 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Adversarial Training against Backdoor Attacks
Feb 22, 2022

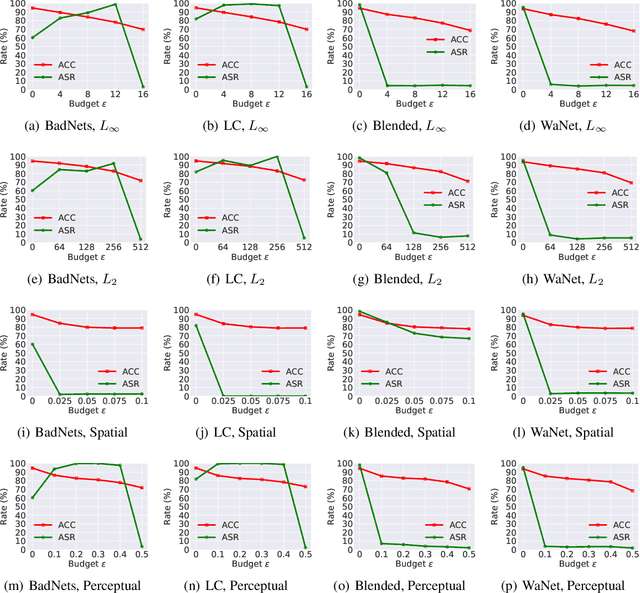
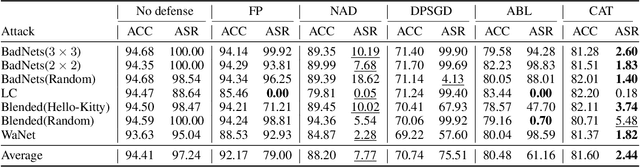
DNNs' demand for massive data forces practitioners to collect data from the Internet without careful check due to the unacceptable cost, which brings potential risks of backdoor attacks. A backdoored model always predicts a target class in the presence of a predefined trigger pattern, which can be easily realized via poisoning a small amount of data. In general, adversarial training is believed to defend against backdoor attacks since it helps models to keep their prediction unchanged even if we perturb the input image (as long as within a feasible range). Unfortunately, few previous studies succeed in doing so. To explore whether adversarial training could defend against backdoor attacks or not, we conduct extensive experiments across different threat models and perturbation budgets, and find the threat model in adversarial training matters. For instance, adversarial training with spatial adversarial examples provides notable robustness against commonly-used patch-based backdoor attacks. We further propose a hybrid strategy which provides satisfactory robustness across different backdoor attacks.
Adversarial Attacks and Defense for Non-Parametric Two-Sample Tests
Feb 07, 2022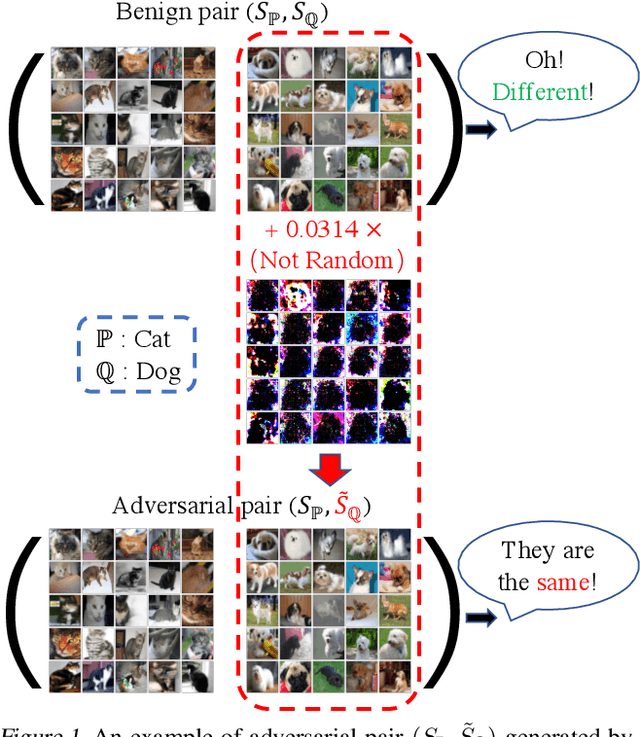
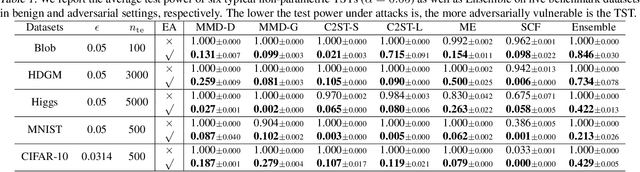
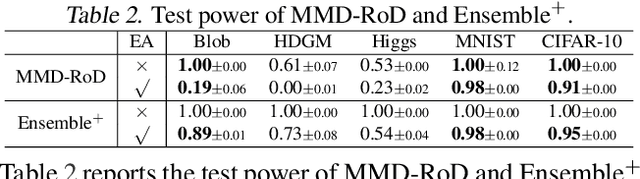
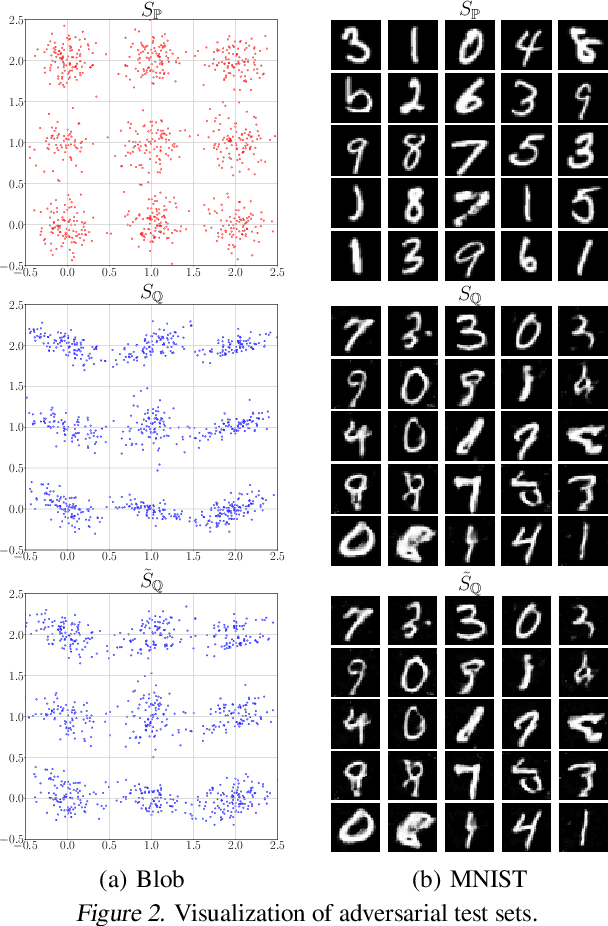
Non-parametric two-sample tests (TSTs) that judge whether two sets of samples are drawn from the same distribution, have been widely used in the analysis of critical data. People tend to employ TSTs as trusted basic tools and rarely have any doubt about their reliability. This paper systematically uncovers the failure mode of non-parametric TSTs through adversarial attacks and then proposes corresponding defense strategies. First, we theoretically show that an adversary can upper-bound the distributional shift which guarantees the attack's invisibility. Furthermore, we theoretically find that the adversary can also degrade the lower bound of a TST's test power, which enables us to iteratively minimize the test criterion in order to search for adversarial pairs. To enable TST-agnostic attacks, we propose an ensemble attack (EA) framework that jointly minimizes the different types of test criteria. Second, to robustify TSTs, we propose a max-min optimization that iteratively generates adversarial pairs to train the deep kernels. Extensive experiments on both simulated and real-world datasets validate the adversarial vulnerabilities of non-parametric TSTs and the effectiveness of our proposed defense.
Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification
Feb 01, 2022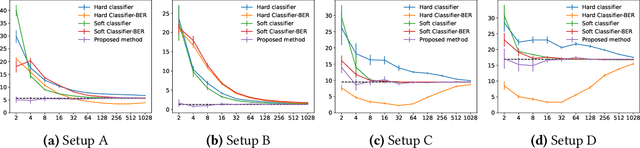

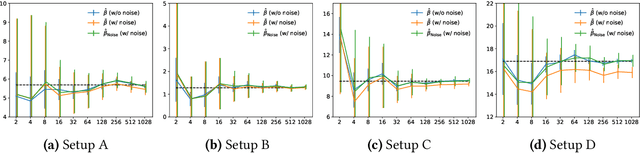

There is a fundamental limitation in the prediction performance that a machine learning model can achieve due to the inevitable uncertainty of the prediction target. In classification problems, this can be characterized by the Bayes error, which is the best achievable error with any classifier. The Bayes error can be used as a criterion to evaluate classifiers with state-of-the-art performance and can be used to detect test set overfitting. We propose a simple and direct Bayes error estimator, where we just take the mean of the labels that show \emph{uncertainty} of the classes. Our flexible approach enables us to perform Bayes error estimation even for weakly supervised data. In contrast to others, our method is model-free and even instance-free. Moreover, it has no hyperparameters and gives a more accurate estimate of the Bayes error than classifier-based baselines. Experiments using our method suggest that a recently proposed classifier, the Vision Transformer, may have already reached the Bayes error for certain benchmark datasets.
Towards Adversarially Robust Deep Image Denoising
Jan 13, 2022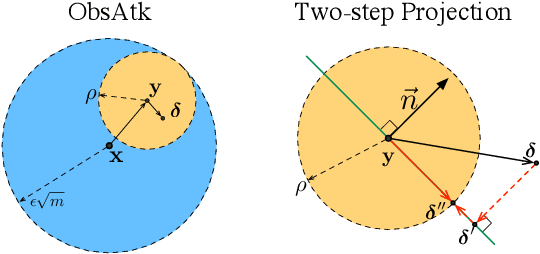
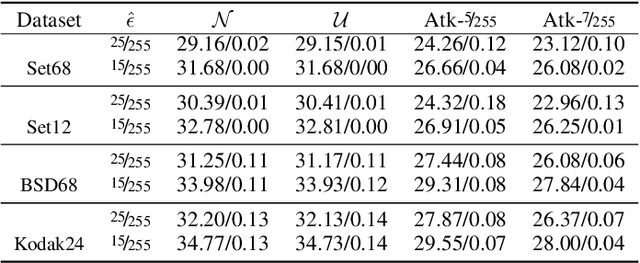

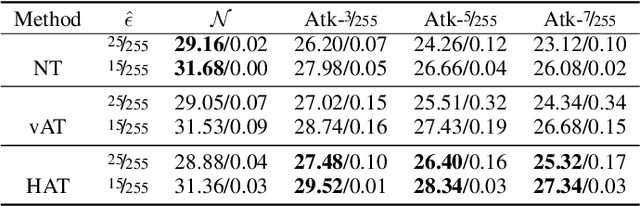
This work systematically investigates the adversarial robustness of deep image denoisers (DIDs), i.e, how well DIDs can recover the ground truth from noisy observations degraded by adversarial perturbations. Firstly, to evaluate DIDs' robustness, we propose a novel adversarial attack, namely Observation-based Zero-mean Attack ({\sc ObsAtk}), to craft adversarial zero-mean perturbations on given noisy images. We find that existing DIDs are vulnerable to the adversarial noise generated by {\sc ObsAtk}. Secondly, to robustify DIDs, we propose an adversarial training strategy, hybrid adversarial training ({\sc HAT}), that jointly trains DIDs with adversarial and non-adversarial noisy data to ensure that the reconstruction quality is high and the denoisers around non-adversarial data are locally smooth. The resultant DIDs can effectively remove various types of synthetic and adversarial noise. We also uncover that the robustness of DIDs benefits their generalization capability on unseen real-world noise. Indeed, {\sc HAT}-trained DIDs can recover high-quality clean images from real-world noise even without training on real noisy data. Extensive experiments on benchmark datasets, including Set68, PolyU, and SIDD, corroborate the effectiveness of {\sc ObsAtk} and {\sc HAT}.
Learning with Proper Partial Labels
Dec 23, 2021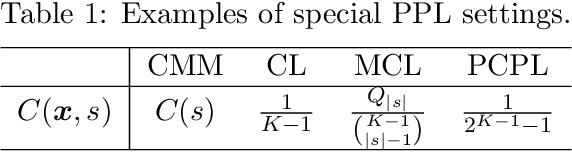
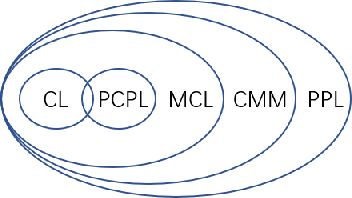

Partial-label learning is a kind of weakly-supervised learning with inexact labels, where for each training example, we are given a set of candidate labels instead of only one true label. Recently, various approaches on partial-label learning have been proposed under different generation models of candidate label sets. However, these methods require relatively strong distributional assumptions on the generation models. When the assumptions do not hold, the performance of the methods is not guaranteed theoretically. In this paper, we propose the notion of properness on partial labels. We show that this proper partial-label learning framework includes many previous partial-label learning settings as special cases. We then derive a unified unbiased estimator of the classification risk. We prove that our estimator is risk-consistent by obtaining its estimation error bound. Finally, we validate the effectiveness of our algorithm through experiments.
Rethinking Importance Weighting for Transfer Learning
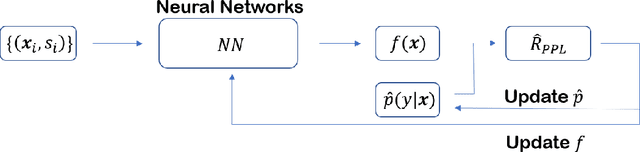
Dec 19, 2021
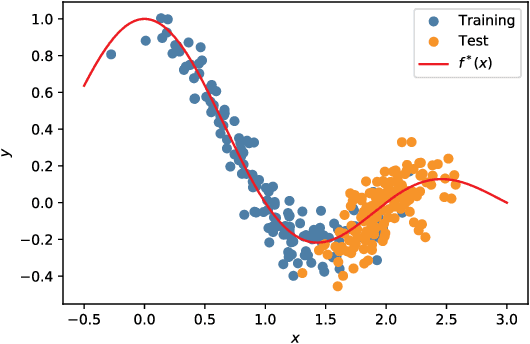
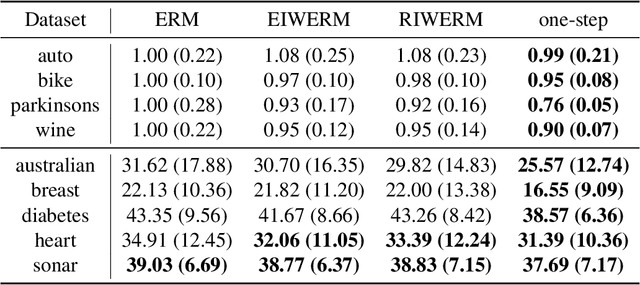
A key assumption in supervised learning is that training and test data follow the same probability distribution. However, this fundamental assumption is not always satisfied in practice, e.g., due to changing environments, sample selection bias, privacy concerns, or high labeling costs. Transfer learning (TL) relaxes this assumption and allows us to learn under distribution shift. Classical TL methods typically rely on importance-weighting -- a predictor is trained based on the training losses weighted according to the importance (i.e., the test-over-training density ratio). However, as real-world machine learning tasks are becoming increasingly complex, high-dimensional, and dynamical, novel approaches are explored to cope with such challenges recently. In this article, after introducing the foundation of TL based on importance-weighting, we review recent advances based on joint and dynamic importance-predictor estimation. Furthermore, we introduce a method of causal mechanism transfer that incorporates causal structure in TL. Finally, we discuss future perspectives of TL research.
Active Refinement for Multi-Label Learning: A Pseudo-Label Approach
Sep 29, 2021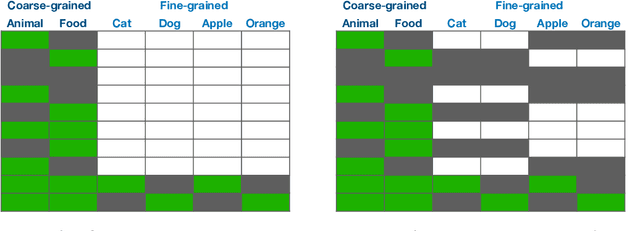
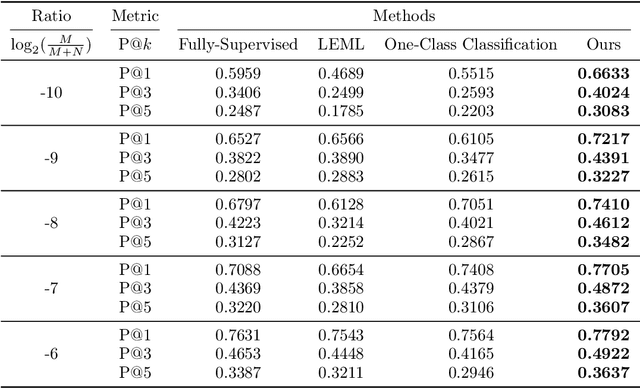
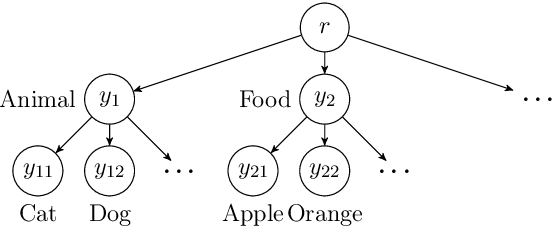
The goal of multi-label learning (MLL) is to associate a given instance with its relevant labels from a set of concepts. Previous works of MLL mainly focused on the setting where the concept set is assumed to be fixed, while many real-world applications require introducing new concepts into the set to meet new demands. One common need is to refine the original coarse concepts and split them into finer-grained ones, where the refinement process typically begins with limited labeled data for the finer-grained concepts. To address the need, we formalize the problem into a special weakly supervised MLL problem to not only learn the fine-grained concepts efficiently but also allow interactive queries to strategically collect more informative annotations to further improve the classifier. The key idea within our approach is to learn to assign pseudo-labels to the unlabeled entries, and in turn leverage the pseudo-labels to train the underlying classifier and to inform a better query strategy. Experimental results demonstrate that our pseudo-label approach is able to accurately recover the missing ground truth, boosting the prediction performance significantly over the baseline methods and facilitating a competitive active learning strategy.
Positive-Unlabeled Classification under Class-Prior Shift: A Prior-invariant Approach Based on Density Ratio Estimation
Aug 17, 2021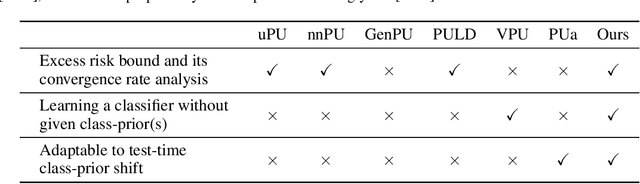
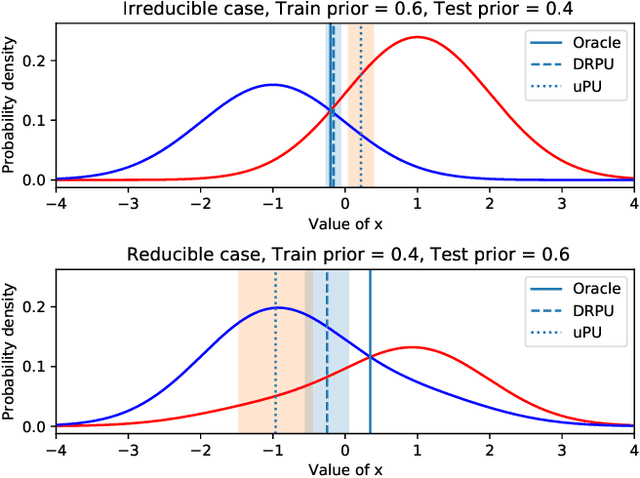
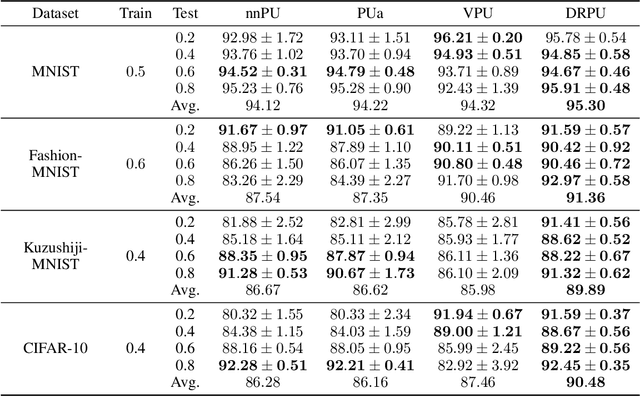
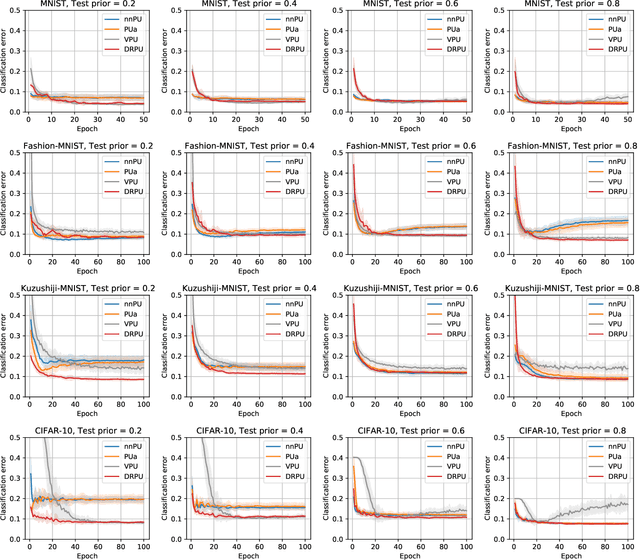
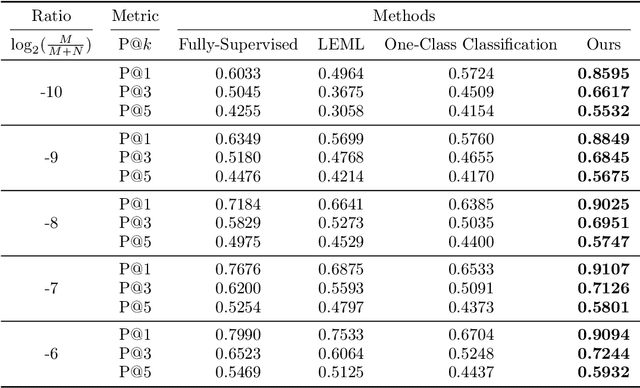
Learning from positive and unlabeled (PU) data is an important problem in various applications. Most of the recent approaches for PU classification assume that the class-prior (the ratio of positive samples) in the training unlabeled dataset is identical to that of the test data, which does not hold in many practical cases. In addition, we usually do not know the class-priors of the training and test data, thus we have no clue on how to train a classifier without them. To address these problems, we propose a novel PU classification method based on density ratio estimation. A notable advantage of our proposed method is that it does not require the class-priors in the training phase; class-prior shift is incorporated only in the test phase. We theoretically justify our proposed method and experimentally demonstrate its effectiveness.
Mediated Uncoupled Learning: Learning Functions without Direct Input-output Correspondences
Jul 16, 2021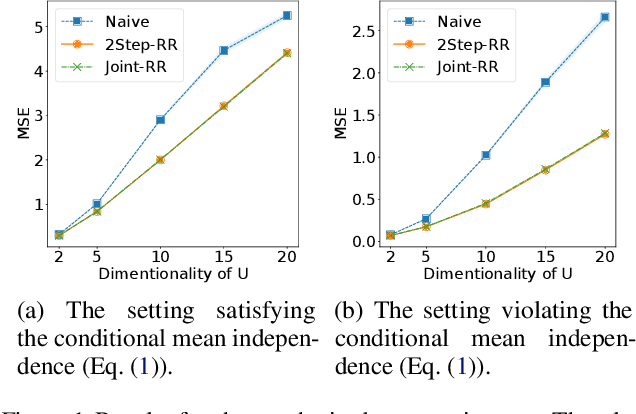
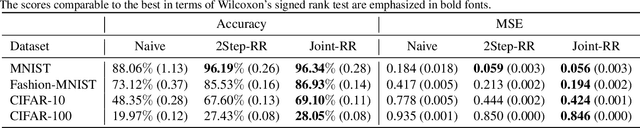
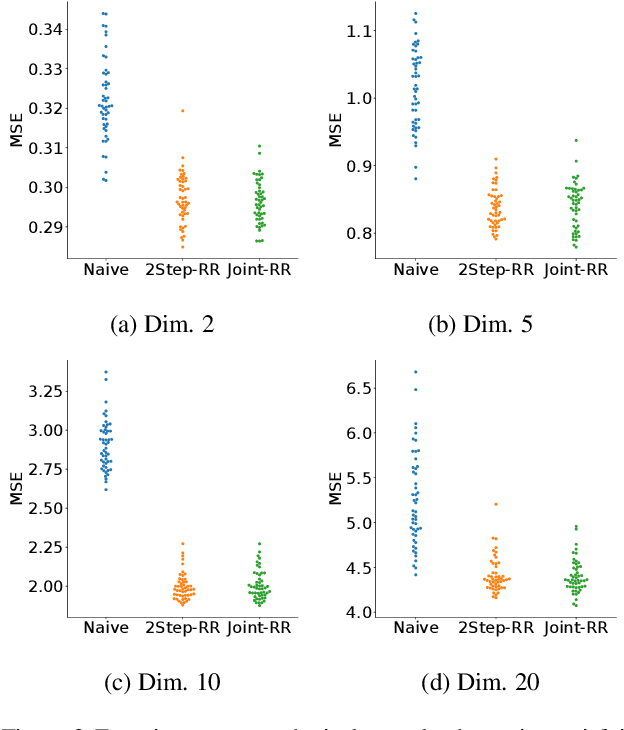
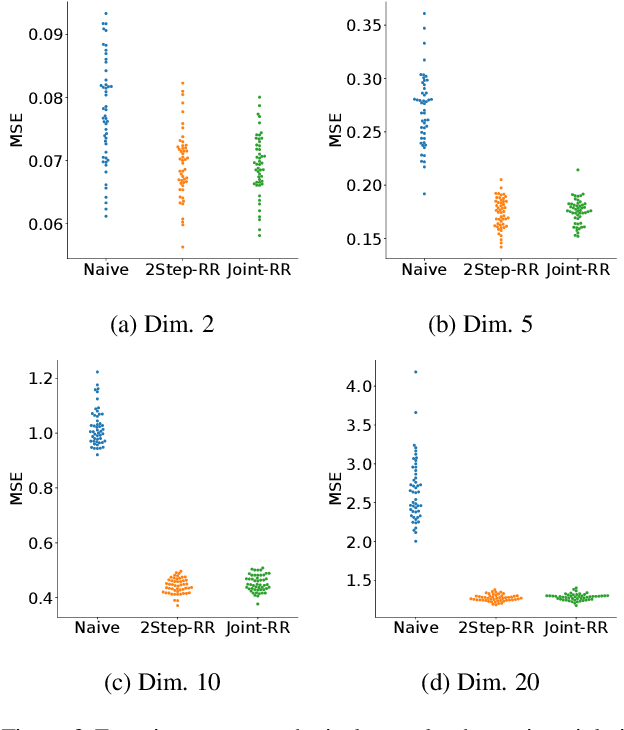
Ordinary supervised learning is useful when we have paired training data of input $X$ and output $Y$. However, such paired data can be difficult to collect in practice. In this paper, we consider the task of predicting $Y$ from $X$ when we have no paired data of them, but we have two separate, independent datasets of $X$ and $Y$ each observed with some mediating variable $U$, that is, we have two datasets $S_X = \{(X_i, U_i)\}$ and $S_Y = \{(U'_j, Y'_j)\}$. A naive approach is to predict $U$ from $X$ using $S_X$ and then $Y$ from $U$ using $S_Y$, but we show that this is not statistically consistent. Moreover, predicting $U$ can be more difficult than predicting $Y$ in practice, e.g., when $U$ has higher dimensionality. To circumvent the difficulty, we propose a new method that avoids predicting $U$ but directly learns $Y = f(X)$ by training $f(X)$ with $S_{X}$ to predict $h(U)$ which is trained with $S_{Y}$ to approximate $Y$. We prove statistical consistency and error bounds of our method and experimentally confirm its practical usefulness.
Seeing Differently, Acting Similarly: Imitation Learning with Heterogeneous Observations
Jun 17, 2021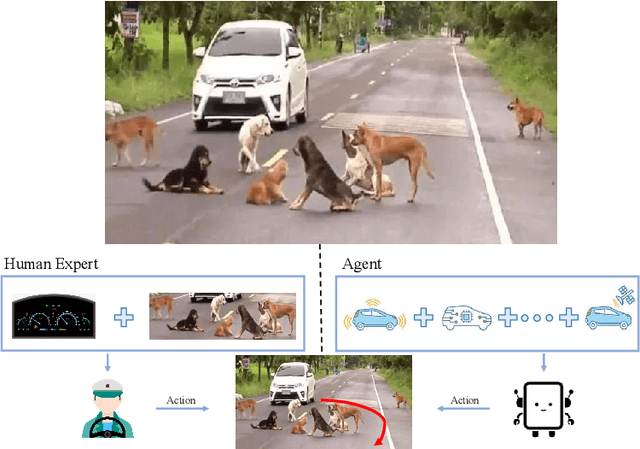
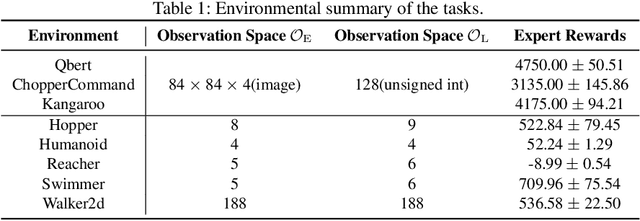
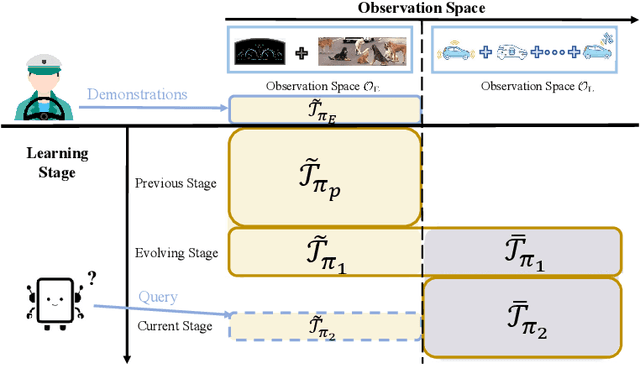
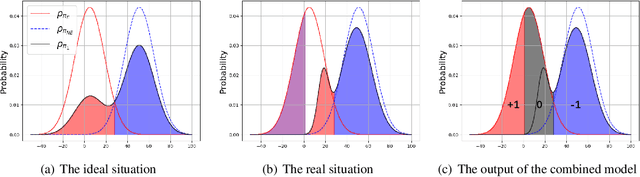
In many real-world imitation learning tasks, the demonstrator and the learner have to act in different but full observation spaces. This situation generates significant obstacles for existing imitation learning approaches to work, even when they are combined with traditional space adaptation techniques. The main challenge lies in bridging expert's occupancy measures to learner's dynamically changing occupancy measures under the different observation spaces. In this work, we model the above learning problem as Heterogeneous Observations Imitation Learning (HOIL). We propose the Importance Weighting with REjection (IWRE) algorithm based on the techniques of importance-weighting, learning with rejection, and active querying to solve the key challenge of occupancy measure matching. Experimental results show that IWRE can successfully solve HOIL tasks, including the challenging task of transforming the vision-based demonstrations to random access memory (RAM)-based policies under the Atari domain.