 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Inductive Biases in Transformers without Message Passing
May 27, 2023



Transformers for graph data are increasingly widely studied and successful in numerous learning tasks. Graph inductive biases are crucial for Graph Transformers, and previous works incorporate them using message-passing modules and/or positional encodings. However, Graph Transformers that use message-passing inherit known issues of message-passing, and differ significantly from Transformers used in other domains, thus making transfer of research advances more difficult. On the other hand, Graph Transformers without message-passing often perform poorly on smaller datasets, where inductive biases are more crucial. To bridge this gap, we propose the Graph Inductive bias Transformer (GRIT) -- a new Graph Transformer that incorporates graph inductive biases without using message passing. GRIT is based on several architectural changes that are each theoretically and empirically justified, including: learned relative positional encodings initialized with random walk probabilities, a flexible attention mechanism that updates node and node-pair representations, and injection of degree information in each layer. We prove that GRIT is expressive -- it can express shortest path distances and various graph propagation matrices. GRIT achieves state-of-the-art empirical performance across a variety of graph datasets, thus showing the power that Graph Transformers without message-passing can deliver.
Structure Aware Incremental Learning with Personalized Imitation Weights for Recommender Systems
May 02, 2023



Recommender systems now consume large-scale data and play a significant role in improving user experience. Graph Neural Networks (GNNs) have emerged as one of the most effective recommender system models because they model the rich relational information. The ever-growing volume of data can make training GNNs prohibitively expensive. To address this, previous attempts propose to train the GNN models incrementally as new data blocks arrive. Feature and structure knowledge distillation techniques have been explored to allow the GNN model to train in a fast incremental fashion while alleviating the catastrophic forgetting problem. However, preserving the same amount of the historical information for all users is sub-optimal since it fails to take into account the dynamics of each user's change of preferences. For the users whose interests shift substantially, retaining too much of the old knowledge can overly constrain the model, preventing it from quickly adapting to the users' novel interests. In contrast, for users who have static preferences, model performance can benefit greatly from preserving as much of the user's long-term preferences as possible. In this work, we propose a novel training strategy that adaptively learns personalized imitation weights for each user to balance the contribution from the recent data and the amount of knowledge to be distilled from previous time periods. We demonstrate the effectiveness of learning imitation weights via a comparison on five diverse datasets for three state-of-art structure distillation based recommender systems. The performance shows consistent improvement over competitive incremental learning techninques.
Diffusing Gaussian Mixtures for Generating Categorical Data
Mar 08, 2023



Learning a categorical distribution comes with its own set of challenges. A successful approach taken by state-of-the-art works is to cast the problem in a continuous domain to take advantage of the impressive performance of the generative models for continuous data. Amongst them are the recently emerging diffusion probabilistic models, which have the observed advantage of generating high-quality samples. Recent advances for categorical generative models have focused on log likelihood improvements. In this work, we propose a generative model for categorical data based on diffusion models with a focus on high-quality sample generation, and propose sampled-based evaluation methods. The efficacy of our method stems from performing diffusion in the continuous domain while having its parameterization informed by the structure of the categorical nature of the target distribution. Our method of evaluation highlights the capabilities and limitations of different generative models for generating categorical data, and includes experiments on synthetic and real-world protein datasets.
Spectral Augmentations for Graph Contrastive Learning
Feb 06, 2023



Contrastive learning has emerged as a premier method for learning representations with or without supervision. Recent studies have shown its utility in graph representation learning for pre-training. Despite successes, the understanding of how to design effective graph augmentations that can capture structural properties common to many different types of downstream graphs remains incomplete. We propose a set of well-motivated graph transformation operations derived via graph spectral analysis to provide a bank of candidates when constructing augmentations for a graph contrastive objective, enabling contrastive learning to capture useful structural representation from pre-training graph datasets. We first present a spectral graph cropping augmentation that involves filtering nodes by applying thresholds to the eigenvalues of the leading Laplacian eigenvectors. Our second novel augmentation reorders the graph frequency components in a structural Laplacian-derived position graph embedding. Further, we introduce a method that leads to improved views of local subgraphs by performing alignment via global random walk embeddings. Our experimental results indicate consistent improvements in out-of-domain graph data transfer compared to state-of-the-art graph contrastive learning methods, shedding light on how to design a graph learner that is able to learn structural properties common to diverse graph types.
Neighbor Auto-Grouping Graph Neural Networks for Handover Parameter Configuration in Cellular Network
Dec 29, 2022



The mobile communication enabled by cellular networks is the one of the main foundations of our modern society. Optimizing the performance of cellular networks and providing massive connectivity with improved coverage and user experience has a considerable social and economic impact on our daily life. This performance relies heavily on the configuration of the network parameters. However, with the massive increase in both the size and complexity of cellular networks, network management, especially parameter configuration, is becoming complicated. The current practice, which relies largely on experts' prior knowledge, is not adequate and will require lots of domain experts and high maintenance costs. In this work, we propose a learning-based framework for handover parameter configuration. The key challenge, in this case, is to tackle the complicated dependencies between neighboring cells and jointly optimize the whole network. Our framework addresses this challenge in two ways. First, we introduce a novel approach to imitate how the network responds to different network states and parameter values, called auto-grouping graph convolutional network (AG-GCN). During the parameter configuration stage, instead of solving the global optimization problem, we design a local multi-objective optimization strategy where each cell considers several local performance metrics to balance its own performance and its neighbors. We evaluate our proposed algorithm via a simulator constructed using real network data. We demonstrate that the handover parameters our model can find, achieve better average network throughput compared to those recommended by experts as well as alternative baselines, which can bring better network quality and stability. It has the potential to massively reduce costs arising from human expert intervention and maintenance.
Intent-aware Multi-source Contrastive Alignment for Tag-enhanced Recommendation
Nov 11, 2022To offer accurate and diverse recommendation services, recent methods use auxiliary information to foster the learning process of user and item representations. Many SOTA methods fuse different sources of information (user, item, knowledge graph, tags, etc.) into a graph and use Graph Neural Networks to introduce the auxiliary information through the message passing paradigm. In this work, we seek an alternative framework that is light and effective through self-supervised learning across different sources of information, particularly for the commonly accessible item tag information. We use a self-supervision signal to pair users with the auxiliary information associated with the items they have interacted with before. To achieve the pairing, we create a proxy training task. For a given item, the model predicts the correct pairing between the representations obtained from the users that have interacted with this item and the assigned tags. This design provides an efficient solution, using the auxiliary information directly to enhance the quality of user and item embeddings. User behavior in recommendation systems is driven by the complex interactions of many factors behind the decision-making processes. To make the pairing process more fine-grained and avoid embedding collapse, we propose an intent-aware self-supervised pairing process where we split the user embeddings into multiple sub-embedding vectors. Each sub-embedding vector captures a specific user intent via self-supervised alignment with a particular cluster of tags. We integrate our designed framework with various recommendation models, demonstrating its flexibility and compatibility. Through comparison with numerous SOTA methods on seven real-world datasets, we show that our method can achieve better performance while requiring less training time. This indicates the potential of applying our approach on web-scale datasets.
DyG2Vec: Representation Learning for Dynamic Graphs with Self-Supervision
Oct 30, 2022



The challenge in learning from dynamic graphs for predictive tasks lies in extracting fine-grained temporal motifs from an ever-evolving graph. Moreover, task labels are often scarce, costly to obtain, and highly imbalanced for large dynamic graphs. Recent advances in self-supervised learning on graphs demonstrate great potential, but focus on static graphs. State-of-the-art (SoTA) models for dynamic graphs are not only incompatible with the self-supervised learning (SSL) paradigm but also fail to forecast interactions beyond the very near future. To address these limitations, we present DyG2Vec, an SSL-compatible, efficient model for representation learning on dynamic graphs. DyG2Vec uses a window-based mechanism to generate task-agnostic node embeddings that can be used to forecast future interactions. DyG2Vec significantly outperforms SoTA baselines on benchmark datasets for downstream tasks while only requiring a fraction of the training/inference time. We adapt two SSL evaluation mechanisms to make them applicable to dynamic graphs and thus show that SSL pre-training helps learn more robust temporal node representations, especially for scenarios with few labels.
Evaluation of Categorical Generative Models -- Bridging the Gap Between Real and Synthetic Data
Oct 28, 2022



The machine learning community has mainly relied on real data to benchmark algorithms as it provides compelling evidence of model applicability. Evaluation on synthetic datasets can be a powerful tool to provide a better understanding of a model's strengths, weaknesses, and overall capabilities. Gaining these insights can be particularly important for generative modeling as the target quantity is completely unknown. Multiple issues related to the evaluation of generative models have been reported in the literature. We argue those problems can be avoided by an evaluation based on ground truth. General criticisms of synthetic experiments are that they are too simplified and not representative of practical scenarios. As such, our experimental setting is tailored to a realistic generative task. We focus on categorical data and introduce an appropriately scalable evaluation method. Our method involves tasking a generative model to learn a distribution in a high-dimensional setting. We then successively bin the large space to obtain smaller probability spaces where meaningful statistical tests can be applied. We consider increasingly large probability spaces, which correspond to increasingly difficult modeling tasks and compare the generative models based on the highest task difficulty they can reach before being detected as being too far from the ground truth. We validate our evaluation procedure with synthetic experiments on both synthetic generative models and current state-of-the-art categorical generative models.
Contrastive Learning for Time Series on Dynamic Graphs
Sep 21, 2022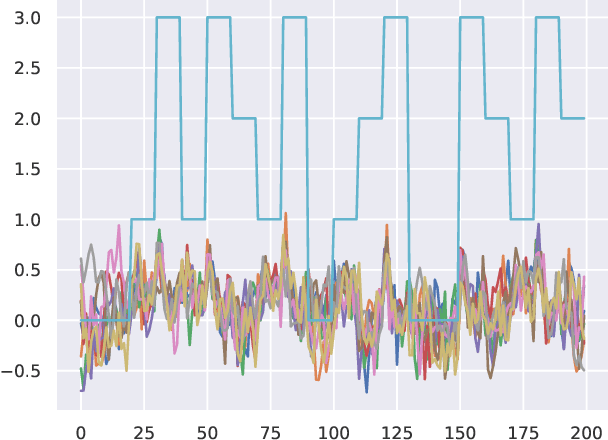
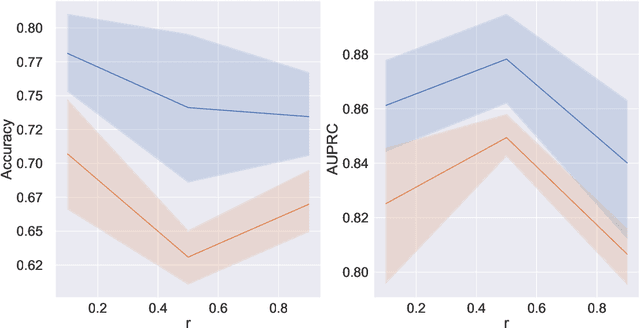
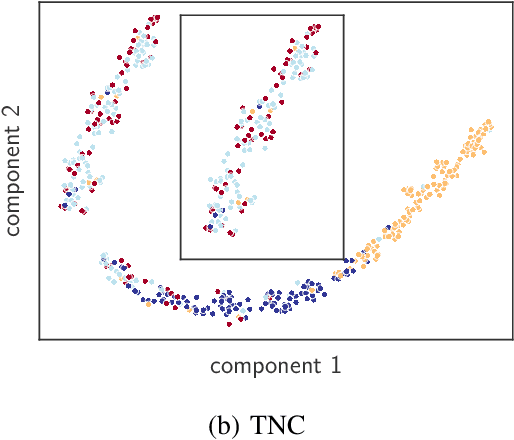

There have been several recent efforts towards developing representations for multivariate time-series in an unsupervised learning framework. Such representations can prove beneficial in tasks such as activity recognition, health monitoring, and anomaly detection. In this paper, we consider a setting where we observe time-series at each node in a dynamic graph. We propose a framework called GraphTNC for unsupervised learning of joint representations of the graph and the time-series. Our approach employs a contrastive learning strategy. Based on an assumption that the time-series and graph evolution dynamics are piecewise smooth, we identify local windows of time where the signals exhibit approximate stationarity. We then train an encoding that allows the distribution of signals within a neighborhood to be distinguished from the distribution of non-neighboring signals. We first demonstrate the performance of our proposed framework using synthetic data, and subsequently we show that it can prove beneficial for the classification task with real-world datasets.
Adapting Triplet Importance of Implicit Feedback for Personalized Recommendation
Aug 05, 2022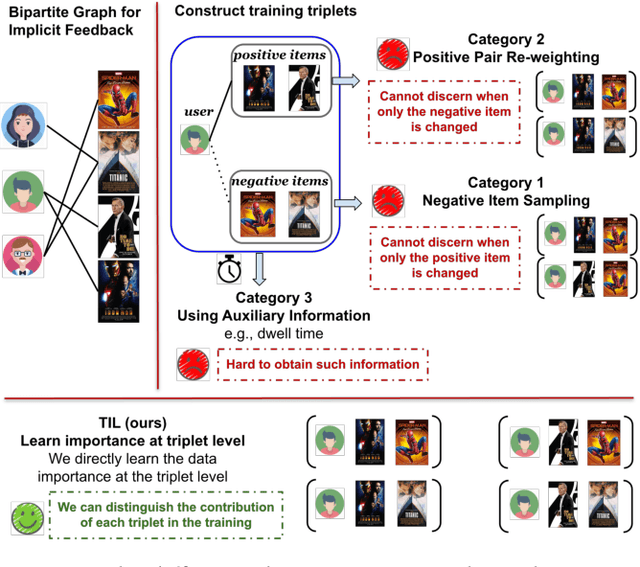
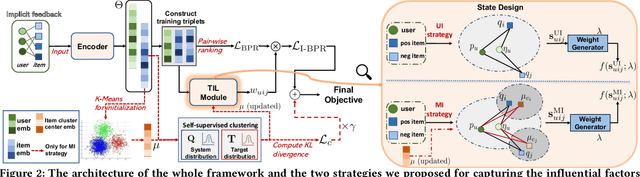
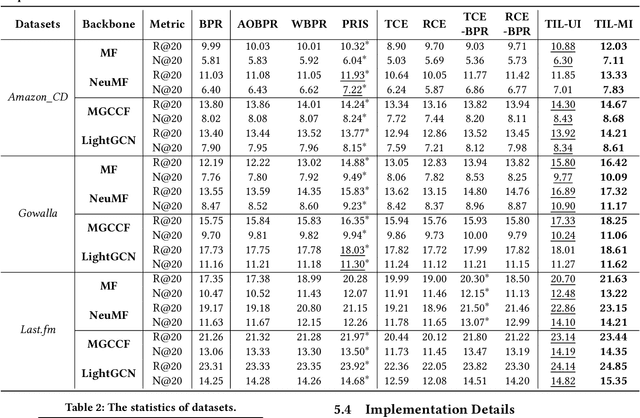
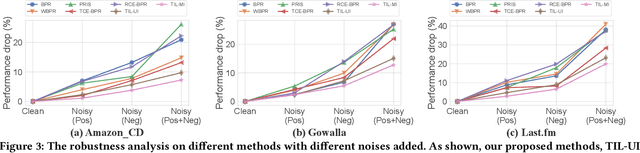
Implicit feedback is frequently used for developing personalized recommendation services due to its ubiquity and accessibility in real-world systems. In order to effectively utilize such information, most research adopts the pairwise ranking method on constructed training triplets (user, positive item, negative item) and aims to distinguish between positive items and negative items for each user. However, most of these methods treat all the training triplets equally, which ignores the subtle difference between different positive or negative items. On the other hand, even though some other works make use of the auxiliary information (e.g., dwell time) of user behaviors to capture this subtle difference, such auxiliary information is hard to obtain. To mitigate the aforementioned problems, we propose a novel training framework named Triplet Importance Learning (TIL), which adaptively learns the importance score of training triplets. We devise two strategies for the importance score generation and formulate the whole procedure as a bilevel optimization, which does not require any rule-based design. We integrate the proposed training procedure with several Matrix Factorization (MF)- and Graph Neural Network (GNN)-based recommendation models, demonstrating the compatibility of our framework. Via a comparison using three real-world datasets with many state-of-the-art methods, we show that our proposed method outperforms the best existing models by 3-21\% in terms of Recall@k for the top-k recommendation.