 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoconj: Recognizing and Exploiting Conjugacy Without a Domain-Specific Language
Nov 29, 2018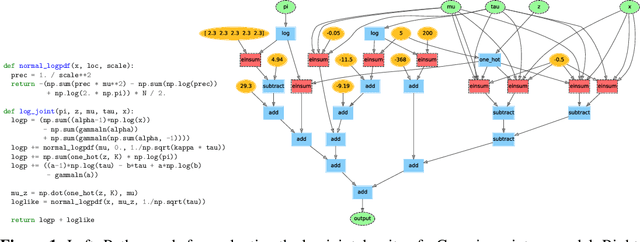

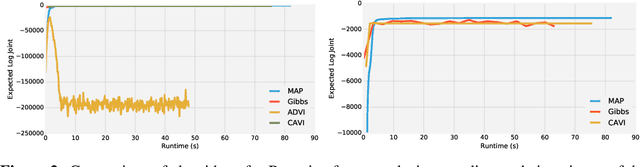
Deriving conditional and marginal distributions using conjugacy relationships can be time consuming and error prone. In this paper, we propose a strategy for automating such derivations. Unlike previous systems which focus on relationships between pairs of random variables, our system (which we call Autoconj) operates directly on Python functions that compute log-joint distribution functions. Autoconj provides support for conjugacy-exploiting algorithms in any Python embedded PPL. This paves the way for accelerating development of novel inference algorithms and structure-exploiting modeling strategies.
The LORACs prior for VAEs: Letting the Trees Speak for the Data
Oct 16, 2018
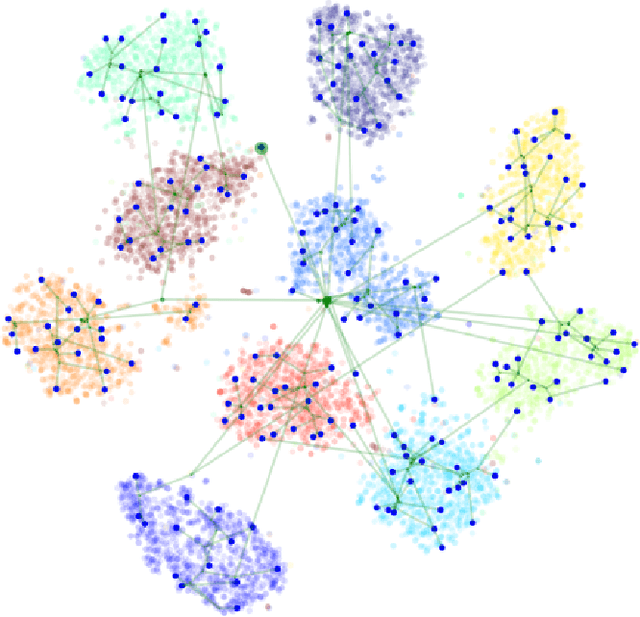
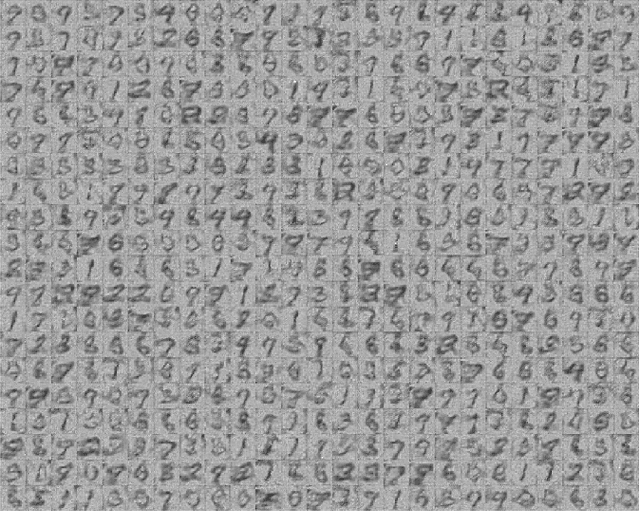

In variational autoencoders, the prior on the latent codes $z$ is often treated as an afterthought, but the prior shapes the kind of latent representation that the model learns. If the goal is to learn a representation that is interpretable and useful, then the prior should reflect the ways in which the high-level factors that describe the data vary. The "default" prior is an isotropic normal, but if the natural factors of variation in the dataset exhibit discrete structure or are not independent, then the isotropic-normal prior will actually encourage learning representations that mask this structure. To alleviate this problem, we propose using a flexible Bayesian nonparametric hierarchical clustering prior based on the time-marginalized coalescent (TMC). To scale learning to large datasets, we develop a new inducing-point approximation and inference algorithm. We then apply the method without supervision to several datasets and examine the interpretability and practical performance of the inferred hierarchies and learned latent space.
Music Transformer
Oct 10, 2018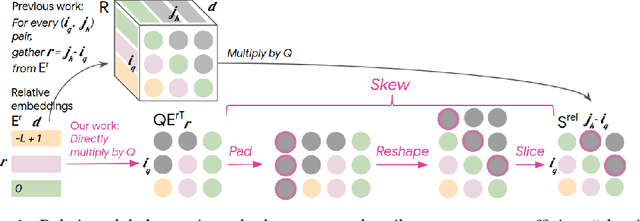

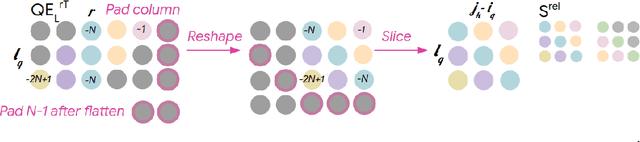

Music relies heavily on repetition to build structure and meaning. Self-reference occurs on multiple timescales, from motifs to phrases to reusing of entire sections of music, such as in pieces with ABA structure. The Transformer (Vaswani et al., 2017), a sequence model based on self-attention, has achieved compelling results in many generation tasks that require maintaining long-range coherence. This suggests that self-attention might also be well-suited to modeling music. In musical composition and performance, however, relative timing is critically important. Existing approaches for representing relative positional information in the Transformer modulate attention based on pairwise distance (Shaw et al., 2018). This is impractical for long sequences such as musical compositions since their memory complexity is quadratic in the sequence length. We propose an algorithm that reduces the intermediate memory requirements to linear in the sequence length. This enables us to demonstrate that a Transformer with our modified relative attention mechanism can generate minute-long (thousands of steps) compositions with compelling structure, generate continuations that coherently elaborate on a given motif, and in a seq2seq setup generate accompaniments conditioned on melodies. We evaluate the Transformer with our relative attention mechanism on two datasets, JSB Chorales and Piano-e-competition, and obtain state-of-the-art results on the latter.
Generalizing Hamiltonian Monte Carlo with Neural Networks
Mar 02, 2018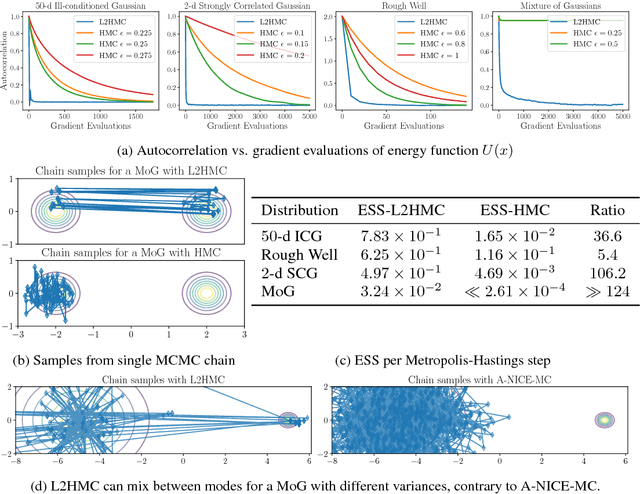

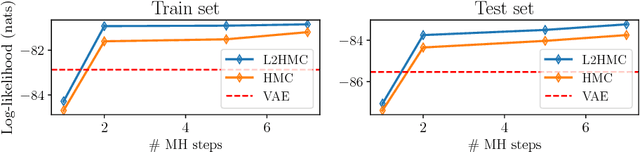

We present a general-purpose method to train Markov chain Monte Carlo kernels, parameterized by deep neural networks, that converge and mix quickly to their target distribution. Our method generalizes Hamiltonian Monte Carlo and is trained to maximize expected squared jumped distance, a proxy for mixing speed. We demonstrate large empirical gains on a collection of simple but challenging distributions, for instance achieving a 106x improvement in effective sample size in one case, and mixing when standard HMC makes no measurable progress in a second. Finally, we show quantitative and qualitative gains on a real-world task: latent-variable generative modeling. We release an open source TensorFlow implementation of the algorithm.
Variational Autoencoders for Collaborative Filtering
Feb 16, 2018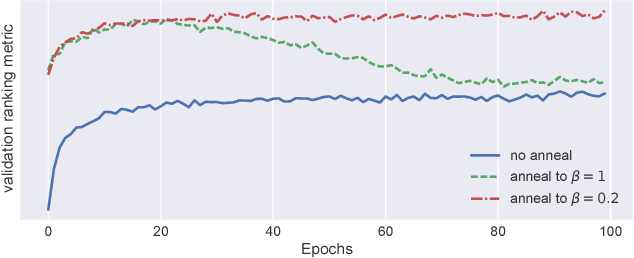
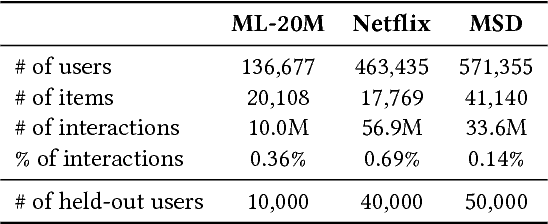
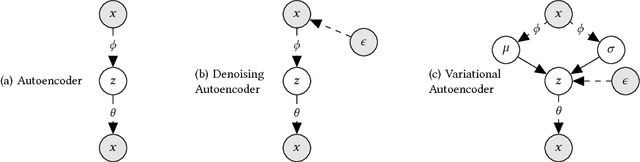
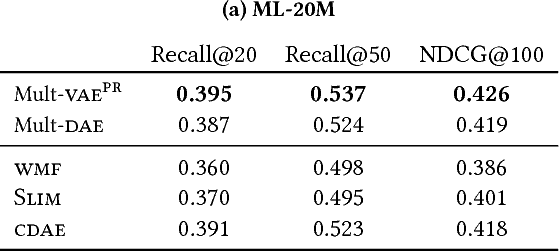
We extend variational autoencoders (VAEs) to collaborative filtering for implicit feedback. This non-linear probabilistic model enables us to go beyond the limited modeling capacity of linear factor models which still largely dominate collaborative filtering research.We introduce a generative model with multinomial likelihood and use Bayesian inference for parameter estimation. Despite widespread use in language modeling and economics, the multinomial likelihood receives less attention in the recommender systems literature. We introduce a different regularization parameter for the learning objective, which proves to be crucial for achieving competitive performance. Remarkably, there is an efficient way to tune the parameter using annealing. The resulting model and learning algorithm has information-theoretic connections to maximum entropy discrimination and the information bottleneck principle. Empirically, we show that the proposed approach significantly outperforms several state-of-the-art baselines, including two recently-proposed neural network approaches, on several real-world datasets. We also provide extended experiments comparing the multinomial likelihood with other commonly used likelihood functions in the latent factor collaborative filtering literature and show favorable results. Finally, we identify the pros and cons of employing a principled Bayesian inference approach and characterize settings where it provides the most significant improvements.
Stochastic Gradient Descent as Approximate Bayesian Inference
Jan 19, 2018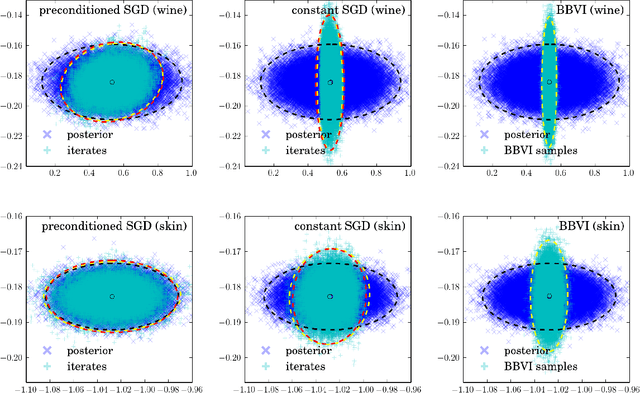
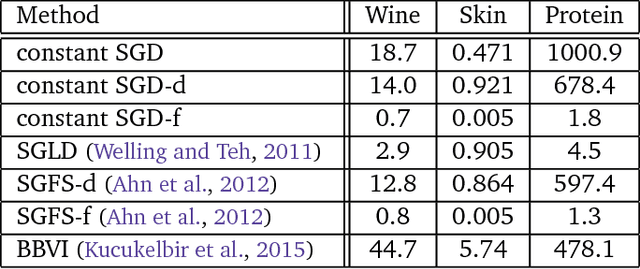
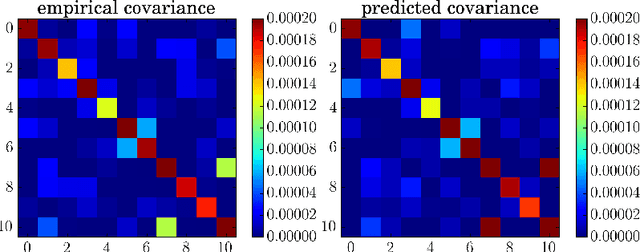
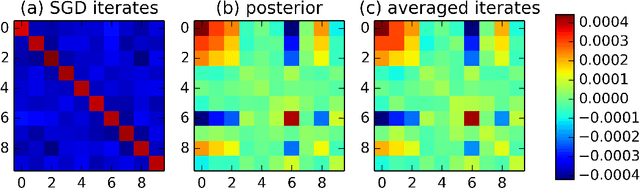
Stochastic Gradient Descent with a constant learning rate (constant SGD) simulates a Markov chain with a stationary distribution. With this perspective, we derive several new results. (1) We show that constant SGD can be used as an approximate Bayesian posterior inference algorithm. Specifically, we show how to adjust the tuning parameters of constant SGD to best match the stationary distribution to a posterior, minimizing the Kullback-Leibler divergence between these two distributions. (2) We demonstrate that constant SGD gives rise to a new variational EM algorithm that optimizes hyperparameters in complex probabilistic models. (3) We also propose SGD with momentum for sampling and show how to adjust the damping coefficient accordingly. (4) We analyze MCMC algorithms. For Langevin Dynamics and Stochastic Gradient Fisher Scoring, we quantify the approximation errors due to finite learning rates. Finally (5), we use the stochastic process perspective to give a short proof of why Polyak averaging is optimal. Based on this idea, we propose a scalable approximate MCMC algorithm, the Averaged Stochastic Gradient Sampler.
* 35 pages, published version (JMLR 2017)
Multimodal Prediction and Personalization of Photo Edits with Deep Generative Models
Apr 17, 2017

Professional-grade software applications are powerful but complicated$-$expert users can achieve impressive results, but novices often struggle to complete even basic tasks. Photo editing is a prime example: after loading a photo, the user is confronted with an array of cryptic sliders like "clarity", "temp", and "highlights". An automatically generated suggestion could help, but there is no single "correct" edit for a given image$-$different experts may make very different aesthetic decisions when faced with the same image, and a single expert may make different choices depending on the intended use of the image (or on a whim). We therefore want a system that can propose multiple diverse, high-quality edits while also learning from and adapting to a user's aesthetic preferences. In this work, we develop a statistical model that meets these objectives. Our model builds on recent advances in neural network generative modeling and scalable inference, and uses hierarchical structure to learn editing patterns across many diverse users. Empirically, we find that our model outperforms other approaches on this challenging multimodal prediction task.
Deep Probabilistic Programming
Mar 07, 2017



We propose Edward, a Turing-complete probabilistic programming language. Edward defines two compositional representations---random variables and inference. By treating inference as a first class citizen, on a par with modeling, we show that probabilistic programming can be as flexible and computationally efficient as traditional deep learning. For flexibility, Edward makes it easy to fit the same model using a variety of composable inference methods, ranging from point estimation to variational inference to MCMC. In addition, Edward can reuse the modeling representation as part of inference, facilitating the design of rich variational models and generative adversarial networks. For efficiency, Edward is integrated into TensorFlow, providing significant speedups over existing probabilistic systems. For example, we show on a benchmark logistic regression task that Edward is at least 35x faster than Stan and 6x faster than PyMC3. Further, Edward incurs no runtime overhead: it is as fast as handwritten TensorFlow.
A Variational Analysis of Stochastic Gradient Algorithms
Feb 08, 2016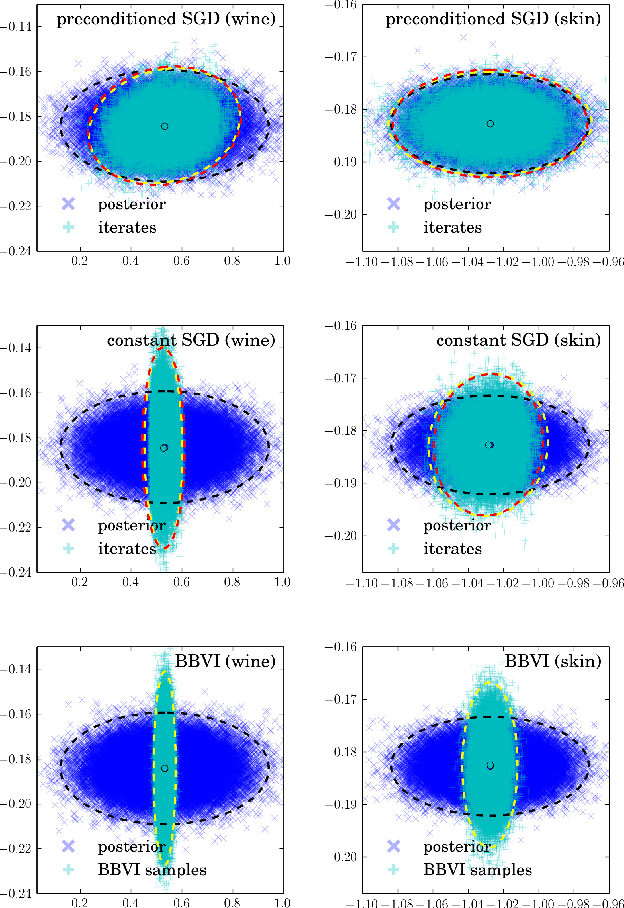
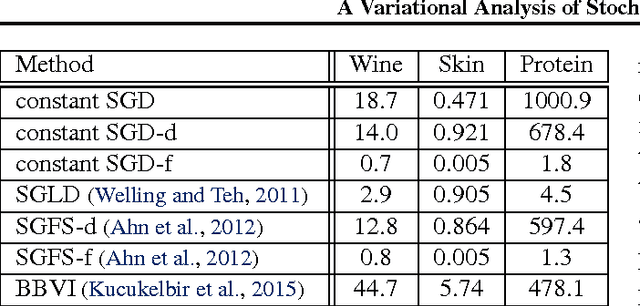
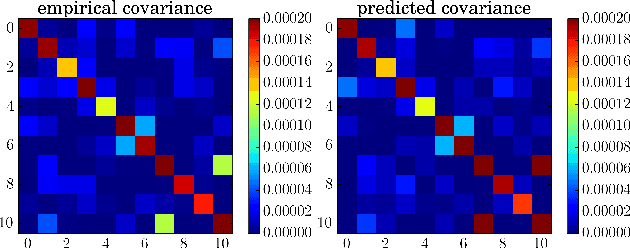
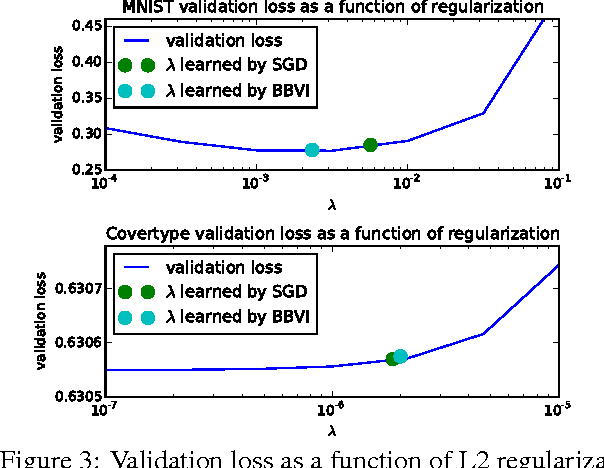
Stochastic Gradient Descent (SGD) is an important algorithm in machine learning. With constant learning rates, it is a stochastic process that, after an initial phase of convergence, generates samples from a stationary distribution. We show that SGD with constant rates can be effectively used as an approximate posterior inference algorithm for probabilistic modeling. Specifically, we show how to adjust the tuning parameters of SGD such as to match the resulting stationary distribution to the posterior. This analysis rests on interpreting SGD as a continuous-time stochastic process and then minimizing the Kullback-Leibler divergence between its stationary distribution and the target posterior. (This is in the spirit of variational inference.) In more detail, we model SGD as a multivariate Ornstein-Uhlenbeck process and then use properties of this process to derive the optimal parameters. This theoretical framework also connects SGD to modern scalable inference algorithms; we analyze the recently proposed stochastic gradient Fisher scoring under this perspective. We demonstrate that SGD with properly chosen constant rates gives a new way to optimize hyperparameters in probabilistic models.
* 8 pages, 3 figures
A trust-region method for stochastic variational inference with applications to streaming data
May 28, 2015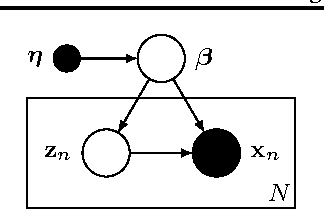
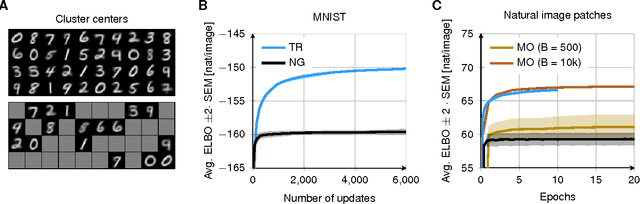
Stochastic variational inference allows for fast posterior inference in complex Bayesian models. However, the algorithm is prone to local optima which can make the quality of the posterior approximation sensitive to the choice of hyperparameters and initialization. We address this problem by replacing the natural gradient step of stochastic varitional inference with a trust-region update. We show that this leads to generally better results and reduced sensitivity to hyperparameters. We also describe a new strategy for variational inference on streaming data and show that here our trust-region method is crucial for getting good performance.