 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Select the Best Forecasting Tasks for Clinical Outcome Prediction
Jul 28, 2024



We propose to meta-learn an a self-supervised patient trajectory forecast learning rule by meta-training on a meta-objective that directly optimizes the utility of the patient representation over the subsequent clinical outcome prediction. This meta-objective directly targets the usefulness of a representation generated from unlabeled clinical measurement forecast for later supervised tasks. The meta-learned can then be directly used in target risk prediction, and the limited available samples can be used for further fine-tuning the model performance. The effectiveness of our approach is tested on a real open source patient EHR dataset MIMIC-III. We are able to demonstrate that our attention-based patient state representation approach can achieve much better performance for predicting target risk with low resources comparing with both direct supervised learning and pretraining with all-observation trajectory forecast.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
Instability in clinical risk stratification models using deep learning
Nov 20, 2022



While it has been well known in the ML community that deep learning models suffer from instability, the consequences for healthcare deployments are under characterised. We study the stability of different model architectures trained on electronic health records, using a set of outpatient prediction tasks as a case study. We show that repeated training runs of the same deep learning model on the same training data can result in significantly different outcomes at a patient level even though global performance metrics remain stable. We propose two stability metrics for measuring the effect of randomness of model training, as well as mitigation strategies for improving model stability.
Boosting the interpretability of clinical risk scores with intervention predictions
Jul 06, 2022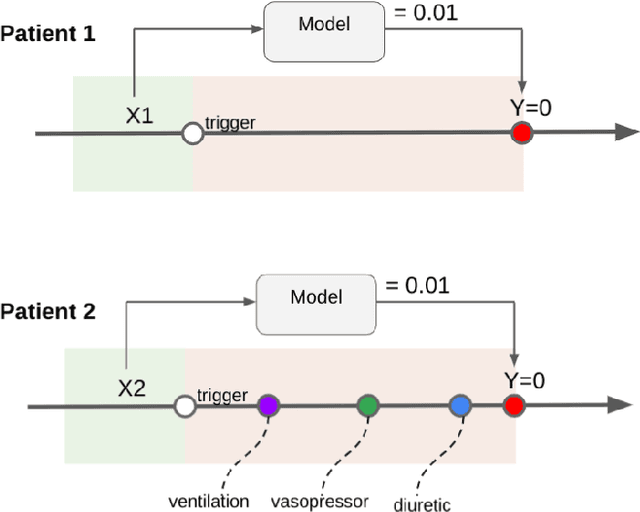
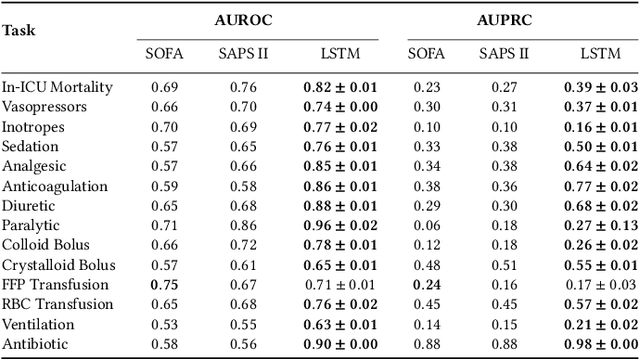
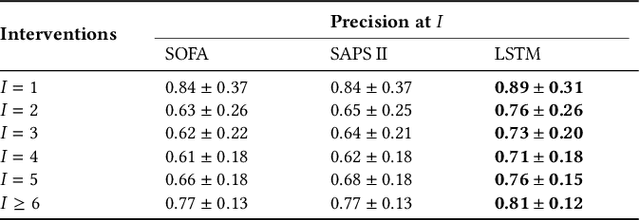
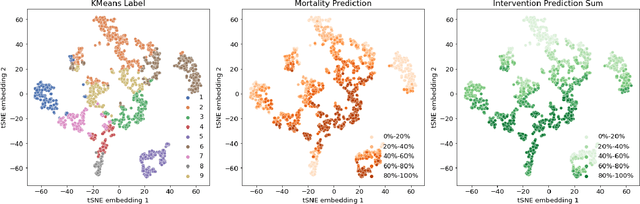
Machine learning systems show significant promise for forecasting patient adverse events via risk scores. However, these risk scores implicitly encode assumptions about future interventions that the patient is likely to receive, based on the intervention policy present in the training data. Without this important context, predictions from such systems are less interpretable for clinicians. We propose a joint model of intervention policy and adverse event risk as a means to explicitly communicate the model's assumptions about future interventions. We develop such an intervention policy model on MIMIC-III, a real world de-identified ICU dataset, and discuss some use cases that highlight the utility of this approach. We show how combining typical risk scores, such as the likelihood of mortality, with future intervention probability scores leads to more interpretable clinical predictions.
BEDS-Bench: Behavior of EHR-models under Distributional Shift--A Benchmark
Jul 17, 2021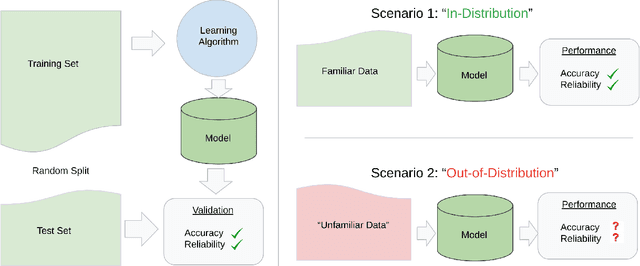
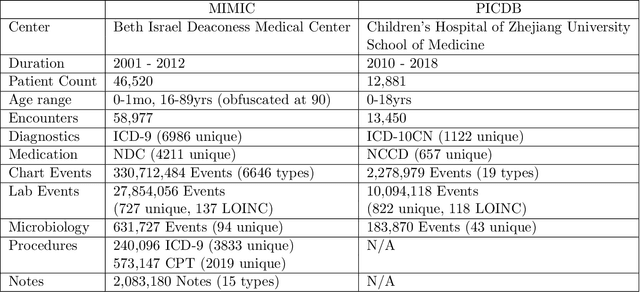
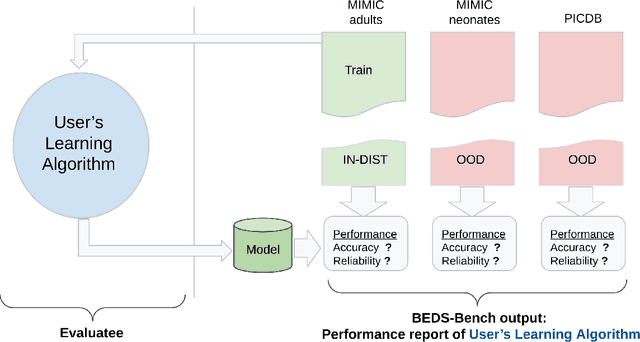
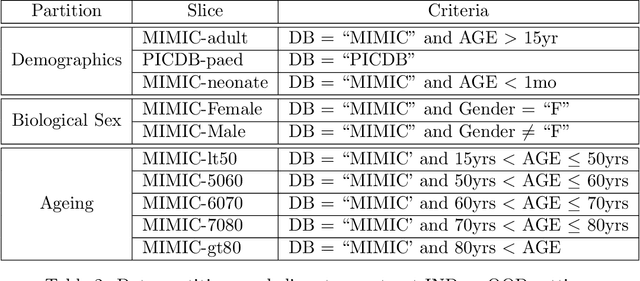
Machine learning has recently demonstrated impressive progress in predictive accuracy across a wide array of tasks. Most ML approaches focus on generalization performance on unseen data that are similar to the training data (In-Distribution, or IND). However, real world applications and deployments of ML rarely enjoy the comfort of encountering examples that are always IND. In such situations, most ML models commonly display erratic behavior on Out-of-Distribution (OOD) examples, such as assigning high confidence to wrong predictions, or vice-versa. Implications of such unusual model behavior are further exacerbated in the healthcare setting, where patient health can potentially be put at risk. It is crucial to study the behavior and robustness properties of models under distributional shift, understand common failure modes, and take mitigation steps before the model is deployed. Having a benchmark that shines light upon these aspects of a model is a first and necessary step in addressing the issue. Recent work and interest in increasing model robustness in OOD settings have focused more on image modality, while the Electronic Health Record (EHR) modality is still largely under-explored. We aim to bridge this gap by releasing BEDS-Bench, a benchmark for quantifying the behavior of ML models over EHR data under OOD settings. We use two open access, de-identified EHR datasets to construct several OOD data settings to run tests on, and measure relevant metrics that characterize crucial aspects of a model's OOD behavior. We evaluate several learning algorithms under BEDS-Bench and find that all of them show poor generalization performance under distributional shift in general. Our results highlight the need and the potential to improve robustness of EHR models under distributional shift, and BEDS-Bench provides one way to measure progress towards that goal.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.