 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Knowledge Graph Fusion by Exploiting the Open Corpus
Jun 15, 2022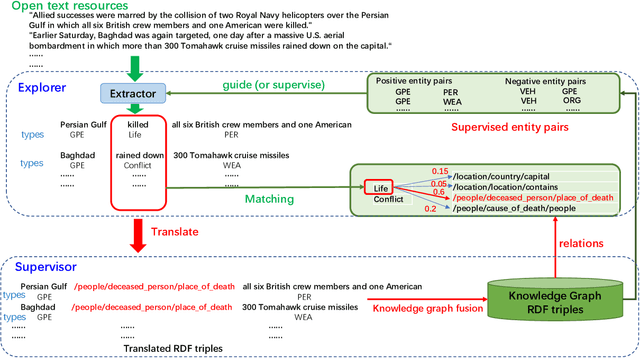
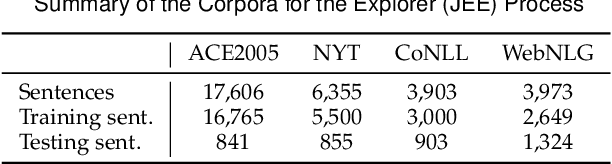
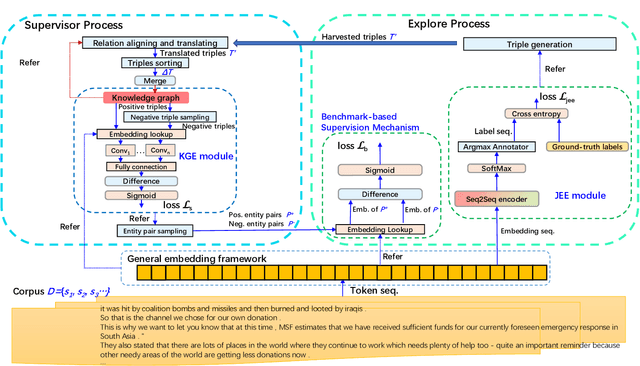
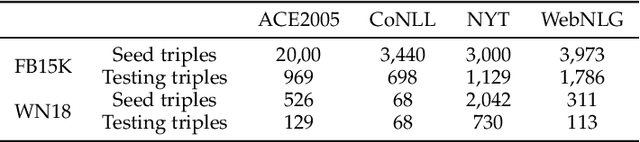
To alleviate the challenges of building Knowledge Graphs (KG) from scratch, a more general task is to enrich a KG using triples from an open corpus, where the obtained triples contain noisy entities and relations. It is challenging to enrich a KG with newly harvested triples while maintaining the quality of the knowledge representation. This paper proposes a system to refine a KG using information harvested from an additional corpus. To this end, we formulate our task as two coupled sub-tasks, namely join event extraction (JEE) and knowledge graph fusion (KGF). We then propose a Collaborative Knowledge Graph Fusion Framework to allow our sub-tasks to mutually assist one another in an alternating manner. More concretely, the explorer carries out the JEE supervised by both the ground-truth annotation and an existing KG provided by the supervisor. The supervisor then evaluates the triples extracted by the explorer and enriches the KG with those that are highly ranked. To implement this evaluation, we further propose a Translated Relation Alignment Scoring Mechanism to align and translate the extracted triples to the prior KG. Experiments verify that this collaboration can both improve the performance of the JEE and the KGF.
Writing Style Aware Document-level Event Extraction
Jan 10, 2022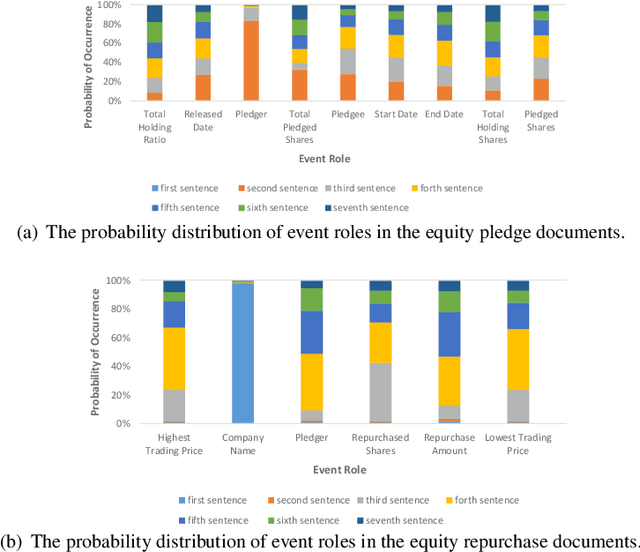
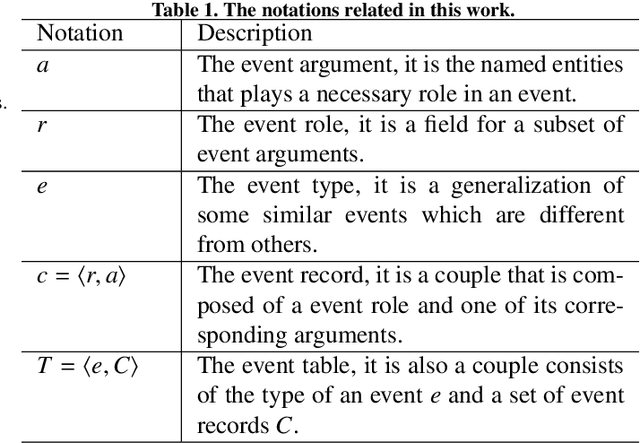
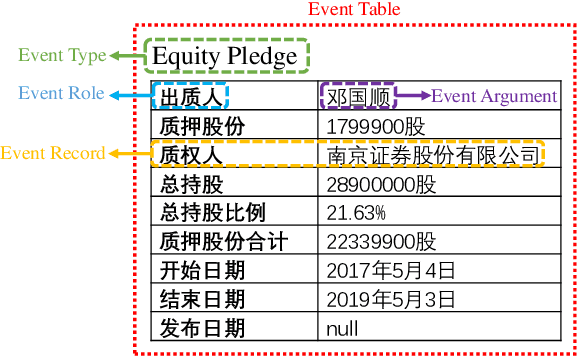
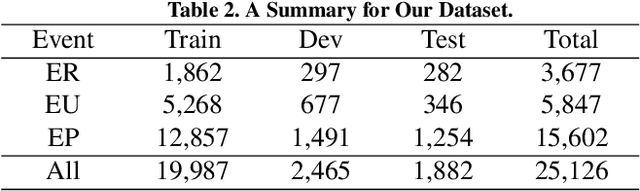
Event extraction, the technology that aims to automatically get the structural information from documents, has attracted more and more attention in many fields. Most existing works discuss this issue with the token-level multi-label classification framework by distinguishing the tokens as different roles while ignoring the writing styles of documents. The writing style is a special way of content organizing for documents and it is relative fixed in documents with a special field (e.g. financial, medical documents, etc.). We argue that the writing style contains important clues for judging the roles for tokens and the ignorance of such patterns might lead to the performance degradation for the existing works. To this end, we model the writing style in documents as a distribution of argument roles, i.e., Role-Rank Distribution, and propose an event extraction model with the Role-Rank Distribution based Supervision Mechanism to capture this pattern through the supervised training process of an event extraction task. We compare our model with state-of-the-art methods on several real-world datasets. The empirical results show that our approach outperforms other alternatives with the captured patterns. This verifies the writing style contains valuable information that could improve the performance of the event extraction task.
Cross-Supervised Joint-Event-Extraction with Heterogeneous Information Networks
Oct 14, 2020
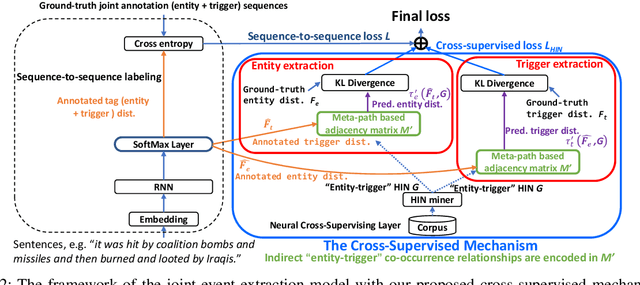
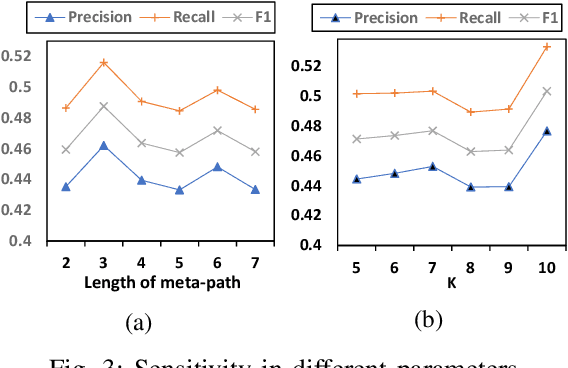

Joint-event-extraction, which extracts structural information (i.e., entities or triggers of events) from unstructured real-world corpora, has attracted more and more research attention in natural language processing. Most existing works do not fully address the sparse co-occurrence relationships between entities and triggers, which loses this important information and thus deteriorates the extraction performance. To mitigate this issue, we first define the joint-event-extraction as a sequence-to-sequence labeling task with a tag set composed of tags of triggers and entities. Then, to incorporate the missing information in the aforementioned co-occurrence relationships, we propose a Cross-Supervised Mechanism (CSM) to alternately supervise the extraction of either triggers or entities based on the type distribution of each other. Moreover, since the connected entities and triggers naturally form a heterogeneous information network (HIN), we leverage the latent pattern along meta-paths for a given corpus to further improve the performance of our proposed method. To verify the effectiveness of our proposed method, we conduct extensive experiments on four real-world datasets as well as compare our method with state-of-the-art methods. Empirical results and analysis show that our approach outperforms the state-of-the-art methods in both entity and trigger extraction.
A Hierarchical Transitive-Aligned Graph Kernel for Un-attributed Graphs
Feb 08, 2020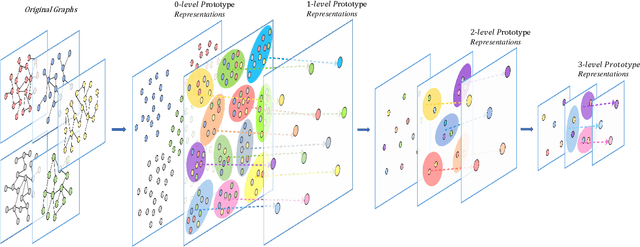
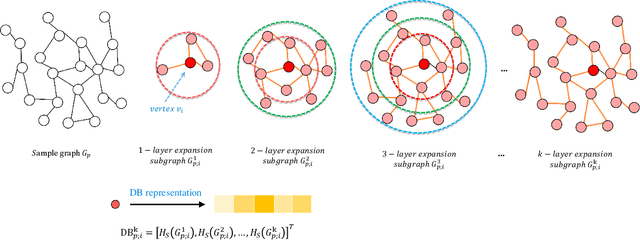


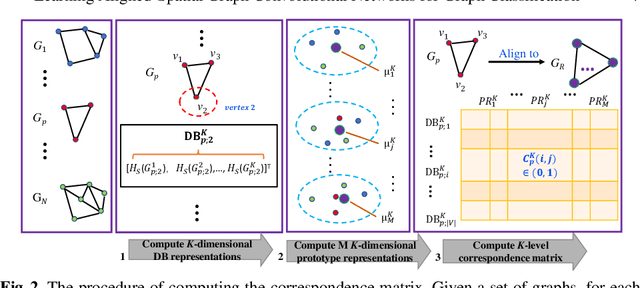
In this paper, we develop a new graph kernel, namely the Hierarchical Transitive-Aligned kernel, by transitively aligning the vertices between graphs through a family of hierarchical prototype graphs. Comparing to most existing state-of-the-art graph kernels, the proposed kernel has three theoretical advantages. First, it incorporates the locational correspondence information between graphs into the kernel computation, and thus overcomes the shortcoming of ignoring structural correspondences arising in most R-convolution kernels. Second, it guarantees the transitivity between the correspondence information that is not available for most existing matching kernels. Third, it incorporates the information of all graphs under comparisons into the kernel computation process, and thus encapsulates richer characteristics. By transductively training the C-SVM classifier, experimental evaluations demonstrate the effectiveness of the new transitive-aligned kernel. The proposed kernel can outperform state-of-the-art graph kernels on standard graph-based datasets in terms of the classification accuracy.
Generative Temporal Link Prediction via Self-tokenized Sequence Modeling
Nov 26, 2019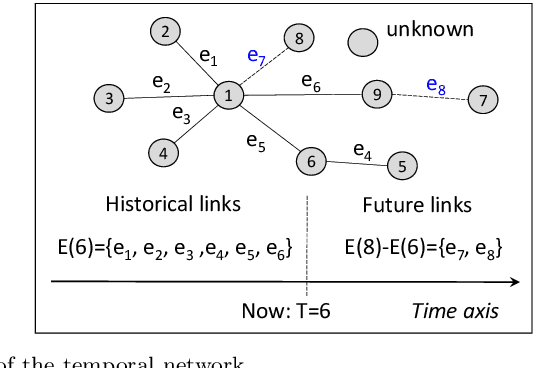
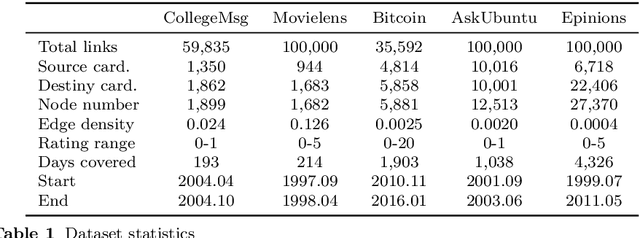
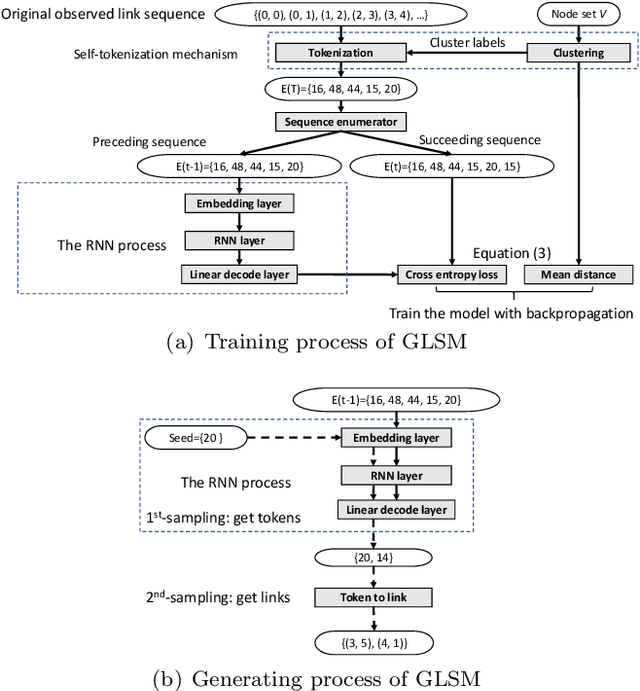
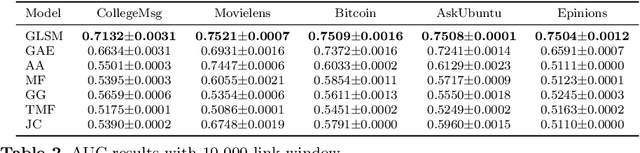
We formalize networks with evolving structures as temporal networks and propose a generative link prediction model, Generative Link Sequence Modeling (GLSM), to predict future links for temporal networks. GLSM captures the temporal link formation patterns from the observed links with a sequence modeling framework and has the ability to generate the emerging links by inferring from the probability distribution on the potential future links. To avoid overfitting caused by treating each link as a unique token, we propose a self-tokenization mechanism to transform each raw link in the network to an abstract aggregation token automatically. The self-tokenization is seamlessly integrated into the sequence modeling framework, which allows the proposed GLSM model to have the generalization capability to discover link formation patterns beyond raw link sequences. We compare GLSM with the existing state-of-art methods on five real-world datasets. The experimental results demonstrate that GLSM obtains future positive links effectively in a generative fashion while achieving the best performance (2-10\% improvements on AUC) among other alternatives.
Entropic Dynamic Time Warping Kernels for Co-evolving Financial Time Series Analysis
Oct 21, 2019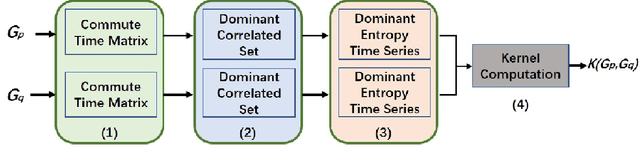
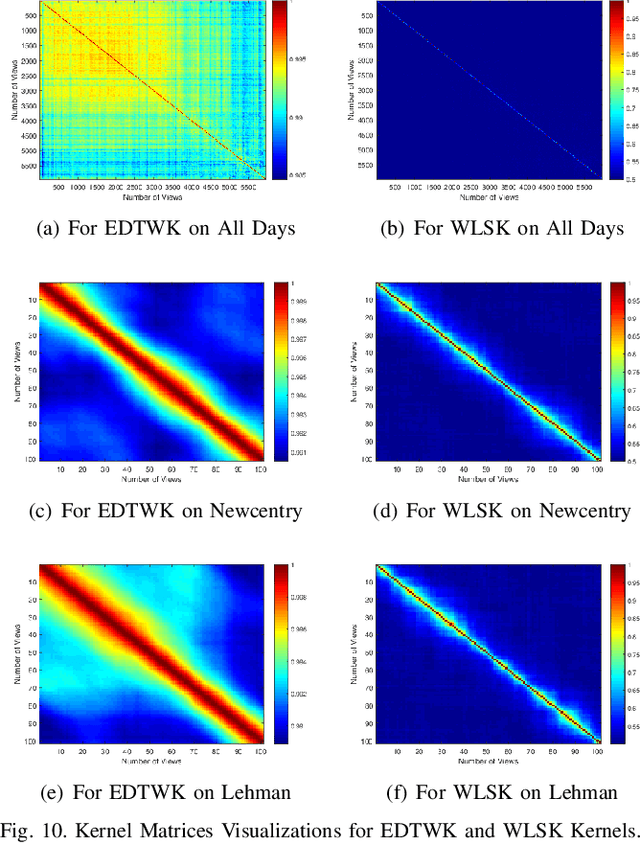
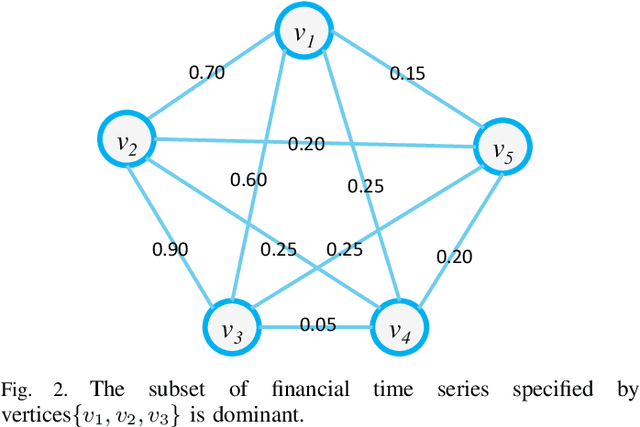
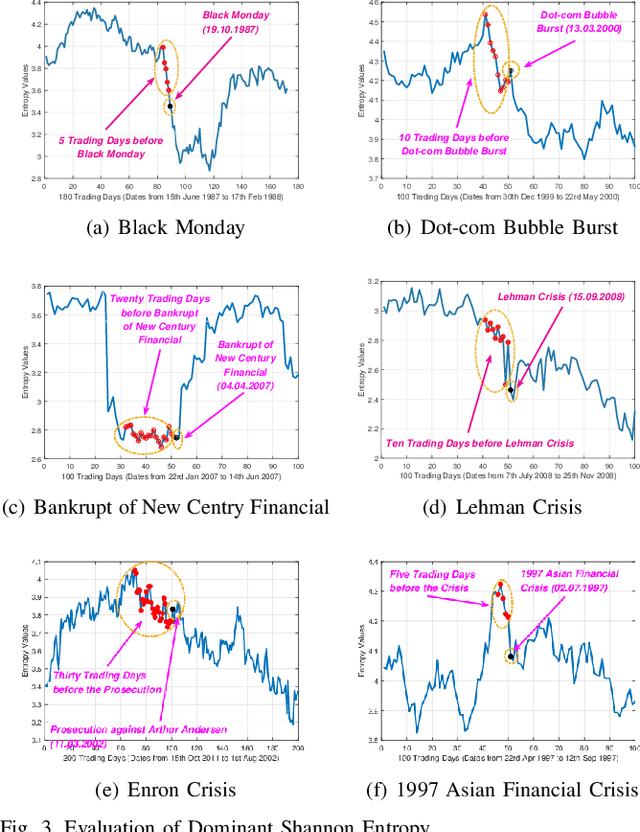
In this work, we develop a novel framework to measure the similarity between dynamic financial networks, i.e., time-varying financial networks. Particularly, we explore whether the proposed similarity measure can be employed to understand the structural evolution of the financial networks with time. For a set of time-varying financial networks with each vertex representing the individual time series of a different stock and each edge between a pair of time series representing the absolute value of their Pearson correlation, our start point is to compute the commute time matrix associated with the weighted adjacency matrix of the network structures, where each element of the matrix can be seen as the enhanced correlation value between pairwise stocks. For each network, we show how the commute time matrix allows us to identify a reliable set of dominant correlated time series as well as an associated dominant probability distribution of the stock belonging to this set. Furthermore, we represent each original network as a discrete dominant Shannon entropy time series computed from the dominant probability distribution. With the dominant entropy time series for each pair of financial networks to hand, we develop a similarity measure based on the classical dynamic time warping framework, for analyzing the financial time-varying networks. We show that the proposed similarity measure is positive definite and thus corresponds to a kernel measure on graphs. The proposed kernel bridges the gap between graph kernels and the classical dynamic time warping framework for multiple financial time series analysis. Experiments on time-varying networks extracted through New York Stock Exchange (NYSE) database demonstrate the effectiveness of the proposed approach.
Competitive Multi-Agent Deep Reinforcement Learning with Counterfactual Thinking
Aug 16, 2019



Counterfactual thinking describes a psychological phenomenon that people re-infer the possible results with different solutions about things that have already happened. It helps people to gain more experience from mistakes and thus to perform better in similar future tasks. This paper investigates the counterfactual thinking for agents to find optimal decision-making strategies in multi-agent reinforcement learning environments. In particular, we propose a multi-agent deep reinforcement learning model with a structure which mimics the human-psychological counterfactual thinking process to improve the competitive abilities for agents. To this end, our model generates several possible actions (intent actions) with a parallel policy structure and estimates the rewards and regrets for these intent actions based on its current understanding of the environment. Our model incorporates a scenario-based framework to link the estimated regrets with its inner policies. During the iterations, our model updates the parallel policies and the corresponding scenario-based regrets for agents simultaneously. To verify the effectiveness of our proposed model, we conduct extensive experiments on two different environments with real-world applications. Experimental results show that counterfactual thinking can actually benefit the agents to obtain more accumulative rewards from the environments with fair information by comparing to their opponents while keeping high performing efficiency.
Learning Aligned-Spatial Graph Convolutional Networks for Graph Classification
Apr 06, 2019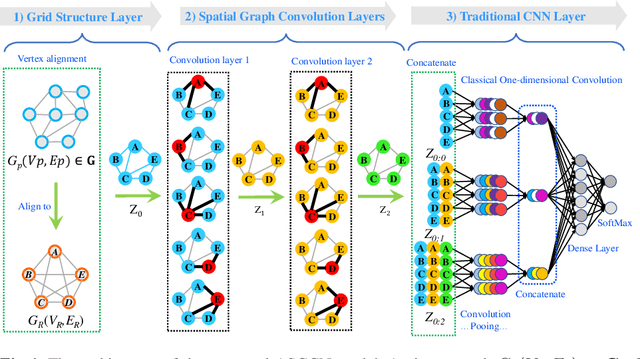
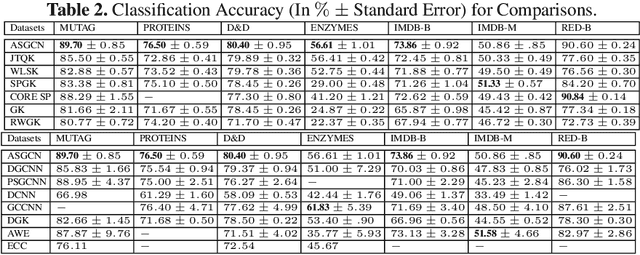
In this paper, we develop a novel Aligned-Spatial Graph Convolutional Network (ASGCN) model to learn effective features for graph classification. Our idea is to transform arbitrary-sized graphs into fixed-sized aligned grid structures, and define a new spatial graph convolution operation associated with the grid structures. We show that the proposed ASGCN model not only reduces the problems of information loss and imprecise information representation arising in existing spatially-based Graph Convolutional Network (GCN) models, but also bridges the theoretical gap between traditional Convolutional Neural Network (CNN) models and spatially-based GCN models. Moreover, the proposed ASGCN model can adaptively discriminate the importance between specified vertices during the process of spatial graph convolution, explaining the effectiveness of the proposed model. Experiments on standard graph datasets demonstrate the effectiveness of the proposed model.
Fused Lasso for Feature Selection using Structural Information
Feb 26, 2019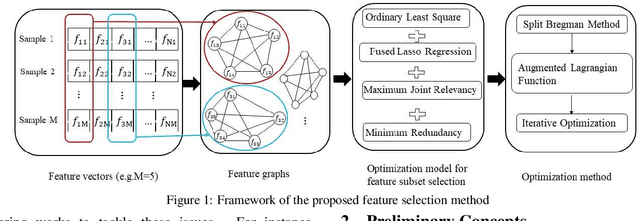
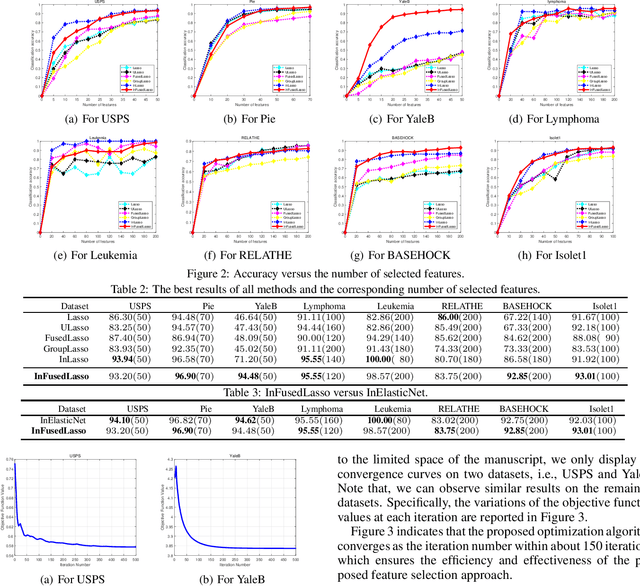
Feature selection has been proven a powerful preprocessing step for high-dimensional data analysis. However, most state-of-the-art methods suffer from two major drawbacks. First, they usually overlook the structural correlation information between pairwise samples, which may encapsulate useful information for refining the performance of feature selection. Second, they usually consider candidate feature relevancy equivalent to selected feature relevancy, and some less relevant features may be misinterpreted as salient features. To overcome these issues, we propose a new fused lasso for feature selection using structural information. Our idea is based on converting the original vectorial features into structure-based feature graph representations to incorporate structural relationship between samples, and defining a new evaluation measure to compute the joint significance of pairwise feature combinations in relation to the target feature graph. Furthermore, we formulate the corresponding feature subset selection problem into a least square regression model associated with a fused lasso regularizer to simultaneously maximize the joint relevancy and minimize the redundancy of the selected features. To effectively solve the challenging optimization problem, an iterative algorithm is developed to identify the most discriminative features. Experiments demonstrate the effectiveness of the proposed approach.
Learning Vertex Convolutional Networks for Graph Classification
Feb 26, 2019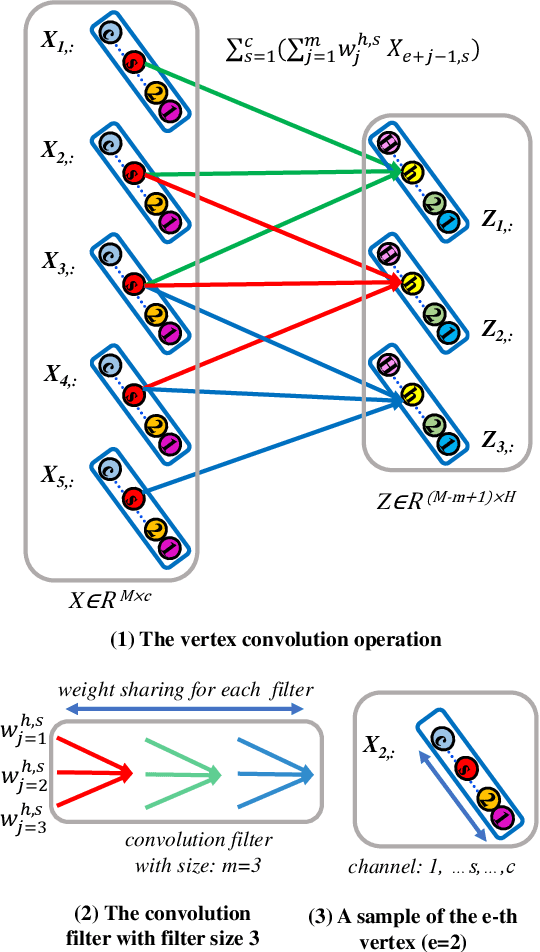


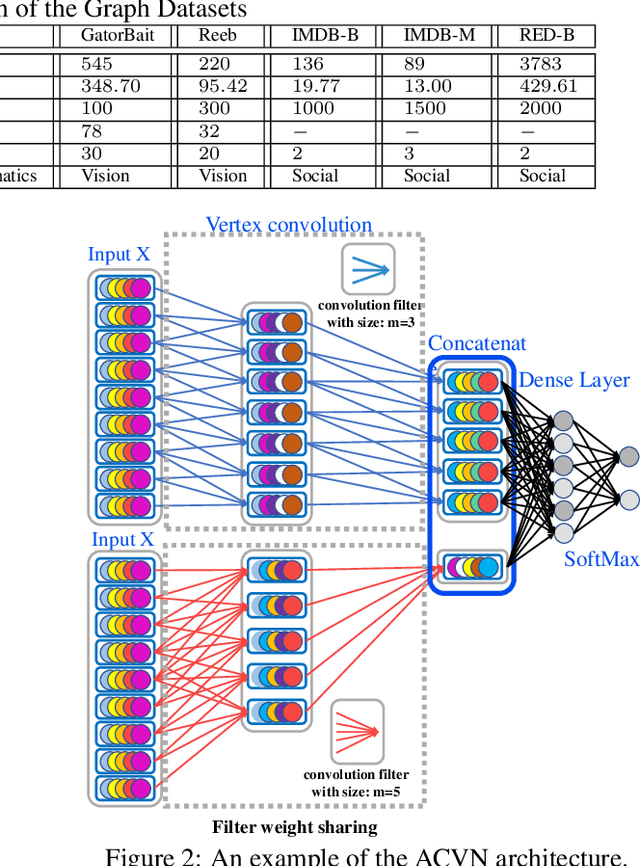
In this paper, we develop a new aligned vertex convolutional network model to learn multi-scale local-level vertex features for graph classification. Our idea is to transform the graphs of arbitrary sizes into fixed-sized aligned vertex grid structures, and define a new vertex convolution operation by adopting a set of fixed-sized one-dimensional convolution filters on the grid structure. We show that the proposed model not only integrates the precise structural correspondence information between graphs but also minimises the loss of structural information residing on local-level vertices. Experiments on standard graph datasets demonstrate the effectiveness of the proposed model.