 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivation Prompting: A Logic-Based Method for Improving Retrieval-Augmented Generation
May 13, 2026The application of Large Language Models to Question Answering has shown great promise, but important challenges such as hallucinations and erroneous reasoning arise when using these models, particularly in knowledge-intensive, domain-specific tasks. To address these issues, we introduce Derivation Prompting, a novel prompting technique for the generation step of the Retrieval-Augmented Generation framework. Inspired by logic derivations, this method involves deriving conclusions from initial hypotheses through the systematic application of predefined rules. It constructs a derivation tree that is interpretable and adds control over the generation process. We applied this method in a specific case study, significantly reducing unacceptable answers compared to traditional RAG and long-context window methods.
A Crowd-Annotated Spanish Corpus for Humor Analysis
Jul 19, 2018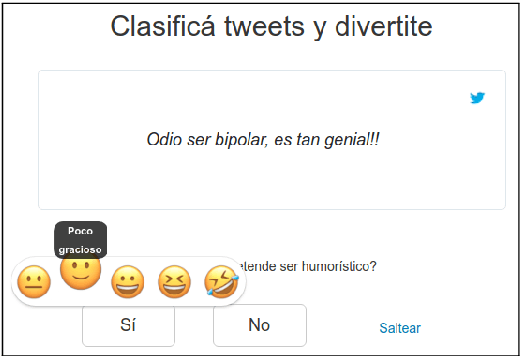
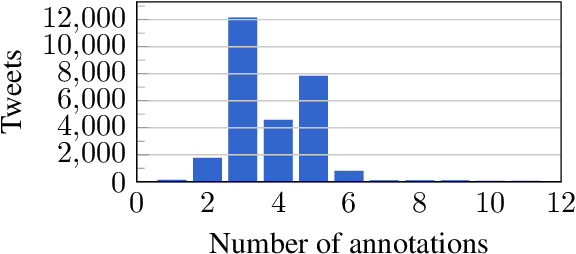
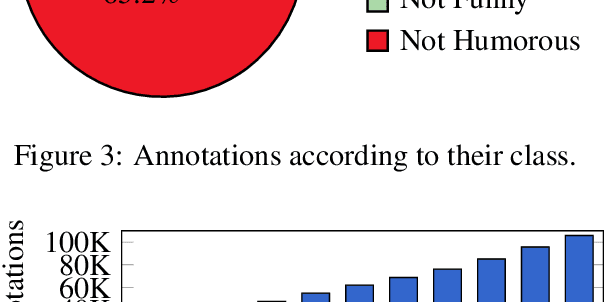
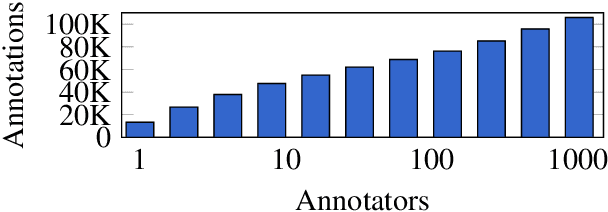
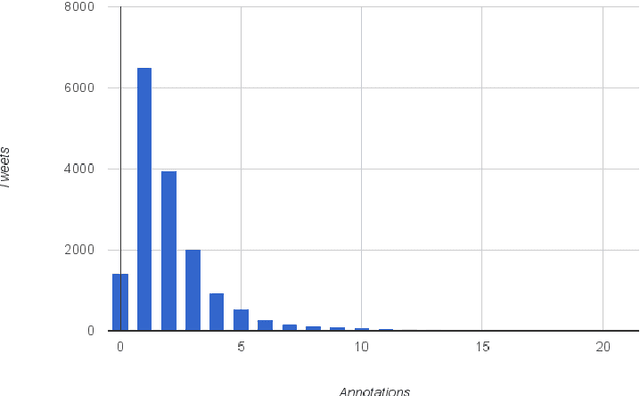
Computational Humor involves several tasks, such as humor recognition, humor generation, and humor scoring, for which it is useful to have human-curated data. In this work we present a corpus of 27,000 tweets written in Spanish and crowd-annotated by their humor value and funniness score, with about four annotations per tweet, tagged by 1,300 people over the Internet. It is equally divided between tweets coming from humorous and non-humorous accounts. The inter-annotator agreement Krippendorff's alpha value is 0.5710. The dataset is available for general use and can serve as a basis for humor detection and as a first step to tackle subjectivity.
Is This a Joke? Detecting Humor in Spanish Tweets
Mar 28, 2017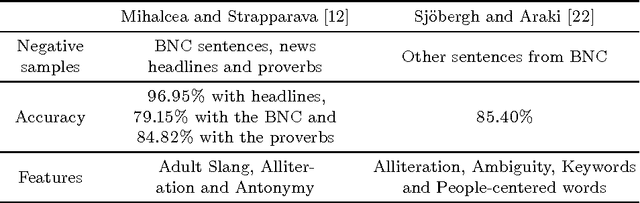
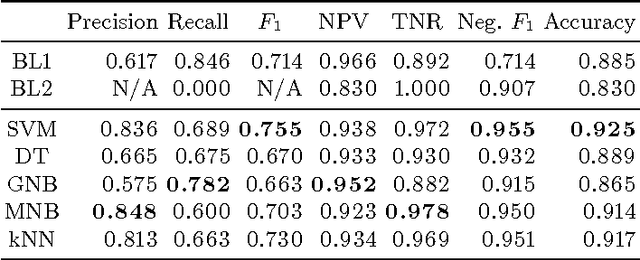
While humor has been historically studied from a psychological, cognitive and linguistic standpoint, its study from a computational perspective is an area yet to be explored in Computational Linguistics. There exist some previous works, but a characterization of humor that allows its automatic recognition and generation is far from being specified. In this work we build a crowdsourced corpus of labeled tweets, annotated according to its humor value, letting the annotators subjectively decide which are humorous. A humor classifier for Spanish tweets is assembled based on supervised learning, reaching a precision of 84% and a recall of 69%.
* Preprint version, without referral