 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021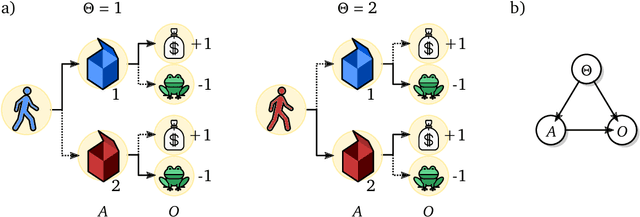
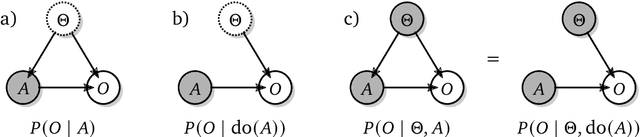
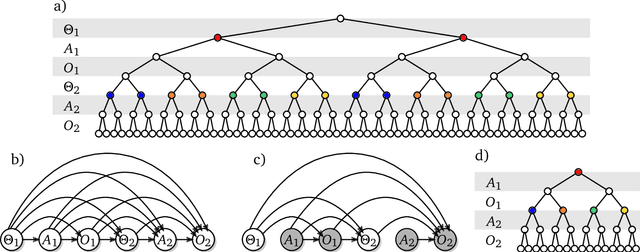
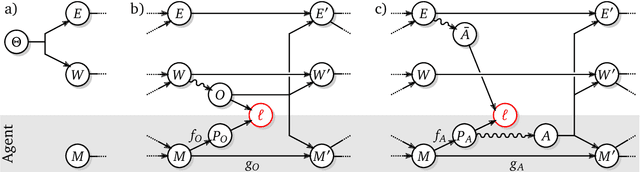
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Reward-Punishment Symmetric Universal Intelligence
Oct 06, 2021Can an agent's intelligence level be negative? We extend the Legg-Hutter agent-environment framework to include punishments and argue for an affirmative answer to that question. We show that if the background encodings and Universal Turing Machine (UTM) admit certain Kolmogorov complexity symmetries, then the resulting Legg-Hutter intelligence measure is symmetric about the origin. In particular, this implies reward-ignoring agents have Legg-Hutter intelligence 0 according to such UTMs.
Reinforcement Learning with Information-Theoretic Actuation
Sep 30, 2021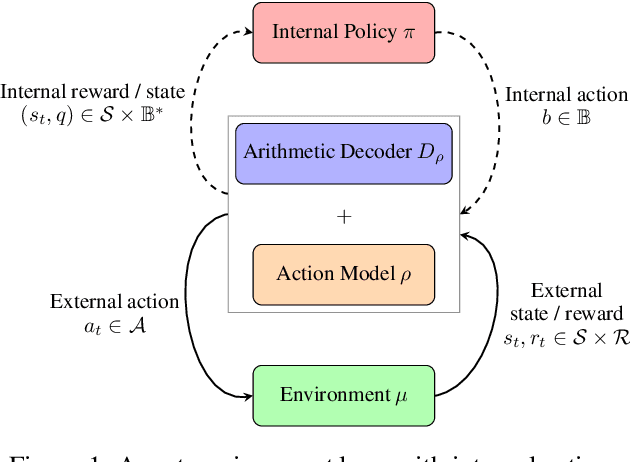

Reinforcement Learning formalises an embodied agent's interaction with the environment through observations, rewards and actions. But where do the actions come from? Actions are often considered to represent something external, such as the movement of a limb, a chess piece, or more generally, the output of an actuator. In this work we explore and formalize a contrasting view, namely that actions are best thought of as the output of a sequence of internal choices with respect to an action model. This view is particularly well-suited for leveraging the recent advances in large sequence models as prior knowledge for multi-task reinforcement learning problems. Our main contribution in this work is to show how to augment the standard MDP formalism with a sequential notion of internal action using information-theoretic techniques, and that this leads to self-consistent definitions of both internal and external action value functions.
Intelligence and Unambitiousness Using Algorithmic Information Theory
May 13, 2021
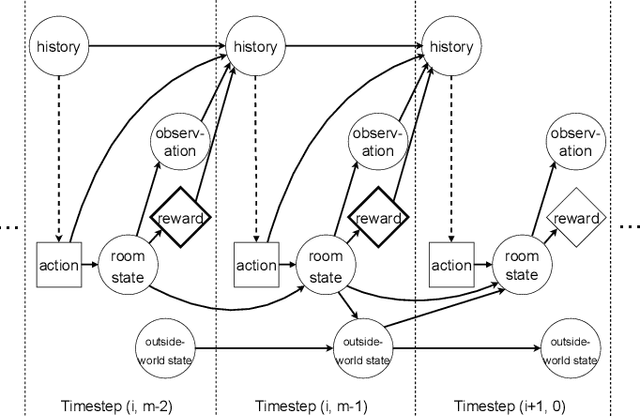
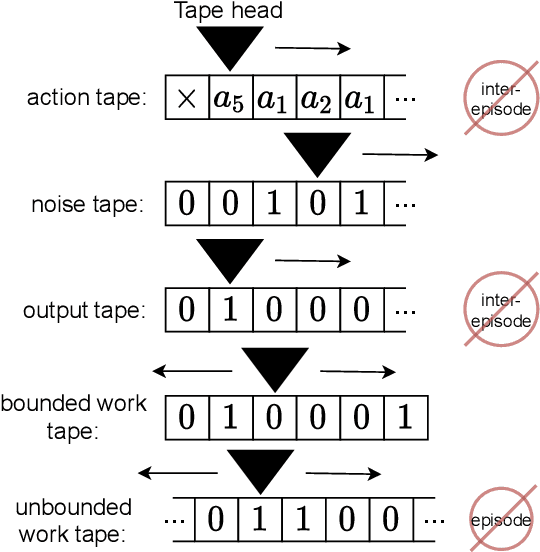
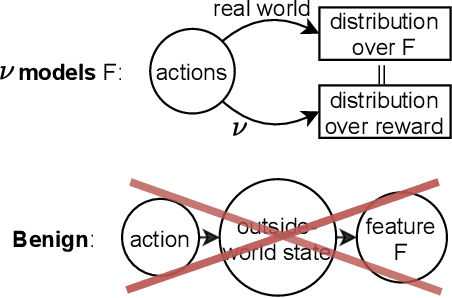
Algorithmic Information Theory has inspired intractable constructions of general intelligence (AGI), and undiscovered tractable approximations are likely feasible. Reinforcement Learning (RL), the dominant paradigm by which an agent might learn to solve arbitrary solvable problems, gives an agent a dangerous incentive: to gain arbitrary "power" in order to intervene in the provision of their own reward. We review the arguments that generally intelligent algorithmic-information-theoretic reinforcement learners such as Hutter's (2005) AIXI would seek arbitrary power, including over us. Then, using an information-theoretic exploration schedule, and a setup inspired by causal influence theory, we present a variant of AIXI which learns to not seek arbitrary power; we call it "unambitious". We show that our agent learns to accrue reward at least as well as a human mentor, while relying on that mentor with diminishing probability. And given a formal assumption that we probe empirically, we show that eventually, the agent's world-model incorporates the following true fact: intervening in the "outside world" will have no effect on reward acquisition; hence, it has no incentive to shape the outside world.
* 13 pages, 6 figures, 5-page appendix. arXiv admin note: text overlap with arXiv:1905.12186
Fully General Online Imitation Learning
Feb 17, 2021

In imitation learning, imitators and demonstrators are policies for picking actions given past interactions with the environment. If we run an imitator, we probably want events to unfold similarly to the way they would have if the demonstrator had been acting the whole time. No existing work provides formal guidance in how this might be accomplished, instead restricting focus to environments that restart, making learning unusually easy, and conveniently limiting the significance of any mistake. We address a fully general setting, in which the (stochastic) environment and demonstrator never reset, not even for training purposes. Our new conservative Bayesian imitation learner underestimates the probabilities of each available action, and queries for more data with the remaining probability. Our main result: if an event would have been unlikely had the demonstrator acted the whole time, that event's likelihood can be bounded above when running the (initially totally ignorant) imitator instead. Meanwhile, queries to the demonstrator rapidly diminish in frequency.
Learning Curve Theory
Feb 08, 2021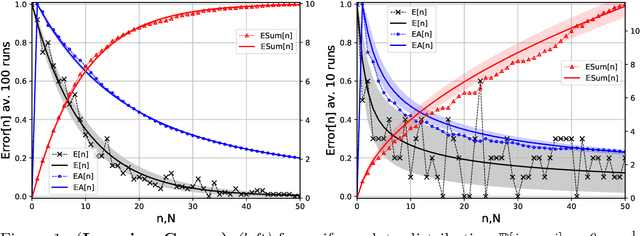
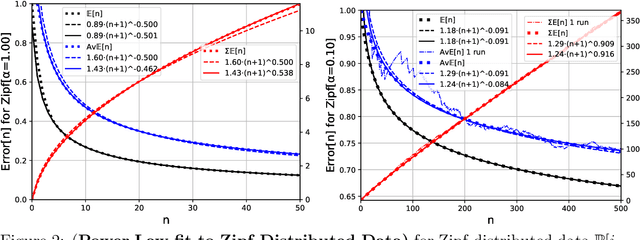
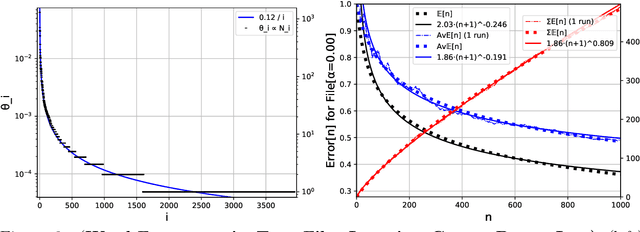
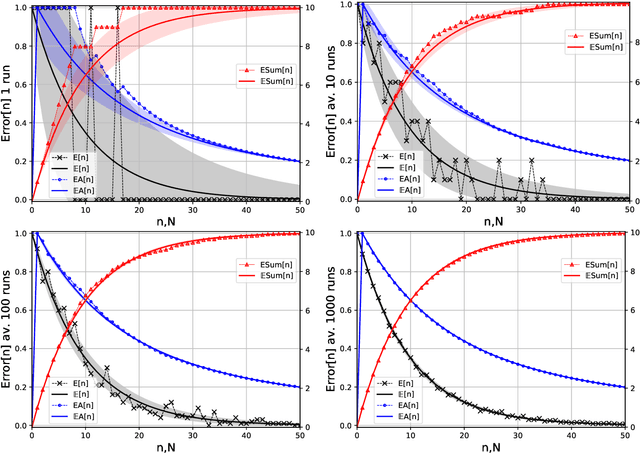
Recently a number of empirical "universal" scaling law papers have been published, most notably by OpenAI. `Scaling laws' refers to power-law decreases of training or test error w.r.t. more data, larger neural networks, and/or more compute. In this work we focus on scaling w.r.t. data size $n$. Theoretical understanding of this phenomenon is largely lacking, except in finite-dimensional models for which error typically decreases with $n^{-1/2}$ or $n^{-1}$, where $n$ is the sample size. We develop and theoretically analyse the simplest possible (toy) model that can exhibit $n^{-\beta}$ learning curves for arbitrary power $\beta>0$, and determine whether power laws are universal or depend on the data distribution.
Exact Reduction of Huge Action Spaces in General Reinforcement Learning
Dec 18, 2020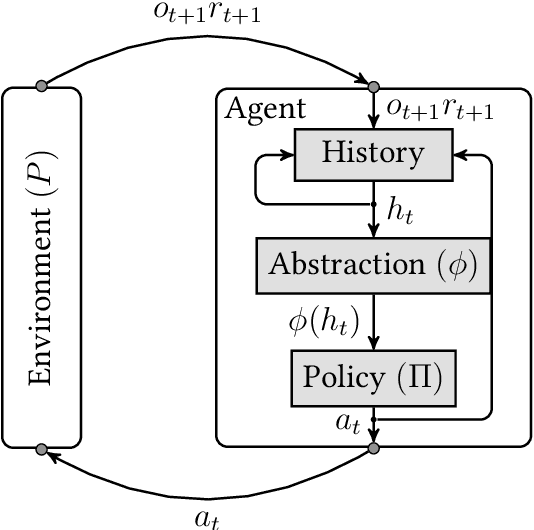
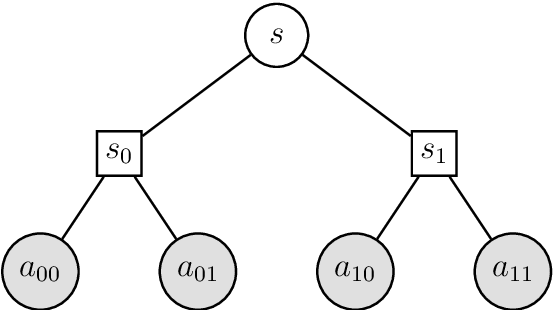
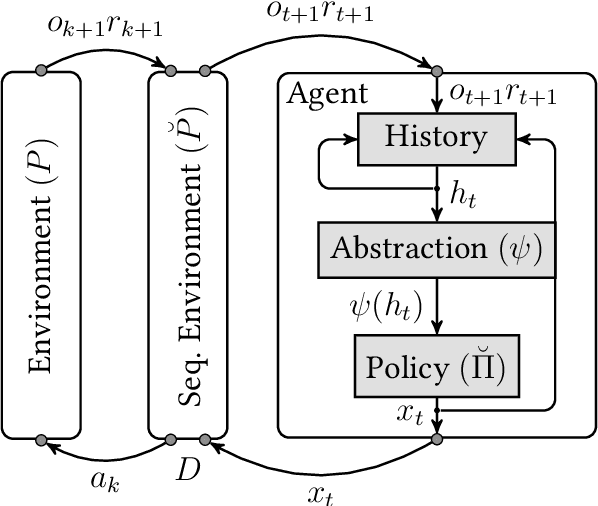
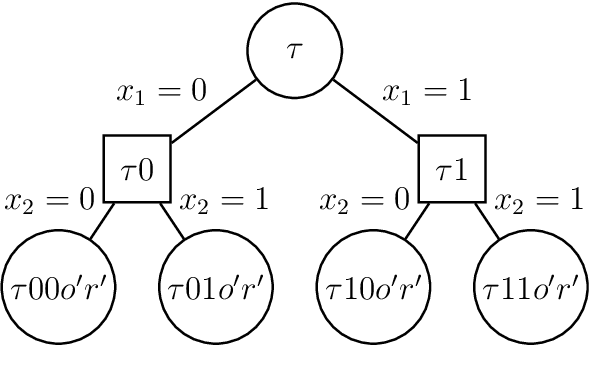
The reinforcement learning (RL) framework formalizes the notion of learning with interactions. Many real-world problems have large state-spaces and/or action-spaces such as in Go, StarCraft, protein folding, and robotics or are non-Markovian, which cause significant challenges to RL algorithms. In this work we address the large action-space problem by sequentializing actions, which can reduce the action-space size significantly, even down to two actions at the expense of an increased planning horizon. We provide explicit and exact constructions and equivalence proofs for all quantities of interest for arbitrary history-based processes. In the case of MDPs, this could help RL algorithms that bootstrap. In this work we show how action-binarization in the non-MDP case can significantly improve Extreme State Aggregation (ESA) bounds. ESA allows casting any (non-MDP, non-ergodic, history-based) RL problem into a fixed-sized non-Markovian state-space with the help of a surrogate Markovian process. On the upside, ESA enjoys similar optimality guarantees as Markovian models do. But a downside is that the size of the aggregated state-space becomes exponential in the size of the action-space. In this work, we patch this issue by binarizing the action-space. We provide an upper bound on the number of states of this binarized ESA that is logarithmic in the original action-space size, a double-exponential improvement.
Counterfactual Credit Assignment in Model-Free Reinforcement Learning
Nov 18, 2020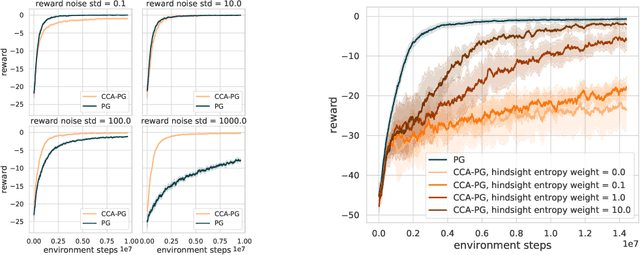
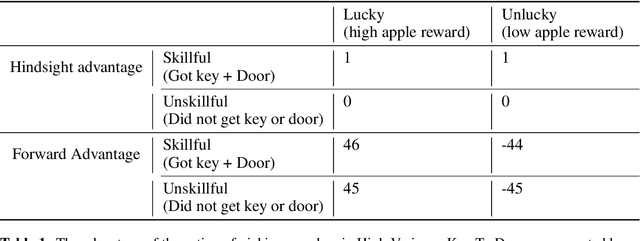

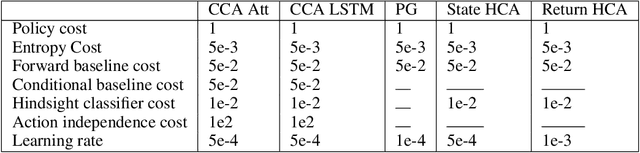
Credit assignment in reinforcement learning is the problem of measuring an action influence on future rewards. In particular, this requires separating skill from luck, ie. disentangling the effect of an action on rewards from that of external factors and subsequent actions. To achieve this, we adapt the notion of counterfactuals from causality theory to a model-free RL setup. The key idea is to condition value functions on future events, by learning to extract relevant information from a trajectory. We then propose to use these as future-conditional baselines and critics in policy gradient algorithms and we develop a valid, practical variant with provably lower variance, while achieving unbiasedness by constraining the hindsight information not to contain information about the agent actions. We demonstrate the efficacy and validity of our algorithm on a number of illustrative problems.
A Combinatorial Perspective on Transfer Learning
Oct 23, 2020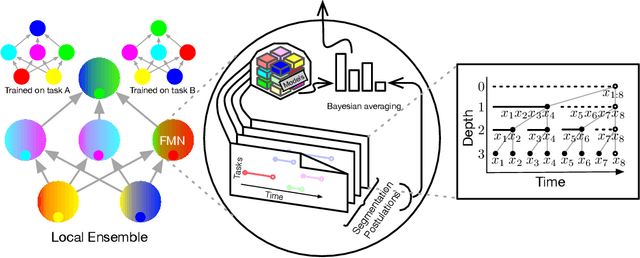
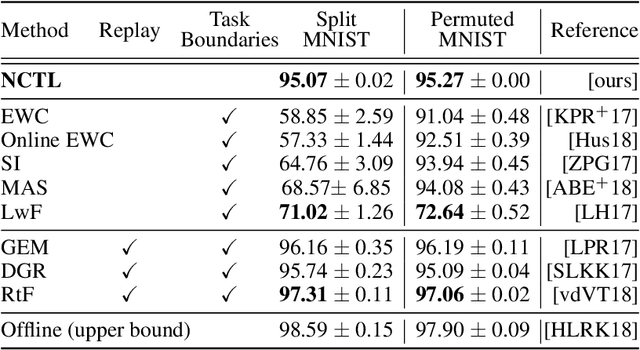
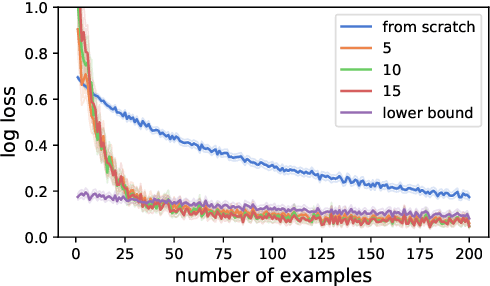
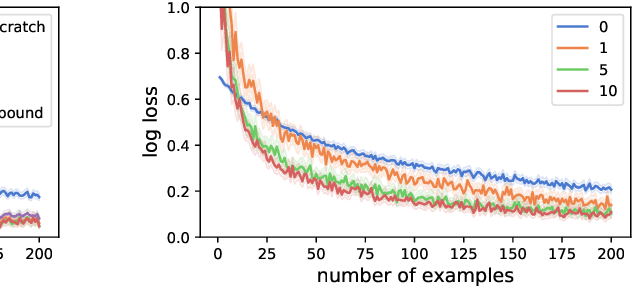
Human intelligence is characterized not only by the capacity to learn complex skills, but the ability to rapidly adapt and acquire new skills within an ever-changing environment. In this work we study how the learning of modular solutions can allow for effective generalization to both unseen and potentially differently distributed data. Our main postulate is that the combination of task segmentation, modular learning and memory-based ensembling can give rise to generalization on an exponentially growing number of unseen tasks. We provide a concrete instantiation of this idea using a combination of: (1) the Forget-Me-Not Process, for task segmentation and memory based ensembling; and (2) Gated Linear Networks, which in contrast to contemporary deep learning techniques use a modular and local learning mechanism. We demonstrate that this system exhibits a number of desirable continual learning properties: robustness to catastrophic forgetting, no negative transfer and increasing levels of positive transfer as more tasks are seen. We show competitive performance against both offline and online methods on standard continual learning benchmarks.
On Representing (Anti)Symmetric Functions
Jul 30, 2020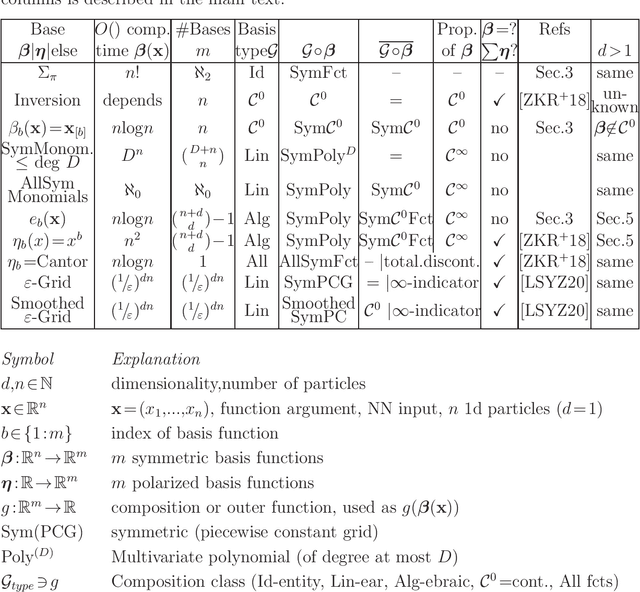
Permutation-invariant, -equivariant, and -covariant functions and anti-symmetric functions are important in quantum physics, computer vision, and other disciplines. Applications often require most or all of the following properties: (a) a large class of such functions can be approximated, e.g. all continuous function, (b) only the (anti)symmetric functions can be represented, (c) a fast algorithm for computing the approximation, (d) the representation itself is continuous or differentiable, (e) the architecture is suitable for learning the function from data. (Anti)symmetric neural networks have recently been developed and applied with great success. A few theoretical approximation results have been proven, but many questions are still open, especially for particles in more than one dimension and the anti-symmetric case, which this work focusses on. More concretely, we derive natural polynomial approximations in the symmetric case, and approximations based on a single generalized Slater determinant in the anti-symmetric case. Unlike some previous super-exponential and discontinuous approximations, these seem a more promising basis for future tighter bounds. We provide a complete and explicit universality proof of the Equivariant MultiLayer Perceptron, which implies universality of symmetric MLPs and the FermiNet.