 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Aided Trajectory Planning for Automated Vehicles through Teleoperation and Arbitration Graphs
Feb 04, 2025



Teleoperation enables remote human support of automated vehicles in scenarios where the automation is not able to find an appropriate solution. Remote assistance concepts, where operators provide discrete inputs to aid specific automation modules like planning, is gaining interest due to its reduced workload on the human remote operator and improved safety. However, these concepts are challenging to implement and maintain due to their deep integration and interaction with the automated driving system. In this paper, we propose a solution to facilitate the implementation of remote assistance concepts that intervene on planning level and extend the operational design domain of the vehicle at runtime. Using arbitration graphs, a modular decision-making framework, we integrate remote assistance into an existing automated driving system without modifying the original software components. Our simulative implementation demonstrates this approach in two use cases, allowing operators to adjust planner constraints and enable trajectory generation beyond nominal operational design domains.
Better Safe Than Sorry: Enhancing Arbitration Graphs for Safe and Robust Autonomous Decision-Making
Nov 15, 2024



This paper introduces an extension to the arbitration graph framework designed to enhance the safety and robustness of autonomous systems in complex, dynamic environments. Building on the flexibility and scalability of arbitration graphs, the proposed method incorporates a verification step and structured fallback layers in the decision-making process. This ensures that only verified and safe commands are executed while enabling graceful degradation in the presence of unexpected faults or bugs. The approach is demonstrated using a Pac-Man simulation and further validated in the context of autonomous driving, where it shows significant reductions in accident risk and improvements in overall system safety. The bottom-up design of arbitration graphs allows for an incremental integration of new behavior components. The extension presented in this work enables the integration of experimental or immature behavior components while maintaining system safety by clearly and precisely defining the conditions under which behaviors are considered safe. The proposed method is implemented as a ready to use header-only C++ library, published under the MIT License. Together with the Pac-Man demo, it is available at github.com/KIT-MRT/arbitration_graphs.
Adversarial Attacked Teacher for Unsupervised Domain Adaptive Object Detection
Aug 18, 2024



Object detectors encounter challenges in handling domain shifts. Cutting-edge domain adaptive object detection methods use the teacher-student framework and domain adversarial learning to generate domain-invariant pseudo-labels for self-training. However, the pseudo-labels generated by the teacher model tend to be biased towards the majority class and often mistakenly include overconfident false positives and underconfident false negatives. We reveal that pseudo-labels vulnerable to adversarial attacks are more likely to be low-quality. To address this, we propose a simple yet effective framework named Adversarial Attacked Teacher (AAT) to improve the quality of pseudo-labels. Specifically, we apply adversarial attacks to the teacher model, prompting it to generate adversarial pseudo-labels to correct bias, suppress overconfidence, and encourage underconfident proposals. An adaptive pseudo-label regularization is introduced to emphasize the influence of pseudo-labels with high certainty and reduce the negative impacts of uncertain predictions. Moreover, robust minority objects verified by pseudo-label regularization are oversampled to minimize dataset imbalance without introducing false positives. Extensive experiments conducted on various datasets demonstrate that AAT achieves superior performance, reaching 52.6 mAP on Clipart1k, surpassing the previous state-of-the-art by 6.7%.
An Approach to Systematic Data Acquisition and Data-Driven Simulation for the Safety Testing of Automated Driving Functions
May 02, 2024



With growing complexity and criticality of automated driving functions in road traffic and their operational design domains (ODD), there is increasing demand for covering significant proportions of development, validation, and verification in virtual environments and through simulation models. If, however, simulations are meant not only to augment real-world experiments, but to replace them, quantitative approaches are required that measure to what degree and under which preconditions simulation models adequately represent reality, and thus, using their results accordingly. Especially in R&D areas related to the safety impact of the "open world", there is a significant shortage of real-world data to parameterize and/or validate simulations - especially with respect to the behavior of human traffic participants, whom automated driving functions will meet in mixed traffic. We present an approach to systematically acquire data in public traffic by heterogeneous means, transform it into a unified representation, and use it to automatically parameterize traffic behavior models for use in data-driven virtual validation of automated driving functions.
Adversarial Defense Teacher for Cross-Domain Object Detection under Poor Visibility Conditions
Mar 23, 2024



Existing object detectors encounter challenges in handling domain shifts between training and real-world data, particularly under poor visibility conditions like fog and night. Cutting-edge cross-domain object detection methods use teacher-student frameworks and compel teacher and student models to produce consistent predictions under weak and strong augmentations, respectively. In this paper, we reveal that manually crafted augmentations are insufficient for optimal teaching and present a simple yet effective framework named Adversarial Defense Teacher (ADT), leveraging adversarial defense to enhance teaching quality. Specifically, we employ adversarial attacks, encouraging the model to generalize on subtly perturbed inputs that effectively deceive the model. To address small objects under poor visibility conditions, we propose a Zoom-in Zoom-out strategy, which zooms-in images for better pseudo-labels and zooms-out images and pseudo-labels to learn refined features. Our results demonstrate that ADT achieves superior performance, reaching 54.5% mAP on Foggy Cityscapes, surpassing the previous state-of-the-art by 2.6% mAP.
PITA: Physics-Informed Trajectory Autoencoder
Mar 18, 2024Validating robotic systems in safety-critical appli-cations requires testing in many scenarios including rare edgecases that are unlikely to occur, requiring to complement real-world testing with testing in simulation. Generative models canbe used to augment real-world datasets with generated data toproduce edge case scenarios by sampling in a learned latentspace. Autoencoders can learn said latent representation for aspecific domain by learning to reconstruct the input data froma lower-dimensional intermediate representation. However, theresulting trajectories are not necessarily physically plausible, butinstead typically contain noise that is not present in the inputtrajectory. To resolve this issue, we propose the novel Physics-Informed Trajectory Autoencoder (PITA) architecture, whichincorporates a physical dynamics model into the loss functionof the autoencoder. This results in smooth trajectories that notonly reconstruct the input trajectory but also adhere to thephysical model. We evaluate PITA on a real-world dataset ofvehicle trajectories and compare its performance to a normalautoencoder and a state-of-the-art action-space autoencoder.
LDFA: Latent Diffusion Face Anonymization for Self-driving Applications
Feb 17, 2023



In order to protect vulnerable road users (VRUs), such as pedestrians or cyclists, it is essential that intelligent transportation systems (ITS) accurately identify them. Therefore, datasets used to train perception models of ITS must contain a significant number of vulnerable road users. However, data protection regulations require that individuals are anonymized in such datasets. In this work, we introduce a novel deep learning-based pipeline for face anonymization in the context of ITS. In contrast to related methods, we do not use generative adversarial networks (GANs) but build upon recent advances in diffusion models. We propose a two-stage method, which contains a face detection model followed by a latent diffusion model to generate realistic face in-paintings. To demonstrate the versatility of anonymized images, we train segmentation methods on anonymized data and evaluate them on non-anonymized data. Our experiment reveal that our pipeline is better suited to anonymize data for segmentation than naive methods and performes comparably with recent GAN-based methods. Moreover, face detectors achieve higher mAP scores for faces anonymized by our method compared to naive or recent GAN-based methods.
High-level Decisions from a Safe Maneuver Catalog with Reinforcement Learning for Safe and Cooperative Automated Merging
Jul 15, 2021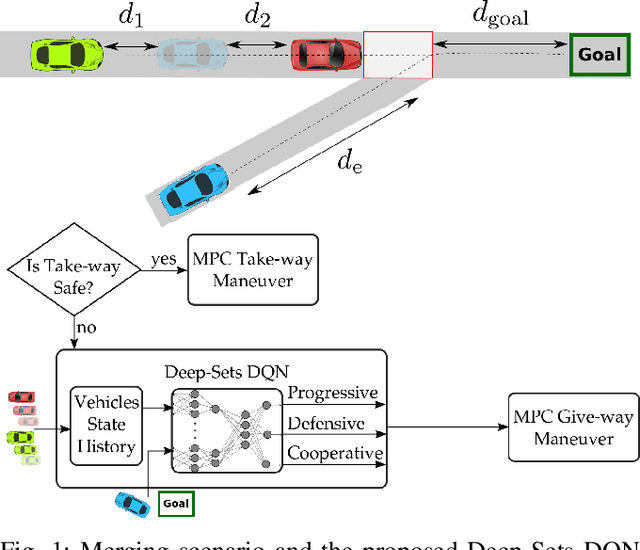
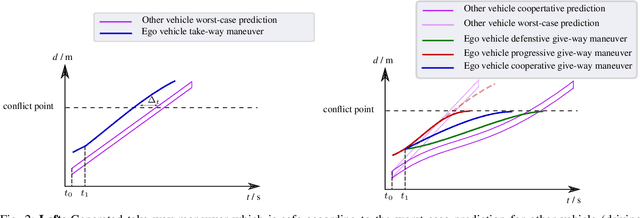
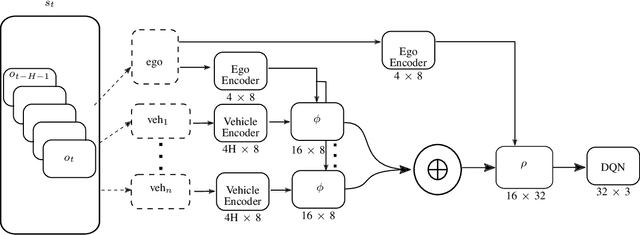
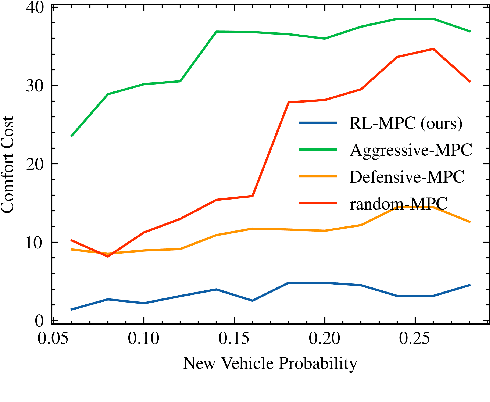
Reinforcement learning (RL) has recently been used for solving challenging decision-making problems in the context of automated driving. However, one of the main drawbacks of the presented RL-based policies is the lack of safety guarantees, since they strive to reduce the expected number of collisions but still tolerate them. In this paper, we propose an efficient RL-based decision-making pipeline for safe and cooperative automated driving in merging scenarios. The RL agent is able to predict the current situation and provide high-level decisions, specifying the operation mode of the low level planner which is responsible for safety. In order to learn a more generic policy, we propose a scalable RL architecture for the merging scenario that is not sensitive to changes in the environment configurations. According to our experiments, the proposed RL agent can efficiently identify cooperative drivers from their vehicle state history and generate interactive maneuvers, resulting in faster and more comfortable automated driving. At the same time, thanks to the safety constraints inside the planner, all of the maneuvers are collision free and safe.
Efficient Sampling in POMDPs with Lipschitz Bandits for Motion Planning in Continuous Spaces
Jun 08, 2021
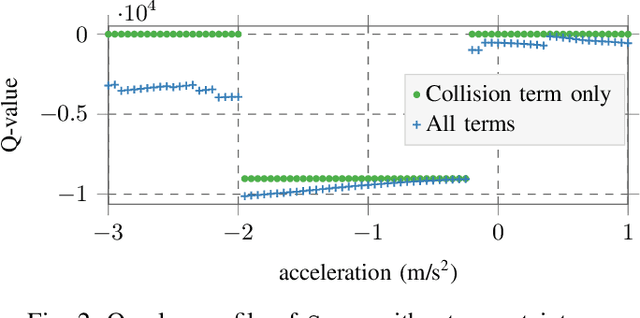
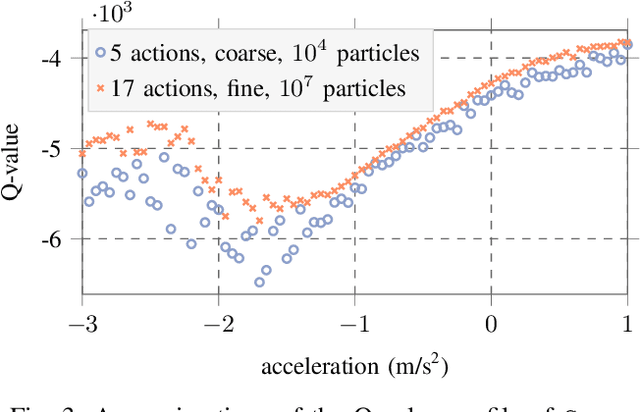
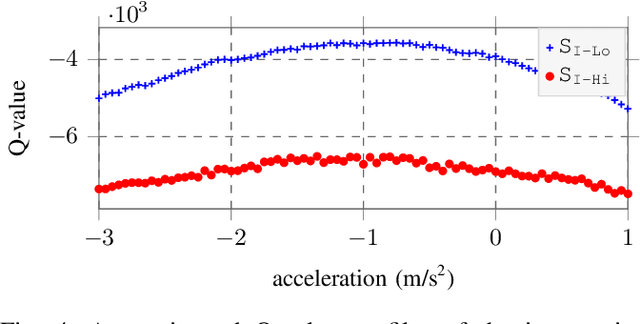
Decision making under uncertainty can be framed as a partially observable Markov decision process (POMDP). Finding exact solutions of POMDPs is generally computationally intractable, but the solution can be approximated by sampling-based approaches. These sampling-based POMDP solvers rely on multi-armed bandit (MAB) heuristics, which assume the outcomes of different actions to be uncorrelated. In some applications, like motion planning in continuous spaces, similar actions yield similar outcomes. In this paper, we utilize variants of MAB heuristics that make Lipschitz continuity assumptions on the outcomes of actions to improve the efficiency of sampling-based planning approaches. We demonstrate the effectiveness of this approach in the context of motion planning for automated driving.
Fast Lane-Level Intersection Estimation using Markov Chain Monte Carlo Sampling and B-Spline Refinement
Jul 14, 2020
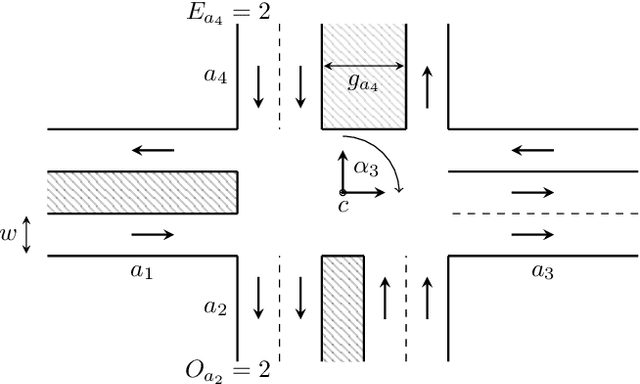
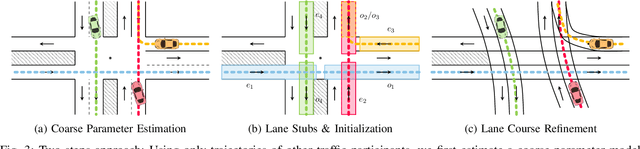
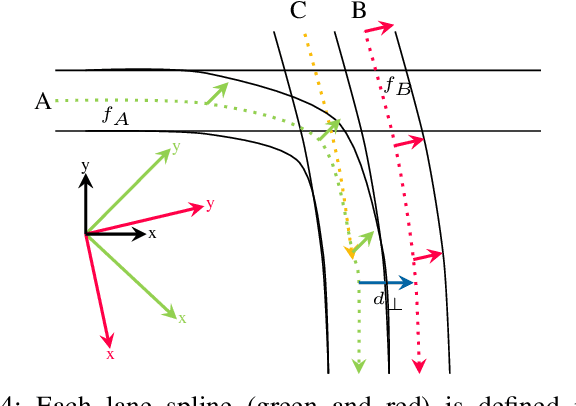
Estimating the current scene and understanding the potential maneuvers are essential capabilities of automated vehicles. Most approaches rely heavily on the correctness of maps, but neglect the possibility of outdated information. We present an approach that is able to estimate lanes without relying on any map prior. The estimation is based solely on the trajectories of other traffic participants and is thereby able to incorporate complex environments. In particular, we are able to estimate the scene in the presence of heavy traffic and occlusions. The algorithm first estimates a coarse lane-level intersection model by Markov chain Monte Carlo sampling and refines it later by aligning the lane course with the measurements using a non-linear least squares formulation. We model the lanes as 1D cubic B-splines and can achieve error rates of less than 10cm within real-time.