 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetromorphic Testing with Hierarchical Verification for Hallucination Detection in RAG
Mar 29, 2026Large language models (LLMs) continue to hallucinate in retrieval-augmented generation (RAG), producing claims that are unsupported by or conflict with the retrieved context. Detecting such errors remains challenging when faithfulness is evaluated solely with respect to the retrieved context. Existing approaches either provide coarse-grained, answer-level scores or focus on open-domain factuality, often lacking fine-grained, evidence-grounded diagnostics. We present RT4CHART, a retromorphic testing framework for context-faithfulness assessment. RT4CHART decomposes model outputs into independently verifiable claims and performs hierarchical, local-to-global verification against the retrieved context. Each claim is assigned one of three labels: entailed, contradicted, or baseless. Furthermore, RT4CHART maps claim-level decisions back to specific answer spans and retrieves explicit supporting or refuting evidence from the context, enabling fine-grained and interpretable auditing. We evaluate RT4CHART on RAGTruth++ (408 samples) and RAGTruth-Enhance (2,675 samples), a newly re-annotated benchmark. RT4CHART achieves the best answer-level hallucination detection F1 among all baselines. On RAGTruth++, it reaches an F1 score of 0.776, outperforming the strongest baseline by 83%. On RAGTruth-Enhance, it achieves a span-level F1 of 47.5%. Ablation studies show that the hierarchical verification design is the primary driver of performance gains. Finally, our re-annotation reveals 1.68x more hallucination cases than the original labels, suggesting that existing benchmarks substantially underestimate the prevalence of hallucinations.
Embedding Cardinality Constraints in Neural Link Predictors
Dec 16, 2018
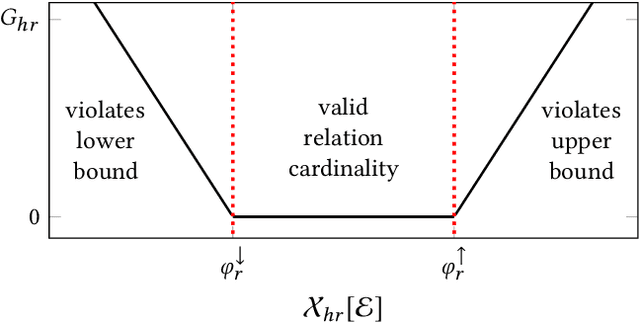

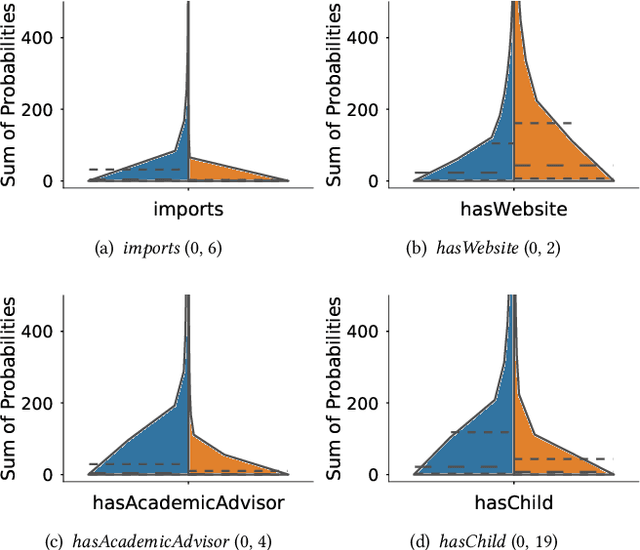
Neural link predictors learn distributed representations of entities and relations in a knowledge graph. They are remarkably powerful in the link prediction and knowledge base completion tasks, mainly due to the learned representations that capture important statistical dependencies in the data. Recent works in the area have focused on either designing new scoring functions or incorporating extra information into the learning process to improve the representations. Yet the representations are mostly learned from the observed links between entities, ignoring commonsense or schema knowledge associated with the relations in the graph. A fundamental aspect of the topology of relational data is the cardinality information, which bounds the number of predictions given for a relation between a minimum and maximum frequency. In this paper, we propose a new regularisation approach to incorporate relation cardinality constraints to any existing neural link predictor without affecting their efficiency or scalability. Our regularisation term aims to impose boundaries on the number of predictions with high probability, thus, structuring the embeddings space to respect commonsense cardinality assumptions resulting in better representations. Experimental results on Freebase, WordNet and YAGO show that, given suitable prior knowledge, the proposed method positively impacts the predictive accuracy of downstream link prediction tasks.