 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-ACT: Improving Surgical Imitation Learning Policies through Supervised Mixture-of-Experts
Jan 29, 2026Imitation learning has achieved remarkable success in robotic manipulation, yet its application to surgical robotics remains challenging due to data scarcity, constrained workspaces, and the need for an exceptional level of safety and predictability. We present a supervised Mixture-of-Experts (MoE) architecture designed for phase-structured surgical manipulation tasks, which can be added on top of any autonomous policy. Unlike prior surgical robot learning approaches that rely on multi-camera setups or thousands of demonstrations, we show that a lightweight action decoder policy like Action Chunking Transformer (ACT) can learn complex, long-horizon manipulation from less than 150 demonstrations using solely stereo endoscopic images, when equipped with our architecture. We evaluate our approach on the collaborative surgical task of bowel grasping and retraction, where a robot assistant interprets visual cues from a human surgeon, executes targeted grasping on deformable tissue, and performs sustained retraction. We benchmark our method against state-of-the-art Vision-Language-Action (VLA) models and the standard ACT baseline. Our results show that generalist VLAs fail to acquire the task entirely, even under standard in-distribution conditions. Furthermore, while standard ACT achieves moderate success in-distribution, adopting a supervised MoE architecture significantly boosts its performance, yielding higher success rates in-distribution and demonstrating superior robustness in out-of-distribution scenarios, including novel grasp locations, reduced illumination, and partial occlusions. Notably, it generalizes to unseen testing viewpoints and also transfers zero-shot to ex vivo porcine tissue without additional training, offering a promising pathway toward in vivo deployment. To support this, we present qualitative preliminary results of policy roll-outs during in vivo porcine surgery.
Federated EndoViT: Pretraining Vision Transformers via Federated Learning on Endoscopic Image Collections
Apr 23, 2025



Purpose: In this study, we investigate the training of foundation models using federated learning to address data-sharing limitations and enable collaborative model training without data transfer for minimally invasive surgery. Methods: Inspired by the EndoViT study, we adapt the Masked Autoencoder for federated learning, enhancing it with adaptive Sharpness-Aware Minimization (FedSAM) and Stochastic Weight Averaging (SWA). Our model is pretrained on the Endo700k dataset collection and later fine-tuned and evaluated for tasks such as Semantic Segmentation, Action Triplet Recognition, and Surgical Phase Recognition. Results: Our findings demonstrate that integrating adaptive FedSAM into the federated MAE approach improves pretraining, leading to a reduction in reconstruction loss per patch. The application of FL-EndoViT in surgical downstream tasks results in performance comparable to CEN-EndoViT. Furthermore, FL-EndoViT exhibits advantages over CEN-EndoViT in surgical scene segmentation when data is limited and in action triplet recognition when large datasets are used. Conclusion: These findings highlight the potential of federated learning for privacy-preserving training of surgical foundation models, offering a robust and generalizable solution for surgical data science. Effective collaboration requires adapting federated learning methods, such as the integration of FedSAM, which can accommodate the inherent data heterogeneity across institutions. In future, exploring FL in video-based models may enhance these capabilities by incorporating spatiotemporal dynamics crucial for real-world surgical environments.
Interactive Surgical Liver Phantom for Cholecystectomy Training
Sep 05, 2024



Training and prototype development in robot-assisted surgery requires appropriate and safe environments for the execution of surgical procedures. Current dry lab laparoscopy phantoms often lack the ability to mimic complex, interactive surgical tasks. This work presents an interactive surgical phantom for the cholecystectomy. The phantom enables the removal of the gallbladder during cholecystectomy by allowing manipulations and cutting interactions with the synthetic tissue. The force-displacement behavior of the gallbladder is modelled based on retraction demonstrations. The force model is compared to the force model of ex-vivo porcine gallbladders and evaluated on its ability to estimate retraction forces.
Sim-To-Real Transfer for Visual Reinforcement Learning of Deformable Object Manipulation for Robot-Assisted Surgery
Jun 10, 2024Automation holds the potential to assist surgeons in robotic interventions, shifting their mental work load from visuomotor control to high level decision making. Reinforcement learning has shown promising results in learning complex visuomotor policies, especially in simulation environments where many samples can be collected at low cost. A core challenge is learning policies in simulation that can be deployed in the real world, thereby overcoming the sim-to-real gap. In this work, we bridge the visual sim-to-real gap with an image-based reinforcement learning pipeline based on pixel-level domain adaptation and demonstrate its effectiveness on an image-based task in deformable object manipulation. We choose a tissue retraction task because of its importance in clinical reality of precise cancer surgery. After training in simulation on domain-translated images, our policy requires no retraining to perform tissue retraction with a 50% success rate on the real robotic system using raw RGB images. Furthermore, our sim-to-real transfer method makes no assumptions on the task itself and requires no paired images. This work introduces the first successful application of visual sim-to-real transfer for robotic manipulation of deformable objects in the surgical field, which represents a notable step towards the clinical translation of cognitive surgical robotics.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
LapGym -- An Open Source Framework for Reinforcement Learning in Robot-Assisted Laparoscopic Surgery
Feb 19, 2023



Recent advances in reinforcement learning (RL) have increased the promise of introducing cognitive assistance and automation to robot-assisted laparoscopic surgery (RALS). However, progress in algorithms and methods depends on the availability of standardized learning environments that represent skills relevant to RALS. We present LapGym, a framework for building RL environments for RALS that models the challenges posed by surgical tasks, and sofa_env, a diverse suite of 12 environments. Motivated by surgical training, these environments are organized into 4 tracks: Spatial Reasoning, Deformable Object Manipulation & Grasping, Dissection, and Thread Manipulation. Each environment is highly parametrizable for increasing difficulty, resulting in a high performance ceiling for new algorithms. We use Proximal Policy Optimization (PPO) to establish a baseline for model-free RL algorithms, investigating the effect of several environment parameters on task difficulty. Finally, we show that many environments and parameter configurations reflect well-known, open problems in RL research, allowing researchers to continue exploring these fundamental problems in a surgical context. We aim to provide a challenging, standard environment suite for further development of RL for RALS, ultimately helping to realize the full potential of cognitive surgical robotics. LapGym is publicly accessible through GitHub (https://github.com/ScheiklP/lap_gym).
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
LapSeg3D: Weakly Supervised Semantic Segmentation of Point Clouds Representing Laparoscopic Scenes
Jul 15, 2022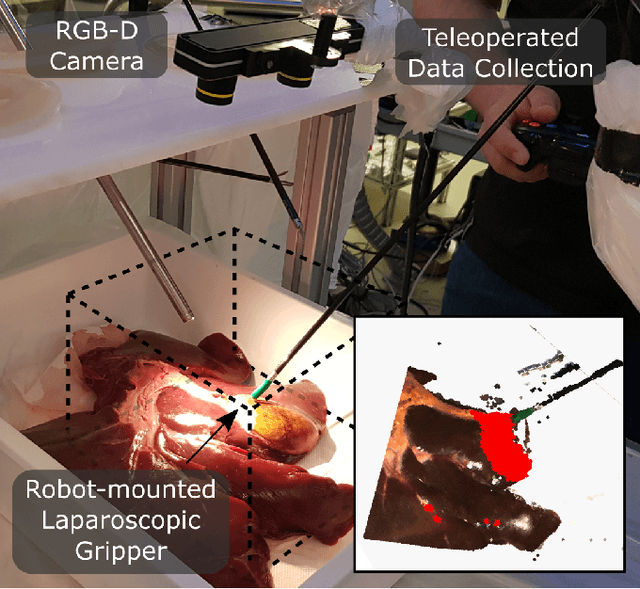
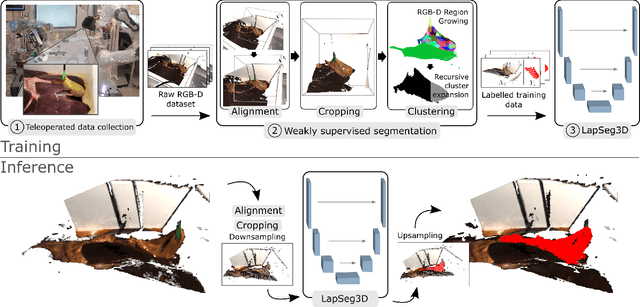
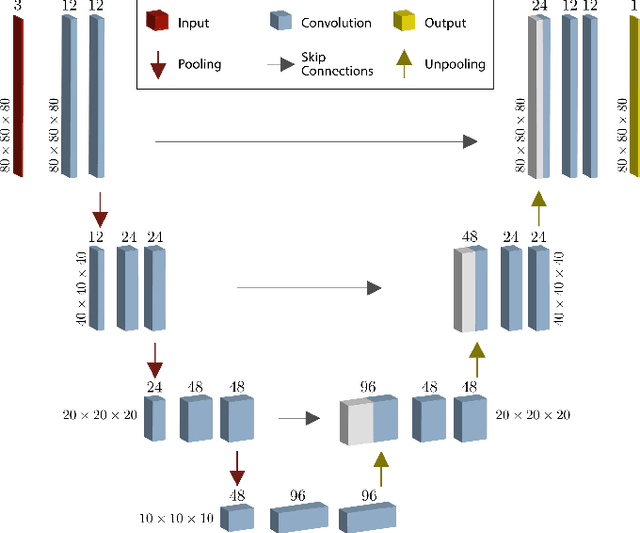

The semantic segmentation of surgical scenes is a prerequisite for task automation in robot assisted interventions. We propose LapSeg3D, a novel DNN-based approach for the voxel-wise annotation of point clouds representing surgical scenes. As the manual annotation of training data is highly time consuming, we introduce a semi-autonomous clustering-based pipeline for the annotation of the gallbladder, which is used to generate segmented labels for the DNN. When evaluated against manually annotated data, LapSeg3D achieves an F1 score of 0.94 for gallbladder segmentation on various datasets of ex-vivo porcine livers. We show LapSeg3D to generalize accurately across different gallbladders and datasets recorded with different RGB-D camera systems.
Robust deep learning-based semantic organ segmentation in hyperspectral images
Nov 09, 2021Semantic image segmentation is an important prerequisite for context-awareness and autonomous robotics in surgery. The state of the art has focused on conventional RGB video data acquired during minimally invasive surgery, but full-scene semantic segmentation based on spectral imaging data and obtained during open surgery has received almost no attention to date. To address this gap in the literature, we are investigating the following research questions based on hyperspectral imaging (HSI) data of pigs acquired in an open surgery setting: (1) What is an adequate representation of HSI data for neural network-based fully automated organ segmentation, especially with respect to the spatial granularity of the data (pixels vs. superpixels vs. patches vs. full images)? (2) Is there a benefit of using HSI data compared to other modalities, namely RGB data and processed HSI data (e.g. tissue parameters like oxygenation), when performing semantic organ segmentation? According to a comprehensive validation study based on 506 HSI images from 20 pigs, annotated with a total of 19 classes, deep learning-based segmentation performance increases - consistently across modalities - with the spatial context of the input data. Unprocessed HSI data offers an advantage over RGB data or processed data from the camera provider, with the advantage increasing with decreasing size of the input to the neural network. Maximum performance (HSI applied to whole images) yielded a mean dice similarity coefficient (DSC) of 0.89 (standard deviation (SD) 0.04), which is in the range of the inter-rater variability (DSC of 0.89 (SD 0.07)). We conclude that HSI could become a powerful image modality for fully-automatic surgical scene understanding with many advantages over traditional imaging, including the ability to recover additional functional tissue information.
Cooperative Assistance in Robotic Surgery through Multi-Agent Reinforcement Learning
Oct 10, 2021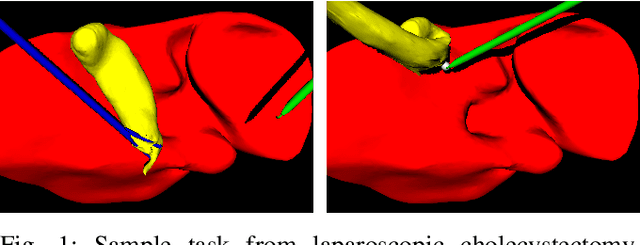

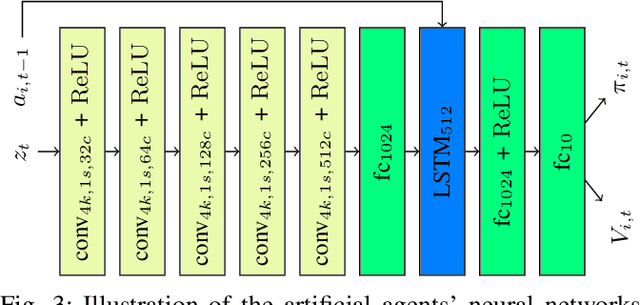
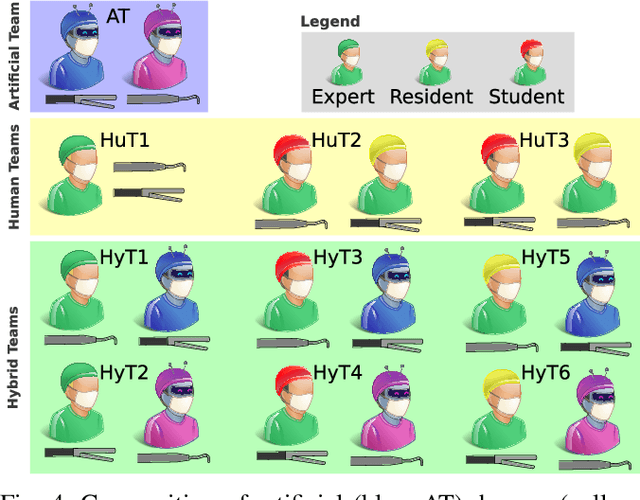
Cognitive cooperative assistance in robot-assisted surgery holds the potential to increase quality of care in minimally invasive interventions. Automation of surgical tasks promises to reduce the mental exertion and fatigue of surgeons. In this work, multi-agent reinforcement learning is demonstrated to be robust to the distribution shift introduced by pairing a learned policy with a human team member. Multi-agent policies are trained directly from images in simulation to control multiple instruments in a sub task of the minimally invasive removal of the gallbladder. These agents are evaluated individually and in cooperation with humans to demonstrate their suitability as autonomous assistants. Compared to human teams, the hybrid teams with artificial agents perform better considering completion time (44.4% to 71.2% shorter) as well as number of collisions (44.7% to 98.0% fewer). Path lengths, however, increase under control of an artificial agent (11.4% to 33.5% longer). A multi-agent formulation of the learning problem was favored over a single-agent formulation on this surgical sub task, due to the sequential learning of the two instruments. This approach may be extended to other tasks that are difficult to formulate within the standard reinforcement learning framework. Multi-agent reinforcement learning may shift the paradigm of cognitive robotic surgery towards seamless cooperation between surgeons and assistive technologies.