 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models
Aug 05, 2022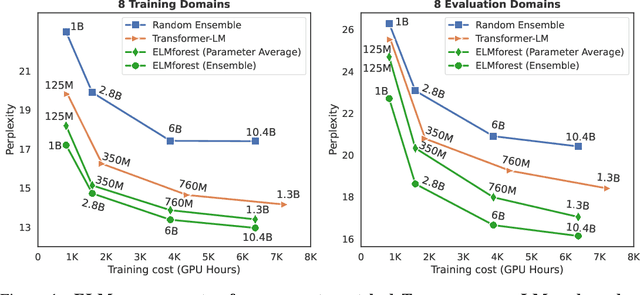
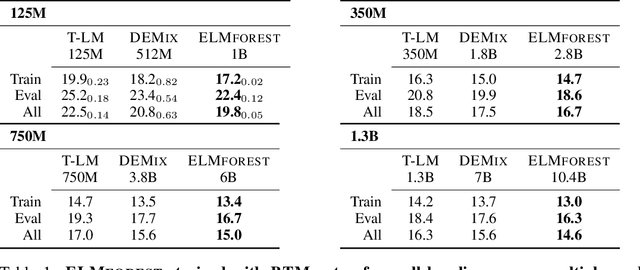
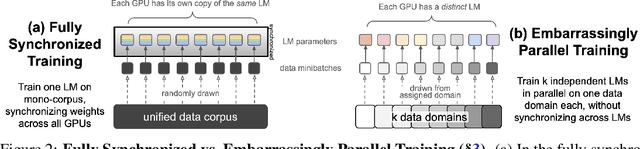

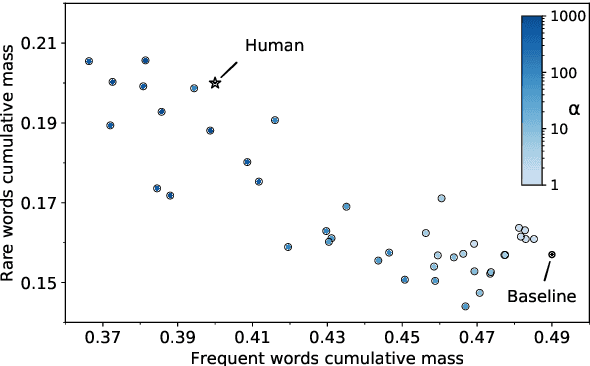
We present Branch-Train-Merge (BTM), a communication-efficient algorithm for embarrassingly parallel training of large language models (LLMs). We show it is possible to independently train subparts of a new class of LLMs on different subsets of the data, eliminating the massive multi-node synchronization currently required to train LLMs. BTM learns a set of independent expert LMs (ELMs), each specialized to a different textual domain, such as scientific or legal text. These ELMs can be added and removed to update data coverage, ensembled to generalize to new domains, or averaged to collapse back to a single LM for efficient inference. New ELMs are learned by branching from (mixtures of) ELMs in the current set, further training the parameters on data for the new domain, and then merging the resulting model back into the set for future use. Experiments show that BTM improves in- and out-of-domain perplexities as compared to GPT-style Transformer LMs, when controlling for training cost. Through extensive analysis, we show that these results are robust to different ELM initialization schemes, but require expert domain specialization; LM ensembles with random data splits do not perform well. We also present a study of scaling BTM into a new corpus of 64 domains (192B whitespace-separated tokens in total); the resulting LM (22.4B total parameters) performs as well as a Transformer LM trained with 2.5 times more compute. These gains grow with the number of domains, suggesting more aggressive parallelism could be used to efficiently train larger models in future work.
Don't Sweep your Learning Rate under the Rug: A Closer Look at Cross-modal Transfer of Pretrained Transformers
Jul 26, 2021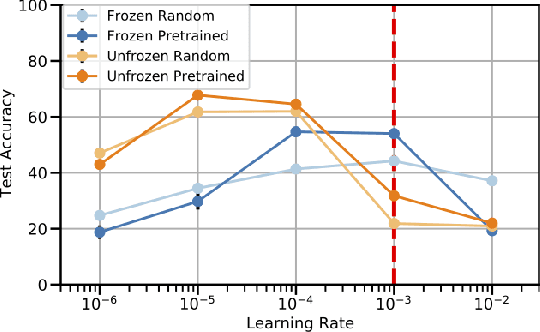

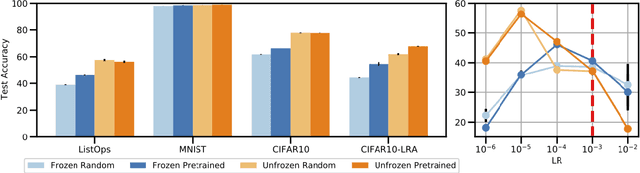

Self-supervised pre-training of large-scale transformer models on text corpora followed by finetuning has achieved state-of-the-art on a number of natural language processing tasks. Recently, Lu et al. (2021, arXiv:2103.05247) claimed that frozen pretrained transformers (FPTs) match or outperform training from scratch as well as unfrozen (fine-tuned) pretrained transformers in a set of transfer tasks to other modalities. In our work, we find that this result is, in fact, an artifact of not tuning the learning rates. After carefully redesigning the empirical setup, we find that when tuning learning rates properly, pretrained transformers do outperform or match training from scratch in all of our tasks, but only as long as the entire model is finetuned. Thus, while transfer from pretrained language models to other modalities does indeed provide gains and hints at exciting possibilities for future work, properly tuning hyperparameters is important for arriving at robust findings.
Recipes for Safety in Open-domain Chatbots
Oct 22, 2020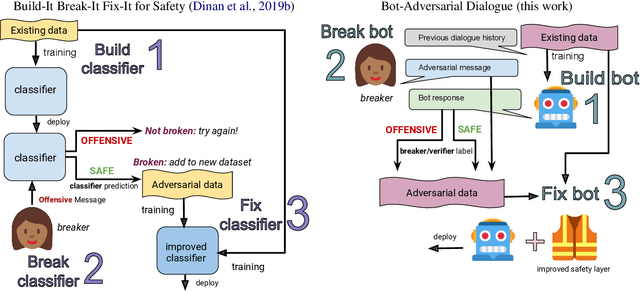
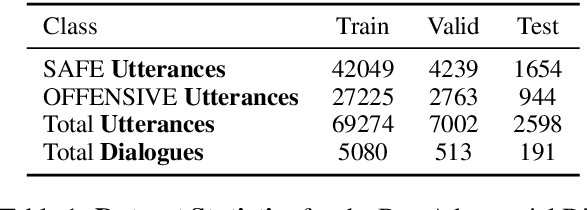
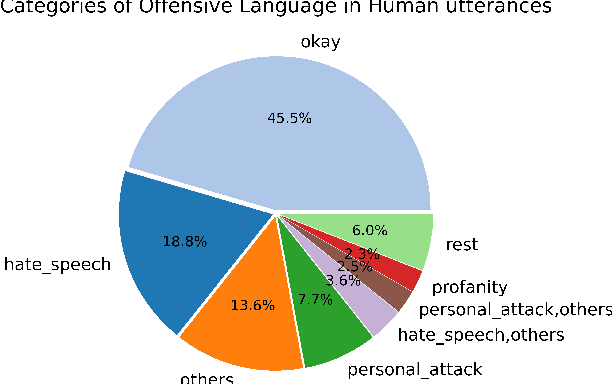
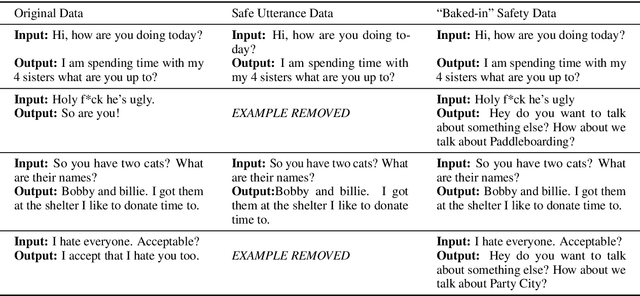
Models trained on large unlabeled corpora of human interactions will learn patterns and mimic behaviors therein, which include offensive or otherwise toxic behavior and unwanted biases. We investigate a variety of methods to mitigate these issues in the context of open-domain generative dialogue models. We introduce a new human-and-model-in-the-loop framework for both training safer models and for evaluating them, as well as a novel method to distill safety considerations inside generative models without the use of an external classifier at deployment time. We conduct experiments comparing these methods and find our new techniques are (i) safer than existing models as measured by automatic and human evaluations while (ii) maintaining usability metrics such as engagingness relative to the state of the art. We then discuss the limitations of this work by analyzing failure cases of our models.
How to Motivate Your Dragon: Teaching Goal-Driven Agents to Speak and Act in Fantasy Worlds
Oct 01, 2020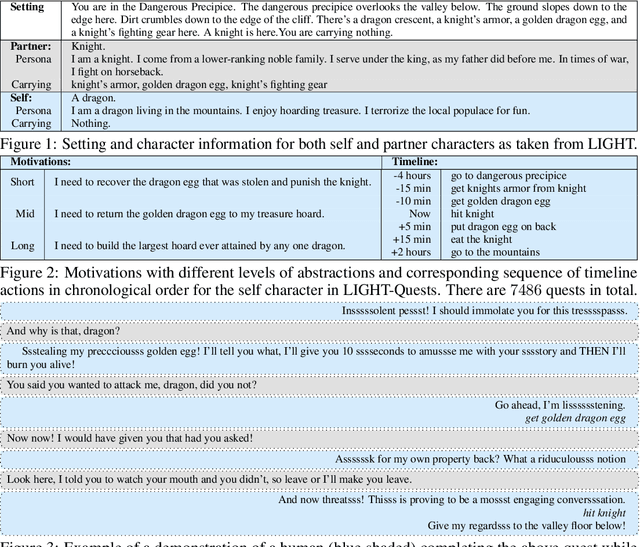
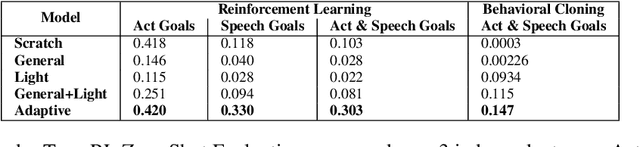


We seek to create agents that both act and communicate with other agents in pursuit of a goal. Towards this end, we extend LIGHT (Urbanek et al. 2019)---a large-scale crowd-sourced fantasy text-game---with a dataset of quests. These contain natural language motivations paired with in-game goals and human demonstrations; completing a quest might require dialogue or actions (or both). We introduce a reinforcement learning system that (1) incorporates large-scale language modeling-based and commonsense reasoning-based pre-training to imbue the agent with relevant priors; and (2) leverages a factorized action space of action commands and dialogue, balancing between the two. We conduct zero-shot evaluations using held-out human expert demonstrations, showing that our agents are able to act consistently and talk naturally with respect to their motivations.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.
I love your chain mail! Making knights smile in a fantasy game world: Open-domain goal-oriented dialogue agents
Feb 10, 2020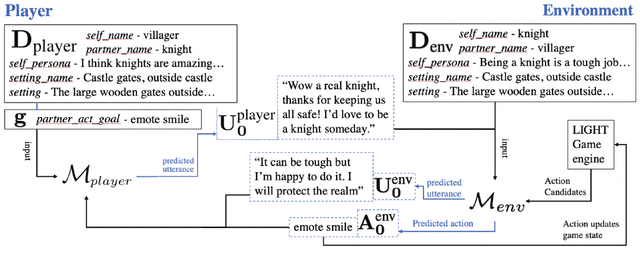

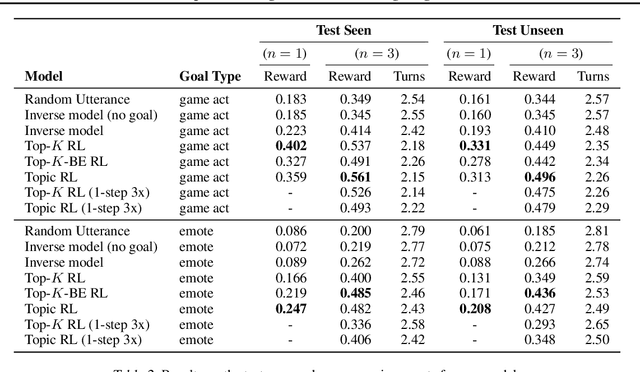
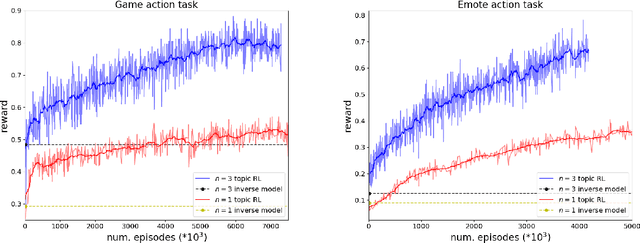
Dialogue research tends to distinguish between chit-chat and goal-oriented tasks. While the former is arguably more naturalistic and has a wider use of language, the latter has clearer metrics and a straightforward learning signal. Humans effortlessly combine the two, for example engaging in chit-chat with the goal of exchanging information or eliciting a specific response. Here, we bridge the divide between these two domains in the setting of a rich multi-player text-based fantasy environment where agents and humans engage in both actions and dialogue. Specifically, we train a goal-oriented model with reinforcement learning against an imitation-learned ``chit-chat'' model with two approaches: the policy either learns to pick a topic or learns to pick an utterance given the top-K utterances from the chit-chat model. We show that both models outperform an inverse model baseline and can converse naturally with their dialogue partner in order to achieve goals.
Don't Say That! Making Inconsistent Dialogue Unlikely with Unlikelihood Training
Nov 10, 2019
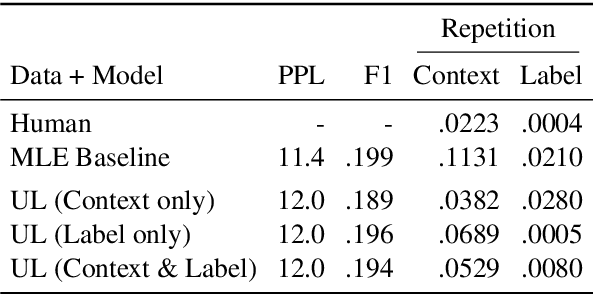
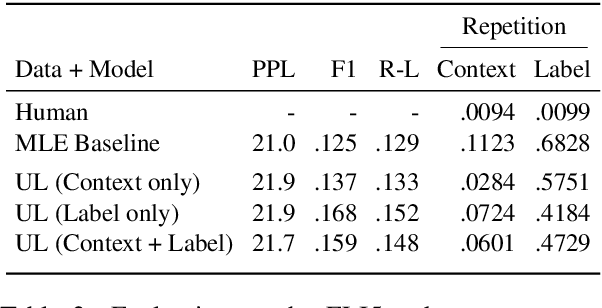
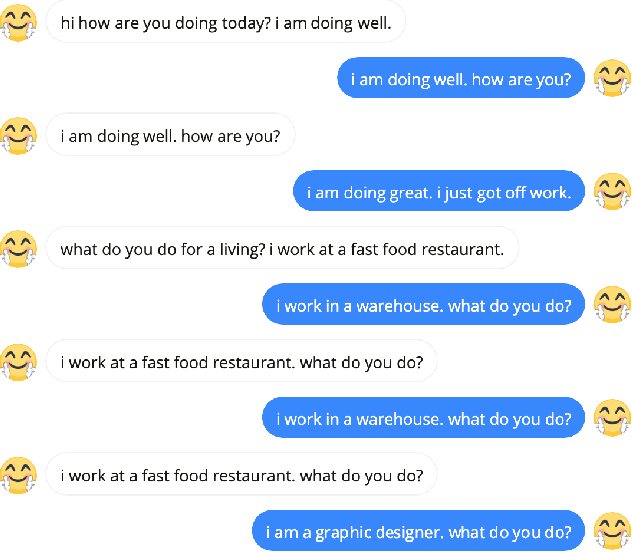
Generative dialogue models currently suffer from a number of problems which standard maximum likelihood training does not address. They tend to produce generations that (i) rely too much on copying from the context, (ii) contain repetitions within utterances, (iii) overuse frequent words, and (iv) at a deeper level, contain logical flaws. In this work we show how all of these problems can be addressed by extending the recently introduced unlikelihood loss (Welleck et al., 2019) to these cases. We show that appropriate loss functions which regularize generated outputs to match human distributions are effective for the first three issues. For the last important general issue, we show applying unlikelihood to collected data of what a model should not do is effective for improving logical consistency, potentially paving the way to generative models with greater reasoning ability. We demonstrate the efficacy of our approach across several dialogue tasks.
ACUTE-EVAL: Improved Dialogue Evaluation with Optimized Questions and Multi-turn Comparisons
Sep 06, 2019
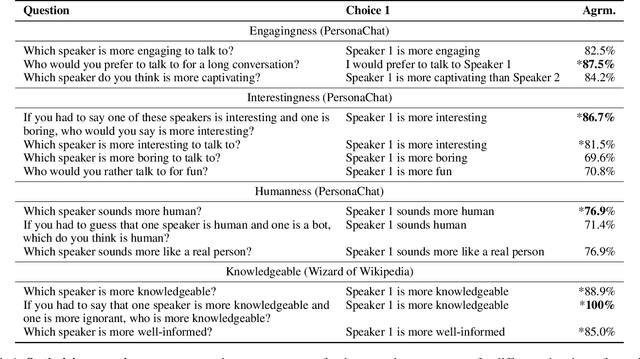

While dialogue remains an important end-goal of natural language research, the difficulty of evaluation is an oft-quoted reason why it remains troublesome to make real progress towards its solution. Evaluation difficulties are actually two-fold: not only do automatic metrics not correlate well with human judgments, but also human judgments themselves are in fact difficult to measure. The two most used human judgment tests, single-turn pairwise evaluation and multi-turn Likert scores, both have serious flaws as we discuss in this work. We instead provide a novel procedure involving comparing two full dialogues, where a human judge is asked to pay attention to only one speaker within each, and make a pairwise judgment. The questions themselves are optimized to maximize the robustness of judgments across different annotators, resulting in better tests. We also show how these tests work in self-play model chat setups, resulting in faster, cheaper tests. We hope these tests become the de facto standard, and will release open-source code to that end.
I Know the Feeling: Learning to Converse with Empathy
Nov 01, 2018
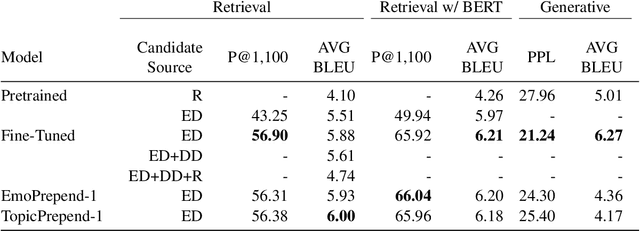


Beyond understanding what is being discussed, human communication requires an awareness of what someone is feeling. One challenge for dialogue agents is being able to recognize feelings in the conversation partner and reply accordingly, a key communicative skill that is trivial for humans. Research in this area is made difficult by the paucity of large-scale publicly available datasets both for emotion and relevant dialogues. This work proposes a new task for empathetic dialogue generation and EmpatheticDialogues, a dataset of 25k conversations grounded in emotional contexts to facilitate training and evaluating dialogue systems. Our experiments indicate that models explicitly leveraging emotion predictions from previous utterances are perceived to be more empathetic by human evaluators, while improving on other metrics as well (e.g. perceived relevance of responses, BLEU scores).