 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Impact of Noise and Speech Enhancement on the Intelligibility of Speech Codecs
May 05, 2026Preserving speech intelligibility is a minimum requirement for speech codecs in communication. Recently, very low-bitrate neural codecs have gained interest for replacing classical codecs, reinforcing the need to evaluate whether intelligibility is preserved in realistic scenarios. In this paper, we evaluate the intelligibility and listening effort of classical and neural speech codecs in clean and noisy conditions. Further, we assess the impact of speech enhancement (SE) before coding, simulating a possible audio processing pipeline. The results show that classical codecs are more noise robust than neural codecs. Further, SE can lead to significant intelligibility and listening effort improvements for codecs otherwise negatively affected by noise. Listening effort reveals nuanced differences when intelligibility is saturated. Lastly, objective intelligibility based on automatic speech recognition is highly correlated with subjective intelligibility scores averaged per condition.
Meta Learning Text-to-Speech Synthesis in over 7000 Languages
Jun 10, 2024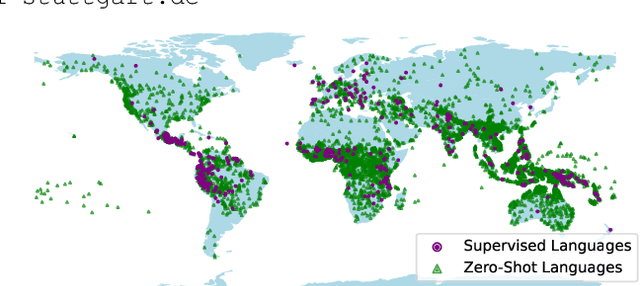
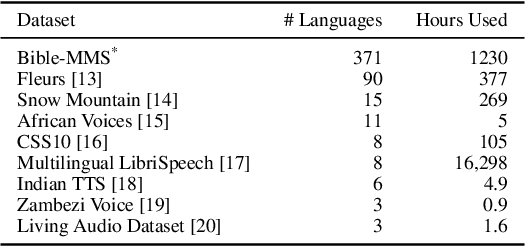
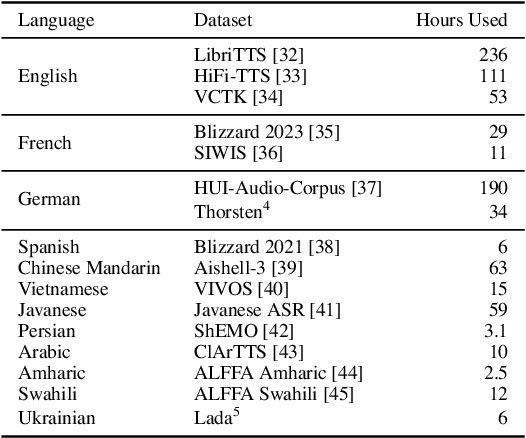
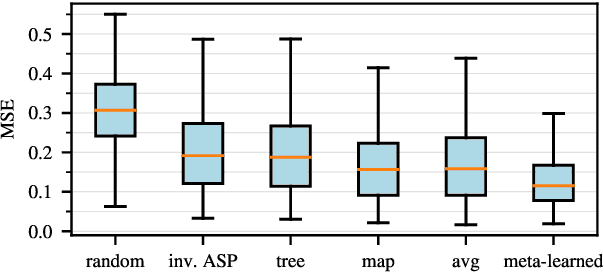
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.