 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundations and Recent Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions
Sep 07, 2022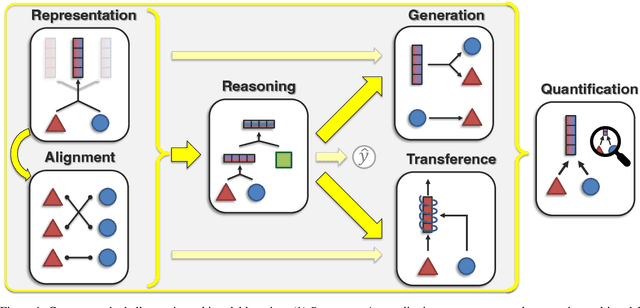
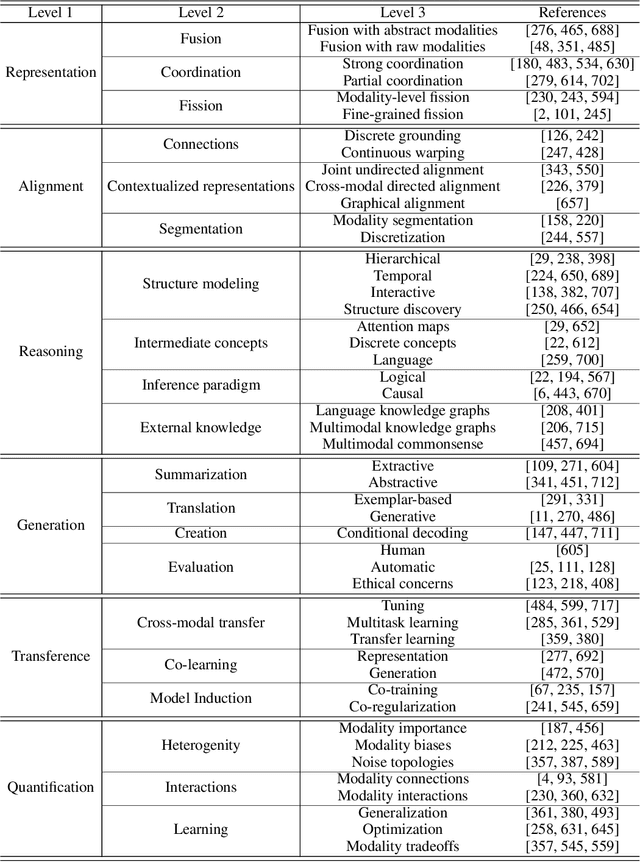
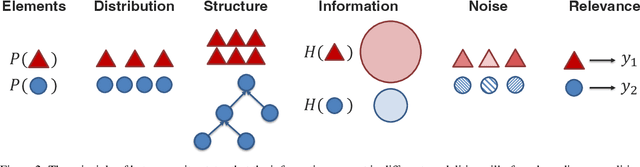
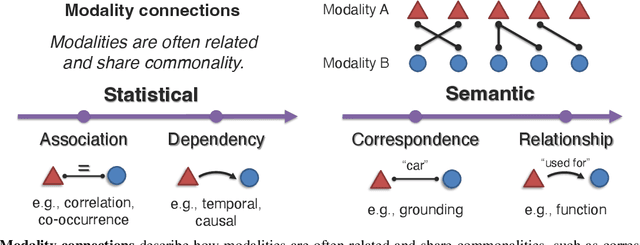
Multimodal machine learning is a vibrant multi-disciplinary research field that aims to design computer agents with intelligent capabilities such as understanding, reasoning, and learning through integrating multiple communicative modalities, including linguistic, acoustic, visual, tactile, and physiological messages. With the recent interest in video understanding, embodied autonomous agents, text-to-image generation, and multisensor fusion in application domains such as healthcare and robotics, multimodal machine learning has brought unique computational and theoretical challenges to the machine learning community given the heterogeneity of data sources and the interconnections often found between modalities. However, the breadth of progress in multimodal research has made it difficult to identify the common themes and open questions in the field. By synthesizing a broad range of application domains and theoretical frameworks from both historical and recent perspectives, this paper is designed to provide an overview of the computational and theoretical foundations of multimodal machine learning. We start by defining two key principles of modality heterogeneity and interconnections that have driven subsequent innovations, and propose a taxonomy of 6 core technical challenges: representation, alignment, reasoning, generation, transference, and quantification covering historical and recent trends. Recent technical achievements will be presented through the lens of this taxonomy, allowing researchers to understand the similarities and differences across new approaches. We end by motivating several open problems for future research as identified by our taxonomy.
Multimodal Lecture Presentations Dataset: Understanding Multimodality in Educational Slides
Aug 17, 2022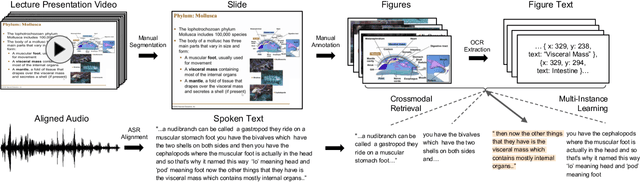
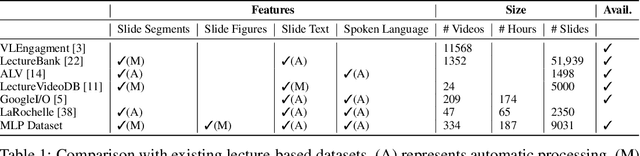
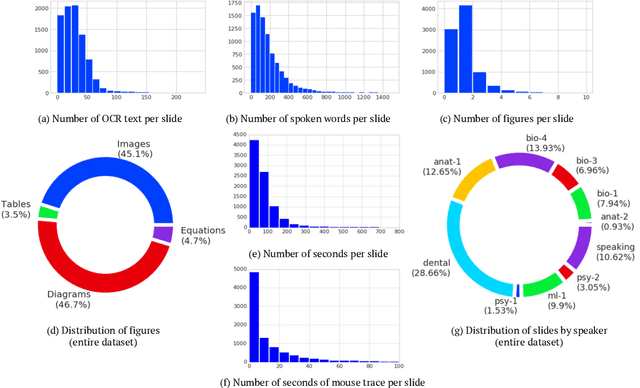
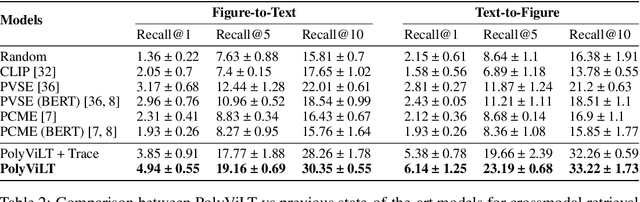
Lecture slide presentations, a sequence of pages that contain text and figures accompanied by speech, are constructed and presented carefully in order to optimally transfer knowledge to students. Previous studies in multimedia and psychology attribute the effectiveness of lecture presentations to their multimodal nature. As a step toward developing AI to aid in student learning as intelligent teacher assistants, we introduce the Multimodal Lecture Presentations dataset as a large-scale benchmark testing the capabilities of machine learning models in multimodal understanding of educational content. Our dataset contains aligned slides and spoken language, for 180+ hours of video and 9000+ slides, with 10 lecturers from various subjects (e.g., computer science, dentistry, biology). We introduce two research tasks which are designed as stepping stones towards AI agents that can explain (automatically captioning a lecture presentation) and illustrate (synthesizing visual figures to accompany spoken explanations) educational content. We provide manual annotations to help implement these two research tasks and evaluate state-of-the-art models on them. Comparing baselines and human student performances, we find that current models struggle in (1) weak crossmodal alignment between slides and spoken text, (2) learning novel visual mediums, (3) technical language, and (4) long-range sequences. Towards addressing this issue, we also introduce PolyViLT, a multimodal transformer trained with a multi-instance learning loss that is more effective than current approaches. We conclude by shedding light on the challenges and opportunities in multimodal understanding of educational presentations.
Face-to-Face Contrastive Learning for Social Intelligence Question-Answering
Aug 15, 2022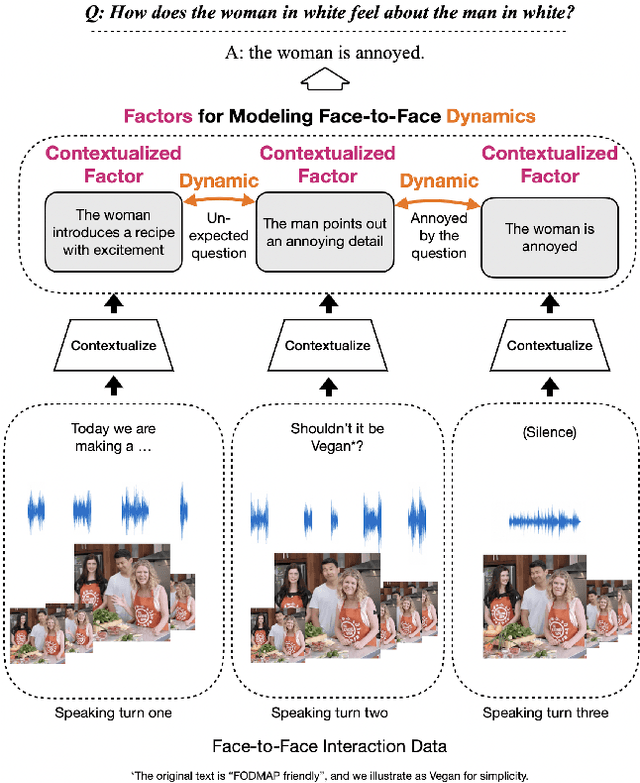
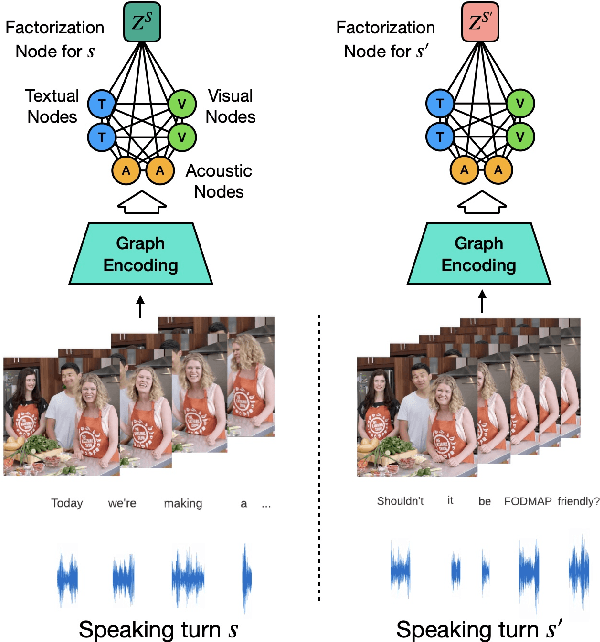
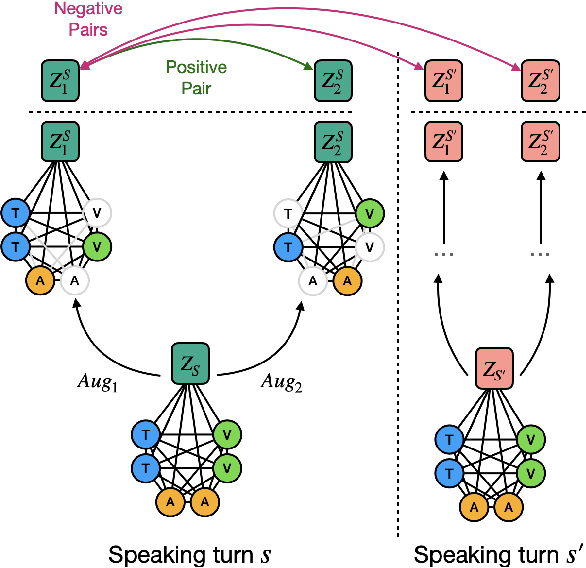
Creating artificial social intelligence - algorithms that can understand the nuances of multi-person interactions - is an exciting and emerging challenge in processing facial expressions and gestures from multimodal videos. Recent multimodal methods have set the state of the art on many tasks, but have difficulty modeling the complex face-to-face conversational dynamics across speaking turns in social interaction, particularly in a self-supervised setup. In this paper, we propose Face-to-Face Contrastive Learning (F2F-CL), a graph neural network designed to model social interactions using factorization nodes to contextualize the multimodal face-to-face interaction along the boundaries of the speaking turn. With the F2F-CL model, we propose to perform contrastive learning between the factorization nodes of different speaking turns within the same video. We experimentally evaluated the challenging Social-IQ dataset and show state-of-the-art results.
MultiViz: An Analysis Benchmark for Visualizing and Understanding Multimodal Models
Jun 30, 2022


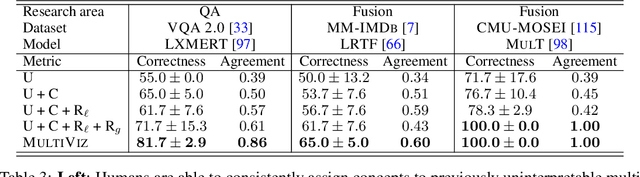
The promise of multimodal models for real-world applications has inspired research in visualizing and understanding their internal mechanics with the end goal of empowering stakeholders to visualize model behavior, perform model debugging, and promote trust in machine learning models. However, modern multimodal models are typically black-box neural networks, which makes it challenging to understand their internal mechanics. How can we visualize the internal modeling of multimodal interactions in these models? Our paper aims to fill this gap by proposing MultiViz, a method for analyzing the behavior of multimodal models by scaffolding the problem of interpretability into 4 stages: (1) unimodal importance: how each modality contributes towards downstream modeling and prediction, (2) cross-modal interactions: how different modalities relate with each other, (3) multimodal representations: how unimodal and cross-modal interactions are represented in decision-level features, and (4) multimodal prediction: how decision-level features are composed to make a prediction. MultiViz is designed to operate on diverse modalities, models, tasks, and research areas. Through experiments on 8 trained models across 6 real-world tasks, we show that the complementary stages in MultiViz together enable users to (1) simulate model predictions, (2) assign interpretable concepts to features, (3) perform error analysis on model misclassifications, and (4) use insights from error analysis to debug models. MultiViz is publicly available, will be regularly updated with new interpretation tools and metrics, and welcomes inputs from the community.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
PACS: A Dataset for Physical Audiovisual CommonSense Reasoning
Mar 21, 2022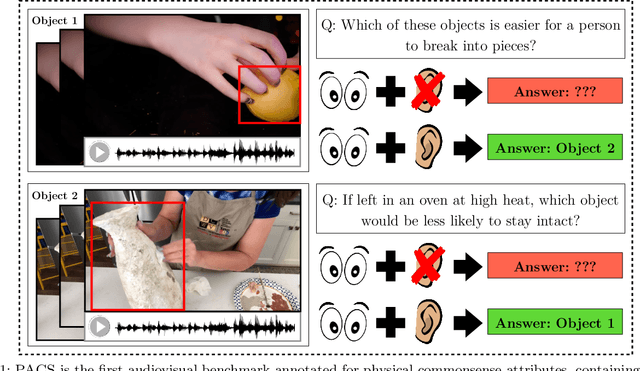
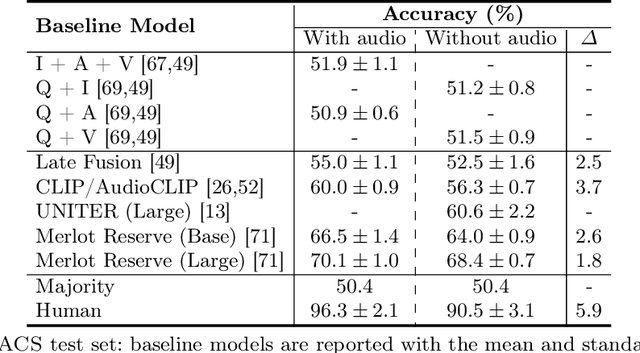
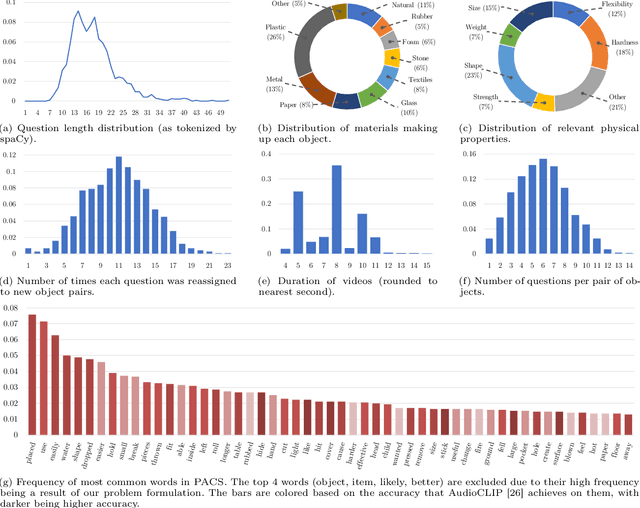
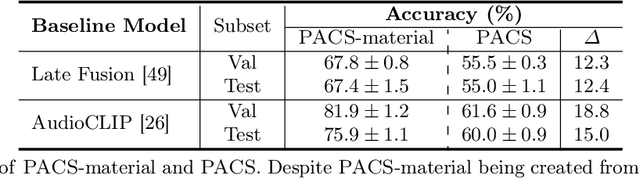
In order for AI to be safely deployed in real-world scenarios such as hospitals, schools, and the workplace, they should be able to reason about the physical world by understanding the physical properties and affordances of available objects, how they can be manipulated, and how they interact with other physical objects. This research field of physical commonsense reasoning is fundamentally a multi-sensory task since physical properties are manifested through multiple modalities, two of them being vision and acoustics. Our paper takes a step towards real-world physical commonsense reasoning by contributing PACS: the first audiovisual benchmark annotated for physical commonsense attributes. PACS contains a total of 13,400 question-answer pairs, involving 1,377 unique physical commonsense questions and 1,526 videos. Our dataset provides new opportunities to advance the research field of physical reasoning by bringing audio as a core component of this multimodal problem. Using PACS, we evaluate multiple state-of-the-art models on this new challenging task. While some models show promising results (70% accuracy), they all fall short of human performance (95% accuracy). We conclude the paper by demonstrating the importance of multimodal reasoning and providing possible avenues for future research.
HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
Mar 04, 2022
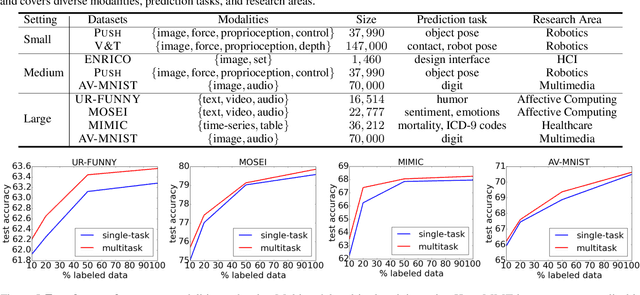
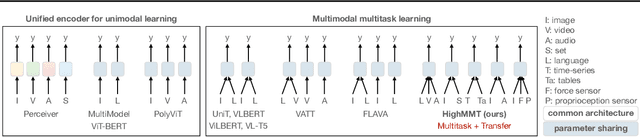
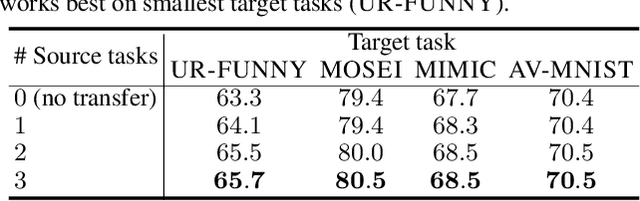
Learning multimodal representations involves discovering correspondences and integrating information from multiple heterogeneous sources of data. While recent research has begun to explore the design of more general-purpose multimodal models (contrary to prior focus on domain and modality-specific architectures), these methods are still largely focused on a small set of modalities in the language, vision, and audio space. In order to accelerate generalization towards diverse and understudied modalities, we investigate methods for high-modality (a large set of diverse modalities) and partially-observable (each task only defined on a small subset of modalities) scenarios. To tackle these challenges, we design a general multimodal model that enables multitask and transfer learning: multitask learning with shared parameters enables stable parameter counts (addressing scalability), and cross-modal transfer learning enables information sharing across modalities and tasks (addressing partial observability). Our resulting model generalizes across text, image, video, audio, time-series, sensors, tables, and set modalities from different research areas, improves the tradeoff between performance and efficiency, transfers to new modalities and tasks, and reveals surprising insights on the nature of information sharing in multitask models. We release our code and benchmarks which we hope will present a unified platform for subsequent theoretical and empirical analysis: https://github.com/pliang279/HighMMT.
DIME: Fine-grained Interpretations of Multimodal Models via Disentangled Local Explanations
Mar 03, 2022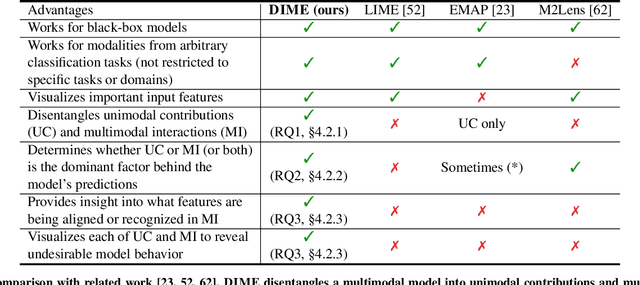
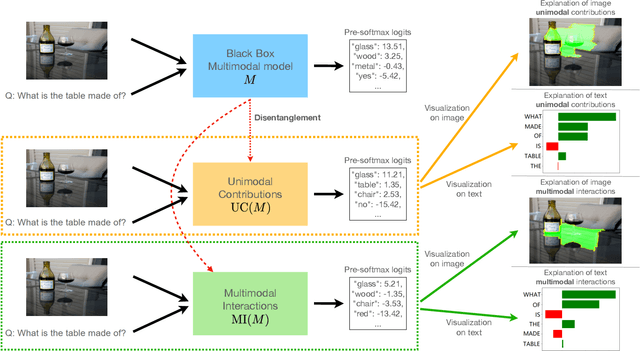

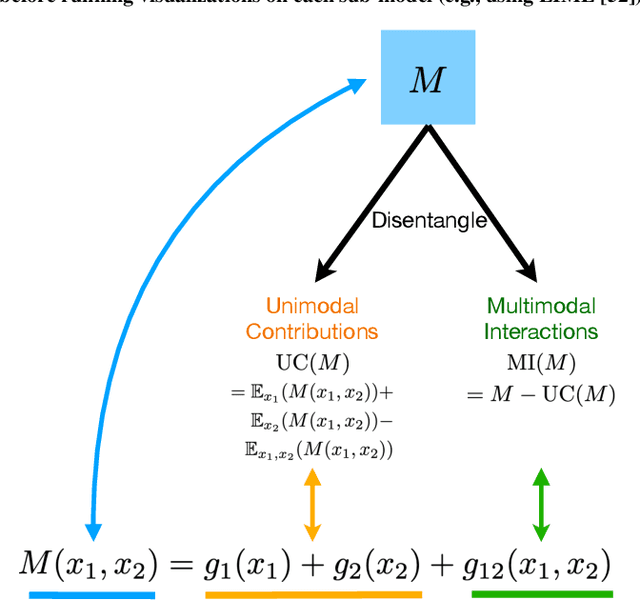
The ability for a human to understand an Artificial Intelligence (AI) model's decision-making process is critical in enabling stakeholders to visualize model behavior, perform model debugging, promote trust in AI models, and assist in collaborative human-AI decision-making. As a result, the research fields of interpretable and explainable AI have gained traction within AI communities as well as interdisciplinary scientists seeking to apply AI in their subject areas. In this paper, we focus on advancing the state-of-the-art in interpreting multimodal models - a class of machine learning methods that tackle core challenges in representing and capturing interactions between heterogeneous data sources such as images, text, audio, and time-series data. Multimodal models have proliferated numerous real-world applications across healthcare, robotics, multimedia, affective computing, and human-computer interaction. By performing model disentanglement into unimodal contributions (UC) and multimodal interactions (MI), our proposed approach, DIME, enables accurate and fine-grained analysis of multimodal models while maintaining generality across arbitrary modalities, model architectures, and tasks. Through a comprehensive suite of experiments on both synthetic and real-world multimodal tasks, we show that DIME generates accurate disentangled explanations, helps users of multimodal models gain a deeper understanding of model behavior, and presents a step towards debugging and improving these models for real-world deployment. Code for our experiments can be found at https://github.com/lvyiwei1/DIME.
Learning Weakly-Supervised Contrastive Representations
Feb 18, 2022



We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
Conditional Contrastive Learning with Kernel
Feb 14, 2022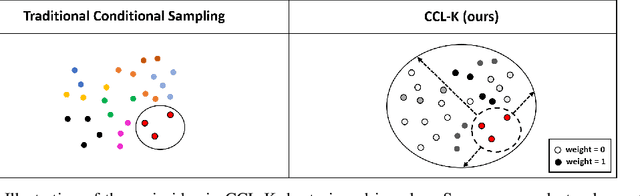



Conditional contrastive learning frameworks consider the conditional sampling procedure that constructs positive or negative data pairs conditioned on specific variables. Fair contrastive learning constructs negative pairs, for example, from the same gender (conditioning on sensitive information), which in turn reduces undesirable information from the learned representations; weakly supervised contrastive learning constructs positive pairs with similar annotative attributes (conditioning on auxiliary information), which in turn are incorporated into the representations. Although conditional contrastive learning enables many applications, the conditional sampling procedure can be challenging if we cannot obtain sufficient data pairs for some values of the conditioning variable. This paper presents Conditional Contrastive Learning with Kernel (CCL-K) that converts existing conditional contrastive objectives into alternative forms that mitigate the insufficient data problem. Instead of sampling data according to the value of the conditioning variable, CCL-K uses the Kernel Conditional Embedding Operator that samples data from all available data and assigns weights to each sampled data given the kernel similarity between the values of the conditioning variable. We conduct experiments using weakly supervised, fair, and hard negatives contrastive learning, showing CCL-K outperforms state-of-the-art baselines.