 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivation Prompting: A Logic-Based Method for Improving Retrieval-Augmented Generation
May 13, 2026The application of Large Language Models to Question Answering has shown great promise, but important challenges such as hallucinations and erroneous reasoning arise when using these models, particularly in knowledge-intensive, domain-specific tasks. To address these issues, we introduce Derivation Prompting, a novel prompting technique for the generation step of the Retrieval-Augmented Generation framework. Inspired by logic derivations, this method involves deriving conclusions from initial hypotheses through the systematic application of predefined rules. It constructs a derivation tree that is interpretable and adds control over the generation process. We applied this method in a specific case study, significantly reducing unacceptable answers compared to traditional RAG and long-context window methods.
Concept Tokens: Learning Behavioral Embeddings Through Concept Definitions
Jan 08, 2026We propose Concept Tokens, a lightweight method that adds a new special token to a pretrained LLM and learns only its embedding from multiple natural language definitions of a target concept, where occurrences of the concept are replaced by the new token. The LLM is kept frozen and the embedding is optimized with the standard language-modeling objective. We evaluate Concept Tokens in three settings. First, we study hallucinations in closed-book question answering on HotpotQA and find a directional effect: negating the hallucination token reduces hallucinated answers mainly by increasing abstentions, whereas asserting it increases hallucinations and lowers precision. Second, we induce recasting, a pedagogical feedback strategy for second language teaching, and observe the same directional effect. Moreover, compared to providing the full definitional corpus in-context, concept tokens better preserve compliance with other instructions (e.g., asking follow-up questions). Finally, we include a qualitative study with the Eiffel Tower and a fictional "Austral Tower" to illustrate what information the learned embeddings capture and where their limitations emerge. Overall, Concept Tokens provide a compact control signal learned from definitions that can steer behavior in frozen LLMs.
Memory Tokens: Large Language Models Can Generate Reversible Sentence Embeddings
Jun 17, 2025In this work, we observe an interesting phenomenon: it is possible to generate reversible sentence embeddings that allow an LLM to reconstruct the original text exactly, without modifying the model's weights. This is achieved by introducing a special memory token, whose embedding is optimized through training on a fixed sequence. When prompted with this embedding, the model reconstructs the fixed sequence exactly. We evaluate this phenomenon across English and Spanish datasets, sequences of up to approximately 240 tokens, and model scales ranging from 100M to 8B parameters. Notably, Llama 3.1 8B successfully reconstructs all tested sequences. Our findings highlight an interesting capability of LLMs and suggest potential applications in memory-based retrieval, compression, and controlled text generation.
RETUYT-INCO at BEA 2025 Shared Task: How Far Can Lightweight Models Go in AI-powered Tutor Evaluation?
Jun 12, 2025



In this paper, we present the RETUYT-INCO participation at the BEA 2025 shared task. Our participation was characterized by the decision of using relatively small models, with fewer than 1B parameters. This self-imposed restriction tries to represent the conditions in which many research labs or institutions are in the Global South, where computational power is not easily accessible due to its prohibitive cost. Even under this restrictive self-imposed setting, our models managed to stay competitive with the rest of teams that participated in the shared task. According to the $exact\ F_1$ scores published by the organizers, the performance gaps between our models and the winners were as follows: $6.46$ in Track 1; $10.24$ in Track 2; $7.85$ in Track 3; $9.56$ in Track 4; and $13.13$ in Track 5. Considering that the minimum difference with a winner team is $6.46$ points -- and the maximum difference is $13.13$ -- according to the $exact\ F_1$ score, we find that models with a size smaller than 1B parameters are competitive for these tasks, all of which can be run on computers with a low-budget GPU or even without a GPU.
A Platform for Generating Educational Activities to Teach English as a Second Language
Apr 28, 2025



We present a platform for the generation of educational activities oriented to teaching English as a foreign language. The different activities -- games and language practice exercises -- are strongly based on Natural Language Processing techniques. The platform offers the possibility of playing out-of-the-box games, generated from resources created semi-automatically and then manually curated. It can also generate games or exercises of greater complexity from texts entered by teachers, providing a stage of review and edition of the generated content before use. As a way of expanding the variety of activities in the platform, we are currently experimenting with image and text generation. In order to integrate them and improve the performance of other neural tools already integrated, we are working on migrating the platform to a more powerful server. In this paper we describe the development of our platform and its deployment for end users, discussing the challenges faced and how we overcame them, and also detail our future work plans.
A Crowd-Annotated Spanish Corpus for Humor Analysis
Jul 19, 2018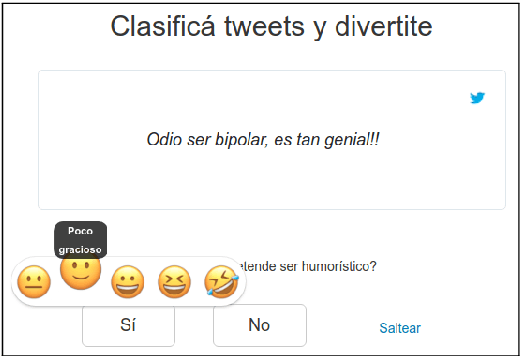
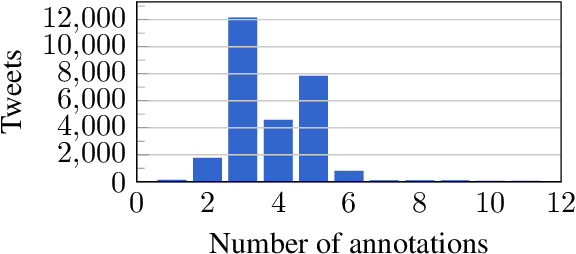
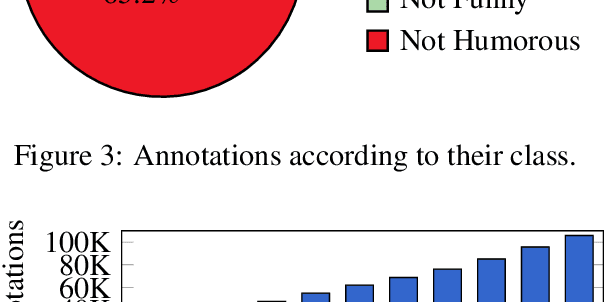
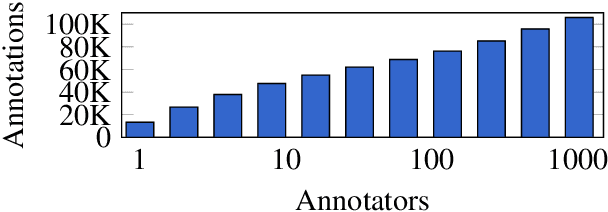
Computational Humor involves several tasks, such as humor recognition, humor generation, and humor scoring, for which it is useful to have human-curated data. In this work we present a corpus of 27,000 tweets written in Spanish and crowd-annotated by their humor value and funniness score, with about four annotations per tweet, tagged by 1,300 people over the Internet. It is equally divided between tweets coming from humorous and non-humorous accounts. The inter-annotator agreement Krippendorff's alpha value is 0.5710. The dataset is available for general use and can serve as a basis for humor detection and as a first step to tackle subjectivity.
RETUYT in TASS 2017: Sentiment Analysis for Spanish Tweets using SVM and CNN
Oct 17, 2017This article presents classifiers based on SVM and Convolutional Neural Networks (CNN) for the TASS 2017 challenge on tweets sentiment analysis. The classifier with the best performance in general uses a combination of SVM and CNN. The use of word embeddings was particularly useful for improving the classifiers performance.
* in Spanish. Published in http://ceur-ws.org/Vol-1896/p9_retuyt_tass2017.pdf