 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Learning Technique for Video Segmentation
Jul 02, 2021
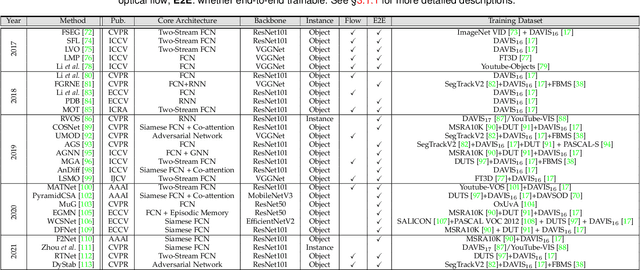
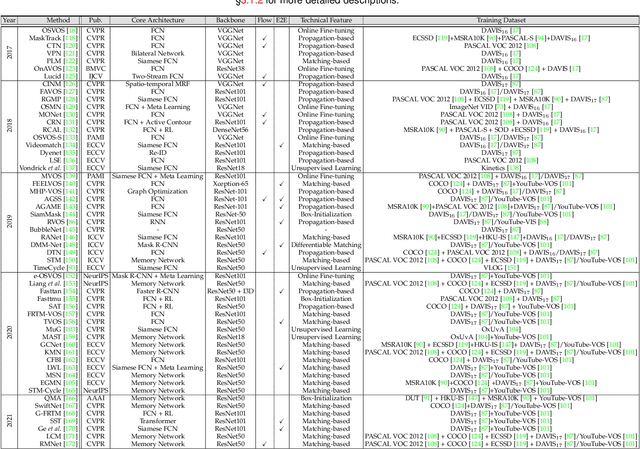

Video segmentation, i.e., partitioning video frames into multiple segments or objects, plays a critical role in a broad range of practical applications, e.g., visual effect assistance in movie, scene understanding in autonomous driving, and virtual background creation in video conferencing, to name a few. Recently, due to the renaissance of connectionism in computer vision, there has been an influx of numerous deep learning based approaches that have been dedicated to video segmentation and delivered compelling performance. In this survey, we comprehensively review two basic lines of research in this area, i.e., generic object segmentation (of unknown categories) in videos and video semantic segmentation, by introducing their respective task settings, background concepts, perceived need, development history, and main challenges. We also provide a detailed overview of representative literature on both methods and datasets. Additionally, we present quantitative performance comparisons of the reviewed methods on benchmark datasets. At last, we point out a set of unsolved open issues in this field, and suggest possible opportunities for further research.
Generative Flows with Invertible Attentions
Jun 26, 2021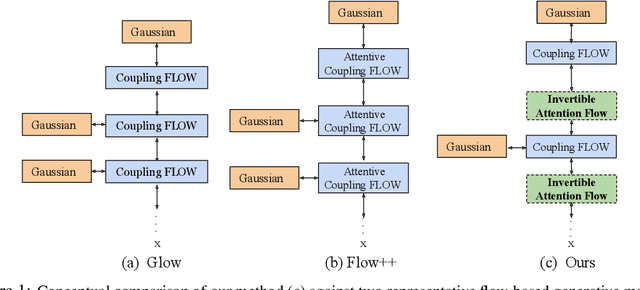
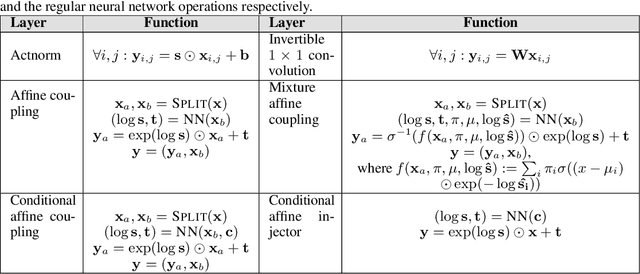
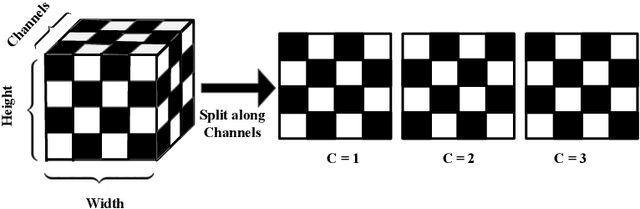
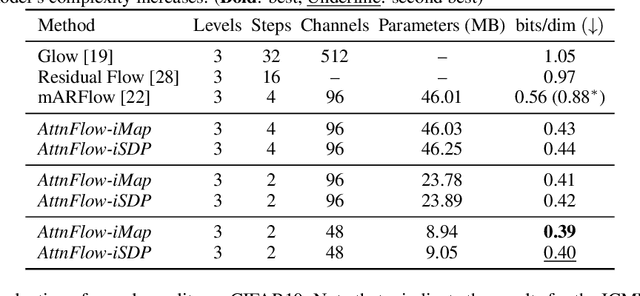
Flow-based generative models have shown excellent ability to explicitly learn the probability density function of data via a sequence of invertible transformations. Yet, modeling long-range dependencies over normalizing flows remains understudied. To fill the gap, in this paper, we introduce two types of invertible attention mechanisms for generative flow models. To be precise, we propose map-based and scaled dot-product attention for unconditional and conditional generative flow models. The key idea is to exploit split-based attention mechanisms to learn the attention weights and input representations on every two splits of flow feature maps. Our method provides invertible attention modules with tractable Jacobian determinants, enabling seamless integration of it at any positions of the flow-based models. The proposed attention mechanism can model the global data dependencies, leading to more comprehensive flow models. Evaluation on multiple generation tasks demonstrates that the introduced attention flow idea results in efficient flow models and compares favorably against the state-of-the-art unconditional and conditional generative flow methods.
Go with the Flows: Mixtures of Normalizing Flows for Point Cloud Generation and Reconstruction
Jun 18, 2021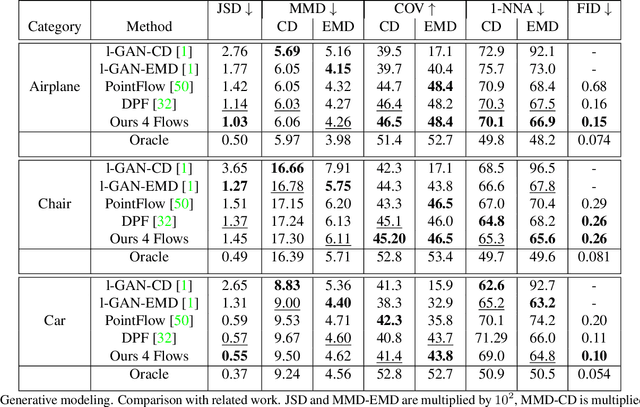
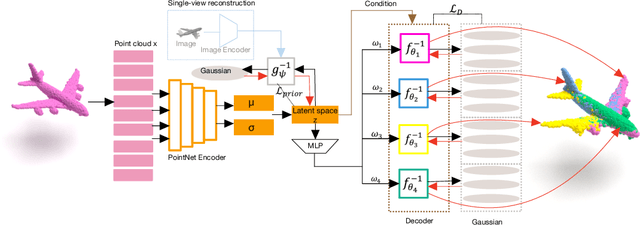
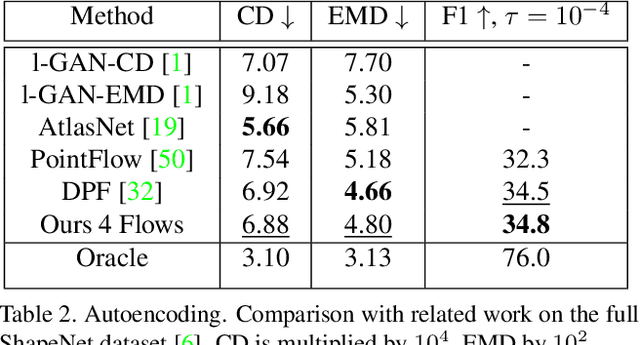
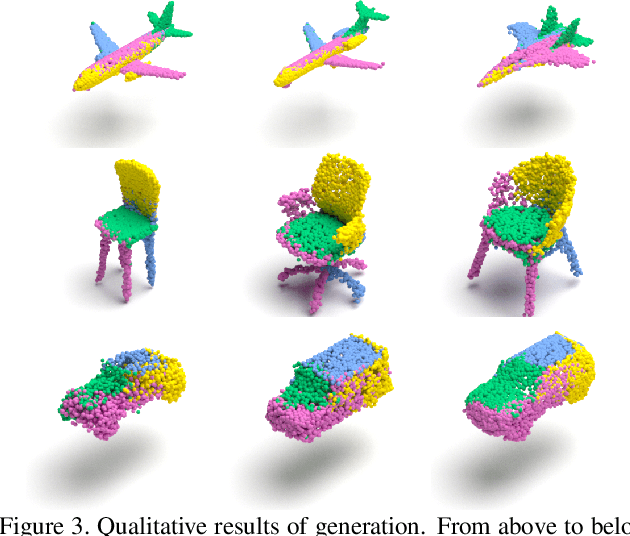
Recently normalizing flows (NFs) have demonstrated state-of-the-art performance on modeling 3D point clouds while allowing sampling with arbitrary resolution at inference time. However, these flow-based models still require long training times and large models for representing complicated geometries. This work enhances their representational power by applying mixtures of NFs to point clouds. We show that in this more general framework each component learns to specialize in a particular subregion of an object in a completely unsupervised fashion. By instantiating each mixture component with a comparatively small NF we generate point clouds with improved details compared to single-flow-based models while using fewer parameters and considerably reducing the inference runtime. We further demonstrate that by adding data augmentation, individual mixture components can learn to specialize in a semantically meaningful manner. We evaluate mixtures of NFs on generation, autoencoding and single-view reconstruction based on the ShapeNet dataset.
Video Super-Resolution Transformer
Jun 12, 2021
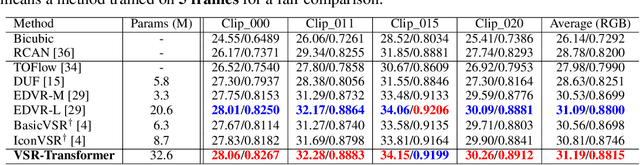
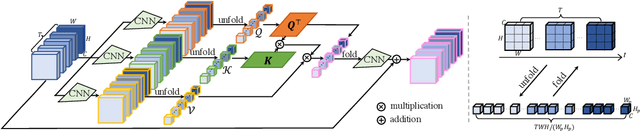

Video super-resolution (VSR), with the aim to restore a high-resolution video from its corresponding low-resolution version, is a spatial-temporal sequence prediction problem. Recently, Transformer has been gaining popularity due to its parallel computing ability for sequence-to-sequence modeling. Thus, it seems to be straightforward to apply the vision Transformer to solve VSR. However, the typical block design of Transformer with a fully connected self-attention layer and a token-wise feed-forward layer does not fit well for VSR due to the following two reasons. First, the fully connected self-attention layer neglects to exploit the data locality because this layer relies on linear layers to compute attention maps. Second, the token-wise feed-forward layer lacks the feature alignment which is important for VSR since this layer independently processes each of the input token embeddings without any interaction among them. In this paper, we make the first attempt to adapt Transformer for VSR. Specifically, to tackle the first issue, we present a spatial-temporal convolutional self-attention layer with a theoretical understanding to exploit the locality information. For the second issue, we design a bidirectional optical flow-based feed-forward layer to discover the correlations across different video frames and also align features. Extensive experiments on several benchmark datasets demonstrate the effectiveness of our proposed method. The code will be available at https://github.com/caojiezhang/VSR-Transformer.
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations
Jun 10, 2021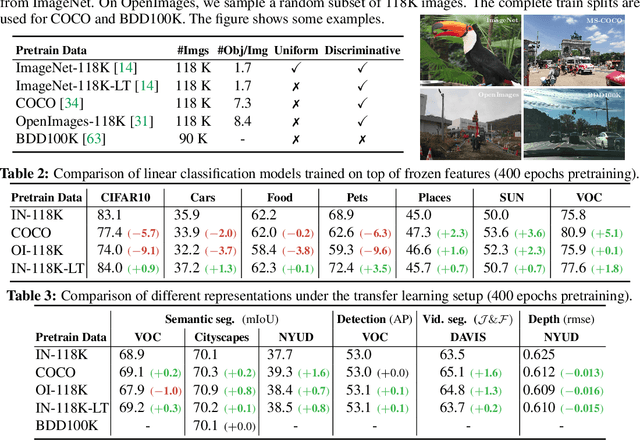
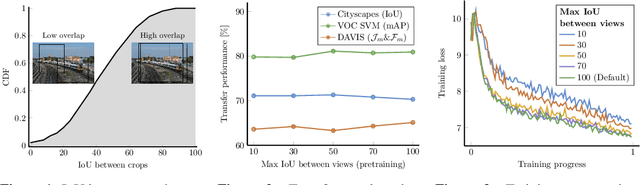
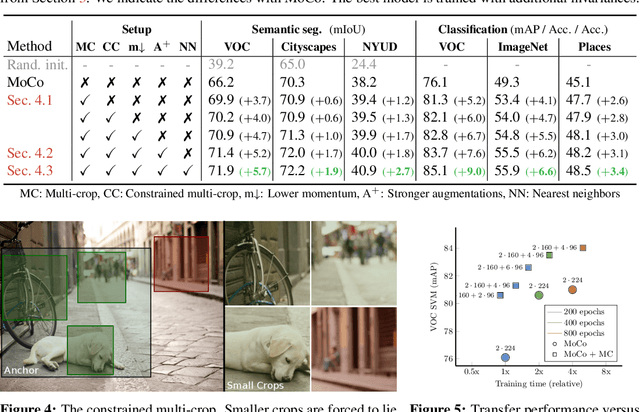
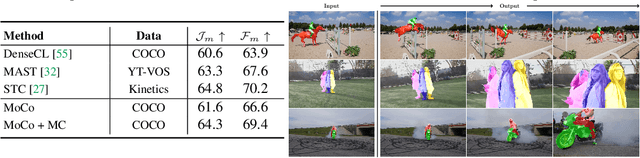
Contrastive self-supervised learning has outperformed supervised pretraining on many downstream tasks like segmentation and object detection. However, current methods are still primarily applied to curated datasets like ImageNet. In this paper, we first study how biases in the dataset affect existing methods. Our results show that current contrastive approaches work surprisingly well across: (i) object- versus scene-centric, (ii) uniform versus long-tailed and (iii) general versus domain-specific datasets. Second, given the generality of the approach, we try to realize further gains with minor modifications. We show that learning additional invariances -- through the use of multi-scale cropping, stronger augmentations and nearest neighbors -- improves the representations. Finally, we observe that MoCo learns spatially structured representations when trained with a multi-crop strategy. The representations can be used for semantic segment retrieval and video instance segmentation without finetuning. Moreover, the results are on par with specialized models. We hope this work will serve as a useful study for other researchers. The code and models will be available at https://github.com/wvangansbeke/Revisiting-Contrastive-SSL.
Transformer in Convolutional Neural Networks
Jun 09, 2021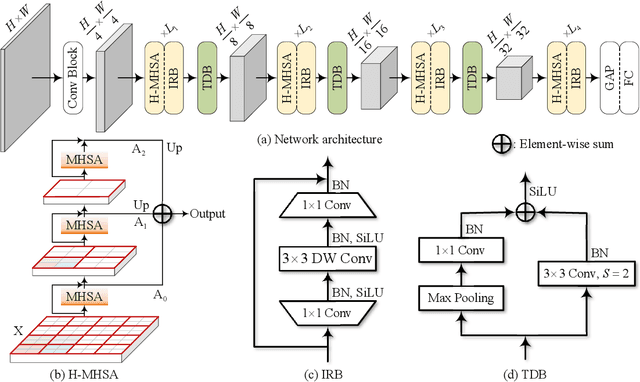
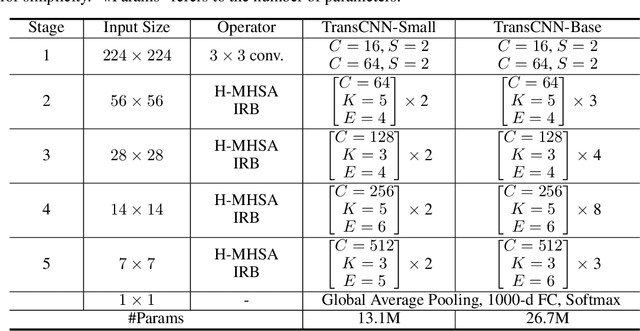

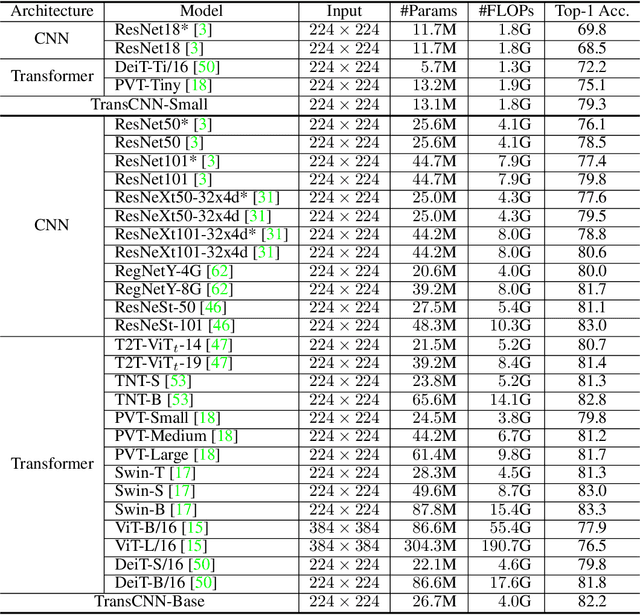
We tackle the low-efficiency flaw of vision transformer caused by the high computational/space complexity in Multi-Head Self-Attention (MHSA). To this end, we propose the Hierarchical MHSA (H-MHSA), whose representation is computed in a hierarchical manner. Specifically, our H-MHSA first learns feature relationships within small grids by viewing image patches as tokens. Then, small grids are merged into larger ones, within which feature relationship is learned by viewing each small grid at the preceding step as a token. This process is iterated to gradually reduce the number of tokens. The H-MHSA module is readily pluggable into any CNN architectures and amenable to training via backpropagation. We call this new backbone TransCNN, and it essentially inherits the advantages of both transformer and CNN. Experiments demonstrate that TransCNN achieves state-of-the-art accuracy for image recognition. Code and pretrained models are available at https://github.com/yun-liu/TransCNN. This technical report will keep updating by adding more experiments.
Fourier Space Losses for Efficient Perceptual Image Super-Resolution
Jun 01, 2021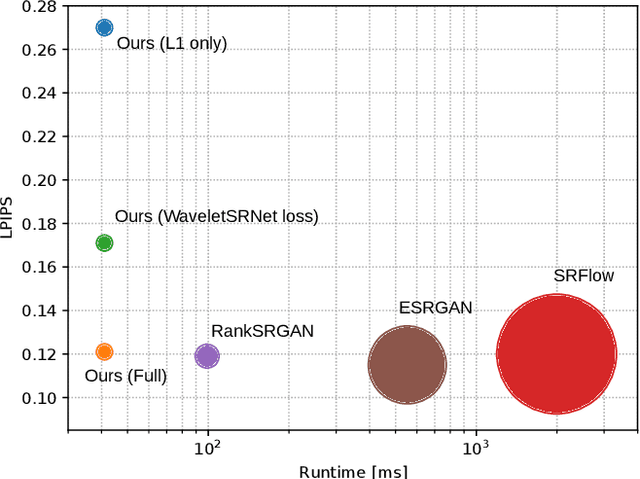

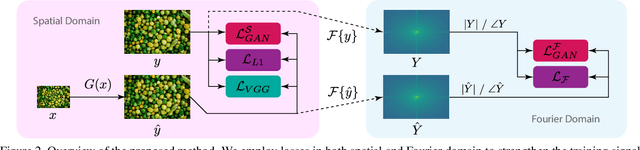
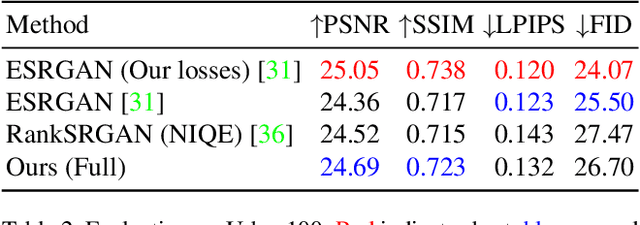
Many super-resolution (SR) models are optimized for high performance only and therefore lack efficiency due to large model complexity. As large models are often not practical in real-world applications, we investigate and propose novel loss functions, to enable SR with high perceptual quality from much more efficient models. The representative power for a given low-complexity generator network can only be fully leveraged by strong guidance towards the optimal set of parameters. We show that it is possible to improve the performance of a recently introduced efficient generator architecture solely with the application of our proposed loss functions. In particular, we use a Fourier space supervision loss for improved restoration of missing high-frequency (HF) content from the ground truth image and design a discriminator architecture working directly in the Fourier domain to better match the target HF distribution. We show that our losses' direct emphasis on the frequencies in Fourier-space significantly boosts the perceptual image quality, while at the same time retaining high restoration quality in comparison to previously proposed loss functions for this task. The performance is further improved by utilizing a combination of spatial and frequency domain losses, as both representations provide complementary information during training. On top of that, the trained generator achieves comparable results with and is 2.4x and 48x faster than state-of-the-art perceptual SR methods RankSRGAN and SRFlow respectively.
Boosting Crowd Counting with Transformers
May 23, 2021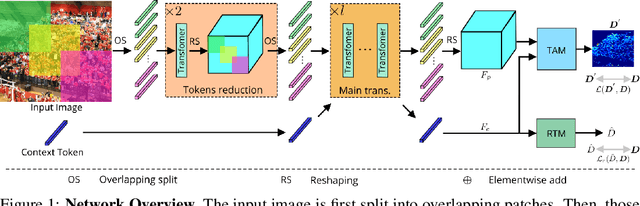
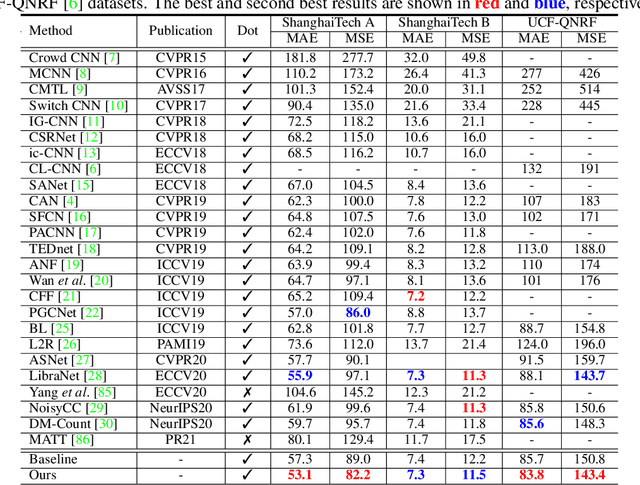
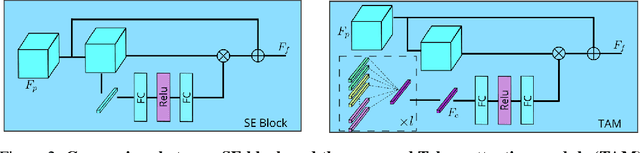
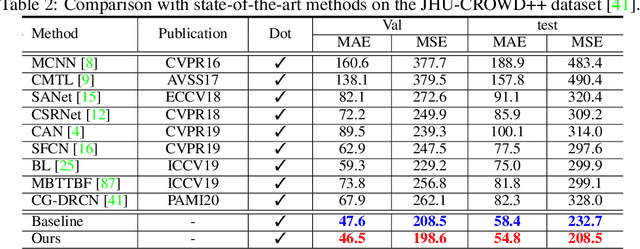
Significant progress on the crowd counting problem has been achieved by integrating larger context into convolutional neural networks (CNNs). This indicates that global scene context is essential, despite the seemingly bottom-up nature of the problem. This may be explained by the fact that context knowledge can adapt and improve local feature extraction to a given scene. In this paper, we therefore investigate the role of global context for crowd counting. Specifically, a pure transformer is used to extract features with global information from overlapping image patches. Inspired by classification, we add a context token to the input sequence, to facilitate information exchange with tokens corresponding to image patches throughout transformer layers. Due to the fact that transformers do not explicitly model the tried-and-true channel-wise interactions, we propose a token-attention module (TAM) to recalibrate encoded features through channel-wise attention informed by the context token. Beyond that, it is adopted to predict the total person count of the image through regression-token module (RTM). Extensive experiments demonstrate that our method achieves state-of-the-art performance on various datasets, including ShanghaiTech, UCF-QNRF, JHU-CROWD++ and NWPU. On the large-scale JHU-CROWD++ dataset, our method improves over the previous best results by 26.9% and 29.9% in terms of MAE and MSE, respectively.
Unsupervised Compound Domain Adaptation for Face Anti-Spoofing
May 18, 2021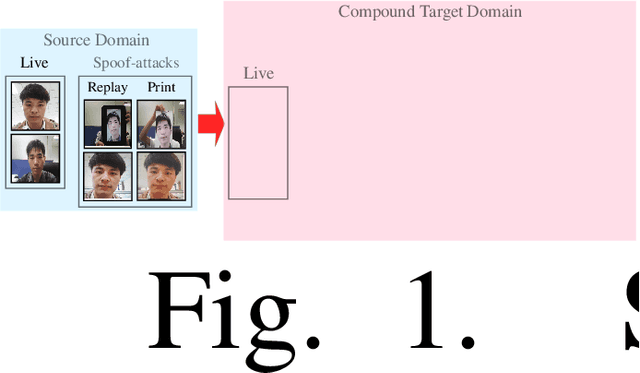
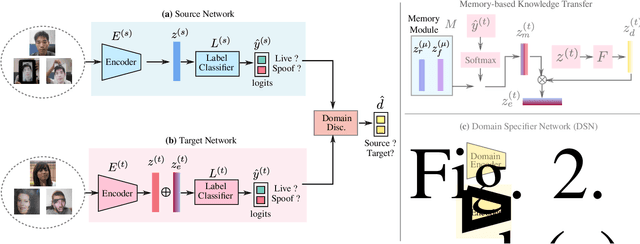
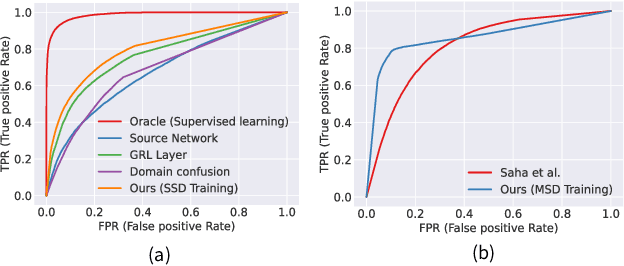
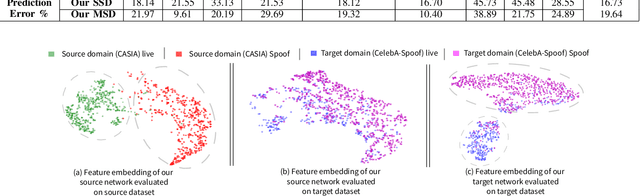
We address the problem of face anti-spoofing which aims to make the face verification systems robust in the real world settings. The context of detecting live vs. spoofed face images may differ significantly in the target domain, when compared to that of labeled source domain where the model is trained. Such difference may be caused due to new and unknown spoof types, illumination conditions, scene backgrounds, among many others. These varieties of differences make the target a compound domain, thus calling for the problem of the unsupervised compound domain adaptation. We demonstrate the effectiveness of the compound domain assumption for the task of face anti-spoofing, for the first time in this work. To this end, we propose a memory augmentation method for adapting the source model to the target domain in a domain aware manner. The adaptation process is further improved by using the curriculum learning and the domain agnostic source network training approaches. The proposed method successfully adapts to the compound target domain consisting multiple new spoof types. Our experiments on multiple benchmark datasets demonstrate the superiority of the proposed method over the state-of-the-art.
Learning to Relate Depth and Semantics for Unsupervised Domain Adaptation
May 17, 2021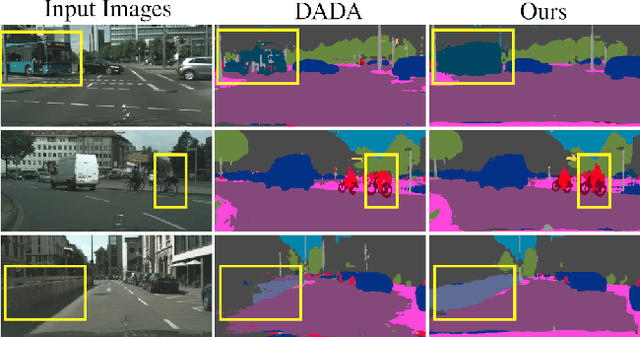
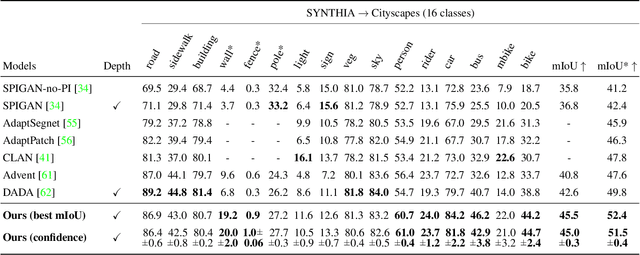

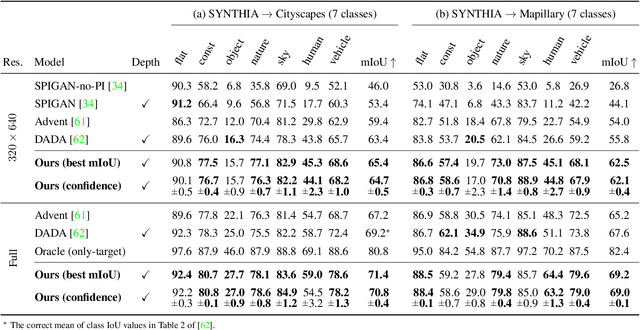
We present an approach for encoding visual task relationships to improve model performance in an Unsupervised Domain Adaptation (UDA) setting. Semantic segmentation and monocular depth estimation are shown to be complementary tasks; in a multi-task learning setting, a proper encoding of their relationships can further improve performance on both tasks. Motivated by this observation, we propose a novel Cross-Task Relation Layer (CTRL), which encodes task dependencies between the semantic and depth predictions. To capture the cross-task relationships, we propose a neural network architecture that contains task-specific and cross-task refinement heads. Furthermore, we propose an Iterative Self-Learning (ISL) training scheme, which exploits semantic pseudo-labels to provide extra supervision on the target domain. We experimentally observe improvements in both tasks' performance because the complementary information present in these tasks is better captured. Specifically, we show that: (1) our approach improves performance on all tasks when they are complementary and mutually dependent; (2) the CTRL helps to improve both semantic segmentation and depth estimation tasks performance in the challenging UDA setting; (3) the proposed ISL training scheme further improves the semantic segmentation performance. The implementation is available at https://github.com/susaha/ctrl-uda.