 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodness of fit by Neyman-Pearson testing
May 23, 2023



The Neyman-Pearson strategy for hypothesis testing can be employed for goodness of fit if the alternative hypothesis $\rm H_1$ is generic enough not to introduce a significant bias while at the same time avoiding overfitting. A practical implementation of this idea (dubbed NPLM) has been developed in the context of high energy physics, targeting the detection in collider data of new physical effects not foreseen by the Standard Model. In this paper we initiate a comparison of this methodology with other approaches to goodness of fit, and in particular with classifier-based strategies that share strong similarities with NPLM. NPLM emerges from our comparison as more sensitive to small departures of the data from the expected distribution and not biased towards detecting specific types of anomalies while being blind to others. These features make it more suited for agnostic searches for new physics at collider experiments. Its deployment in other contexts should be investigated.
Symbolic Regression on FPGAs for Fast Machine Learning Inference
May 06, 2023



The high-energy physics community is investigating the feasibility of deploying machine-learning-based solutions on Field-Programmable Gate Arrays (FPGAs) to improve physics sensitivity while meeting data processing latency limitations. In this contribution, we introduce a novel end-to-end procedure that utilizes a machine learning technique called symbolic regression (SR). It searches equation space to discover algebraic relations approximating a dataset. We use PySR (software for uncovering these expressions based on evolutionary algorithm) and extend the functionality of hls4ml (a package for machine learning inference in FPGAs) to support PySR-generated expressions for resource-constrained production environments. Deep learning models often optimise the top metric by pinning the network size because vast hyperparameter space prevents extensive neural architecture search. Conversely, SR selects a set of models on the Pareto front, which allows for optimising the performance-resource tradeoff directly. By embedding symbolic forms, our implementation can dramatically reduce the computational resources needed to perform critical tasks. We validate our procedure on a physics benchmark: multiclass classification of jets produced in simulated proton-proton collisions at the CERN Large Hadron Collider, and show that we approximate a 3-layer neural network with an inference model that has as low as 5 ns execution time (a reduction by a factor of 13) and over 90% approximation accuracy.
Progress towards an improved particle flow algorithm at CMS with machine learning
Mar 30, 2023



The particle-flow (PF) algorithm, which infers particles based on tracks and calorimeter clusters, is of central importance to event reconstruction in the CMS experiment at the CERN LHC, and has been a focus of development in light of planned Phase-2 running conditions with an increased pileup and detector granularity. In recent years, the machine learned particle-flow (MLPF) algorithm, a graph neural network that performs PF reconstruction, has been explored in CMS, with the possible advantages of directly optimizing for the physical quantities of interest, being highly reconfigurable to new conditions, and being a natural fit for deployment to heterogeneous accelerators. We discuss progress in CMS towards an improved implementation of the MLPF reconstruction, now optimized using generator/simulation-level particle information as the target for the first time. This paves the way to potentially improving the detector response in terms of physical quantities of interest. We describe the simulation-based training target, progress and studies on event-based loss terms, details on the model hyperparameter tuning, as well as physics validation with respect to the current PF algorithm in terms of high-level physical quantities such as the jet and missing transverse momentum resolutions. We find that the MLPF algorithm, trained on a generator/simulator level particle information for the first time, results in broadly compatible particle and jet reconstruction performance with the baseline PF, setting the stage for improving the physics performance by additional training statistics and model tuning.
* 7 pages, 4 Figures, 1 Table
Towards Optimal Compression: Joint Pruning and Quantization
Feb 15, 2023



Compression of deep neural networks has become a necessary stage for optimizing model inference on resource-constrained hardware. This paper presents FITCompress, a method for unifying layer-wise mixed precision quantization and pruning under a single heuristic, as an alternative to neural architecture search and Bayesian-based techniques. FITCompress combines the Fisher Information Metric, and path planning through compression space, to pick optimal configurations given size and operation constraints with single-shot fine-tuning. Experiments on ImageNet validate the method and show that our approach yields a better trade-off between accuracy and efficiency when compared to the baselines. Besides computer vision benchmarks, we experiment with the BERT model on a language understanding task, paving the way towards its optimal compression.
Unravelling physics beyond the standard model with classical and quantum anomaly detection
Jan 27, 2023Much hope for finding new physics phenomena at microscopic scale relies on the observations obtained from High Energy Physics experiments, like the ones performed at the Large Hadron Collider (LHC). However, current experiments do not indicate clear signs of new physics that could guide the development of additional Beyond Standard Model (BSM) theories. Identifying signatures of new physics out of the enormous amount of data produced at the LHC falls into the class of anomaly detection and constitutes one of the greatest computational challenges. In this article, we propose a novel strategy to perform anomaly detection in a supervised learning setting, based on the artificial creation of anomalies through a random process. For the resulting supervised learning problem, we successfully apply classical and quantum Support Vector Classifiers (CSVC and QSVC respectively) to identify the artificial anomalies among the SM events. Even more promising, we find that employing an SVC trained to identify the artificial anomalies, it is possible to identify realistic BSM events with high accuracy. In parallel, we also explore the potential of quantum algorithms for improving the classification accuracy and provide plausible conditions for the best exploitation of this novel computational paradigm.
Quantum anomaly detection in the latent space of proton collision events at the LHC
Jan 25, 2023We propose a new strategy for anomaly detection at the LHC based on unsupervised quantum machine learning algorithms. To accommodate the constraints on the problem size dictated by the limitations of current quantum hardware we develop a classical convolutional autoencoder. The designed quantum anomaly detection models, namely an unsupervised kernel machine and two clustering algorithms, are trained to find new-physics events in the latent representation of LHC data produced by the autoencoder. The performance of the quantum algorithms is benchmarked against classical counterparts on different new-physics scenarios and its dependence on the dimensionality of the latent space and the size of the training dataset is studied. For kernel-based anomaly detection, we identify a regime where the quantum model significantly outperforms its classical counterpart. An instance of the kernel machine is implemented on a quantum computer to verify its suitability for available hardware. We demonstrate that the observed consistent performance advantage is related to the inherent quantum properties of the circuit used.
On the Evaluation of Generative Models in High Energy Physics
Nov 18, 2022



There has been a recent explosion in research into machine-learning-based generative modeling to tackle computational challenges for simulations in high energy physics (HEP). In order to use such alternative simulators in practice, we need well defined metrics to compare different generative models and evaluate their discrepancy from the true distributions. We present the first systematic review and investigation into evaluation metrics and their sensitivity to failure modes of generative models, using the framework of two-sample goodness-of-fit testing, and their relevance and viability for HEP. Inspired by previous work in both physics and computer vision, we propose two new metrics, the Fr\'echet and kernel physics distances (FPD and KPD), and perform a variety of experiments measuring their performance on simple Gaussian-distributed, and simulated high energy jet datasets. We find FPD, in particular, to be the most sensitive metric to all alternative jet distributions tested and recommend its adoption, along with the KPD and Wasserstein distances between individual feature distributions, for evaluating generative models in HEP. We finally demonstrate the efficacy of these proposed metrics in evaluating and comparing a novel attention-based generative adversarial particle transformer to the state-of-the-art message-passing generative adversarial network jet simulation model.
FIT: A Metric for Model Sensitivity
Oct 16, 2022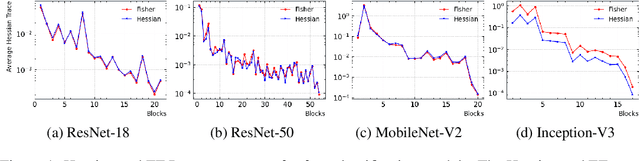

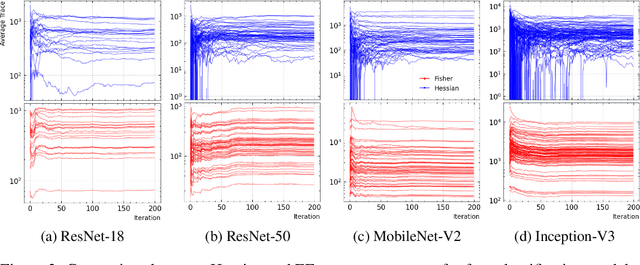
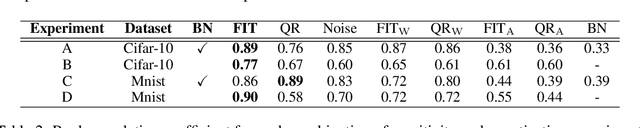
Model compression is vital to the deployment of deep learning on edge devices. Low precision representations, achieved via quantization of weights and activations, can reduce inference time and memory requirements. However, quantifying and predicting the response of a model to the changes associated with this procedure remains challenging. This response is non-linear and heterogeneous throughout the network. Understanding which groups of parameters and activations are more sensitive to quantization than others is a critical stage in maximizing efficiency. For this purpose, we propose FIT. Motivated by an information geometric perspective, FIT combines the Fisher information with a model of quantization. We find that FIT can estimate the final performance of a network without retraining. FIT effectively fuses contributions from both parameter and activation quantization into a single metric. Additionally, FIT is fast to compute when compared to existing methods, demonstrating favourable convergence properties. These properties are validated experimentally across hundreds of quantization configurations, with a focus on layer-wise mixed-precision quantization.
LL-GNN: Low Latency Graph Neural Networks on FPGAs for Particle Detectors
Oct 11, 2022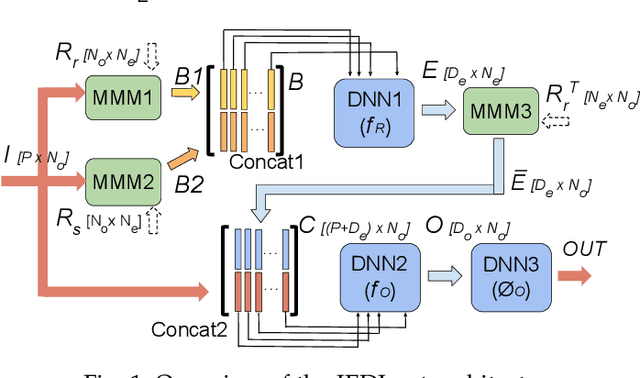
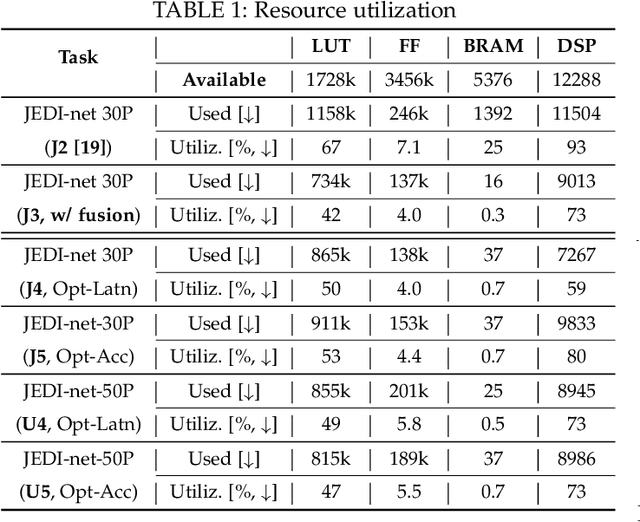
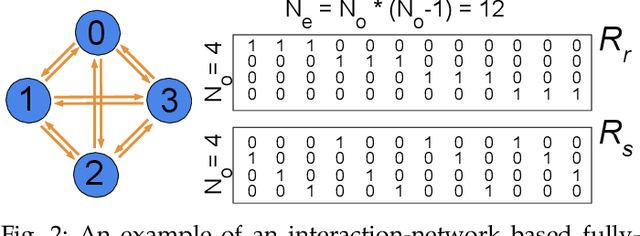
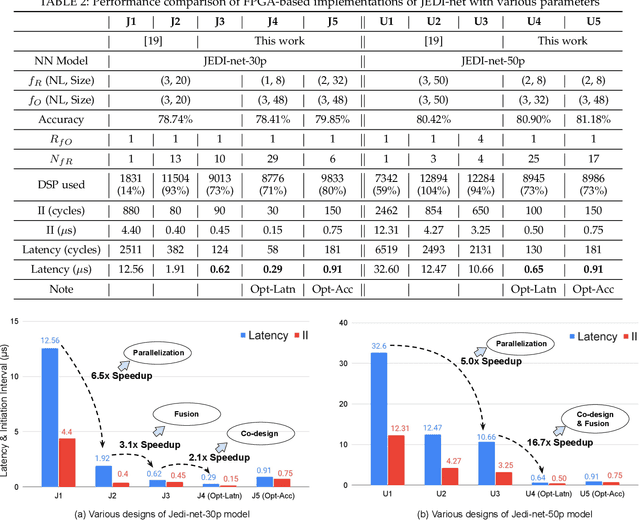
This work proposes a novel reconfigurable architecture for low latency Graph Neural Network (GNN) design specifically for particle detectors. Adopting FPGA-based GNNs for particle detectors is challenging since it requires sub-microsecond latency to deploy the networks for online event selection in the Level-1 triggers for the CERN Large Hadron Collider experiments. This paper proposes a custom code transformation with strength reduction for the matrix multiplication operations in the interaction-network based GNNs with fully connected graphs, which avoids the costly multiplication. It exploits sparsity patterns as well as binary adjacency matrices, and avoids irregular memory access, leading to a reduction in latency and improvement in hardware efficiency. In addition, we introduce an outer-product based matrix multiplication approach which is enhanced by the strength reduction for low latency design. Also, a fusion step is introduced to further reduce the design latency. Furthermore, an GNN-specific algorithm-hardware co-design approach is presented which not only finds a design with a much better latency but also finds a high accuracy design under a given latency constraint. Finally, a customizable template for this low latency GNN hardware architecture has been designed and open-sourced, which enables the generation of low-latency FPGA designs with efficient resource utilization using a high-level synthesis tool. Evaluation results show that our FPGA implementation is up to 24 times faster and consumes up to 45 times less power than a GPU implementation. Compared to our previous FPGA implementations, this work achieves 6.51 to 16.7 times lower latency. Moreover, the latency of our FPGA design is sufficiently low to enable deployment of GNNs in a sub-microsecond, real-time collider trigger system, enabling it to benefit from improved accuracy.
Real-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml
May 16, 2022

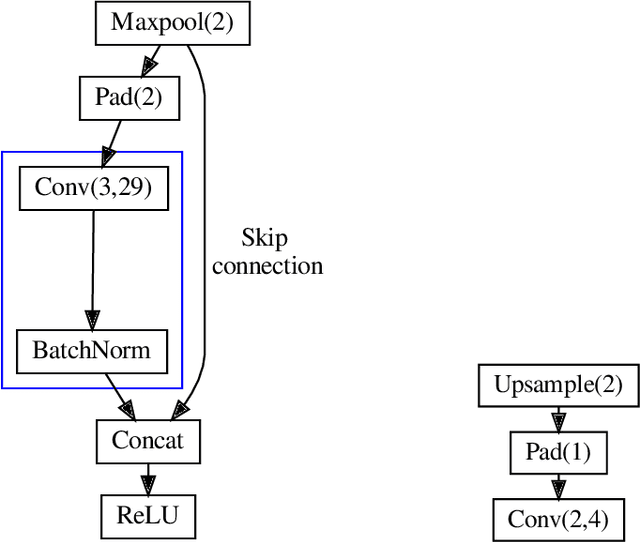
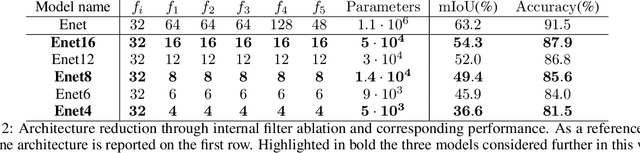
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.