 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multivariate Time Series Forecasting against Intra- and Inter-Series Transitional Shift
Jul 18, 2024



The non-stationary nature of real-world Multivariate Time Series (MTS) data presents forecasting models with a formidable challenge of the time-variant distribution of time series, referred to as distribution shift. Existing studies on the distribution shift mostly adhere to adaptive normalization techniques for alleviating temporal mean and covariance shifts or time-variant modeling for capturing temporal shifts. Despite improving model generalization, these normalization-based methods often assume a time-invariant transition between outputs and inputs but disregard specific intra-/inter-series correlations, while time-variant models overlook the intrinsic causes of the distribution shift. This limits model expressiveness and interpretability of tackling the distribution shift for MTS forecasting. To mitigate such a dilemma, we present a unified Probabilistic Graphical Model to Jointly capturing intra-/inter-series correlations and modeling the time-variant transitional distribution, and instantiate a neural framework called JointPGM for non-stationary MTS forecasting. Specifically, JointPGM first employs multiple Fourier basis functions to learn dynamic time factors and designs two distinct learners: intra-series and inter-series learners. The intra-series learner effectively captures temporal dynamics by utilizing temporal gates, while the inter-series learner explicitly models spatial dynamics through multi-hop propagation, incorporating Gumbel-softmax sampling. These two types of series dynamics are subsequently fused into a latent variable, which is inversely employed to infer time factors, generate final prediction, and perform reconstruction. We validate the effectiveness and efficiency of JointPGM through extensive experiments on six highly non-stationary MTS datasets, achieving state-of-the-art forecasting performance of MTS forecasting.
ParamReL: Learning Parameter Space Representation via Progressively Encoding Bayesian Flow Networks
May 24, 2024The recently proposed Bayesian Flow Networks~(BFNs) show great potential in modeling parameter spaces, offering a unified strategy for handling continuous, discretized, and discrete data. However, BFNs cannot learn high-level semantic representation from the parameter space since {common encoders, which encode data into one static representation, cannot capture semantic changes in parameters.} This motivates a new direction: learning semantic representations hidden in the parameter spaces to characterize mixed-typed noisy data. {Accordingly, we propose a representation learning framework named ParamReL, which operates in the parameter space to obtain parameter-wise latent semantics that exhibit progressive structures. Specifically, ParamReL proposes a \emph{self-}encoder to learn latent semantics directly from parameters, rather than from observations. The encoder is then integrated into BFNs, enabling representation learning with various formats of observations. Mutual information terms further promote the disentanglement of latent semantics and capture meaningful semantics simultaneously.} We illustrate {conditional generation and reconstruction} in ParamReL via expanding BFNs, and extensive {quantitative} experimental results demonstrate the {superior effectiveness} of ParamReL in learning parameter representation.
FedSI: Federated Subnetwork Inference for Efficient Uncertainty Quantification
Apr 24, 2024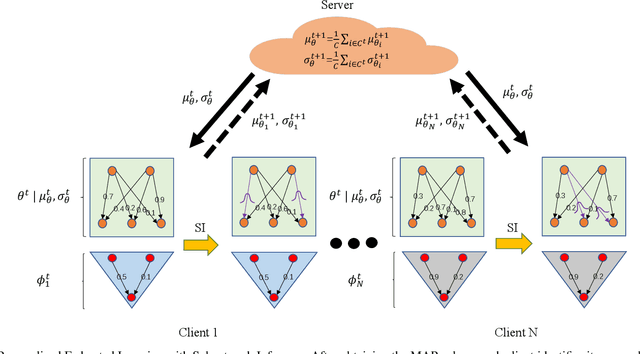
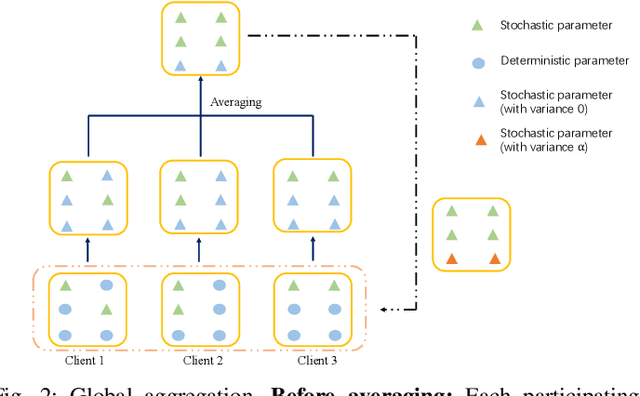
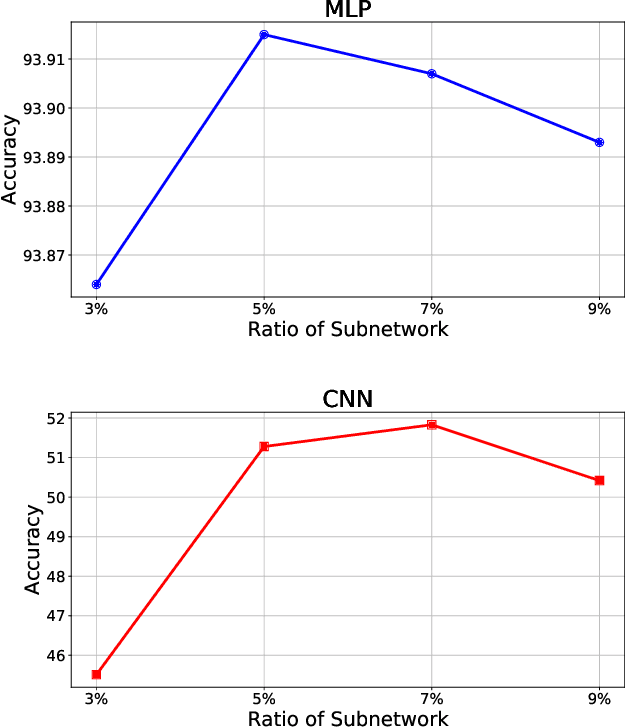
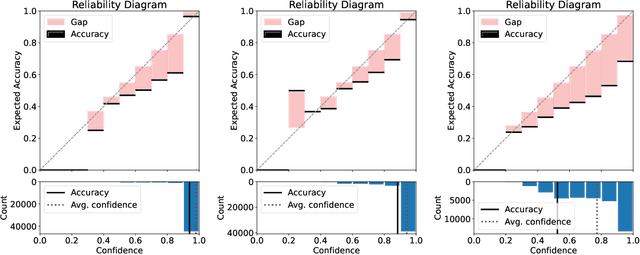
While deep neural networks (DNNs) based personalized federated learning (PFL) is demanding for addressing data heterogeneity and shows promising performance, existing methods for federated learning (FL) suffer from efficient systematic uncertainty quantification. The Bayesian DNNs-based PFL is usually questioned of either over-simplified model structures or high computational and memory costs. In this paper, we introduce FedSI, a novel Bayesian DNNs-based subnetwork inference PFL framework. FedSI is simple and scalable by leveraging Bayesian methods to incorporate systematic uncertainties effectively. It implements a client-specific subnetwork inference mechanism, selects network parameters with large variance to be inferred through posterior distributions, and fixes the rest as deterministic ones. FedSI achieves fast and scalable inference while preserving the systematic uncertainties to the fullest extent. Extensive experiments on three different benchmark datasets demonstrate that FedSI outperforms existing Bayesian and non-Bayesian FL baselines in heterogeneous FL scenarios.
Causal Learning for Trustworthy Recommender Systems: A Survey
Feb 13, 2024



Recommender Systems (RS) have significantly advanced online content discovery and personalized decision-making. However, emerging vulnerabilities in RS have catalyzed a paradigm shift towards Trustworthy RS (TRS). Despite numerous progress on TRS, most of them focus on data correlations while overlooking the fundamental causal nature in recommendation. This drawback hinders TRS from identifying the cause in addressing trustworthiness issues, leading to limited fairness, robustness, and explainability. To bridge this gap, causal learning emerges as a class of promising methods to augment TRS. These methods, grounded in reliable causality, excel in mitigating various biases and noises while offering insightful explanations for TRS. However, there lacks a timely survey in this vibrant area. This paper creates an overview of TRS from the perspective of causal learning. We begin by presenting the advantages and common procedures of Causality-oriented TRS (CTRS). Then, we identify potential trustworthiness challenges at each stage and link them to viable causal solutions, followed by a classification of CTRS methods. Finally, we discuss several future directions for advancing this field.
DE$^3$-BERT: Distance-Enhanced Early Exiting for BERT based on Prototypical Networks
Feb 03, 2024



Early exiting has demonstrated its effectiveness in accelerating the inference of pre-trained language models like BERT by dynamically adjusting the number of layers executed. However, most existing early exiting methods only consider local information from an individual test sample to determine their exiting indicators, failing to leverage the global information offered by sample population. This leads to suboptimal estimation of prediction correctness, resulting in erroneous exiting decisions. To bridge the gap, we explore the necessity of effectively combining both local and global information to ensure reliable early exiting during inference. Purposefully, we leverage prototypical networks to learn class prototypes and devise a distance metric between samples and class prototypes. This enables us to utilize global information for estimating the correctness of early predictions. On this basis, we propose a novel Distance-Enhanced Early Exiting framework for BERT (DE$^3$-BERT). DE$^3$-BERT implements a hybrid exiting strategy that supplements classic entropy-based local information with distance-based global information to enhance the estimation of prediction correctness for more reliable early exiting decisions. Extensive experiments on the GLUE benchmark demonstrate that DE$^3$-BERT consistently outperforms state-of-the-art models under different speed-up ratios with minimal storage or computational overhead, yielding a better trade-off between model performance and inference efficiency. Additionally, an in-depth analysis further validates the generality and interpretability of our method.
Weakly Augmented Variational Autoencoder in Time Series Anomaly Detection
Jan 07, 2024Due to their unsupervised training and uncertainty estimation, deep Variational Autoencoders (VAEs) have become powerful tools for reconstruction-based Time Series Anomaly Detection (TSAD). Existing VAE-based TSAD methods, either statistical or deep, tune meta-priors to estimate the likelihood probability for effectively capturing spatiotemporal dependencies in the data. However, these methods confront the challenge of inherent data scarcity, which is often the case in anomaly detection tasks. Such scarcity easily leads to latent holes, discontinuous regions in latent space, resulting in non-robust reconstructions on these discontinuous spaces. We propose a novel generative framework that combines VAEs with self-supervised learning (SSL) to address this issue.
Frequency Spectrum is More Effective for Multimodal Representation and Fusion: A Multimodal Spectrum Rumor Detector
Dec 18, 2023



Multimodal content, such as mixing text with images, presents significant challenges to rumor detection in social media. Existing multimodal rumor detection has focused on mixing tokens among spatial and sequential locations for unimodal representation or fusing clues of rumor veracity across modalities. However, they suffer from less discriminative unimodal representation and are vulnerable to intricate location dependencies in the time-consuming fusion of spatial and sequential tokens. This work makes the first attempt at multimodal rumor detection in the frequency domain, which efficiently transforms spatial features into the frequency spectrum and obtains highly discriminative spectrum features for multimodal representation and fusion. A novel Frequency Spectrum Representation and fUsion network (FSRU) with dual contrastive learning reveals the frequency spectrum is more effective for multimodal representation and fusion, extracting the informative components for rumor detection. FSRU involves three novel mechanisms: utilizing the Fourier transform to convert features in the spatial domain to the frequency domain, the unimodal spectrum compression, and the cross-modal spectrum co-selection module in the frequency domain. Substantial experiments show that FSRU achieves satisfactory multimodal rumor detection performance.
Out-of-Distribution Knowledge Distillation via Confidence Amendment
Nov 14, 2023



Out-of-distribution (OOD) detection is essential in identifying test samples that deviate from the in-distribution (ID) data upon which a standard network is trained, ensuring network robustness and reliability. This paper introduces OOD knowledge distillation, a pioneering learning framework applicable whether or not training ID data is available, given a standard network. This framework harnesses OOD-sensitive knowledge from the standard network to craft a binary classifier adept at distinguishing between ID and OOD samples. To accomplish this, we introduce Confidence Amendment (CA), an innovative methodology that transforms an OOD sample into an ID one while progressively amending prediction confidence derived from the standard network. This approach enables the simultaneous synthesis of both ID and OOD samples, each accompanied by an adjusted prediction confidence, thereby facilitating the training of a binary classifier sensitive to OOD. Theoretical analysis provides bounds on the generalization error of the binary classifier, demonstrating the pivotal role of confidence amendment in enhancing OOD sensitivity. Extensive experiments spanning various datasets and network architectures confirm the efficacy of the proposed method in detecting OOD samples.
Frequency-domain MLPs are More Effective Learners in Time Series Forecasting
Nov 10, 2023



Time series forecasting has played the key role in different industrial, including finance, traffic, energy, and healthcare domains. While existing literatures have designed many sophisticated architectures based on RNNs, GNNs, or Transformers, another kind of approaches based on multi-layer perceptrons (MLPs) are proposed with simple structure, low complexity, and {superior performance}. However, most MLP-based forecasting methods suffer from the point-wise mappings and information bottleneck, which largely hinders the forecasting performance. To overcome this problem, we explore a novel direction of applying MLPs in the frequency domain for time series forecasting. We investigate the learned patterns of frequency-domain MLPs and discover their two inherent characteristic benefiting forecasting, (i) global view: frequency spectrum makes MLPs own a complete view for signals and learn global dependencies more easily, and (ii) energy compaction: frequency-domain MLPs concentrate on smaller key part of frequency components with compact signal energy. Then, we propose FreTS, a simple yet effective architecture built upon Frequency-domain MLPs for Time Series forecasting. FreTS mainly involves two stages, (i) Domain Conversion, that transforms time-domain signals into complex numbers of frequency domain; (ii) Frequency Learning, that performs our redesigned MLPs for the learning of real and imaginary part of frequency components. The above stages operated on both inter-series and intra-series scales further contribute to channel-wise and time-wise dependency learning. Extensive experiments on 13 real-world benchmarks (including 7 benchmarks for short-term forecasting and 6 benchmarks for long-term forecasting) demonstrate our consistent superiority over state-of-the-art methods.
FourierGNN: Rethinking Multivariate Time Series Forecasting from a Pure Graph Perspective
Nov 10, 2023



Multivariate time series (MTS) forecasting has shown great importance in numerous industries. Current state-of-the-art graph neural network (GNN)-based forecasting methods usually require both graph networks (e.g., GCN) and temporal networks (e.g., LSTM) to capture inter-series (spatial) dynamics and intra-series (temporal) dependencies, respectively. However, the uncertain compatibility of the two networks puts an extra burden on handcrafted model designs. Moreover, the separate spatial and temporal modeling naturally violates the unified spatiotemporal inter-dependencies in real world, which largely hinders the forecasting performance. To overcome these problems, we explore an interesting direction of directly applying graph networks and rethink MTS forecasting from a pure graph perspective. We first define a novel data structure, hypervariate graph, which regards each series value (regardless of variates or timestamps) as a graph node, and represents sliding windows as space-time fully-connected graphs. This perspective considers spatiotemporal dynamics unitedly and reformulates classic MTS forecasting into the predictions on hypervariate graphs. Then, we propose a novel architecture Fourier Graph Neural Network (FourierGNN) by stacking our proposed Fourier Graph Operator (FGO) to perform matrix multiplications in Fourier space. FourierGNN accommodates adequate expressiveness and achieves much lower complexity, which can effectively and efficiently accomplish the forecasting. Besides, our theoretical analysis reveals FGO's equivalence to graph convolutions in the time domain, which further verifies the validity of FourierGNN. Extensive experiments on seven datasets have demonstrated our superior performance with higher efficiency and fewer parameters compared with state-of-the-art methods.