 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOGLO-FNO: Efficient Learning of Local and Global Features in Fourier Neural Operators
Apr 05, 2025



Modeling high-frequency information is a critical challenge in scientific machine learning. For instance, fully turbulent flow simulations of Navier-Stokes equations at Reynolds numbers 3500 and above can generate high-frequency signals due to swirling fluid motions caused by eddies and vortices. Faithfully modeling such signals using neural networks depends on accurately reconstructing moderate to high frequencies. However, it has been well known that deep neural nets exhibit the so-called spectral bias toward learning low-frequency components. Meanwhile, Fourier Neural Operators (FNOs) have emerged as a popular class of data-driven models in recent years for solving Partial Differential Equations (PDEs) and for surrogate modeling in general. Although impressive results have been achieved on several PDE benchmark problems, FNOs often perform poorly in learning non-dominant frequencies characterized by local features. This limitation stems from the spectral bias inherent in neural networks and the explicit exclusion of high-frequency modes in FNOs and their variants. Therefore, to mitigate these issues and improve FNO's spectral learning capabilities to represent a broad range of frequency components, we propose two key architectural enhancements: (i) a parallel branch performing local spectral convolutions (ii) a high-frequency propagation module. Moreover, we propose a novel frequency-sensitive loss term based on radially binned spectral errors. This introduction of a parallel branch for local convolutions reduces number of trainable parameters by up to 50% while achieving the accuracy of baseline FNO that relies solely on global convolutions. Experiments on three challenging PDE problems in fluid mechanics and biological pattern formation, and the qualitative and spectral analysis of predictions show the effectiveness of our method over the state-of-the-art neural operator baselines.
Active Learning for Neural PDE Solvers
Aug 02, 2024



Solving partial differential equations (PDEs) is a fundamental problem in engineering and science. While neural PDE solvers can be more efficient than established numerical solvers, they often require large amounts of training data that is costly to obtain. Active Learning (AL) could help surrogate models reach the same accuracy with smaller training sets by querying classical solvers with more informative initial conditions and PDE parameters. While AL is more common in other domains, it has yet to be studied extensively for neural PDE solvers. To bridge this gap, we introduce AL4PDE, a modular and extensible active learning benchmark. It provides multiple parametric PDEs and state-of-the-art surrogate models for the solver-in-the-loop setting, enabling the evaluation of existing and the development of new AL methods for PDE solving. We use the benchmark to evaluate batch active learning algorithms such as uncertainty- and feature-based methods. We show that AL reduces the average error by up to 71% compared to random sampling and significantly reduces worst-case errors. Moreover, AL generates similar datasets across repeated runs, with consistent distributions over the PDE parameters and initial conditions. The acquired datasets are reusable, providing benefits for surrogate models not involved in the data generation.
Vectorized Conditional Neural Fields: A Framework for Solving Time-dependent Parametric Partial Differential Equations
Jun 06, 2024



Transformer models are increasingly used for solving Partial Differential Equations (PDEs). Several adaptations have been proposed, all of which suffer from the typical problems of Transformers, such as quadratic memory and time complexity. Furthermore, all prevalent architectures for PDE solving lack at least one of several desirable properties of an ideal surrogate model, such as (i) generalization to PDE parameters not seen during training, (ii) spatial and temporal zero-shot super-resolution, (iii) continuous temporal extrapolation, (iv) support for 1D, 2D, and 3D PDEs, and (v) efficient inference for longer temporal rollouts. To address these limitations, we propose Vectorized Conditional Neural Fields (VCNeFs), which represent the solution of time-dependent PDEs as neural fields. Contrary to prior methods, however, VCNeFs compute, for a set of multiple spatio-temporal query points, their solutions in parallel and model their dependencies through attention mechanisms. Moreover, VCNeF can condition the neural field on both the initial conditions and the parameters of the PDEs. An extensive set of experiments demonstrates that VCNeFs are competitive with and often outperform existing ML-based surrogate models.
Fusion Models for Improved Visual Captioning
Oct 28, 2020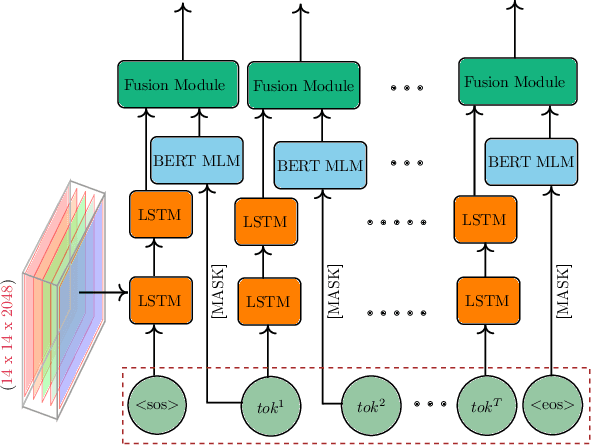
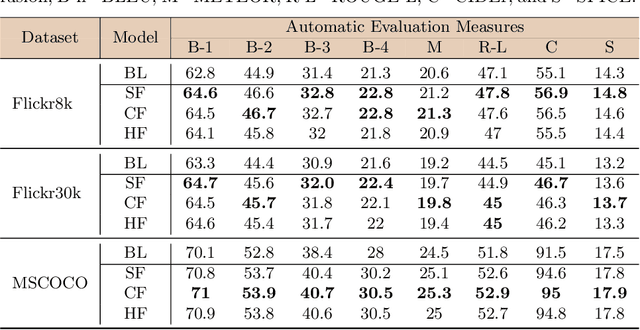
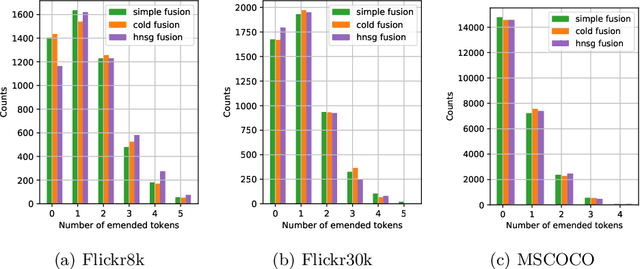
Visual captioning aims to generate textual descriptions given images. Traditionally, the captioning models are trained on human annotated datasets such as Flickr30k and MS-COCO, which are limited in size and diversity. This limitation hinders the generalization capabilities of these models while also rendering them to often make mistakes. Language models can, however, be trained on vast amounts of freely available unlabelled data and have recently emerged as successful language encoders and coherent text generators. Meanwhile, several unimodal and multimodal fusion techniques have been proven to work well for natural language generation and automatic speech recognition. Building on these recent developments, and with an aim of improving the quality of generated captions, the contribution of our work in this paper is two-fold: First, we propose a generic multimodal model fusion framework for caption generation as well as emendation where we utilize different fusion strategies to integrate a pretrained Auxiliary Language Model (AuxLM) within the traditional encoder-decoder visual captioning frameworks. Next, we employ the same fusion strategies to integrate a pretrained Masked Language Model (MLM), namely BERT, with a visual captioning model, viz. Show, Attend, and Tell, for emending both syntactic and semantic errors in captions. Our caption emendation experiments on three benchmark image captioning datasets, viz. Flickr8k, Flickr30k, and MSCOCO, show improvements over the baseline, indicating the usefulness of our proposed multimodal fusion strategies. Further, we perform a preliminary qualitative analysis on the emended captions and identify error categories based on the type of corrections.
Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods
Jul 22, 2019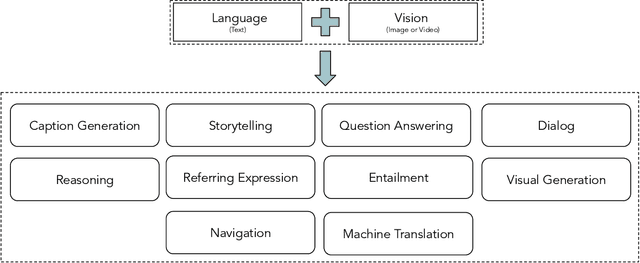
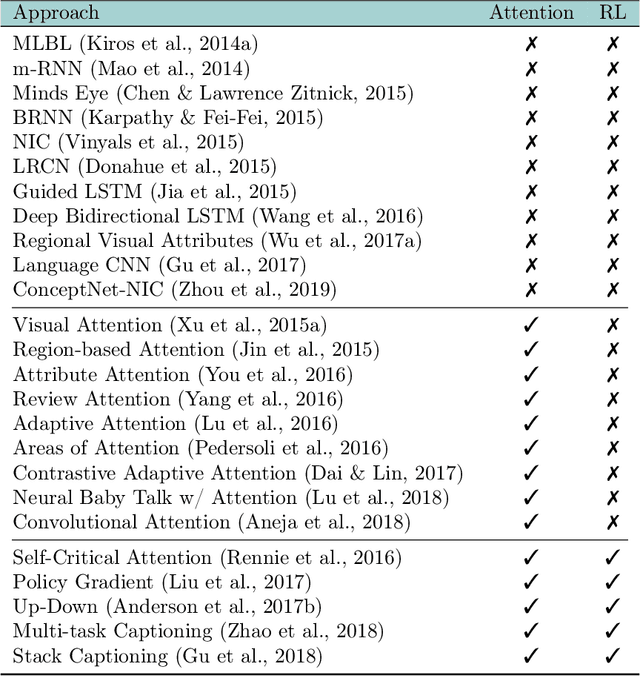

Integration of vision and language tasks has seen a significant growth in the recent times due to surge of interest from multi-disciplinary communities such as deep learning, computer vision, and natural language processing. In this survey, we focus on ten different vision and language integration tasks in terms of their problem formulation, methods, existing datasets, evaluation measures, and comparison of results achieved with the corresponding state-of-the-art methods. This goes beyond earlier surveys which are either task-specific or concentrate only on one type of visual content i.e., image or video. We then conclude the survey by discussing some possible future directions for integration of vision and language research.