 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification and Resource-Demanding Computer Vision Applications of Deep Learning
May 30, 2022
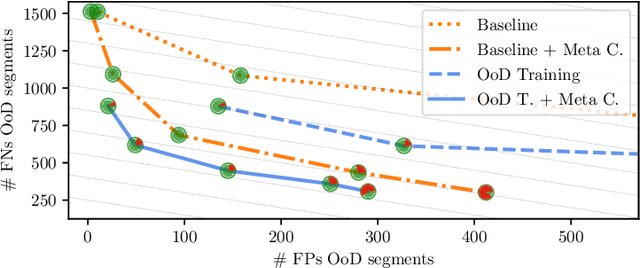

Bringing deep neural networks (DNNs) into safety critical applications such as automated driving, medical imaging and finance, requires a thorough treatment of the model's uncertainties. Training deep neural networks is already resource demanding and so is also their uncertainty quantification. In this overview article, we survey methods that we developed to teach DNNs to be uncertain when they encounter new object classes. Additionally, we present training methods to learn from only a few labels with help of uncertainty quantification. Note that this is typically paid with a massive overhead in computation of an order of magnitude and more compared to ordinary network training. Finally, we survey our work on neural architecture search which is also an order of magnitude more resource demanding then ordinary network training.
Detecting and Learning the Unknown in Semantic Segmentation
Feb 17, 2022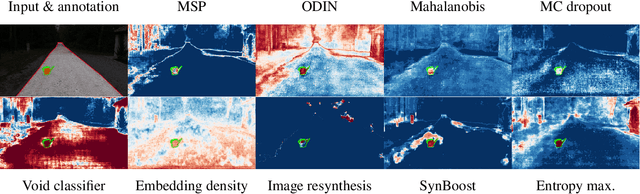
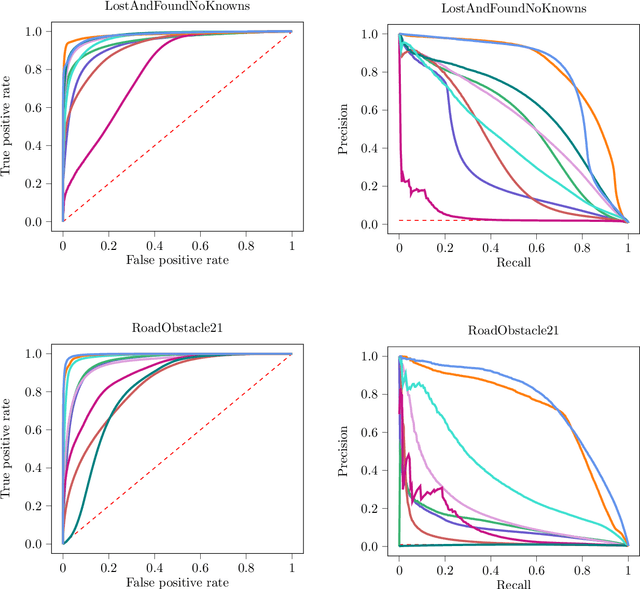
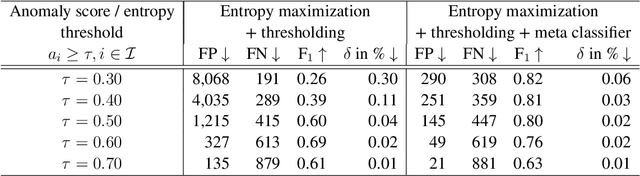
Semantic segmentation is a crucial component for perception in automated driving. Deep neural networks (DNNs) are commonly used for this task and they are usually trained on a closed set of object classes appearing in a closed operational domain. However, this is in contrast to the open world assumption in automated driving that DNNs are deployed to. Therefore, DNNs necessarily face data that they have never encountered previously, also known as anomalies, which are extremely safety-critical to properly cope with. In this work, we first give an overview about anomalies from an information-theoretic perspective. Next, we review research in detecting semantically unknown objects in semantic segmentation. We demonstrate that training for high entropy responses on anomalous objects outperforms other recent methods, which is in line with our theoretical findings. Moreover, we examine a method to assess the occurrence frequency of anomalies in order to select anomaly types to include into a model's set of semantic categories. We demonstrate that these anomalies can then be learned in an unsupervised fashion, which is particularly suitable in online applications based on deep learning.
UQGAN: A Unified Model for Uncertainty Quantification of Deep Classifiers trained via Conditional GANs
Jan 31, 2022
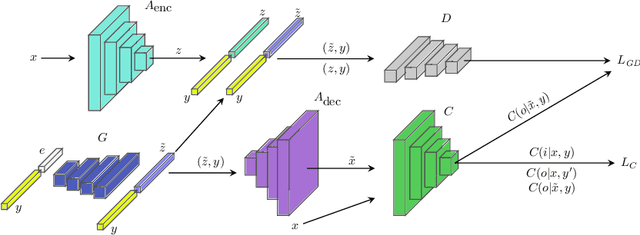
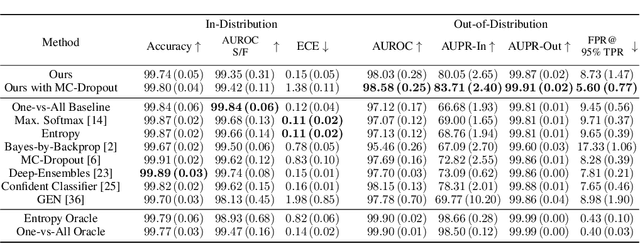

We present an approach to quantifying both aleatoric and epistemic uncertainty for deep neural networks in image classification, based on generative adversarial networks (GANs). While most works in the literature that use GANs to generate out-of-distribution (OoD) examples only focus on the evaluation of OoD detection, we present a GAN based approach to learn a classifier that exhibits proper uncertainties for OoD examples as well as for false positives (FPs). Instead of shielding the entire in-distribution data with GAN generated OoD examples which is state-of-the-art, we shield each class separately with out-of-class examples generated by a conditional GAN and complement this with a one-vs-all image classifier. In our experiments, in particular on CIFAR10, we improve over the OoD detection and FP detection performance of state-of-the-art GAN-training based classifiers. Furthermore, we also find that the generated GAN examples do not significantly affect the calibration error of our classifier and result in a significant gain in model accuracy.
Towards Unsupervised Open World Semantic Segmentation
Jan 04, 2022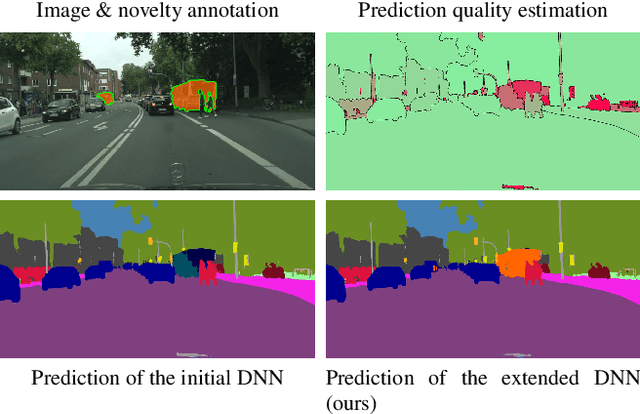
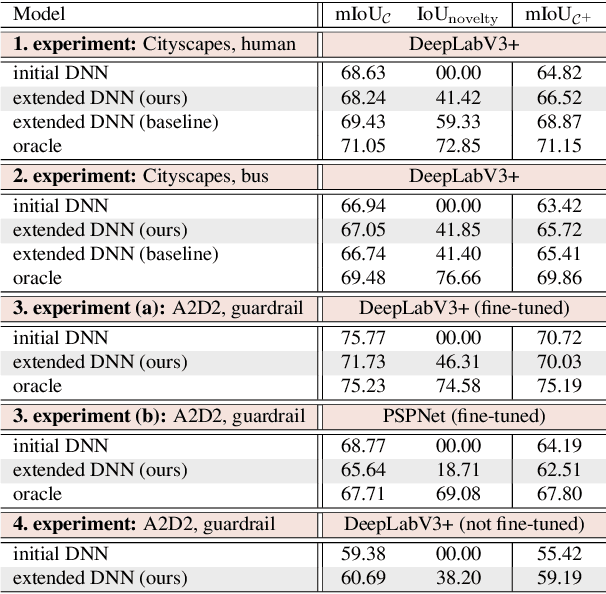
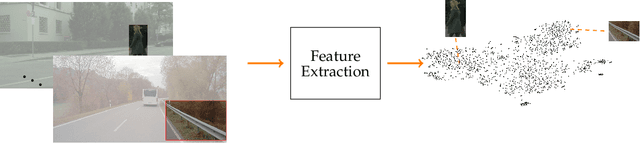
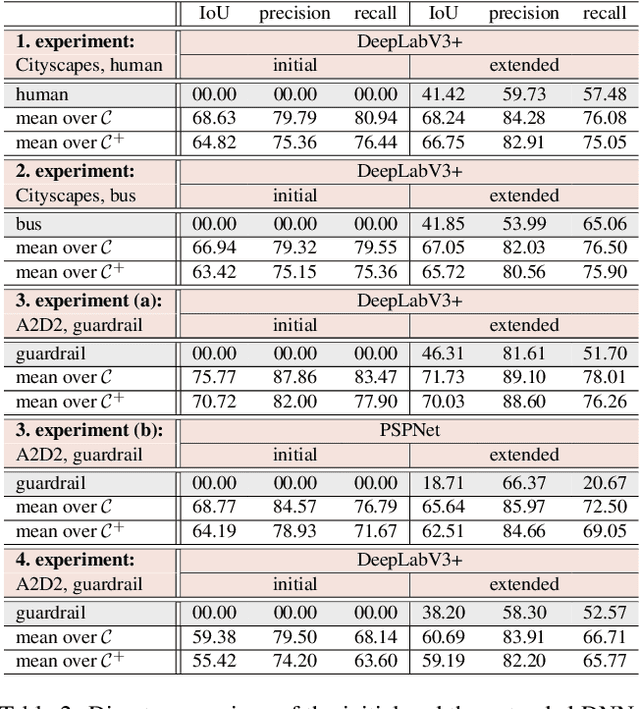
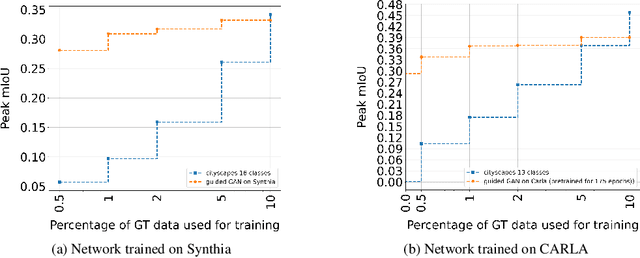
For the semantic segmentation of images, state-of-the-art deep neural networks (DNNs) achieve high segmentation accuracy if that task is restricted to a closed set of classes. However, as of now DNNs have limited ability to operate in an open world, where they are tasked to identify pixels belonging to unknown objects and eventually to learn novel classes, incrementally. Humans have the capability to say: I don't know what that is, but I've already seen something like that. Therefore, it is desirable to perform such an incremental learning task in an unsupervised fashion. We introduce a method where unknown objects are clustered based on visual similarity. Those clusters are utilized to define new classes and serve as training data for unsupervised incremental learning. More precisely, the connected components of a predicted semantic segmentation are assessed by a segmentation quality estimate. connected components with a low estimated prediction quality are candidates for a subsequent clustering. Additionally, the component-wise quality assessment allows for obtaining predicted segmentation masks for the image regions potentially containing unknown objects. The respective pixels of such masks are pseudo-labeled and afterwards used for re-training the DNN, i.e., without the use of ground truth generated by humans. In our experiments we demonstrate that, without access to ground truth and even with few data, a DNN's class space can be extended by a novel class, achieving considerable segmentation accuracy.
Does Redundancy in AI Perception Systems Help to Test for Super-Human Automated Driving Performance?
Dec 09, 2021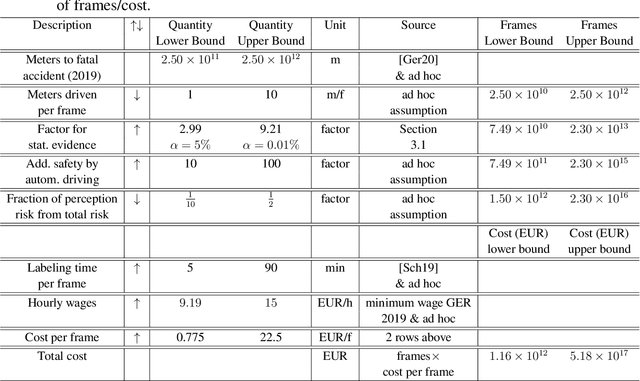
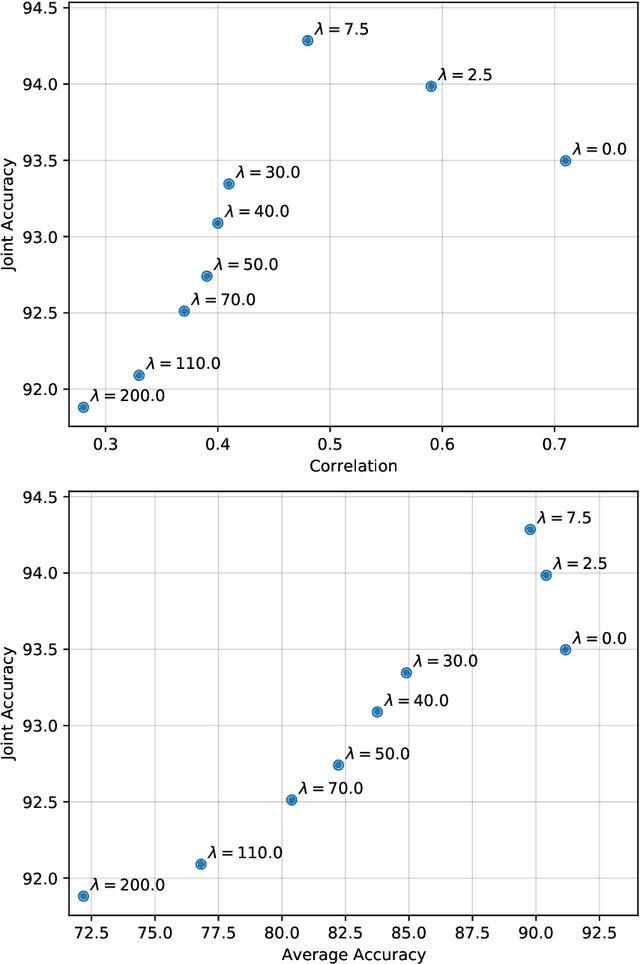
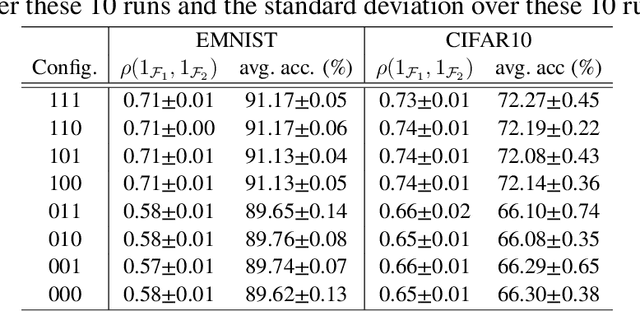
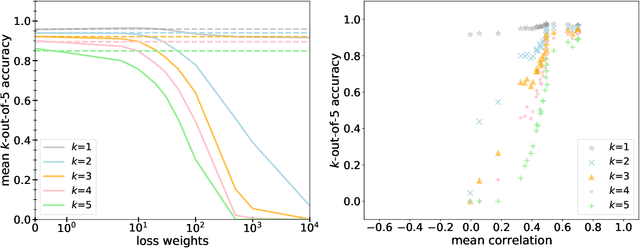
While automated driving is often advertised with better-than-human driving performance, this work reviews that it is nearly impossible to provide direct statistical evidence on the system level that this is actually the case. The amount of labeled data needed would exceed dimensions of present day technical and economical capabilities. A commonly used strategy therefore is the use of redundancy along with the proof of sufficient subsystems' performances. As it is known, this strategy is efficient especially for the case of subsystems operating independently, i.e. the occurrence of errors is independent in a statistical sense. Here, we give some first considerations and experimental evidence that this strategy is not a free ride as the errors of neural networks fulfilling the same computer vision task, at least for some cases, show correlated occurrences of errors. This remains true, if training data, architecture, and training are kept separate or independence is trained using special loss functions. Using data from different sensors (realized by up to five 2D projections of the 3D MNIST data set) in our experiments is more efficiently reducing correlations, however not to an extent that is realizing the potential of reduction of testing data that can be obtained for redundant and statistically independent subsystems.
False Positive Detection and Prediction Quality Estimation for LiDAR Point Cloud Segmentation
Oct 29, 2021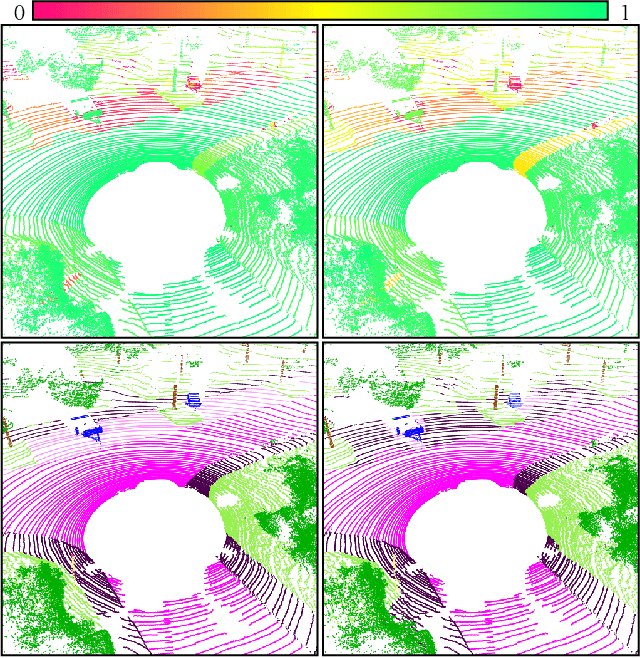
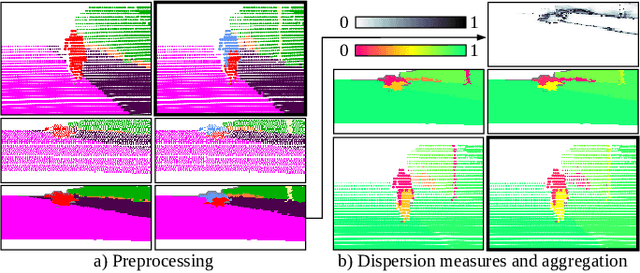
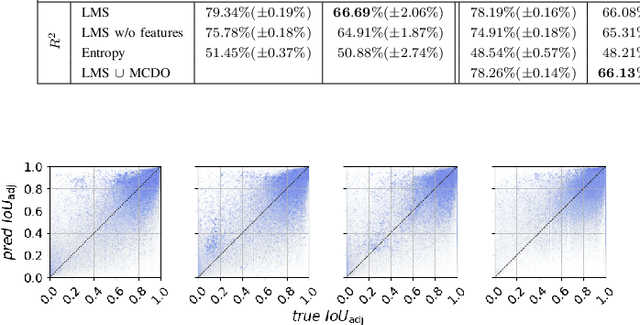
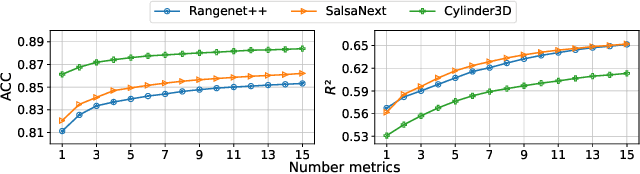
We present a novel post-processing tool for semantic segmentation of LiDAR point cloud data, called LidarMetaSeg, which estimates the prediction quality segmentwise. For this purpose we compute dispersion measures based on network probability outputs as well as feature measures based on point cloud input features and aggregate them on segment level. These aggregated measures are used to train a meta classification model to predict whether a predicted segment is a false positive or not and a meta regression model to predict the segmentwise intersection over union. Both models can then be applied to semantic segmentation inferences without knowing the ground truth. In our experiments we use different LiDAR segmentation models and datasets and analyze the power of our method. We show that our results outperform other standard approaches.
Background-Foreground Segmentation for Interior Sensing in Automotive Industry
Sep 20, 2021

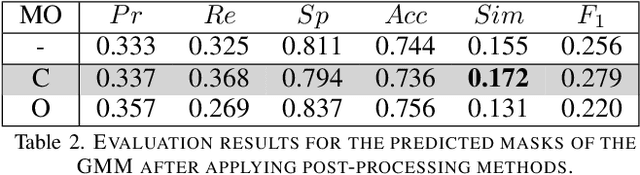
To ensure safety in automated driving, the correct perception of the situation inside the car is as important as its environment. Thus, seat occupancy detection and classification of detected instances play an important role in interior sensing. By the knowledge of the seat occupancy status, it is possible to, e.g., automate the airbag deployment control. Furthermore, the presence of a driver, which is necessary for partially automated driving cars at the automation levels two to four can be verified. In this work, we compare different statistical methods from the field of image segmentation to approach the problem of background-foreground segmentation in camera based interior sensing. In the recent years, several methods based on different techniques have been developed and applied to images or videos from different applications. The peculiarity of the given scenarios of interior sensing is, that the foreground instances and the background both contain static as well as dynamic elements. In data considered in this work, even the camera position is not completely fixed. We review and benchmark three different methods ranging, i.e., Gaussian Mixture Models (GMM), Morphological Snakes and a deep neural network, namely a Mask R-CNN. In particular, the limitations of the classical methods, GMM and Morphological Snakes, for interior sensing are shown. Furthermore, it turns, that it is possible to overcome these limitations by deep learning, e.g.\ using a Mask R-CNN. Although only a small amount of ground truth data was available for training, we enabled the Mask R-CNN to produce high quality background-foreground masks via transfer learning. Moreover, we demonstrate that certain augmentation as well as pre- and post-processing methods further enhance the performance of the investigated methods.
Gradient-Based Quantification of Epistemic Uncertainty for Deep Object Detectors
Jul 09, 2021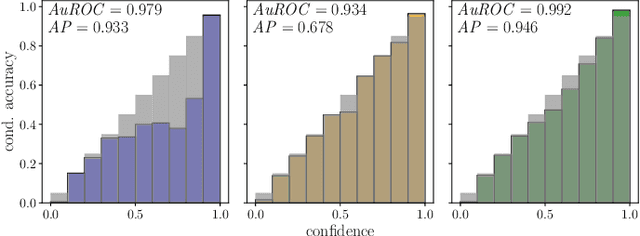
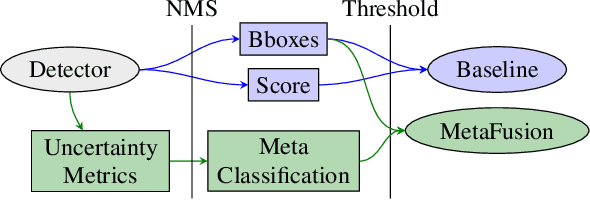
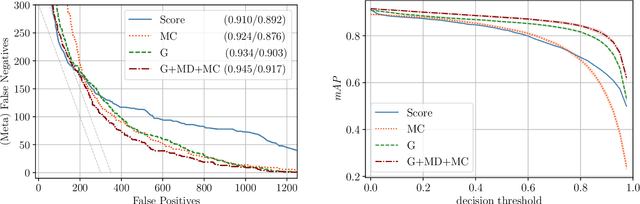
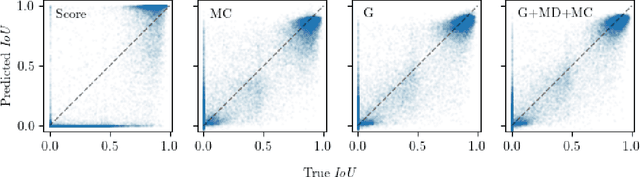
Reliable epistemic uncertainty estimation is an essential component for backend applications of deep object detectors in safety-critical environments. Modern network architectures tend to give poorly calibrated confidences with limited predictive power. Here, we introduce novel gradient-based uncertainty metrics and investigate them for different object detection architectures. Experiments on the MS COCO, PASCAL VOC and the KITTI dataset show significant improvements in true positive / false positive discrimination and prediction of intersection over union as compared to network confidence. We also find improvement over Monte-Carlo dropout uncertainty metrics and further significant boosts by aggregating different sources of uncertainty metrics.The resulting uncertainty models generate well-calibrated confidences in all instances. Furthermore, we implement our uncertainty quantification models into object detection pipelines as a means to discern true against false predictions, replacing the ordinary score-threshold-based decision rule. In our experiments, we achieve a significant boost in detection performance in terms of mean average precision. With respect to computational complexity, we find that computing gradient uncertainty metrics results in floating point operation counts similar to those of Monte-Carlo dropout.
Validation of Simulation-Based Testing: Bypassing Domain Shift with Label-to-Image Synthesis
Jun 10, 2021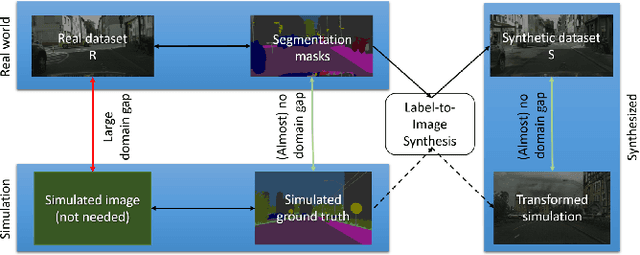
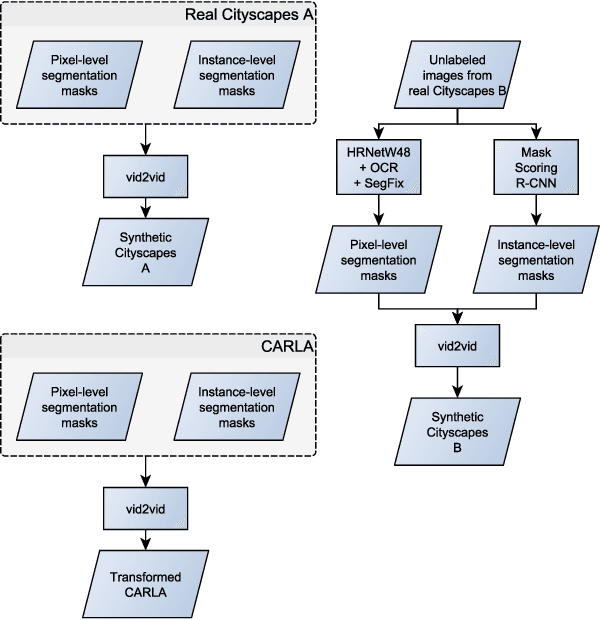


Many machine learning applications can benefit from simulated data for systematic validation - in particular if real-life data is difficult to obtain or annotate. However, since simulations are prone to domain shift w.r.t. real-life data, it is crucial to verify the transferability of the obtained results. We propose a novel framework consisting of a generative label-to-image synthesis model together with different transferability measures to inspect to what extent we can transfer testing results of semantic segmentation models from synthetic data to equivalent real-life data. With slight modifications, our approach is extendable to, e.g., general multi-class classification tasks. Grounded on the transferability analysis, our approach additionally allows for extensive testing by incorporating controlled simulations. We validate our approach empirically on a semantic segmentation task on driving scenes. Transferability is tested using correlation analysis of IoU and a learned discriminator. Although the latter can distinguish between real-life and synthetic tests, in the former we observe surprisingly strong correlations of 0.7 for both cars and pedestrians.
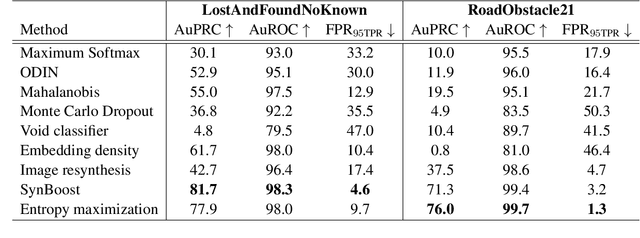
SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation
Apr 30, 2021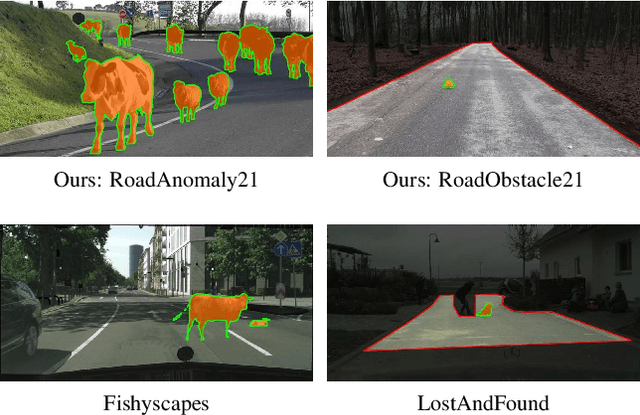
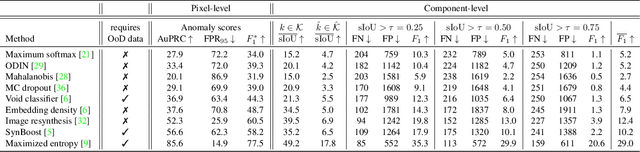

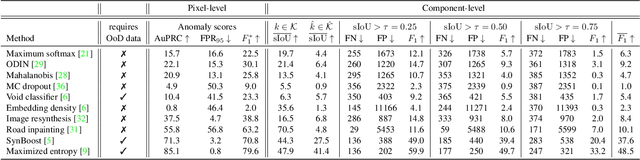
State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects. However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown. We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several specifically designed for anomaly / obstacle segmentation, on our datasets as well as on public ones, using our benchmark suite. The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and challengingness of both dataset landscapes.