 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Task Descriptions
Nov 16, 2020
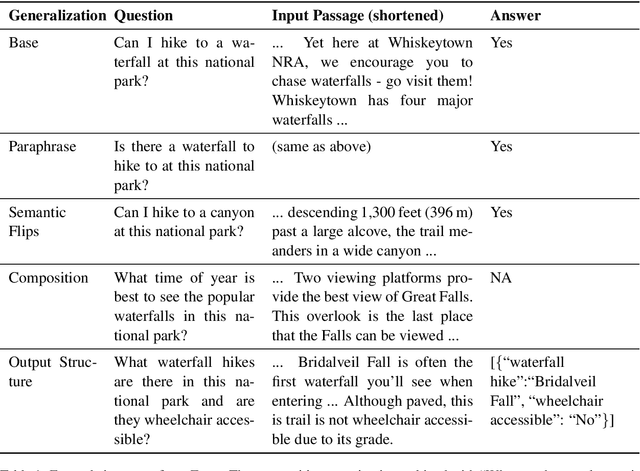
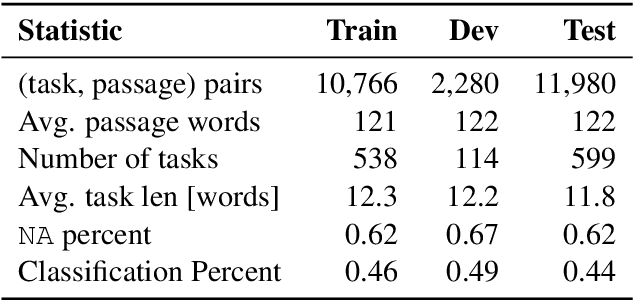
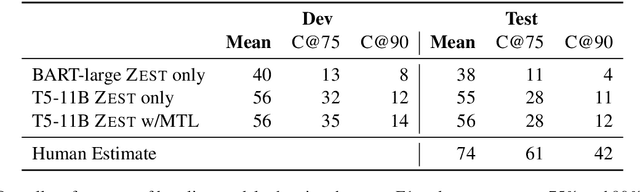
Typically, machine learning systems solve new tasks by training on thousands of examples. In contrast, humans can solve new tasks by reading some instructions, with perhaps an example or two. To take a step toward closing this gap, we introduce a framework for developing NLP systems that solve new tasks after reading their descriptions, synthesizing prior work in this area. We instantiate this framework with a new English language dataset, ZEST, structured for task-oriented evaluation on unseen tasks. Formulating task descriptions as questions, we ensure each is general enough to apply to many possible inputs, thus comprehensively evaluating a model's ability to solve each task. Moreover, the dataset's structure tests specific types of systematic generalization. We find that the state-of-the-art T5 model achieves a score of 12% on ZEST, leaving a significant challenge for NLP researchers.
IIRC: A Dataset of Incomplete Information Reading Comprehension Questions
Nov 13, 2020
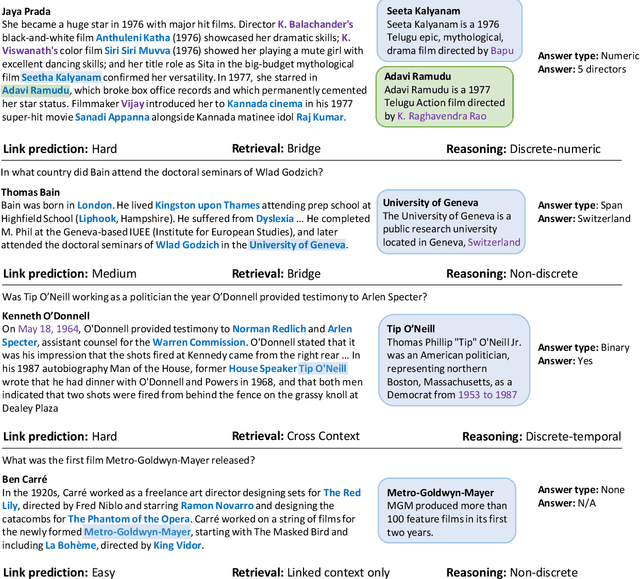

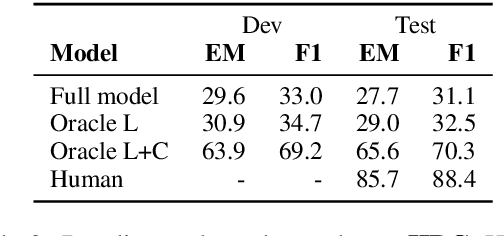
Humans often have to read multiple documents to address their information needs. However, most existing reading comprehension (RC) tasks only focus on questions for which the contexts provide all the information required to answer them, thus not evaluating a system's performance at identifying a potential lack of sufficient information and locating sources for that information. To fill this gap, we present a dataset, IIRC, with more than 13K questions over paragraphs from English Wikipedia that provide only partial information to answer them, with the missing information occurring in one or more linked documents. The questions were written by crowd workers who did not have access to any of the linked documents, leading to questions that have little lexical overlap with the contexts where the answers appear. This process also gave many questions without answers, and those that require discrete reasoning, increasing the difficulty of the task. We follow recent modeling work on various reading comprehension datasets to construct a baseline model for this dataset, finding that it achieves 31.1% F1 on this task, while estimated human performance is 88.4%. The dataset, code for the baseline system, and a leaderboard can be found at https://allennlp.org/iirc.
MOCHA: A Dataset for Training and Evaluating Generative Reading Comprehension Metrics
Oct 15, 2020


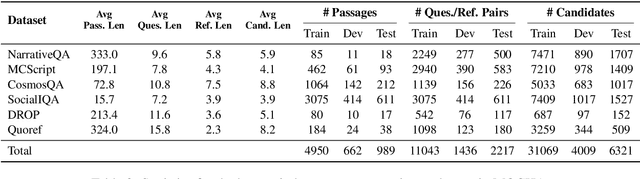
Posing reading comprehension as a generation problem provides a great deal of flexibility, allowing for open-ended questions with few restrictions on possible answers. However, progress is impeded by existing generation metrics, which rely on token overlap and are agnostic to the nuances of reading comprehension. To address this, we introduce a benchmark for training and evaluating generative reading comprehension metrics: MOdeling Correctness with Human Annotations. MOCHA contains 40K human judgement scores on model outputs from 6 diverse question answering datasets and an additional set of minimal pairs for evaluation. Using MOCHA, we train a Learned Evaluation metric for Reading Comprehension, LERC, to mimic human judgement scores. LERC outperforms baseline metrics by 10 to 36 absolute Pearson points on held-out annotations. When we evaluate robustness on minimal pairs, LERC achieves 80% accuracy, outperforming baselines by 14 to 26 absolute percentage points while leaving significant room for improvement. MOCHA presents a challenging problem for developing accurate and robust generative reading comprehension metrics.
MedICaT: A Dataset of Medical Images, Captions, and Textual References
Oct 12, 2020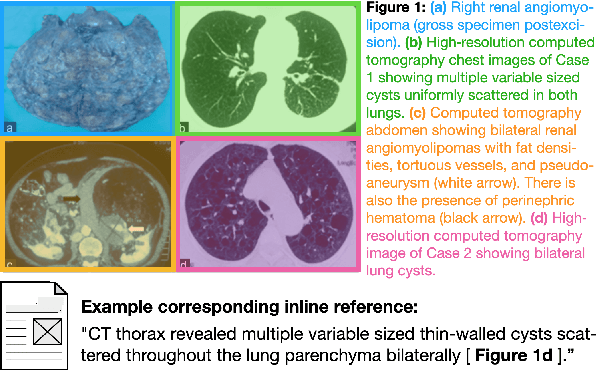

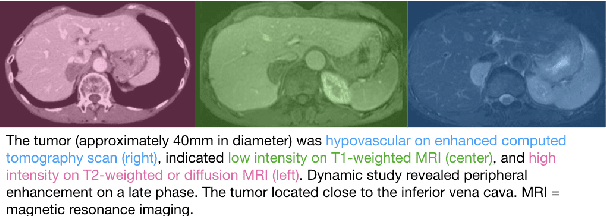
Understanding the relationship between figures and text is key to scientific document understanding. Medical figures in particular are quite complex, often consisting of several subfigures (75% of figures in our dataset), with detailed text describing their content. Previous work studying figures in scientific papers focused on classifying figure content rather than understanding how images relate to the text. To address challenges in figure retrieval and figure-to-text alignment, we introduce MedICaT, a dataset of medical images in context. MedICaT consists of 217K images from 131K open access biomedical papers, and includes captions, inline references for 74% of figures, and manually annotated subfigures and subcaptions for a subset of figures. Using MedICaT, we introduce the task of subfigure to subcaption alignment in compound figures and demonstrate the utility of inline references in image-text matching. Our data and code can be accessed at https://github.com/allenai/medicat.
Improving Compositional Generalization in Semantic Parsing
Oct 12, 2020
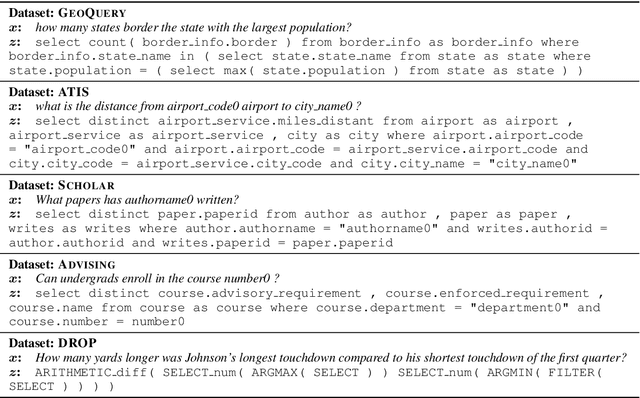

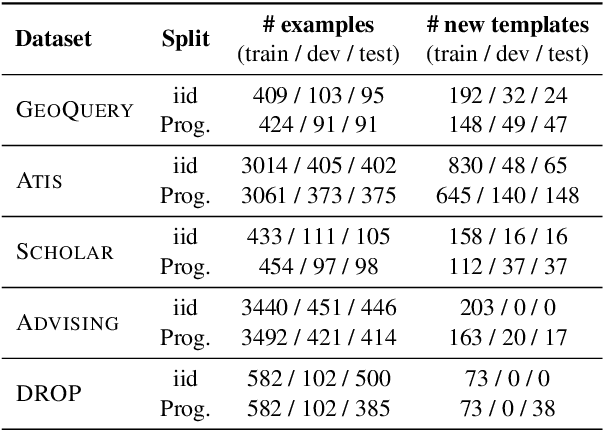
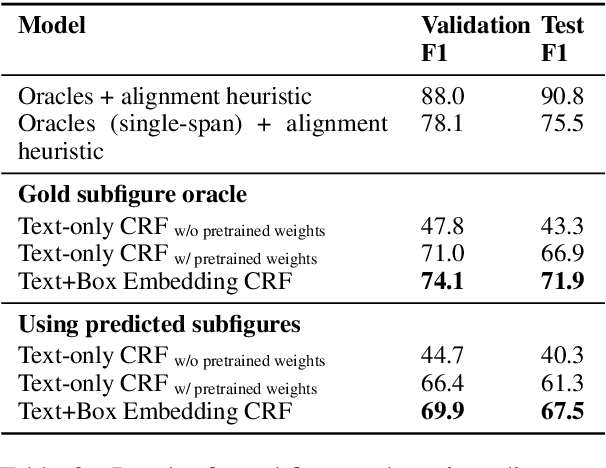
Generalization of models to out-of-distribution (OOD) data has captured tremendous attention recently. Specifically, compositional generalization, i.e., whether a model generalizes to new structures built of components observed during training, has sparked substantial interest. In this work, we investigate compositional generalization in semantic parsing, a natural test-bed for compositional generalization, as output programs are constructed from sub-components. We analyze a wide variety of models and propose multiple extensions to the attention module of the semantic parser, aiming to improve compositional generalization. We find that the following factors improve compositional generalization: (a) using contextual representations, such as ELMo and BERT, (b) informing the decoder what input tokens have previously been attended to, (c) training the decoder attention to agree with pre-computed token alignments, and (d) downsampling examples corresponding to frequent program templates. While we substantially reduce the gap between in-distribution and OOD generalization, performance on OOD compositions is still substantially lower.
Understanding Mention Detector-Linker Interaction for Neural Coreference Resolution
Sep 20, 2020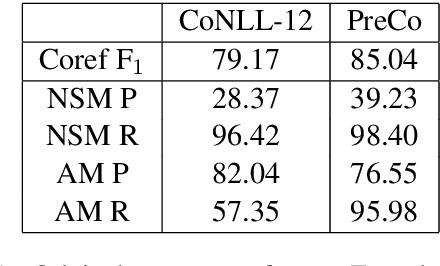
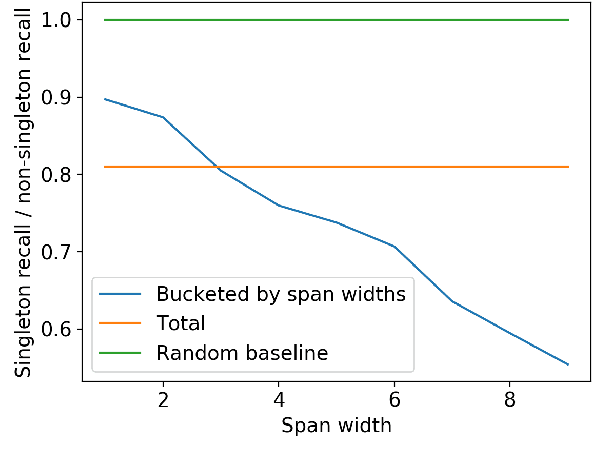
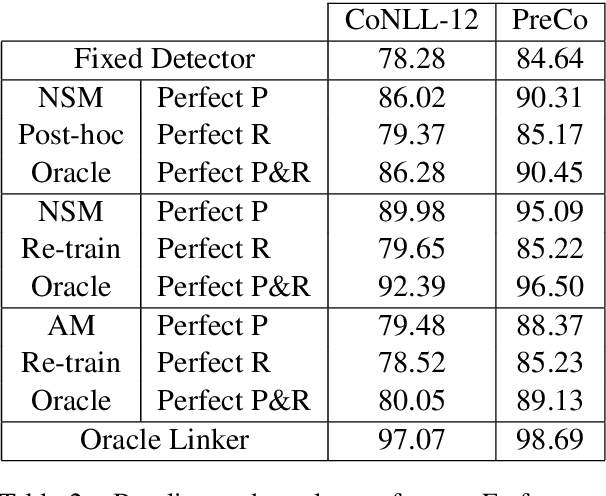

Coreference resolution is an important task for discourse-level natural language understanding. However, despite significant recent progress, the quality of current state-of-the-art systems still considerably trails behind human-level performance. Using the CoNLL-2012 and PreCo datasets, we dissect the best instantiation of the mainstream end-to-end coreference resolution model that underlies most current best-performing coreference systems, and empirically analyze the behavior of its two components: the mention detector and mention linker. While the detector traditionally focuses heavily on recall as a design decision, we demonstrate the importance of precision, calling for their balance. However, we point out the difficulty in building a precise detector due to its inability to make important anaphoricity decisions. We also highlight the enormous room for improving the linker and that the rest of its errors mainly involve pronoun resolution. We hope our findings will help future research in building coreference resolution systems.
Latent Compositional Representations Improve Systematic Generalization in Grounded Question Answering
Jul 01, 2020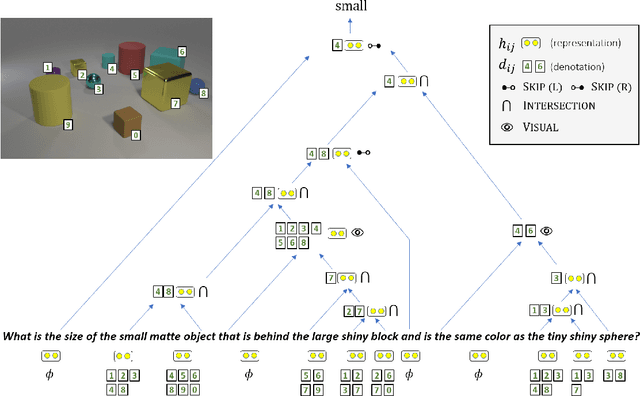


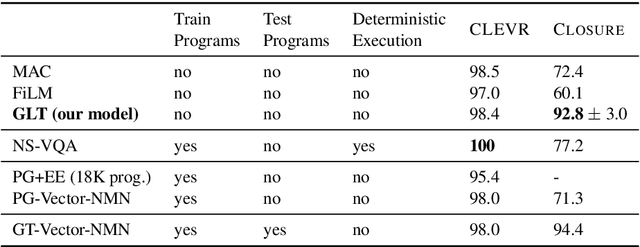
Answering questions that involve multi-step reasoning requires decomposing them and using the answers of intermediate steps to reach the final answer. However, state-of-the-art models in grounded question answering often do not explicitly perform decomposition, leading to difficulties in generalization to out-of-distribution examples. In this work, we propose a model that computes a representation and denotation for all question spans in a bottom-up, compositional manner using a CKY-style parser. Our model effectively induces latent trees, driven by end-to-end (the answer) supervision only. We show that this inductive bias towards tree structures dramatically improves systematic generalization to out-of-distribution examples compared to strong baselines on an arithmetic expressions benchmark as well as on CLOSURE, a dataset that focuses on systematic generalization of models for grounded question answering. On this challenging dataset, our model reaches an accuracy of 92.8%, significantly higher than prior models that almost perfectly solve the task on a random, in-distribution split.
Obtaining Faithful Interpretations from Compositional Neural Networks
May 02, 2020
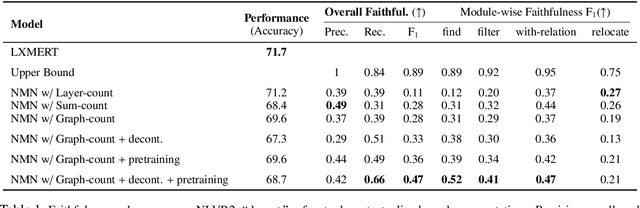
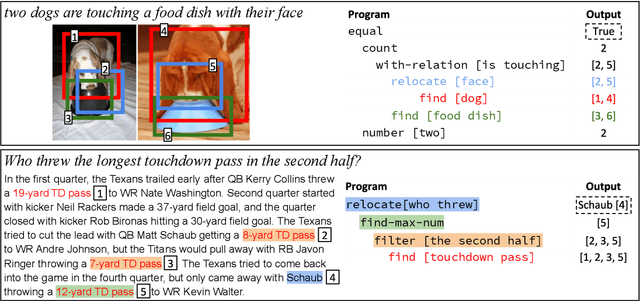
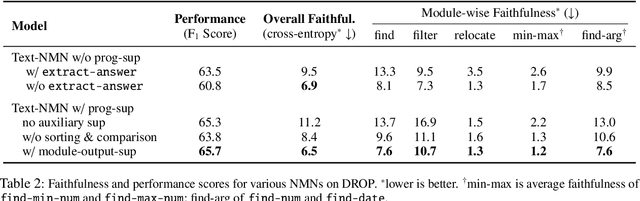
Neural module networks (NMNs) are a popular approach for modeling compositionality: they achieve high accuracy when applied to problems in language and vision, while reflecting the compositional structure of the problem in the network architecture. However, prior work implicitly assumed that the structure of the network modules, describing the abstract reasoning process, provides a faithful explanation of the model's reasoning; that is, that all modules perform their intended behaviour. In this work, we propose and conduct a systematic evaluation of the intermediate outputs of NMNs on NLVR2 and DROP, two datasets which require composing multiple reasoning steps. We find that the intermediate outputs differ from the expected output, illustrating that the network structure does not provide a faithful explanation of model behaviour. To remedy that, we train the model with auxiliary supervision and propose particular choices for module architecture that yield much better faithfulness, at a minimal cost to accuracy.
TORQUE: A Reading Comprehension Dataset of Temporal Ordering Questions
May 01, 2020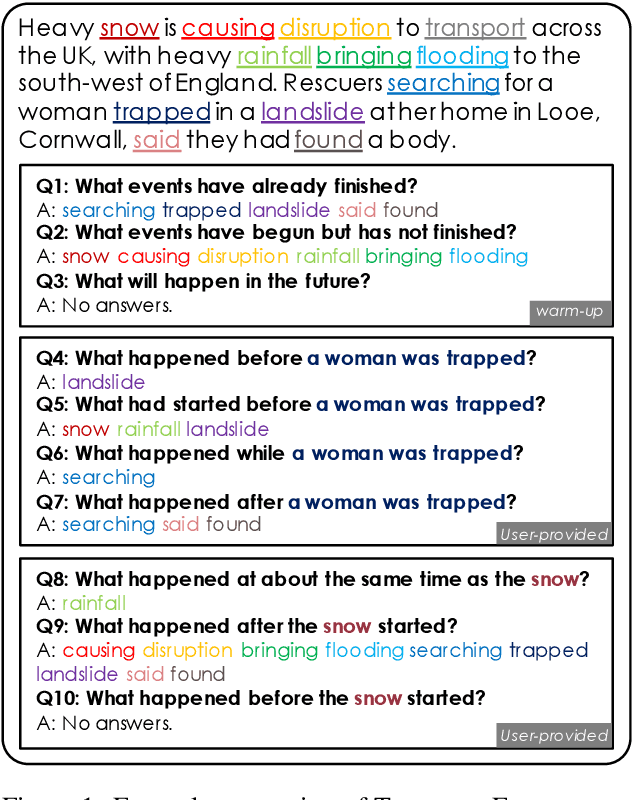



A critical part of reading is being able to understand the temporal relationships between events described in a passage of text, even when those relationships are not explicitly stated. However, current machine reading comprehension benchmarks have practically no questions that test temporal phenomena, so systems trained on these benchmarks have no capacity to answer questions such as "what happened before/after [some event]?" We introduce TORQUE, a new English reading comprehension benchmark built on 3.2k news snippets with 21k human-generated questions querying temporal relationships. Results show that RoBERTa-large achieves an exact-match score of 51% on the test set of TORQUE, about 30% behind human performance.
Multi-Step Inference for Reasoning Over Paragraphs
Apr 06, 2020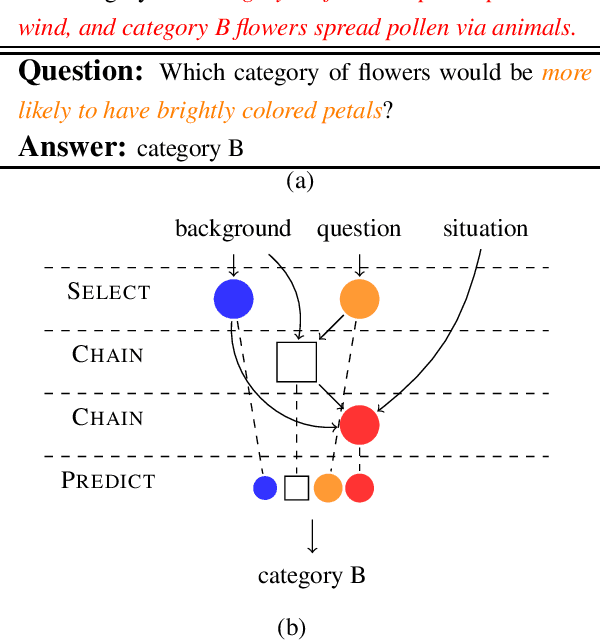

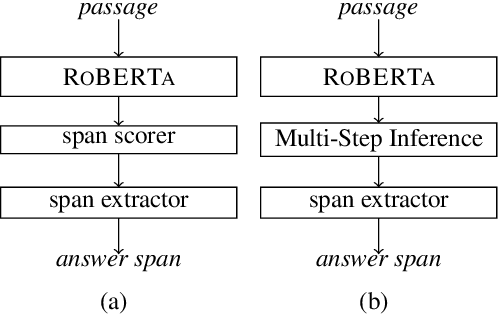
Complex reasoning over text requires understanding and chaining together free-form predicates and logical connectives. Prior work has largely tried to do this either symbolically or with black-box transformers. We present a middle ground between these two extremes: a compositional model reminiscent of neural module networks that can perform chained logical reasoning. This model first finds relevant sentences in the context and then chains them together using neural modules. Our model gives significant performance improvements (up to 29\% relative error reduction when combined with a reranker) on ROPES, a recently-introduced complex reasoning dataset