 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Apr 09, 2024



Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data. Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
What explains the success of cross-modal fine-tuning with ORCA?
Mar 20, 2024



ORCA (Shen et al., 2023) is a recent technique for cross-modal fine-tuning, i.e., applying pre-trained transformer models to modalities beyond their training data. The technique consists primarily of training an embedder and fine-tuning the embedder and model. Despite its high performance on a variety of downstream tasks, we do not understand precisely how each of these components contribute to ORCA's success. Therefore, we run a series of ablations and find that embedder training does not help 2D tasks at all, contrary to what the original paper posits. In 1D tasks, some amount of embedder training is necessary but more is not better. In 4 out of 6 datasets we experiment with, it is model fine-tuning that makes the biggest difference. Through our ablations and baselines, we contribute a better understanding of the individual components of ORCA.
The Impact of Demonstrations on Multilingual In-Context Learning: A Multidimensional Analysis
Feb 20, 2024



In-context learning is a popular inference strategy where large language models solve a task using only a few labelled demonstrations without needing any parameter updates. Compared to work on monolingual (English) in-context learning, multilingual in-context learning is under-explored, and we lack an in-depth understanding of the role of demonstrations in this context. To address this gap, we conduct a multidimensional analysis of multilingual in-context learning, experimenting with 5 models from different model families, 9 datasets covering classification and generation tasks, and 56 typologically diverse languages. Our results reveal that the effectiveness of demonstrations varies significantly across models, tasks, and languages. We also find that Llama 2-Chat, GPT-3.5, and GPT-4 are largely insensitive to the quality of demonstrations. Instead, a carefully crafted template often eliminates the benefits of demonstrations for some tasks and languages altogether. These findings show that the importance of demonstrations might be overestimated. Our work highlights the need for granular evaluation across multiple axes towards a better understanding of in-context learning.
The Hidden Space of Transformer Language Adapters
Feb 20, 2024



We analyze the operation of transformer language adapters, which are small modules trained on top of a frozen language model to adapt its predictions to new target languages. We show that adapted predictions mostly evolve in the source language the model was trained on, while the target language becomes pronounced only in the very last layers of the model. Moreover, the adaptation process is gradual and distributed across layers, where it is possible to skip small groups of adapters without decreasing adaptation performance. Last, we show that adapters operate on top of the model's frozen representation space while largely preserving its structure, rather than on an 'isolated' subspace. Our findings provide a deeper view into the adaptation process of language models to new languages, showcasing the constraints imposed on it by the underlying model and introduces practical implications to enhance its efficiency.
Large GPT-like Models are Bad Babies: A Closer Look at the Relationship between Linguistic Competence and Psycholinguistic Measures
Nov 08, 2023Research on the cognitive plausibility of language models (LMs) has so far mostly concentrated on modelling psycholinguistic response variables such as reading times, gaze durations and N400/P600 EEG signals, while mostly leaving out the dimension of what Mahowald et al. (2023) described as formal and functional linguistic competence, and developmental plausibility. We address this gap by training a series of GPT-like language models of different sizes on the strict version of the BabyLM pretraining corpus, evaluating on the challenge tasks (BLiMP, GLUE, MSGS) and an additional reading time prediction task. We find a positive correlation between LM size and performance on all three challenge tasks, with different preferences for model width and depth in each of the tasks. In contrast, a negative correlation was found between LM size and reading time fit of linear mixed-effects models using LM surprisal as a predictor, with the second-smallest LM achieving the largest log-likelihood reduction over a baseline model without surprisal. This suggests that modelling processing effort and linguistic competence may require an approach different from training GPT-like LMs on a developmentally plausible corpus.
Few-shot Fine-tuning vs. In-context Learning: A Fair Comparison and Evaluation
May 30, 2023



Few-shot fine-tuning and in-context learning are two alternative strategies for task adaptation of pre-trained language models. Recently, in-context learning has gained popularity over fine-tuning due to its simplicity and improved out-of-domain generalization, and because extensive evidence shows that fine-tuned models pick up on spurious correlations. Unfortunately, previous comparisons of the two approaches were done using models of different sizes. This raises the question of whether the observed weaker out-of-domain generalization of fine-tuned models is an inherent property of fine-tuning or a limitation of the experimental setup. In this paper, we compare the generalization of few-shot fine-tuning and in-context learning to challenge datasets, while controlling for the models used, the number of examples, and the number of parameters, ranging from 125M to 30B. Our results show that fine-tuned language models can in fact generalize well out-of-domain. We find that both approaches generalize similarly; they exhibit large variation and depend on properties such as model size and the number of examples, highlighting that robust task adaptation remains a challenge.
Weaker Than You Think: A Critical Look atWeakly Supervised Learning
May 27, 2023



Weakly supervised learning is a popular approach for training machine learning models in low-resource settings. Instead of requesting high-quality yet costly human annotations, it allows training models with noisy annotations obtained from various weak sources. Recently, many sophisticated approaches have been proposed for robust training under label noise, reporting impressive results. In this paper, we revisit the setup of these approaches and find that the benefits brought by these approaches are significantly overestimated. Specifically, we find that the success of existing weakly supervised learning approaches heavily relies on the availability of clean validation samples which, as we show, can be leveraged much more efficiently by simply training on them. After using these clean labels in training, the advantages of using these sophisticated approaches are mostly wiped out. This remains true even when reducing the size of the available clean data to just five samples per class, making these approaches impractical. To understand the true value of weakly supervised learning, we thoroughly analyse diverse NLP datasets and tasks to ascertain when and why weakly supervised approaches work, and provide recommendations for future research.
Fusing Sentence Embeddings Into LSTM-based Autoregressive Language Models
Aug 05, 2022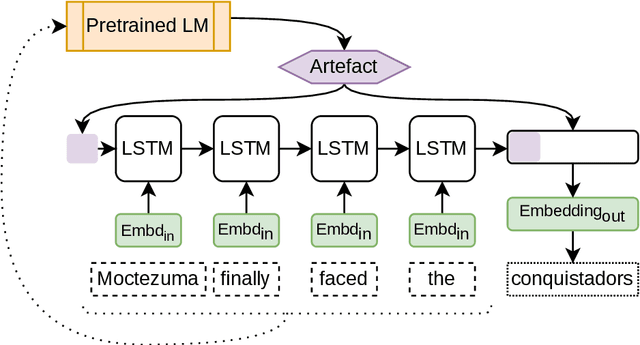
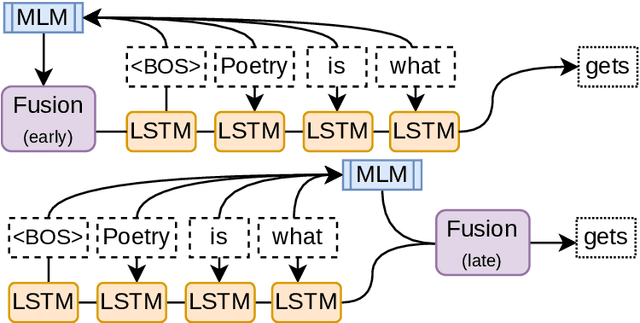

Although masked language models are highly performant and widely adopted by NLP practitioners, they can not be easily used for autoregressive language modelling (next word prediction and sequence probability estimation). We present an LSTM-based autoregressive language model which uses prefix embeddings (from a pretrained masked language model) via fusion (e.g. concatenation) to obtain a richer context representation for language modelling. We find that fusion helps reliably in lowering the perplexity (16.74 $\rightarrow$ 15.80), which is even preserved after a transfer to a dataset from a different domain than the training data. We also evaluate the best-performing fusion model by correlating its next word surprisal estimates with human reading times. Contradicting our expectation, and despite the improvement in perplexity overall, the correlation remains the same as for the baseline model. Lastly, while we focus on language models pre-trained on text as the sources for the fusion, our approach can be possibly extended to fuse any information represented as a fixed-size vector into an auto-regressive language model. These include e.g. sentence external information retrieved for a knowledge base or representations of multi-modal encoders.
Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions
Jul 28, 2022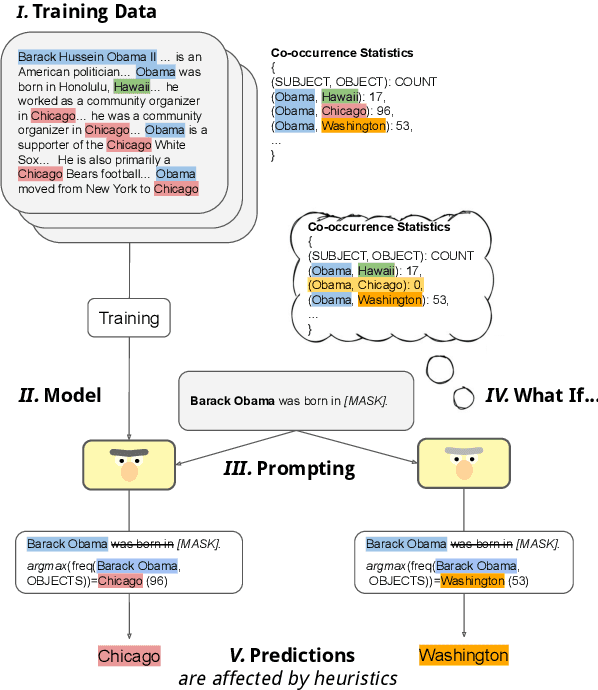

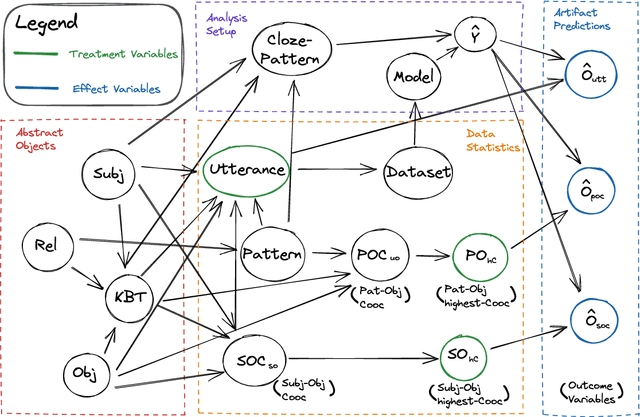

Large amounts of training data are one of the major reasons for the high performance of state-of-the-art NLP models. But what exactly in the training data causes a model to make a certain prediction? We seek to answer this question by providing a language for describing how training data influences predictions, through a causal framework. Importantly, our framework bypasses the need to retrain expensive models and allows us to estimate causal effects based on observational data alone. Addressing the problem of extracting factual knowledge from pretrained language models (PLMs), we focus on simple data statistics such as co-occurrence counts and show that these statistics do influence the predictions of PLMs, suggesting that such models rely on shallow heuristics. Our causal framework and our results demonstrate the importance of studying datasets and the benefits of causality for understanding NLP models.
StereoKG: Data-Driven Knowledge Graph Construction for Cultural Knowledge and Stereotypes
May 27, 2022

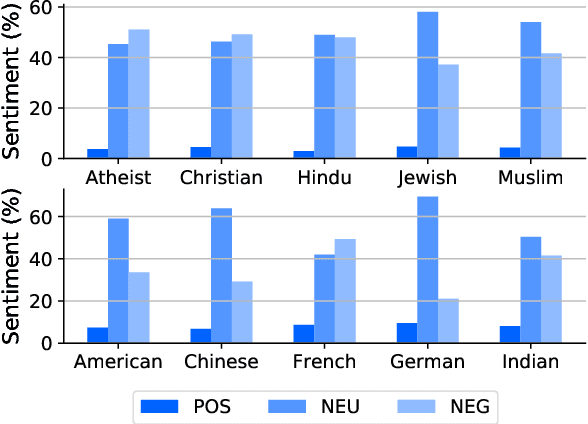
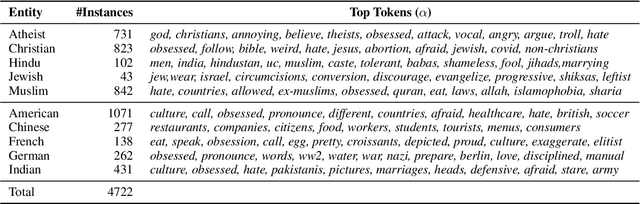
Analyzing ethnic or religious bias is important for improving fairness, accountability, and transparency of natural language processing models. However, many techniques rely on human-compiled lists of bias terms, which are expensive to create and are limited in coverage. In this study, we present a fully data-driven pipeline for generating a knowledge graph (KG) of cultural knowledge and stereotypes. Our resulting KG covers 5 religious groups and 5 nationalities and can easily be extended to include more entities. Our human evaluation shows that the majority (59.2%) of non-singleton entries are coherent and complete stereotypes. We further show that performing intermediate masked language model training on the verbalized KG leads to a higher level of cultural awareness in the model and has the potential to increase classification performance on knowledge-crucial samples on a related task, i.e., hate speech detection.