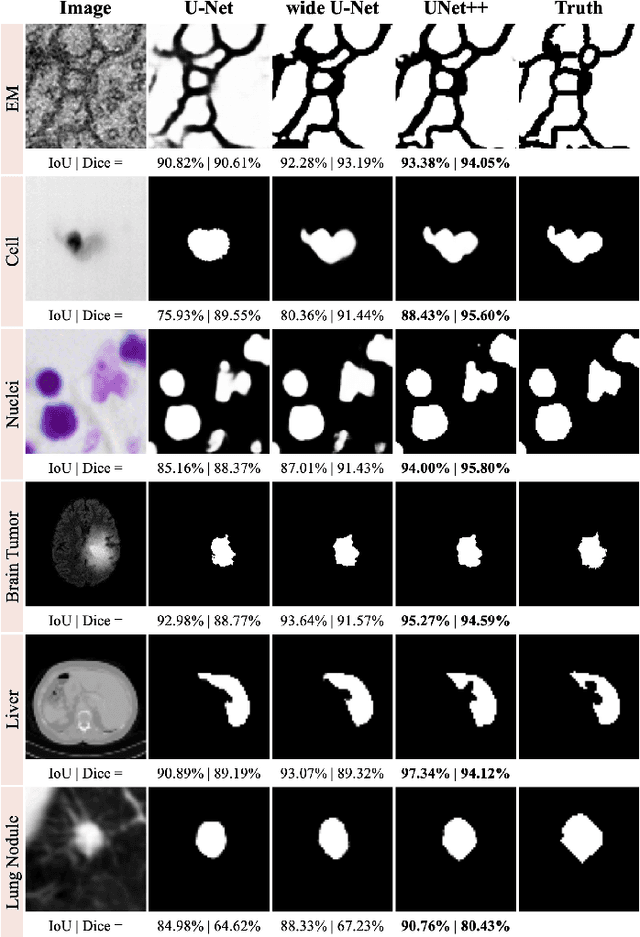
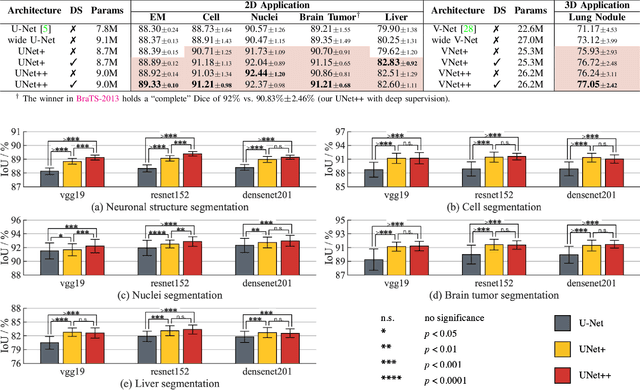
The state-of-the-art models for medical image segmentation are variants of U-Net and fully convolutional networks (FCN). Despite their success, these models have two limitations: (1) their optimal depth is apriori unknown, requiring extensive architecture search or inefficient ensemble of models of varying depths; and (2) their skip connections impose an unnecessarily restrictive fusion scheme, forcing aggregation only at the same-scale feature maps of the encoder and decoder sub-networks. To overcome these two limitations, we propose UNet++, a new neural architecture for semantic and instance segmentation, by (1) alleviating the unknown network depth with an efficient ensemble of U-Nets of varying depths, which partially share an encoder and co-learn simultaneously using deep supervision; (2) redesigning skip connections to aggregate features of varying semantic scales at the decoder sub-networks, leading to a highly flexible feature fusion scheme; and (3) devising a pruning scheme to accelerate the inference speed of UNet++. We have evaluated UNet++ using six different medical image segmentation datasets, covering multiple imaging modalities such as computed tomography (CT), magnetic resonance imaging (MRI), and electron microscopy (EM), and demonstrating that (1) UNet++ consistently outperforms the baseline models for the task of semantic segmentation across different datasets and backbone architectures; (2) UNet++ enhances segmentation quality of varying-size objects -- an improvement over the fixed-depth U-Net; (3) Mask RCNN++ (Mask R-CNN with UNet++ design) outperforms the original Mask R-CNN for the task of instance segmentation; and (4) pruned UNet++ models achieve significant speedup while showing only modest performance degradation. Our implementation and pre-trained models are available at https://github.com/MrGiovanni/UNetPlusPlus.
Learning Fixed Points in Generative Adversarial Networks: From Image-to-Image Translation to Disease Detection and Localization
Aug 29, 2019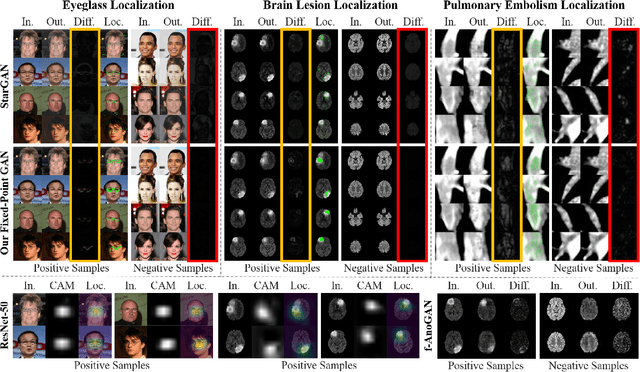

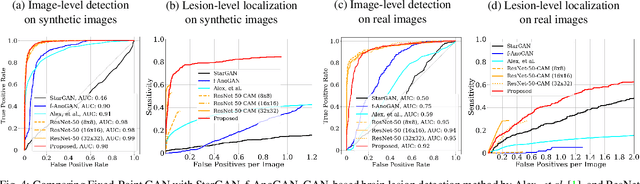
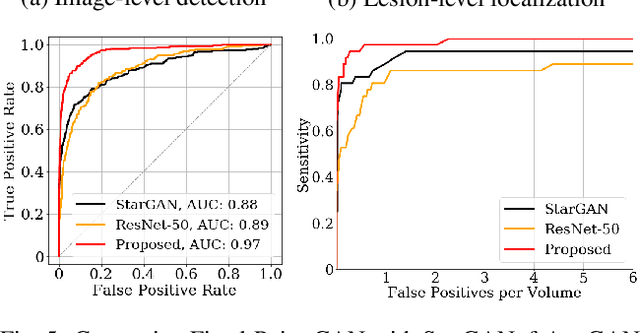
Generative adversarial networks (GANs) have ushered in a revolution in image-to-image translation. The development and proliferation of GANs raises an interesting question: can we train a GAN to remove an object, if present, from an image while otherwise preserving the image? Specifically, can a GAN "virtually heal" anyone by turning his medical image, with an unknown health status (diseased or healthy), into a healthy one, so that diseased regions could be revealed by subtracting those two images? Such a task requires a GAN to identify a minimal subset of target pixels for domain translation, an ability that we call fixed-point translation, which no GAN is equipped with yet. Therefore, we propose a new GAN, called Fixed-Point GAN, trained by (1) supervising same-domain translation through a conditional identity loss, and (2) regularizing cross-domain translation through revised adversarial, domain classification, and cycle consistency loss. Based on fixed-point translation, we further derive a novel framework for disease detection and localization using only image-level annotation. Qualitative and quantitative evaluations demonstrate that the proposed method outperforms the state of the art in multi-domain image-to-image translation and that it surpasses predominant weakly-supervised localization methods in both disease detection and localization. Implementation is available at https://github.com/jlianglab/Fixed-Point-GAN.
Models Genesis: Generic Autodidactic Models for 3D Medical Image Analysis
Aug 19, 2019
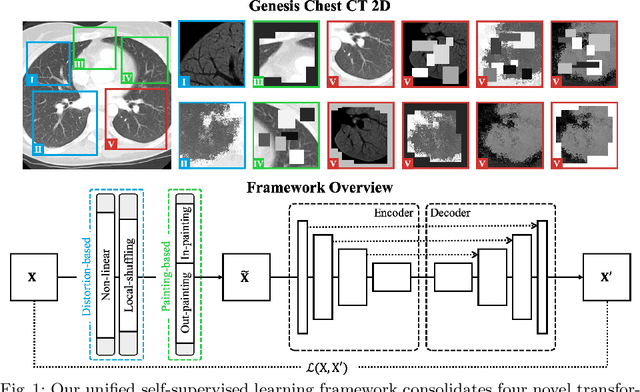
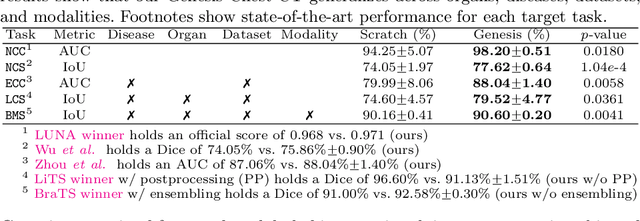
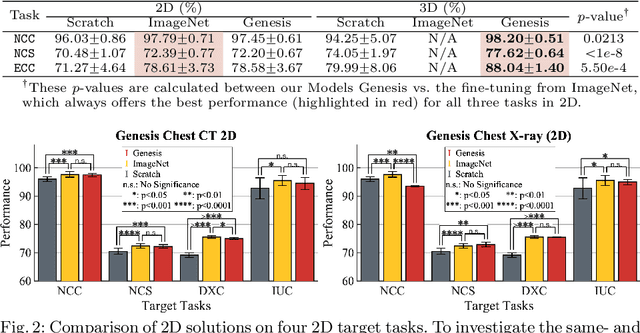
Transfer learning from natural image to medical image has established as one of the most practical paradigms in deep learning for medical image analysis. However, to fit this paradigm, 3D imaging tasks in the most prominent imaging modalities (e.g., CT and MRI) have to be reformulated and solved in 2D, losing rich 3D anatomical information and inevitably compromising the performance. To overcome this limitation, we have built a set of models, called Generic Autodidactic Models, nicknamed Models Genesis, because they are created ex nihilo (with no manual labeling), self-taught (learned by self-supervision), and generic (served as source models for generating application-specific target models). Our extensive experiments demonstrate that our Models Genesis significantly outperform learning from scratch in all five target 3D applications covering both segmentation and classification. More importantly, learning a model from scratch simply in 3D may not necessarily yield performance better than transfer learning from ImageNet in 2D, but our Models Genesis consistently top any 2D approaches including fine-tuning the models pre-trained from ImageNet as well as fine-tuning the 2D versions of our Models Genesis, confirming the importance of 3D anatomical information and significance of our Models Genesis for 3D medical imaging. This performance is attributed to our unified self-supervised learning framework, built on a simple yet powerful observation: the sophisticated yet recurrent anatomy in medical images can serve as strong supervision signals for deep models to learn common anatomical representation automatically via self-supervision. As open science, all pre-trained Models Genesis are available at https://github.com/MrGiovanni/ModelsGenesis.
UNet++: A Nested U-Net Architecture for Medical Image Segmentation
Jul 18, 2018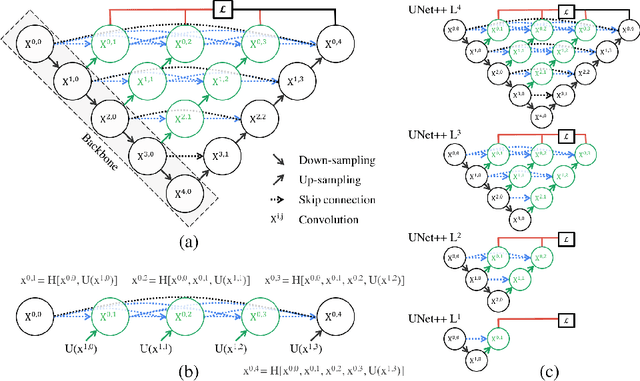
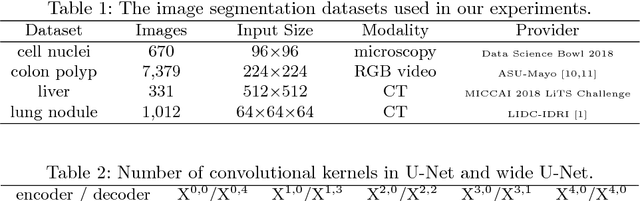

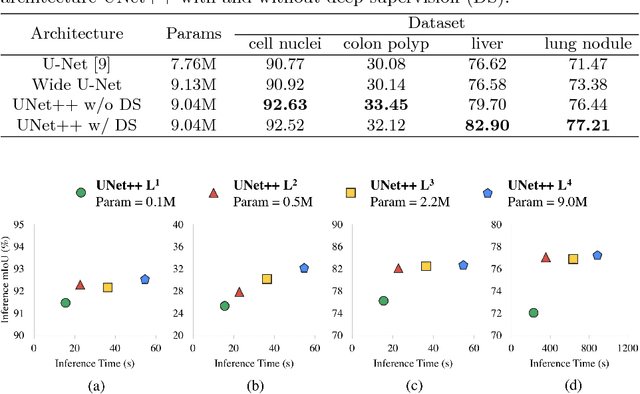
In this paper, we present UNet++, a new, more powerful architecture for medical image segmentation. Our architecture is essentially a deeply-supervised encoder-decoder network where the encoder and decoder sub-networks are connected through a series of nested, dense skip pathways. The re-designed skip pathways aim at reducing the semantic gap between the feature maps of the encoder and decoder sub-networks. We argue that the optimizer would deal with an easier learning task when the feature maps from the decoder and encoder networks are semantically similar. We have evaluated UNet++ in comparison with U-Net and wide U-Net architectures across multiple medical image segmentation tasks: nodule segmentation in the low-dose CT scans of chest, nuclei segmentation in the microscopy images, liver segmentation in abdominal CT scans, and polyp segmentation in colonoscopy videos. Our experiments demonstrate that UNet++ with deep supervision achieves an average IoU gain of 3.9 and 3.4 points over U-Net and wide U-Net, respectively.