 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOPS: Learning to Detect 3D Objects and Predict their 3D Shapes
Apr 07, 2020
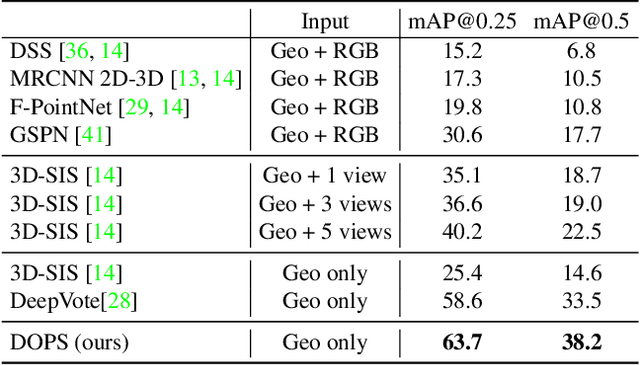
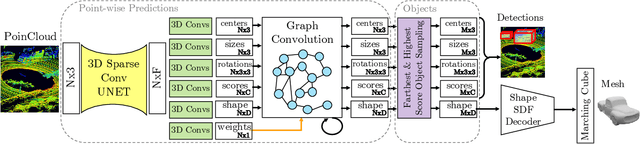
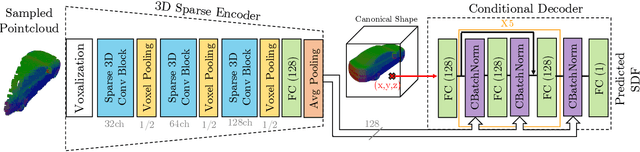
We propose DOPS, a fast single-stage 3D object detection method for LIDAR data. Previous methods often make domain-specific design decisions, for example projecting points into a bird-eye view image in autonomous driving scenarios. In contrast, we propose a general-purpose method that works on both indoor and outdoor scenes. The core novelty of our method is a fast, single-pass architecture that both detects objects in 3D and estimates their shapes. 3D bounding box parameters are estimated in one pass for every point, aggregated through graph convolutions, and fed into a branch of the network that predicts latent codes representing the shape of each detected object. The latent shape space and shape decoder are learned on a synthetic dataset and then used as supervision for the end-to-end training of the 3D object detection pipeline. Thus our model is able to extract shapes without access to ground-truth shape information in the target dataset. During experiments, we find that our proposed method achieves state-of-the-art results by ~5% on object detection in ScanNet scenes, and it gets top results by 3.4% in the Waymo Open Dataset, while reproducing the shapes of detected cars.
Adversarial Training for Free!
Apr 29, 2019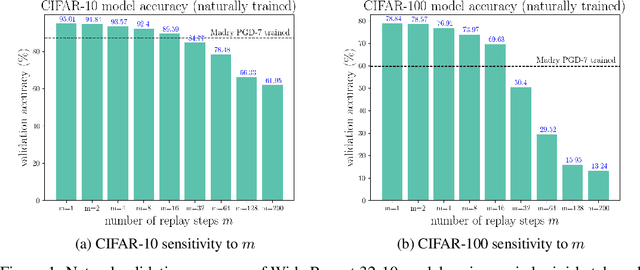
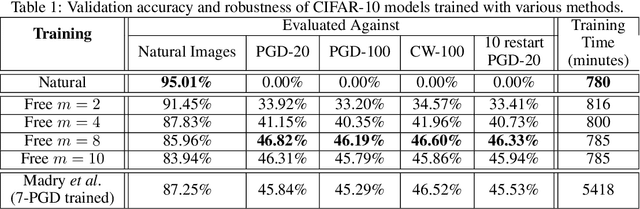
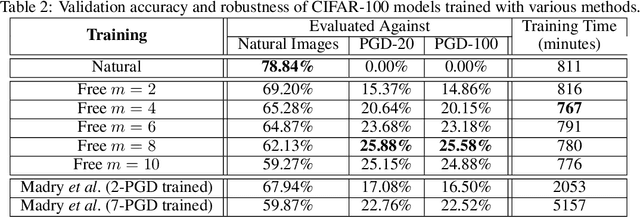

Adversarial training, in which a network is trained on adversarial examples, is one of the few defenses against adversarial attacks that withstands strong attacks. Unfortunately, the high cost of generating strong adversarial examples makes standard adversarial training impractical on large-scale problems like ImageNet. We present an algorithm that eliminates the overhead cost of generating adversarial examples by recycling the gradient information computed when updating model parameters. Our "free" adversarial training algorithm achieves state-of-the-art robustness on CIFAR-10 and CIFAR-100 datasets at negligible additional cost compared to natural training, and can be 7 to 30 times faster than other strong adversarial training methods. Using a single workstation with 4 P100 GPUs and 2 days of runtime, we can train a robust model for the large-scale ImageNet classification task that maintains 40% accuracy against PGD attacks.
An Analysis of Pre-Training on Object Detection
Apr 11, 2019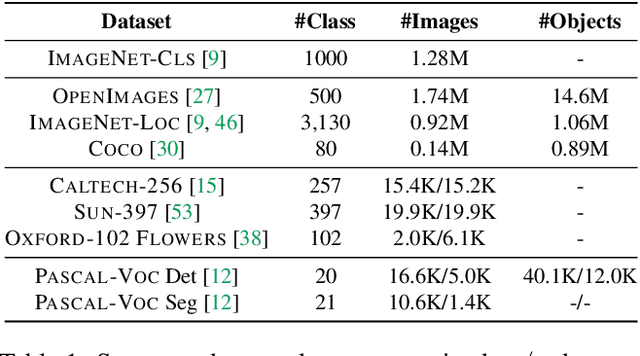
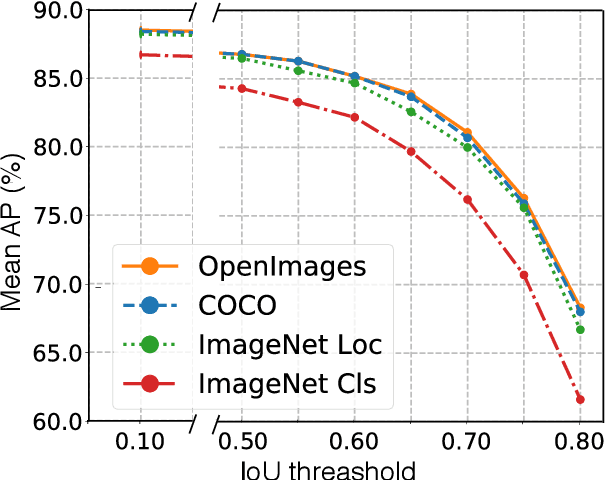
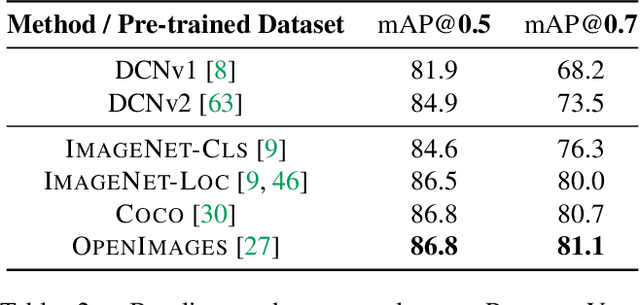

We provide a detailed analysis of convolutional neural networks which are pre-trained on the task of object detection. To this end, we train detectors on large datasets like OpenImagesV4, ImageNet Localization and COCO. We analyze how well their features generalize to tasks like image classification, semantic segmentation and object detection on small datasets like PASCAL-VOC, Caltech-256, SUN-397, Flowers-102 etc. Some important conclusions from our analysis are --- 1) Pre-training on large detection datasets is crucial for fine-tuning on small detection datasets, especially when precise localization is needed. For example, we obtain 81.1% mAP on the PASCAL-VOC dataset at 0.7 IoU after pre-training on OpenImagesV4, which is 7.6% better than the recently proposed DeformableConvNetsV2 which uses ImageNet pre-training. 2) Detection pre-training also benefits other localization tasks like semantic segmentation but adversely affects image classification. 3) Features for images (like avg. pooled Conv5) which are similar in the object detection feature space are likely to be similar in the image classification feature space but the converse is not true. 4) Visualization of features reveals that detection neurons have activations over an entire object, while activations for classification networks typically focus on parts. Therefore, detection networks are poor at classification when multiple instances are present in an image or when an instance only covers a small fraction of an image.
FA-RPN: Floating Region Proposals for Face Detection
Dec 13, 2018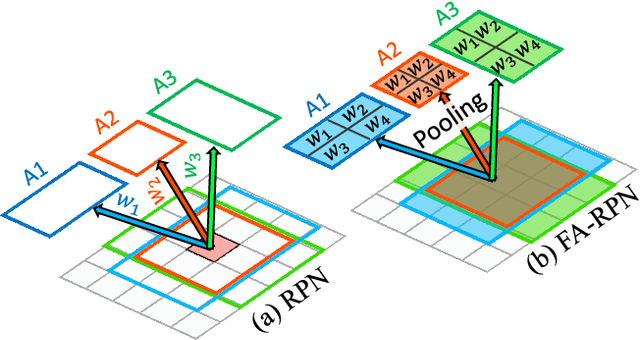

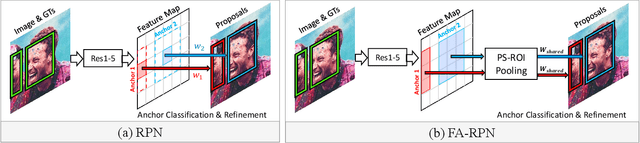
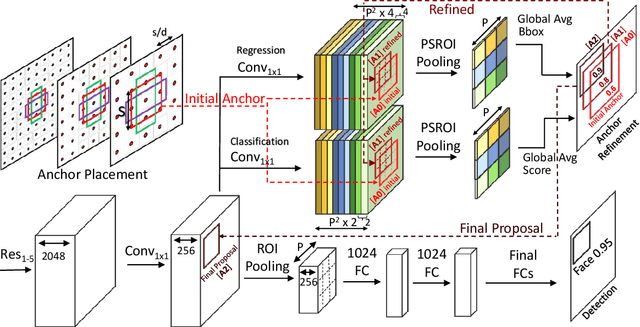
We propose a novel approach for generating region proposals for performing face-detection. Instead of classifying anchor boxes using features from a pixel in the convolutional feature map, we adopt a pooling-based approach for generating region proposals. However, pooling hundreds of thousands of anchors which are evaluated for generating proposals becomes a computational bottleneck during inference. To this end, an efficient anchor placement strategy for reducing the number of anchor-boxes is proposed. We then show that proposals generated by our network (Floating Anchor Region Proposal Network, FA-RPN) are better than RPN for generating region proposals for face detection. We discuss several beneficial features of FA-RPN proposals like iterative refinement, placement of fractional anchors and changing anchors which can be enabled without making any changes to the trained model. Our face detector based on FA-RPN obtains 89.4% mAP with a ResNet-50 backbone on the WIDER dataset.
AutoFocus: Efficient Multi-Scale Inference
Dec 04, 2018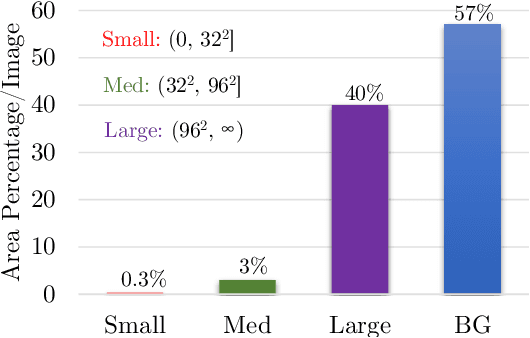
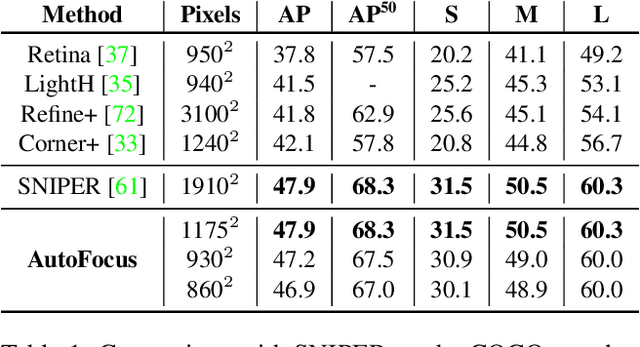

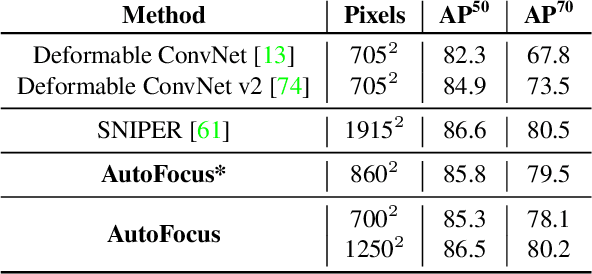
This paper describes AutoFocus, an efficient multi-scale inference algorithm for deep-learning based object detectors. Instead of processing an entire image pyramid, AutoFocus adopts a coarse to fine approach and only processes regions which are likely to contain small objects at finer scales. This is achieved by predicting category agnostic segmentation maps for small objects at coarser scales, called FocusPixels. FocusPixels can be predicted with high recall, and in many cases, they only cover a small fraction of the entire image. To make efficient use of FocusPixels, an algorithm is proposed which generates compact rectangular FocusChips which enclose FocusPixels. The detector is only applied inside FocusChips, which reduces computation while processing finer scales. Different types of error can arise when detections from FocusChips of multiple scales are combined, hence techniques to correct them are proposed. AutoFocus obtains an mAP of 47.9% (68.3% at 50% overlap) on the COCO test-dev set while processing 6.4 images per second on a Titan X (Pascal) GPU. This is 2.5X faster than our multi-scale baseline detector and matches its mAP. The number of pixels processed in the pyramid can be reduced by 5X with a 1% drop in mAP. AutoFocus obtains more than 10% mAP gain compared to RetinaNet but runs at the same speed with the same ResNet-101 backbone.
Universal Adversarial Training
Nov 27, 2018
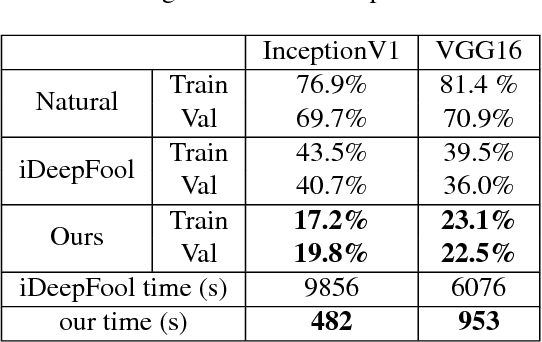
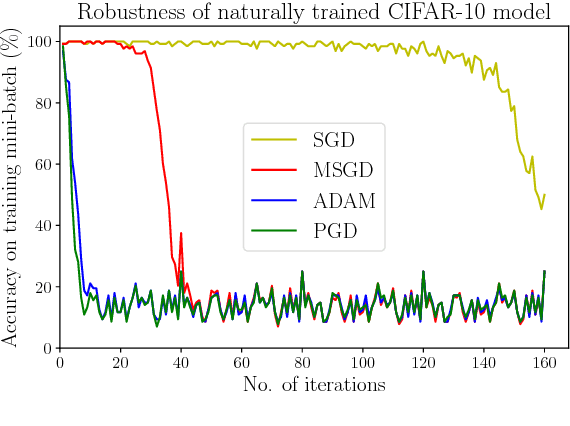
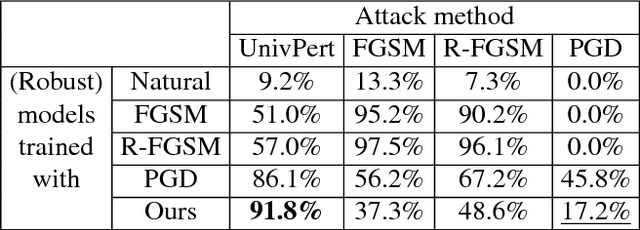
Standard adversarial attacks change the predicted class label of an image by adding specially tailored small perturbations to its pixels. In contrast, a universal perturbation is an update that can be added to any image in a broad class of images, while still changing the predicted class label. We study the efficient generation of universal adversarial perturbations, and also efficient methods for hardening networks to these attacks. We propose a simple optimization-based universal attack that reduces the top-1 accuracy of various network architectures on ImageNet to less than 20%, while learning the universal perturbation 13X faster than the standard method. To defend against these perturbations, we propose universal adversarial training, which models the problem of robust classifier generation as a two-player min-max game. This method is much faster and more scalable than conventional adversarial training with a strong adversary (PGD), and yet yields models that are extremely resistant to universal attacks, and comparably resistant to standard (per-instance) black box attacks. We also discover a rather fascinating side-effect of universal adversarial training: attacks built for universally robust models transfer better to other (black box) models than those built with conventional adversarial training.
Generate, Segment and Replace: Towards Generic Manipulation Segmentation
Nov 24, 2018
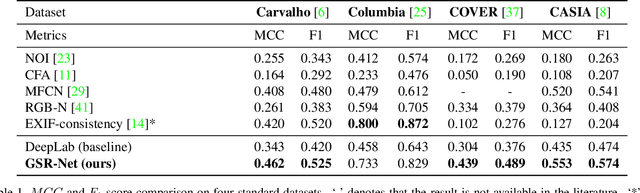
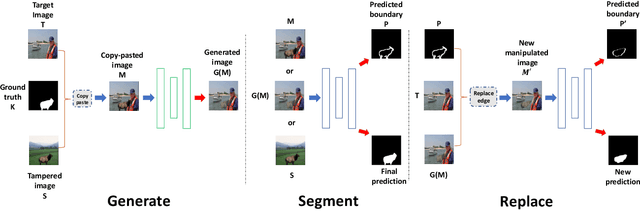
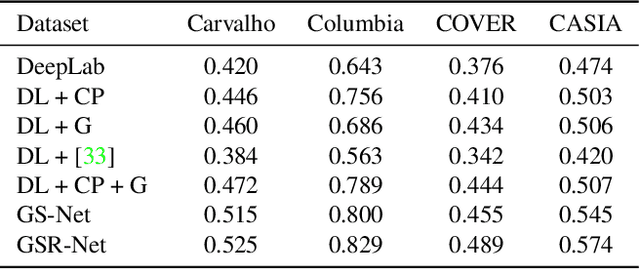
It has been witnessed an emerging demand for image manipulation segmentation to distinguish between fake images produced by advanced photo editing software and authentic ones. In this paper, we describe an approach based on semantic segmentation for detecting image manipulation. The approach consists of three stages. A generation stage generates hard manipulated images from authentic images using a Generative Adversarial Network (GAN) based model by cutting a region out of a training sample, pasting it into an authentic image and then passing the image through a GAN to generate harder true positive tampered region. A segmentation stage and a replacement stage, sharing weights with each other, then collaboratively construct dense predictions of tampered regions. We achieve state-of-the-art performance on four public image manipulation detection benchmarks while maintaining robustness to various attacks.
Soft Sampling for Robust Object Detection
Jun 18, 2018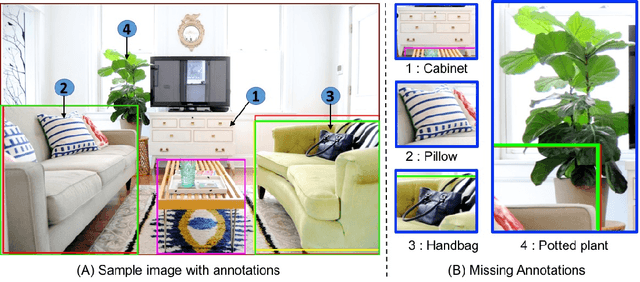
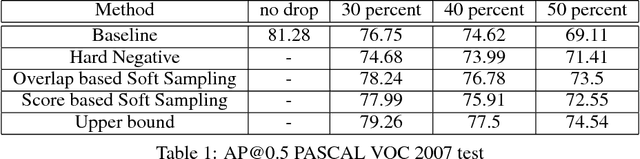
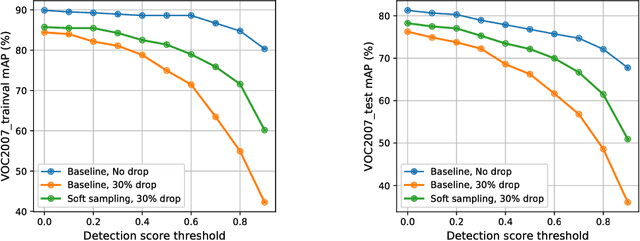
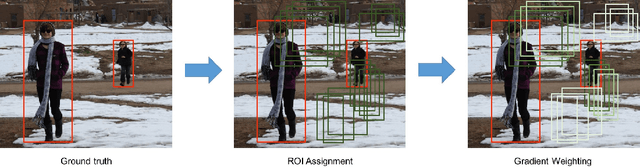
We study the robustness of object detection under the presence of missing annotations. In this setting, the unlabeled object instances will be treated as background, which will generate an incorrect training signal for the detector. Interestingly, we observe that after dropping 30% of the annotations (and labeling them as background), the performance of CNN-based object detectors like Faster-RCNN only drops by 5% on the PASCAL VOC dataset. We provide a detailed explanation for this result. To further bridge the performance gap, we propose a simple yet effective solution, called Soft Sampling. Soft Sampling re-weights the gradients of RoIs as a function of overlap with positive instances. This ensures that the uncertain background regions are given a smaller weight compared to the hardnegatives. Extensive experiments on curated PASCAL VOC datasets demonstrate the effectiveness of the proposed Soft Sampling method at different annotation drop rates. Finally, we show that on OpenImagesV3, which is a real-world dataset with missing annotations, Soft Sampling outperforms standard detection baselines by over 3%.
SNIPER: Efficient Multi-Scale Training
Jun 18, 2018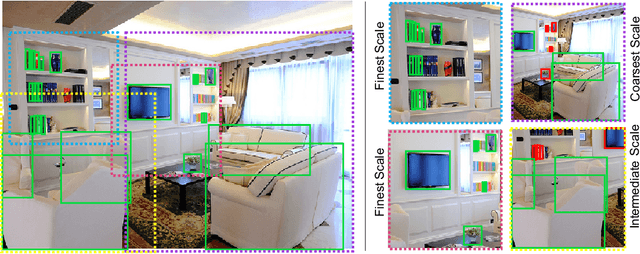



We present SNIPER, an algorithm for performing efficient multi-scale training in instance level visual recognition tasks. Instead of processing every pixel in an image pyramid, SNIPER processes context regions around ground-truth instances (referred to as chips) at the appropriate scale. For background sampling, these context-regions are generated using proposals extracted from a region proposal network trained with a short learning schedule. Hence, the number of chips generated per image during training adaptively changes based on the scene complexity. SNIPER only processes 30% more pixels compared to the commonly used single scale training at 800x1333 pixels on the COCO dataset. But, it also observes samples from extreme resolutions of the image pyramid, like 1400x2000 pixels. As SNIPER operates on resampled low resolution chips (512x512 pixels), it can have a batch size as large as 20 on a single GPU even with a ResNet-101 backbone. Therefore it can benefit from batch-normalization during training without the need for synchronizing batch-normalization statistics across GPUs. SNIPER brings training of instance level recognition tasks like object detection closer to the protocol for image classification and suggests that the commonly accepted guideline that it is important to train on high resolution images for instance level visual recognition tasks might not be correct. Our implementation based on Faster-RCNN with a ResNet-101 backbone obtains an mAP of 47.6% on the COCO dataset for bounding box detection and can process 5 images per second with a single GPU. The code is available at https://github.com/MahyarNajibi/SNIPER.
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
Apr 03, 2018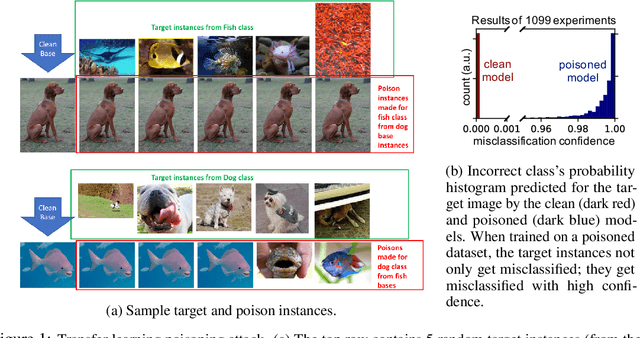
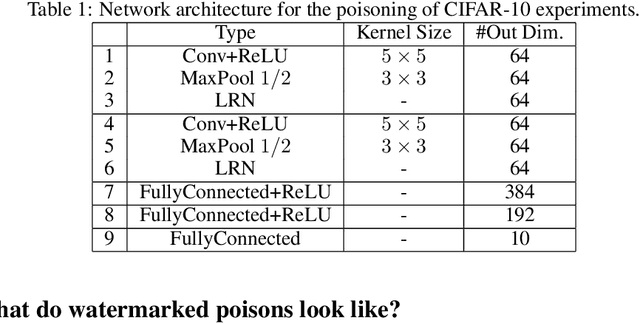
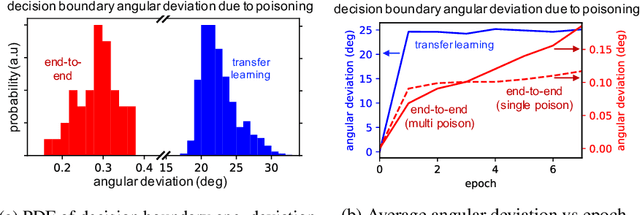
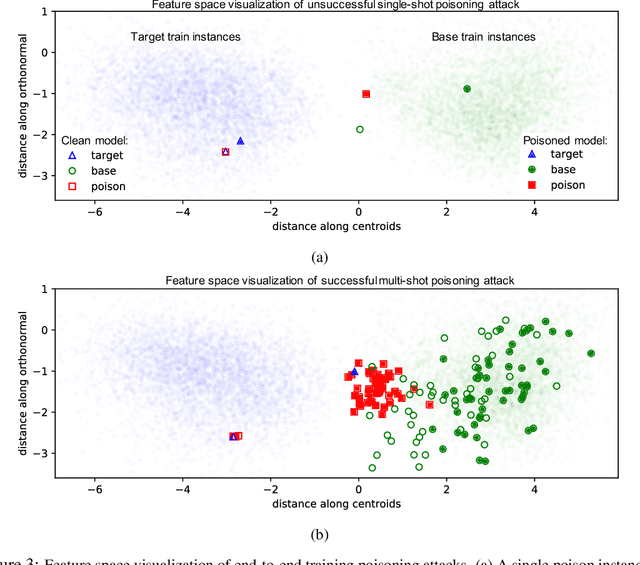
Data poisoning is a type of adversarial attack on machine learning models wherein the attacker adds examples to the training set to manipulate the behavior of the model at test time. This paper explores a broad class of poisoning attacks on neural nets. The proposed attacks use "clean-labels"; they don't require the attacker to have any control over the labeling of training data. They are also targeted; they control the behavior of the classifier on a specific test instance without noticeably degrading classifier performance on other instances. For example, an attacker could add a seemingly innocuous image (that is properly labeled) to a training set for a face recognition engine, and control the identity of a chosen person at test time. Because the attacker does not need to control the labeling function, poisons could be entered into the training set simply by putting them online and waiting for them to be scraped by a data collection bot. We present an optimization-based method for crafting poisons, and show that just one single poison image can control classifier behavior when transfer learning is used. For full end-to-end training, we present a "watermarking" strategy that makes poisoning reliable using multiple (~50) poisoned training instances. We demonstrate our method by generating poisoned frog images from the CIFAR dataset and using them to manipulate image classifiers.