 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Multi-Task Representation Learning by Two-Layer ReLU Neural Networks
Jul 17, 2023Feature learning, i.e. extracting meaningful representations of data, is quintessential to the practical success of neural networks trained with gradient descent, yet it is notoriously difficult to explain how and why it occurs. Recent theoretical studies have shown that shallow neural networks optimized on a single task with gradient-based methods can learn meaningful features, extending our understanding beyond the neural tangent kernel or random feature regime in which negligible feature learning occurs. But in practice, neural networks are increasingly often trained on {\em many} tasks simultaneously with differing loss functions, and these prior analyses do not generalize to such settings. In the multi-task learning setting, a variety of studies have shown effective feature learning by simple linear models. However, multi-task learning via {\em nonlinear} models, arguably the most common learning paradigm in practice, remains largely mysterious. In this work, we present the first results proving feature learning occurs in a multi-task setting with a nonlinear model. We show that when the tasks are binary classification problems with labels depending on only $r$ directions within the ambient $d\gg r$-dimensional input space, executing a simple gradient-based multitask learning algorithm on a two-layer ReLU neural network learns the ground-truth $r$ directions. In particular, any downstream task on the $r$ ground-truth coordinates can be solved by learning a linear classifier with sample and neuron complexity independent of the ambient dimension $d$, while a random feature model requires exponential complexity in $d$ for such a guarantee.
Don't Memorize; Mimic The Past: Federated Class Incremental Learning Without Episodic Memory
Jul 17, 2023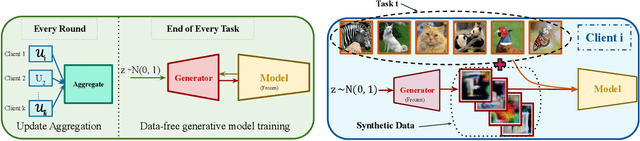
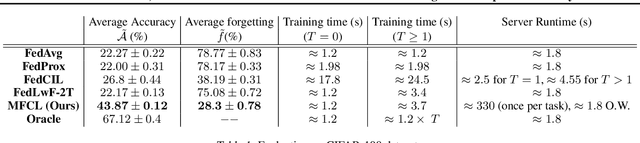

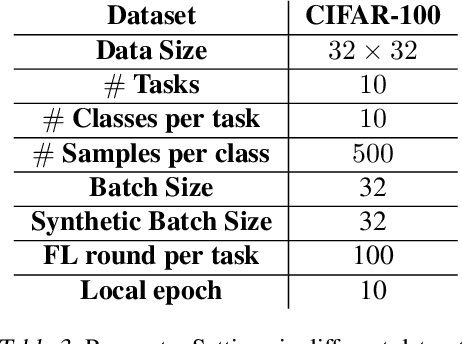
Deep learning models are prone to forgetting information learned in the past when trained on new data. This problem becomes even more pronounced in the context of federated learning (FL), where data is decentralized and subject to independent changes for each user. Continual Learning (CL) studies this so-called \textit{catastrophic forgetting} phenomenon primarily in centralized settings, where the learner has direct access to the complete training dataset. However, applying CL techniques to FL is not straightforward due to privacy concerns and resource limitations. This paper presents a framework for federated class incremental learning that utilizes a generative model to synthesize samples from past distributions instead of storing part of past data. Then, clients can leverage the generative model to mitigate catastrophic forgetting locally. The generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Therefore, it reduces the risk of data leakage as opposed to training it on the client's private data. We demonstrate significant improvements for the CIFAR-100 dataset compared to existing baselines.
On the Role of Attention in Prompt-tuning
Jun 06, 2023Prompt-tuning is an emerging strategy to adapt large language models (LLM) to downstream tasks by learning a (soft-)prompt parameter from data. Despite its success in LLMs, there is limited theoretical understanding of the power of prompt-tuning and the role of the attention mechanism in prompting. In this work, we explore prompt-tuning for one-layer attention architectures and study contextual mixture-models where each input token belongs to a context-relevant or -irrelevant set. We isolate the role of prompt-tuning through a self-contained prompt-attention model. Our contributions are as follows: (1) We show that softmax-prompt-attention is provably more expressive than softmax-self-attention and linear-prompt-attention under our contextual data model. (2) We analyze the initial trajectory of gradient descent and show that it learns the prompt and prediction head with near-optimal sample complexity and demonstrate how prompt can provably attend to sparse context-relevant tokens. (3) Assuming a known prompt but an unknown prediction head, we characterize the exact finite sample performance of prompt-attention which reveals the fundamental performance limits and the precise benefit of the context information. We also provide experiments that verify our theoretical insights on real datasets and demonstrate how prompt-tuning enables the model to attend to context-relevant information.
DiracDiffusion: Denoising and Incremental Reconstruction with Assured Data-Consistency
Mar 25, 2023



Diffusion models have established new state of the art in a multitude of computer vision tasks, including image restoration. Diffusion-based inverse problem solvers generate reconstructions of exceptional visual quality from heavily corrupted measurements. However, in what is widely known as the perception-distortion trade-off, the price of perceptually appealing reconstructions is often paid in declined distortion metrics, such as PSNR. Distortion metrics measure faithfulness to the observation, a crucial requirement in inverse problems. In this work, we propose a novel framework for inverse problem solving, namely we assume that the observation comes from a stochastic degradation process that gradually degrades and noises the original clean image. We learn to reverse the degradation process in order to recover the clean image. Our technique maintains consistency with the original measurement throughout the reverse process, and allows for great flexibility in trading off perceptual quality for improved distortion metrics and sampling speedup via early-stopping. We demonstrate the efficiency of our method on different high-resolution datasets and inverse problems, achieving great improvements over other state-of-the-art diffusion-based methods with respect to both perceptual and distortion metrics. Source code and pre-trained models will be released soon.
Implicit Balancing and Regularization: Generalization and Convergence Guarantees for Overparameterized Asymmetric Matrix Sensing
Mar 24, 2023



Recently, there has been significant progress in understanding the convergence and generalization properties of gradient-based methods for training overparameterized learning models. However, many aspects including the role of small random initialization and how the various parameters of the model are coupled during gradient-based updates to facilitate good generalization remain largely mysterious. A series of recent papers have begun to study this role for non-convex formulations of symmetric Positive Semi-Definite (PSD) matrix sensing problems which involve reconstructing a low-rank PSD matrix from a few linear measurements. The underlying symmetry/PSDness is crucial to existing convergence and generalization guarantees for this problem. In this paper, we study a general overparameterized low-rank matrix sensing problem where one wishes to reconstruct an asymmetric rectangular low-rank matrix from a few linear measurements. We prove that an overparameterized model trained via factorized gradient descent converges to the low-rank matrix generating the measurements. We show that in this setting, factorized gradient descent enjoys two implicit properties: (1) coupling of the trajectory of gradient descent where the factors are coupled in various ways throughout the gradient update trajectory and (2) an algorithmic regularization property where the iterates show a propensity towards low-rank models despite the overparameterized nature of the factorized model. These two implicit properties in turn allow us to show that the gradient descent trajectory from small random initialization moves towards solutions that are both globally optimal and generalize well.
CUDA: Convolution-based Unlearnable Datasets
Mar 07, 2023
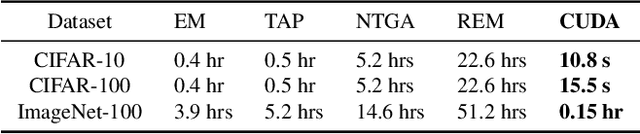
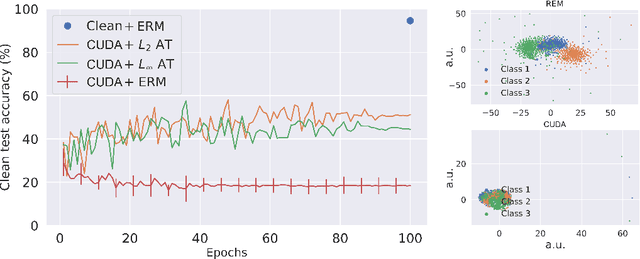
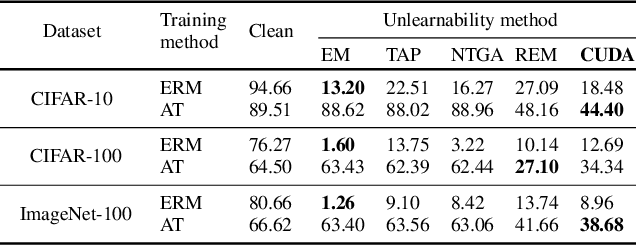
Large-scale training of modern deep learning models heavily relies on publicly available data on the web. This potentially unauthorized usage of online data leads to concerns regarding data privacy. Recent works aim to make unlearnable data for deep learning models by adding small, specially designed noises to tackle this issue. However, these methods are vulnerable to adversarial training (AT) and/or are computationally heavy. In this work, we propose a novel, model-free, Convolution-based Unlearnable DAtaset (CUDA) generation technique. CUDA is generated using controlled class-wise convolutions with filters that are randomly generated via a private key. CUDA encourages the network to learn the relation between filters and labels rather than informative features for classifying the clean data. We develop some theoretical analysis demonstrating that CUDA can successfully poison Gaussian mixture data by reducing the clean data performance of the optimal Bayes classifier. We also empirically demonstrate the effectiveness of CUDA with various datasets (CIFAR-10, CIFAR-100, ImageNet-100, and Tiny-ImageNet), and architectures (ResNet-18, VGG-16, Wide ResNet-34-10, DenseNet-121, DeIT, EfficientNetV2-S, and MobileNetV2). Our experiments show that CUDA is robust to various data augmentations and training approaches such as smoothing, AT with different budgets, transfer learning, and fine-tuning. For instance, training a ResNet-18 on ImageNet-100 CUDA achieves only 8.96$\%$, 40.08$\%$, and 20.58$\%$ clean test accuracies with empirical risk minimization (ERM), $L_{\infty}$ AT, and $L_{2}$ AT, respectively. Here, ERM on the clean training data achieves a clean test accuracy of 80.66$\%$. CUDA exhibits unlearnability effect with ERM even when only a fraction of the training dataset is perturbed. Furthermore, we also show that CUDA is robust to adaptive defenses designed specifically to break it.
SMILE: Scaling Mixture-of-Experts with Efficient Bi-level Routing
Dec 10, 2022



The mixture of Expert (MoE) parallelism is a recent advancement that scales up the model size with constant computational cost. MoE selects different sets of parameters (i.e., experts) for each incoming token, resulting in a sparsely-activated model. Despite several successful applications of MoE, its training efficiency degrades significantly as the number of experts increases. The routing stage in MoE relies on the efficiency of the All2All communication collective, which suffers from network congestion and has poor scalability. To mitigate these issues, we introduce SMILE, which exploits heterogeneous network bandwidth and splits a single-step routing into bi-level routing. Our experimental results show that the proposed method obtains a 2.5x speedup over Switch Transformer in terms of pretraining throughput on the Colossal Clean Crawled Corpus without losing any convergence speed.
The Geometry of Self-supervised Learning Models and its Impact on Transfer Learning
Sep 18, 2022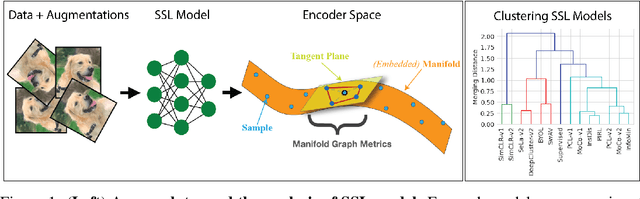
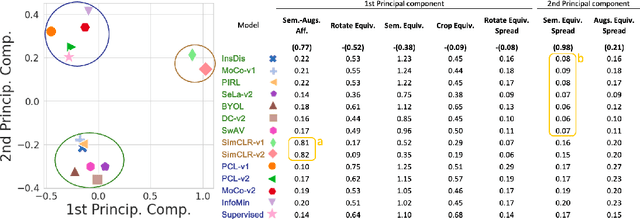
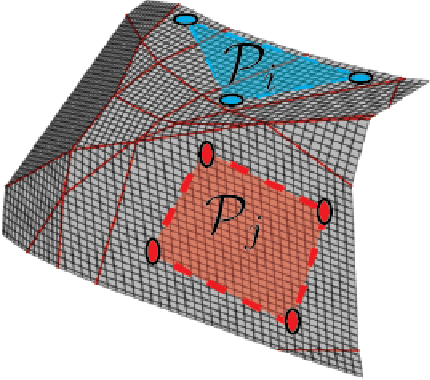
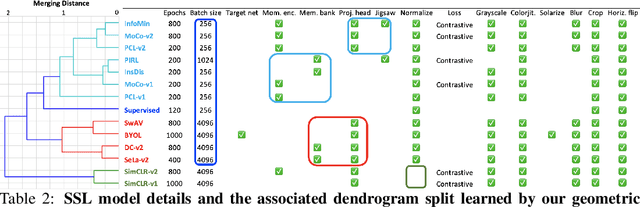
Self-supervised learning (SSL) has emerged as a desirable paradigm in computer vision due to the inability of supervised models to learn representations that can generalize in domains with limited labels. The recent popularity of SSL has led to the development of several models that make use of diverse training strategies, architectures, and data augmentation policies with no existing unified framework to study or assess their effectiveness in transfer learning. We propose a data-driven geometric strategy to analyze different SSL models using local neighborhoods in the feature space induced by each. Unlike existing approaches that consider mathematical approximations of the parameters, individual components, or optimization landscape, our work aims to explore the geometric properties of the representation manifolds learned by SSL models. Our proposed manifold graph metrics (MGMs) provide insights into the geometric similarities and differences between available SSL models, their invariances with respect to specific augmentations, and their performances on transfer learning tasks. Our key findings are two fold: (i) contrary to popular belief, the geometry of SSL models is not tied to its training paradigm (contrastive, non-contrastive, and cluster-based); (ii) we can predict the transfer learning capability for a specific model based on the geometric properties of its semantic and augmentation manifolds.
Neural Networks can Learn Representations with Gradient Descent
Jun 30, 2022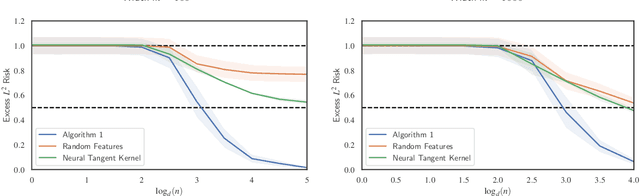
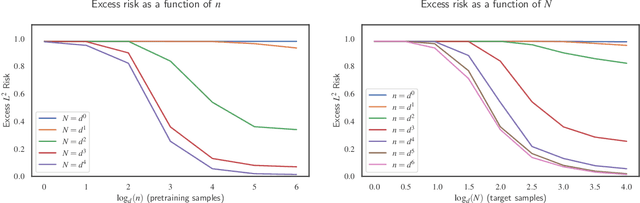
Significant theoretical work has established that in specific regimes, neural networks trained by gradient descent behave like kernel methods. However, in practice, it is known that neural networks strongly outperform their associated kernels. In this work, we explain this gap by demonstrating that there is a large class of functions which cannot be efficiently learned by kernel methods but can be easily learned with gradient descent on a two layer neural network outside the kernel regime by learning representations that are relevant to the target task. We also demonstrate that these representations allow for efficient transfer learning, which is impossible in the kernel regime. Specifically, we consider the problem of learning polynomials which depend on only a few relevant directions, i.e. of the form $f^\star(x) = g(Ux)$ where $U: \R^d \to \R^r$ with $d \gg r$. When the degree of $f^\star$ is $p$, it is known that $n \asymp d^p$ samples are necessary to learn $f^\star$ in the kernel regime. Our primary result is that gradient descent learns a representation of the data which depends only on the directions relevant to $f^\star$. This results in an improved sample complexity of $n\asymp d^2 r + dr^p$. Furthermore, in a transfer learning setup where the data distributions in the source and target domain share the same representation $U$ but have different polynomial heads we show that a popular heuristic for transfer learning has a target sample complexity independent of $d$.
Toward a Geometrical Understanding of Self-supervised Contrastive Learning
May 13, 2022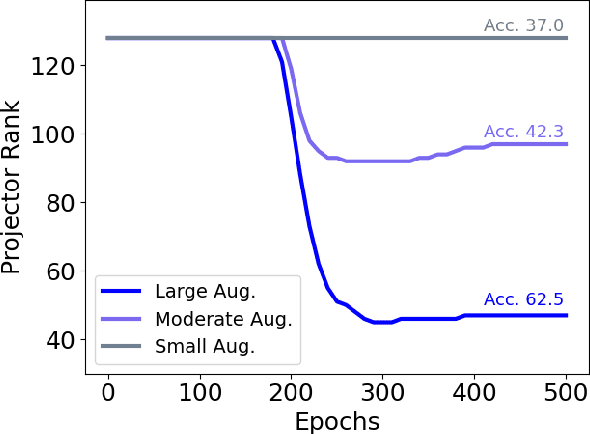

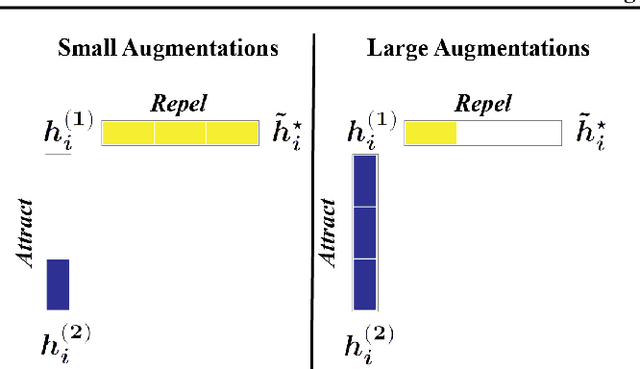

Self-supervised learning (SSL) is currently one of the premier techniques to create data representations that are actionable for transfer learning in the absence of human annotations. Despite their success, the underlying geometry of these representations remains elusive, which obfuscates the quest for more robust, trustworthy, and interpretable models. In particular, mainstream SSL techniques rely on a specific deep neural network architecture with two cascaded neural networks: the encoder and the projector. When used for transfer learning, the projector is discarded since empirical results show that its representation generalizes more poorly than the encoder's. In this paper, we investigate this curious phenomenon and analyze how the strength of the data augmentation policies affects the data embedding. We discover a non-trivial relation between the encoder, the projector, and the data augmentation strength: with increasingly larger augmentation policies, the projector, rather than the encoder, is more strongly driven to become invariant to the augmentations. It does so by eliminating crucial information about the data by learning to project it into a low-dimensional space, a noisy estimate of the data manifold tangent plane in the encoder representation. This analysis is substantiated through a geometrical perspective with theoretical and empirical results.