 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Streaming: Fast LLM Inference without Auxiliary Models
Feb 16, 2024



Speculative decoding is a prominent technique to speed up the inference of a large target language model based on predictions of an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target models to achieve high acceptance rates. As the number of downstream tasks grows, these draft models add significant complexity to inference systems. We propose Speculative Streaming, a single-model speculative decoding method that fuses drafting into the target model by changing the fine-tuning objective from next token prediction to future n-gram prediction. Speculative Streaming speeds up decoding by 1.8 - 3.1X in a diverse set of tasks, such as Summarization, Structured Queries, and Meaning Representation, without sacrificing generation quality. Additionally, Speculative Streaming is parameter-efficient. It achieves on-par/higher speed-ups than Medusa-style architectures while using ~10000X fewer extra parameters, making it well-suited for resource-constrained devices.
Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving
Sep 25, 2023



Closed-set 3D perception models trained on only a pre-defined set of object categories can be inadequate for safety critical applications such as autonomous driving where new object types can be encountered after deployment. In this paper, we present a multi-modal auto labeling pipeline capable of generating amodal 3D bounding boxes and tracklets for training models on open-set categories without 3D human labels. Our pipeline exploits motion cues inherent in point cloud sequences in combination with the freely available 2D image-text pairs to identify and track all traffic participants. Compared to the recent studies in this domain, which can only provide class-agnostic auto labels limited to moving objects, our method can handle both static and moving objects in the unsupervised manner and is able to output open-vocabulary semantic labels thanks to the proposed vision-language knowledge distillation. Experiments on the Waymo Open Dataset show that our approach outperforms the prior work by significant margins on various unsupervised 3D perception tasks.
3D Human Keypoints Estimation From Point Clouds in the Wild Without Human Labels
Jun 07, 2023
Training a 3D human keypoint detector from point clouds in a supervised manner requires large volumes of high quality labels. While it is relatively easy to capture large amounts of human point clouds, annotating 3D keypoints is expensive, subjective, error prone and especially difficult for long-tail cases (pedestrians with rare poses, scooterists, etc.). In this work, we propose GC-KPL - Geometry Consistency inspired Key Point Leaning, an approach for learning 3D human joint locations from point clouds without human labels. We achieve this by our novel unsupervised loss formulations that account for the structure and movement of the human body. We show that by training on a large training set from Waymo Open Dataset without any human annotated keypoints, we are able to achieve reasonable performance as compared to the fully supervised approach. Further, the backbone benefits from the unsupervised training and is useful in downstream fewshot learning of keypoints, where fine-tuning on only 10 percent of the labeled training data gives comparable performance to fine-tuning on the entire set. We demonstrated that GC-KPL outperforms by a large margin over SoTA when trained on entire dataset and efficiently leverages large volumes of unlabeled data.
GINA-3D: Learning to Generate Implicit Neural Assets in the Wild
Apr 04, 2023



Modeling the 3D world from sensor data for simulation is a scalable way of developing testing and validation environments for robotic learning problems such as autonomous driving. However, manually creating or re-creating real-world-like environments is difficult, expensive, and not scalable. Recent generative model techniques have shown promising progress to address such challenges by learning 3D assets using only plentiful 2D images -- but still suffer limitations as they leverage either human-curated image datasets or renderings from manually-created synthetic 3D environments. In this paper, we introduce GINA-3D, a generative model that uses real-world driving data from camera and LiDAR sensors to create realistic 3D implicit neural assets of diverse vehicles and pedestrians. Compared to the existing image datasets, the real-world driving setting poses new challenges due to occlusions, lighting-variations and long-tail distributions. GINA-3D tackles these challenges by decoupling representation learning and generative modeling into two stages with a learned tri-plane latent structure, inspired by recent advances in generative modeling of images. To evaluate our approach, we construct a large-scale object-centric dataset containing over 520K images of vehicles and pedestrians from the Waymo Open Dataset, and a new set of 80K images of long-tail instances such as construction equipment, garbage trucks, and cable cars. We compare our model with existing approaches and demonstrate that it achieves state-of-the-art performance in quality and diversity for both generated images and geometries.
Improving the Intra-class Long-tail in 3D Detection via Rare Example Mining
Oct 15, 2022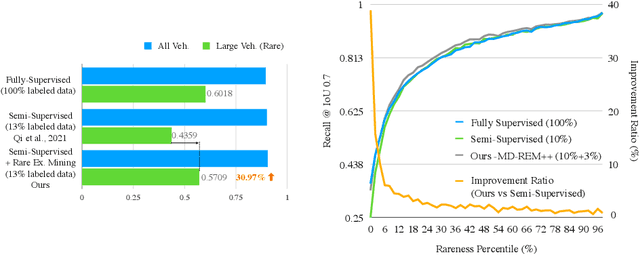
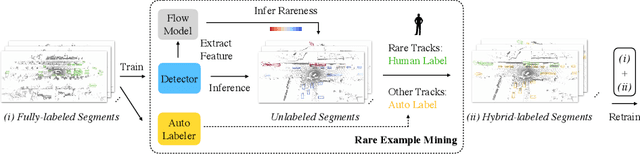
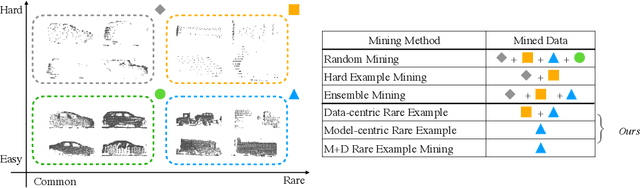
Continued improvements in deep learning architectures have steadily advanced the overall performance of 3D object detectors to levels on par with humans for certain tasks and datasets, where the overall performance is mostly driven by common examples. However, even the best performing models suffer from the most naive mistakes when it comes to rare examples that do not appear frequently in the training data, such as vehicles with irregular geometries. Most studies in the long-tail literature focus on class-imbalanced classification problems with known imbalanced label counts per class, but they are not directly applicable to the intra-class long-tail examples in problems with large intra-class variations such as 3D object detection, where instances with the same class label can have drastically varied properties such as shapes and sizes. Other works propose to mitigate this problem using active learning based on the criteria of uncertainty, difficulty, or diversity. In this study, we identify a new conceptual dimension - rareness - to mine new data for improving the long-tail performance of models. We show that rareness, as opposed to difficulty, is the key to data-centric improvements for 3D detectors, since rareness is the result of a lack in data support while difficulty is related to the fundamental ambiguity in the problem. We propose a general and effective method to identify the rareness of objects based on density estimation in the feature space using flow models, and propose a principled cost-aware formulation for mining rare object tracks, which improves overall model performance, but more importantly - significantly improves the performance for rare objects (by 30.97\%
Motion Inspired Unsupervised Perception and Prediction in Autonomous Driving
Oct 14, 2022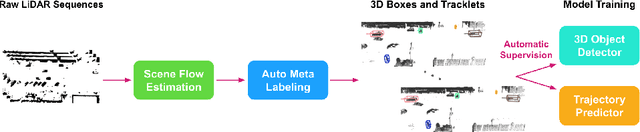
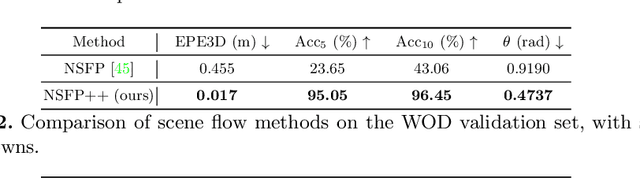

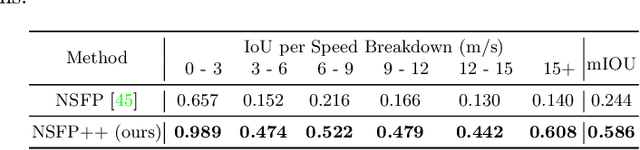
Learning-based perception and prediction modules in modern autonomous driving systems typically rely on expensive human annotation and are designed to perceive only a handful of predefined object categories. This closed-set paradigm is insufficient for the safety-critical autonomous driving task, where the autonomous vehicle needs to process arbitrarily many types of traffic participants and their motion behaviors in a highly dynamic world. To address this difficulty, this paper pioneers a novel and challenging direction, i.e., training perception and prediction models to understand open-set moving objects, with no human supervision. Our proposed framework uses self-learned flow to trigger an automated meta labeling pipeline to achieve automatic supervision. 3D detection experiments on the Waymo Open Dataset show that our method significantly outperforms classical unsupervised approaches and is even competitive to the counterpart with supervised scene flow. We further show that our approach generates highly promising results in open-set 3D detection and trajectory prediction, confirming its potential in closing the safety gap of fully supervised systems.
Revisiting 3D Object Detection From an Egocentric Perspective
Dec 14, 2021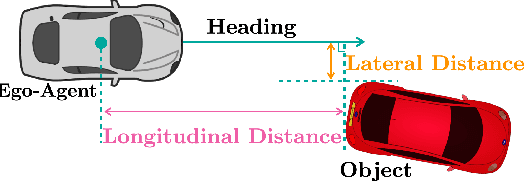
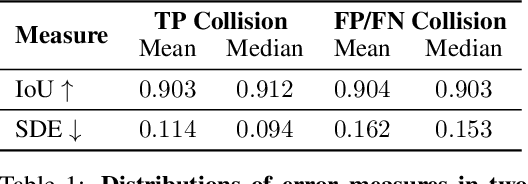
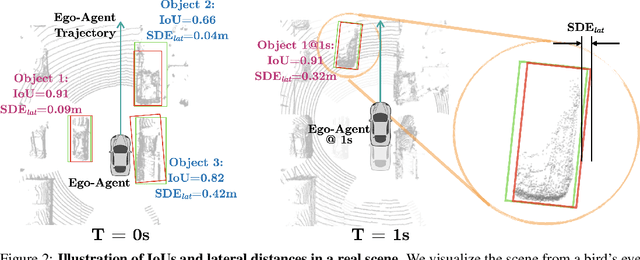
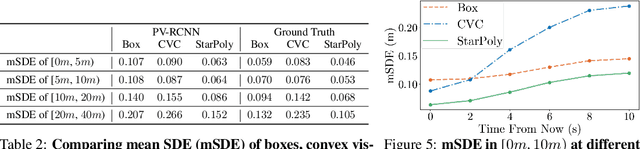
3D object detection is a key module for safety-critical robotics applications such as autonomous driving. For these applications, we care most about how the detections affect the ego-agent's behavior and safety (the egocentric perspective). Intuitively, we seek more accurate descriptions of object geometry when it's more likely to interfere with the ego-agent's motion trajectory. However, current detection metrics, based on box Intersection-over-Union (IoU), are object-centric and aren't designed to capture the spatio-temporal relationship between objects and the ego-agent. To address this issue, we propose a new egocentric measure to evaluate 3D object detection, namely Support Distance Error (SDE). Our analysis based on SDE reveals that the egocentric detection quality is bounded by the coarse geometry of the bounding boxes. Given the insight that SDE would benefit from more accurate geometry descriptions, we propose to represent objects as amodal contours, specifically amodal star-shaped polygons, and devise a simple model, StarPoly, to predict such contours. Our experiments on the large-scale Waymo Open Dataset show that SDE better reflects the impact of detection quality on the ego-agent's safety compared to IoU; and the estimated contours from StarPoly consistently improve the egocentric detection quality over recent 3D object detectors.
Offboard 3D Object Detection from Point Cloud Sequences
Mar 08, 2021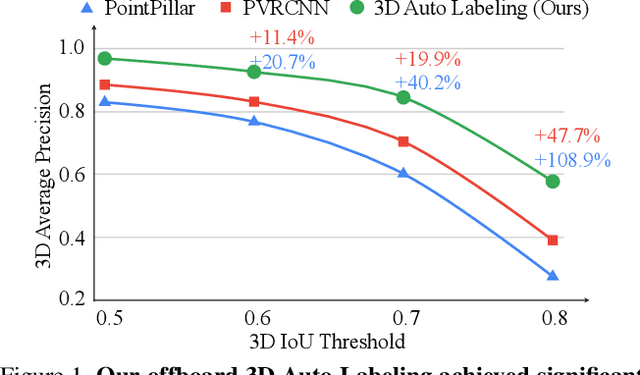
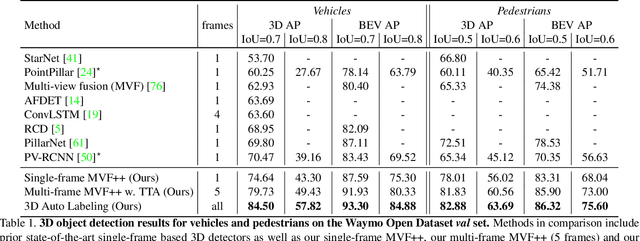
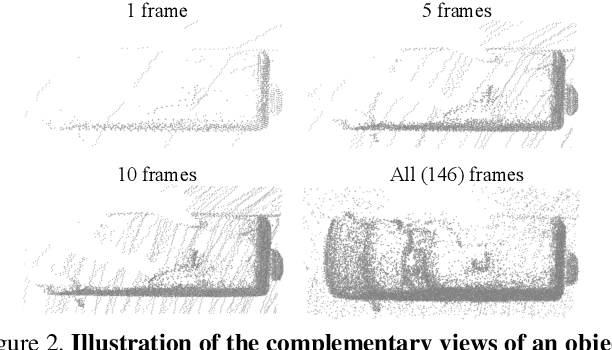

While current 3D object recognition research mostly focuses on the real-time, onboard scenario, there are many offboard use cases of perception that are largely under-explored, such as using machines to automatically generate high-quality 3D labels. Existing 3D object detectors fail to satisfy the high-quality requirement for offboard uses due to the limited input and speed constraints. In this paper, we propose a novel offboard 3D object detection pipeline using point cloud sequence data. Observing that different frames capture complementary views of objects, we design the offboard detector to make use of the temporal points through both multi-frame object detection and novel object-centric refinement models. Evaluated on the Waymo Open Dataset, our pipeline named 3D Auto Labeling shows significant gains compared to the state-of-the-art onboard detectors and our offboard baselines. Its performance is even on par with human labels verified through a human label study. Further experiments demonstrate the application of auto labels for semi-supervised learning and provide extensive analysis to validate various design choices.
Scale Normalized Image Pyramids with AutoFocus for Object Detection
Feb 10, 2021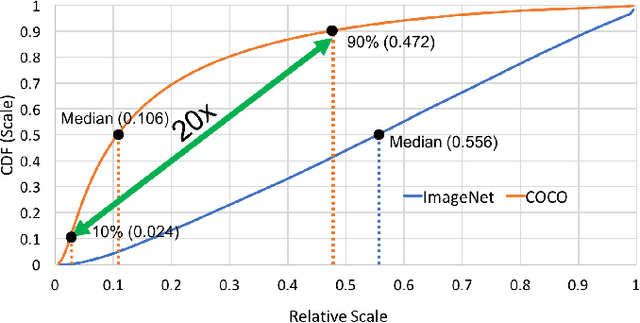

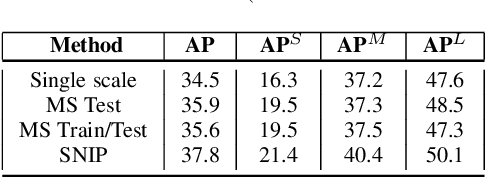
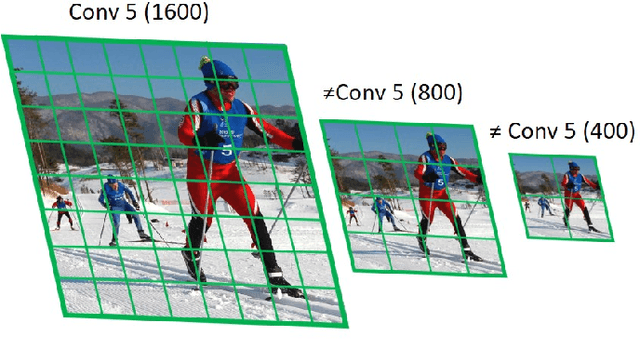
We present an efficient foveal framework to perform object detection. A scale normalized image pyramid (SNIP) is generated that, like human vision, only attends to objects within a fixed size range at different scales. Such a restriction of objects' size during training affords better learning of object-sensitive filters, and therefore, results in better accuracy. However, the use of an image pyramid increases the computational cost. Hence, we propose an efficient spatial sub-sampling scheme which only operates on fixed-size sub-regions likely to contain objects (as object locations are known during training). The resulting approach, referred to as Scale Normalized Image Pyramid with Efficient Resampling or SNIPER, yields up to 3 times speed-up during training. Unfortunately, as object locations are unknown during inference, the entire image pyramid still needs processing. To this end, we adopt a coarse-to-fine approach, and predict the locations and extent of object-like regions which will be processed in successive scales of the image pyramid. Intuitively, it's akin to our active human-vision that first skims over the field-of-view to spot interesting regions for further processing and only recognizes objects at the right resolution. The resulting algorithm is referred to as AutoFocus and results in a 2.5-5 times speed-up during inference when used with SNIP.
ASAP-NMS: Accelerating Non-Maximum Suppression Using Spatially Aware Priors
Aug 21, 2020

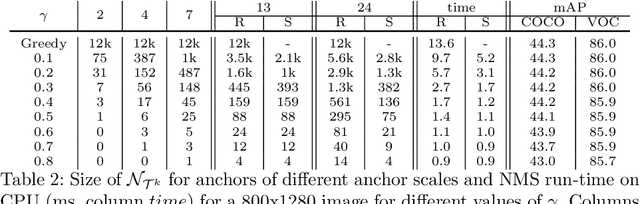

The widely adopted sequential variant of Non Maximum Suppression (or Greedy-NMS) is a crucial module for object-detection pipelines. Unfortunately, for the region proposal stage of two/multi-stage detectors, NMS is turning out to be a latency bottleneck due to its sequential nature. In this article, we carefully profile Greedy-NMS iterations to find that a major chunk of computation is wasted in comparing proposals that are already far-away and have a small chance of suppressing each other. We address this issue by comparing only those proposals that are generated from nearby anchors. The translation-invariant property of the anchor lattice affords generation of a lookup table, which provides an efficient access to nearby proposals, during NMS. This leads to an Accelerated NMS algorithm which leverages Spatially Aware Priors, or ASAP-NMS, and improves the latency of the NMS step from 13.6ms to 1.2 ms on a CPU without sacrificing the accuracy of a state-of-the-art two-stage detector on COCO and VOC datasets. Importantly, ASAP-NMS is agnostic to image resolution and can be used as a simple drop-in module during inference. Using ASAP-NMS at run-time only, we obtain an mAP of 44.2\%@25Hz on the COCO dataset with a V100 GPU.